







hive能兼容大部分sql语句,所以操作hive的语法与sql类似。
Hive的基本数据类型:

Hive的复杂数据类型
Hive表种类
Hive表类型:
-
内部表(受控表)
完全被Hive控制,删除内部表,元数据、源数据一同被删除 -
临时表
生命周期是一次会话,主要用于测试 -
外部表
不是完全受Hive控制,源数据可以在任何的目录下,删除外部表,源数据不会被删除,只是删除元数据 -
分区表
将源数据分到不同的Hive工作目录中存储,一个分区对应一个目录,防止暴力扫描全表 -
分桶表
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中对于hive中每一个表、分区都可以进一步进行分桶

Hive操作表和数据库
Hive的操作对于用户来说实际上就是表的操作、数据库的操作。
登录进去hive,创建一个test的数据库:
create database test;
创建一个内部表:
建表方式一:
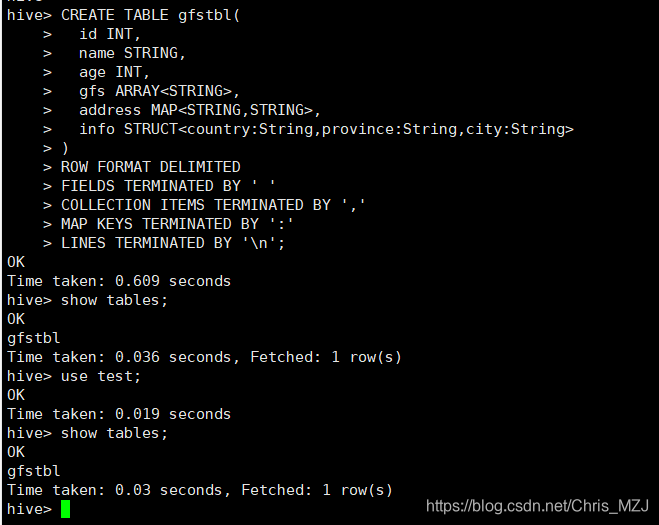
CREATE TABLE gfstbl(
id INT,
name STRING,
age INT,
gfs ARRAY<STRING>,
address MAP<STRING,STRING>,
info STRUCT<country:String,province:String,city:String>
)
ROW FORMAT DELIMITED //一行文本对应表中的一条记录
FIELDS TERMINATED BY ' ' //指定输入文件字段的间隔符,即输入文件的字段之间是用生什么隔开的
COLLECTION ITEMS TERMINATED BY ',' //指定集合数据类型的分隔符
MAP KEYS TERMINATED BY ':' //指定Map数据类型的分割符
LINES TERMINATED BY '\n'; //指定输入文件的每一行作为一条记录
LOCATION "/test" //可以设置源数据的位置,若不设置默认就在Hive的工作目录区
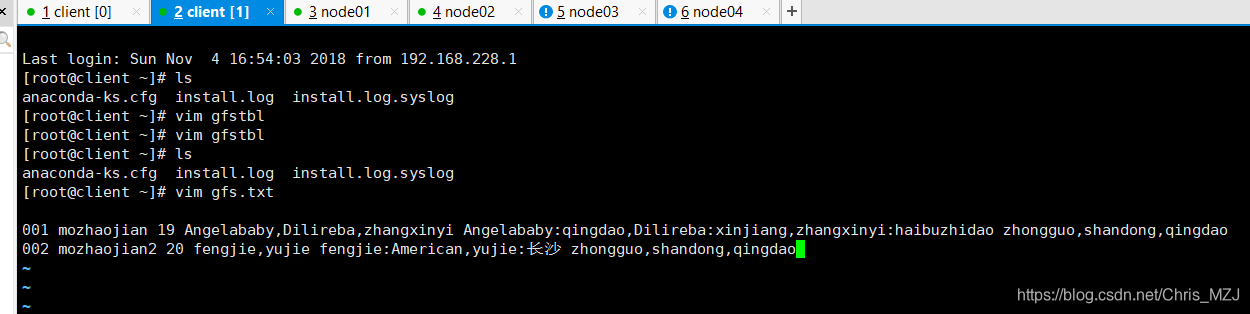
加载数据到gfstbl表中,首先在本地创建一个格式和gfstbl相对应的文件,文件内容如下:
001 mozhaojian 19 Angelababy,Dilireba,zhangxinyi Angelababy:qingdao,Dilireba:xinjiang,zhangxinyi:haibuzhidao zhongguo,shandong,qingdao
002 mozhaojian2 20 fengjie,yujie fengjie:American,yujie:长沙 zhongguo,shandong,qingdao
然后执行:
load data local inpath '/root/gfs.txt' into table gfstbl;(加载数据到gfstbl中)
执行这段代码,hive会根据gfstbl表中的字段对gfs.txt中的每一行进行切割,并将切割好的内容保存到相应字段:

查看表描述信息
DESCRIBE [EXTENDED|FORMATTED] table_name
EXTENDED极简的方式显示
FORMATTED格式化方式来显示
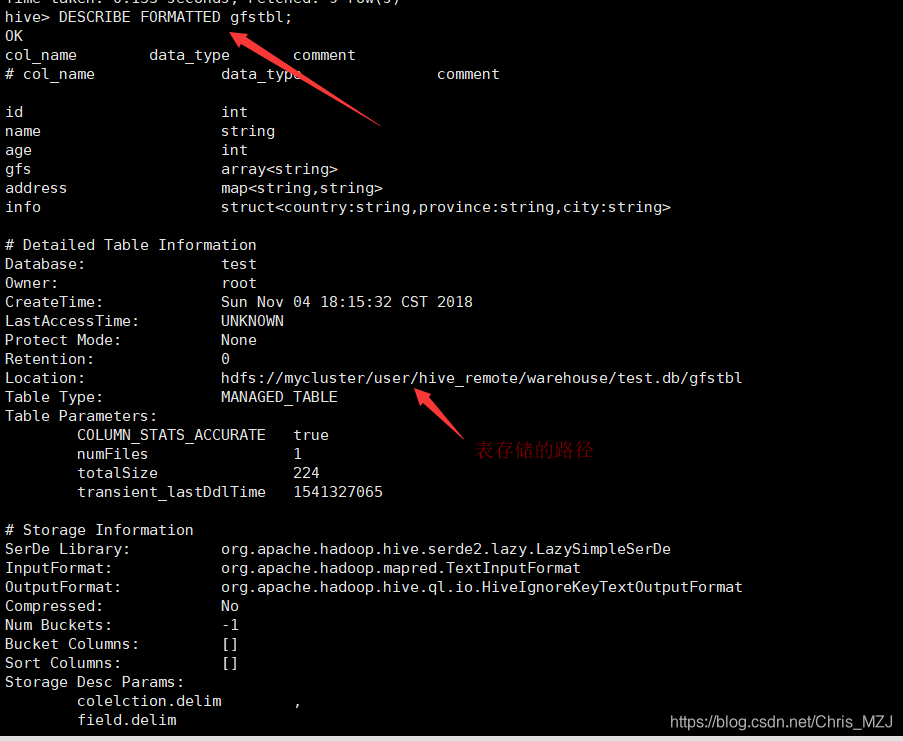
DESCRIBE EXTENDED gfstbl;默认就是EXTENDED
DESCRIBE FORMATTED gfstbl;
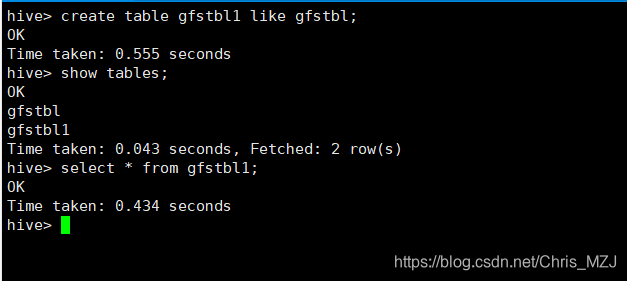
建表方式二:
create table gfstbl1 like gfstbl;只是创建表结构
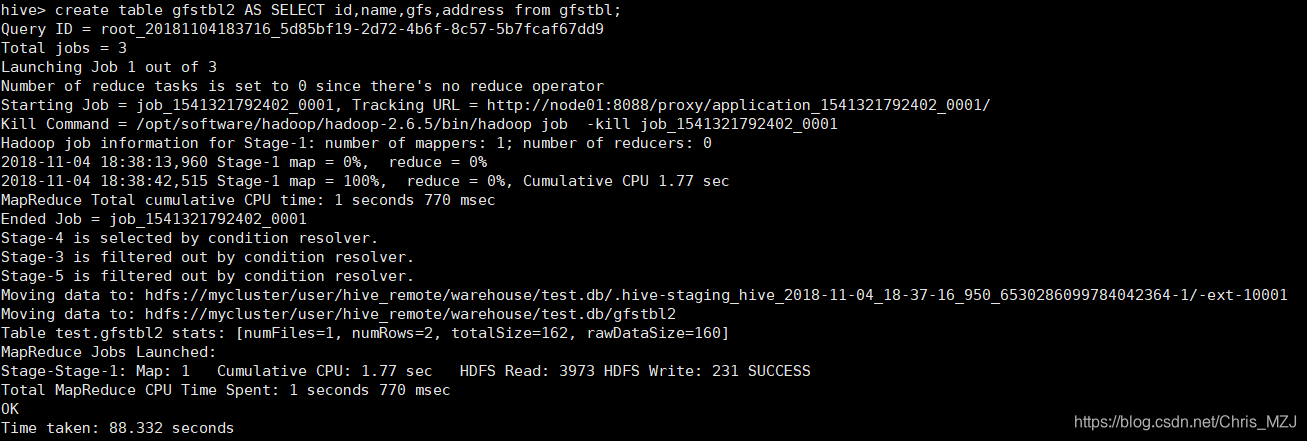
创建表方式三
create table gfstbl2 AS SELECT id,name,gfs,address from gfstbl; 会创建相应的表结构,并且插入数据,插入的数据是从gfstbl查询到的数据,插入数据会转化成一个MapReduce程序执行:

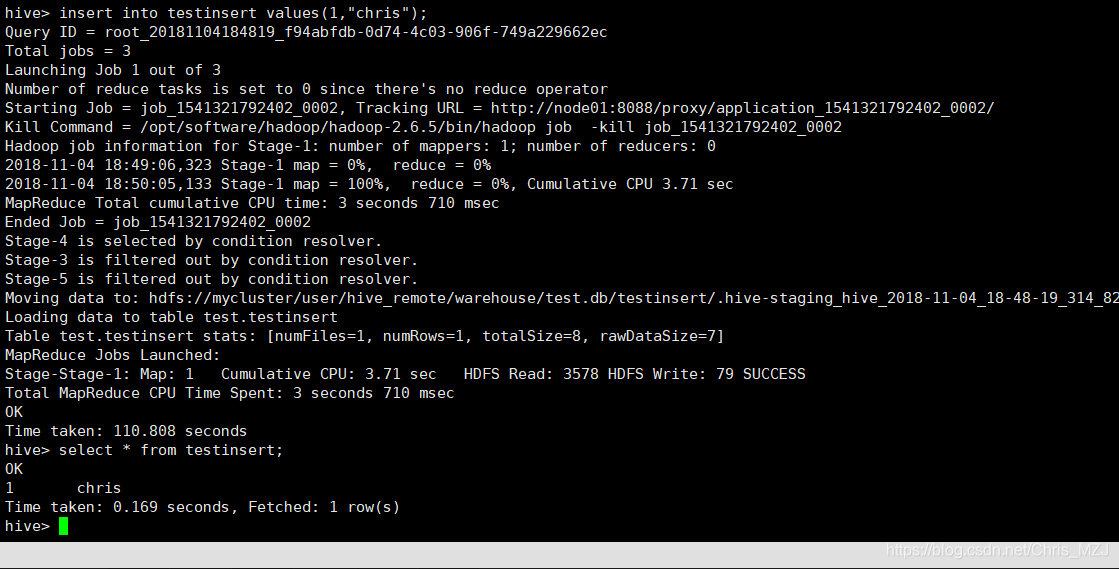
插入数据的方式:
- 1、insert 新数据
-
2、load (前面创建gfstbl表的时候就是用的这种方式)
load data local inpath '/root/gfs.txt' into table gfstbl; load data local inpath '/gfs' into table gfstbl;load data是固定格式,local表示从本地加载,inpath紧跟输入路径。如果不加local,表示从hdfs集群上加载数据,从本地加载数据到gfstbl表中,本地的数据不会被删除,而从hdfs集群中加载数据到gfstbl表中,则会将文件移动到gfstbl表对应的目录下,如:
load之前:

load之后:


可以去gfstbl表的目录下找到gfs这个文件
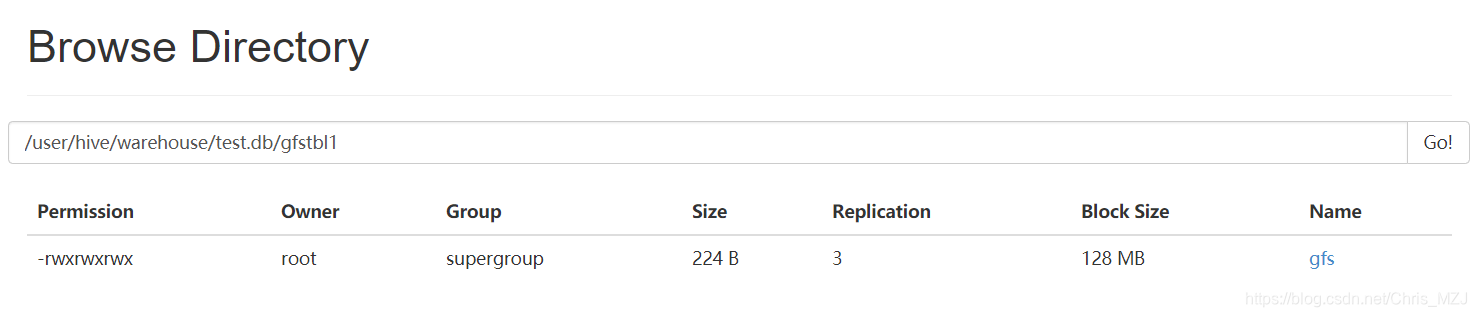
-
3、查询其他表数据 insert 到新表中
模板:
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 …)] select_statement1 FROM from_statement;
或者
FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 …) [IF NOT EXISTS]] select_statement;(习惯写法 from提前 减少SQL代码的冗余)
测试代码:
insert into rest select count(*) from gfstbl;
from gfstbl
insert into rest
select count(*) from day_hour_table;
运行结果:
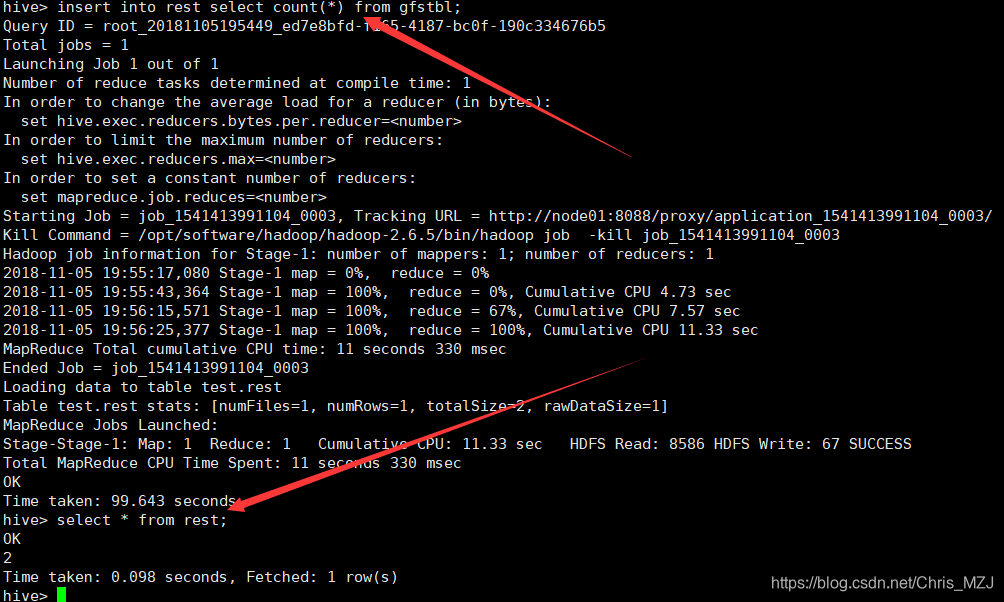
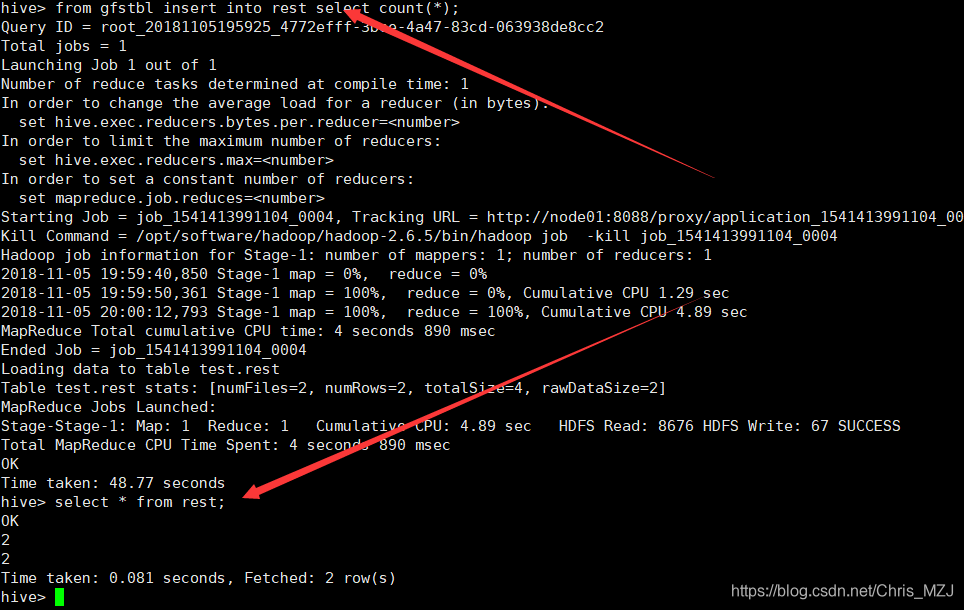
创建一个临时表:
临时表的有效期仅仅是一次会话,关闭会话后表就会被删除掉。
创建一个临时表只需要在create关键字后加 TEMPORARY 修饰即可:
create TEMPORARY table ttabc(id Int,name String);
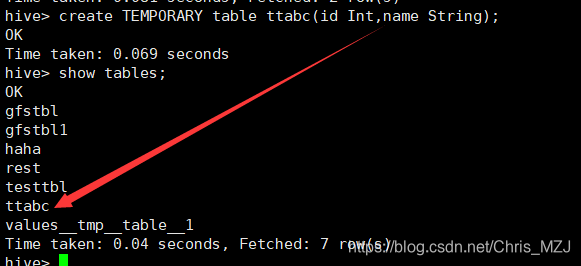
退出会话,重新进入hive,ttabc表不见了:
创建一个外部表:
外部表相对于内部表,源数据可以在任何的目录下,删除外部表,源数据不会被删除,只是删除元数据。
创建外部表只需要在create和table之间添加一个external即可:
create external table wc_external
(word1 STRING,
word2 STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
location '/test/external'; //location可加可不加,不加location默认是在hive的工作目录区
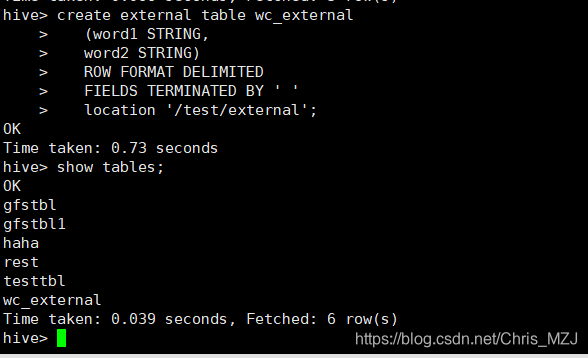
将按照wc_external表的规则 创建了一个新的文件wc:
将这个文件拷贝到这个表的工作目录区中,然后查询这个表数据量增多
上传:

查询:
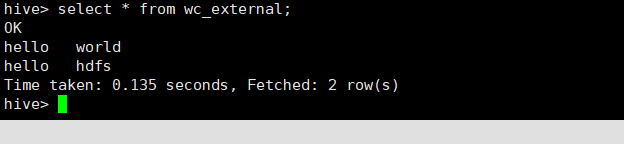
将工作目录区中文件再次添加到这个表中,发现数据量没有增量:
load data inpath "/test/external/wc" into table wc_external;
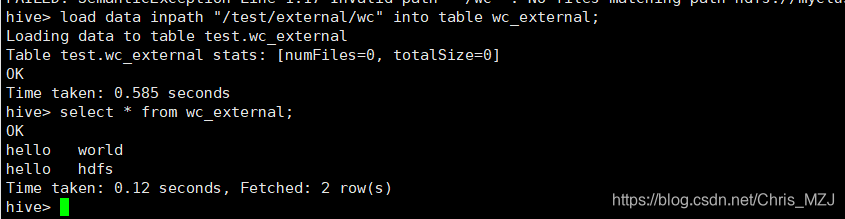
将文件上传到了hdfs的/根目录

执行:
load data inpath "/wc" into table wc_external;
数据量增多了,但是/wc文件被剪切了
hive> select * from wc_external;
OK
hello world
hello hdfs
Time taken: 0.736 seconds, Fetched: 2 row(s)
hive> load data inpath '/wc' into table wc_external;
Loading data to table test.wc_external
Table test.wc_external stats: [numFiles=0, totalSize=0]
OK
Time taken: 0.671 seconds
hive> select * from wc_external;
OK
hello world
hello hdfs
hello world
hello hdfs
Time taken: 0.114 seconds, Fetched: 4 row(s)
hive>
执行下面这段代码:
create external table wc_external1
(word1 STRING,
word2 STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
location '/test/external';
建表的时候指定了数据位置是在集群的/test/external下,因为该目录下本来就有wc文件,wc内的内容也符合wc_external1的格式,所以wc_external1中会有数据:
hive> create external table wc_external1
> (word1 STRING,
> word2 STRING)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ' '
> location '/test/external';
OK
Time taken: 0.068 seconds
hive> select * from wc_external1;
OK
hello world
hello hdfs
hello world
hello hdfs
Time taken: 0.142 seconds, Fetched: 4 row(s)
hive>
再执行这段代码:
create external table wc_external2
(word1 STRING,
word2 STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' ';
建表的时候没有指定位置,所以wc_external2中不会有数据:
hive> create external table wc_external2
> (word1 STRING,
> word2 STRING)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ' ';
OK
Time taken: 0.436 seconds
hive> select * from wc_external2;
OK
Time taken: 0.668 seconds
hive>
创建一个静态分区表
为什么要有分区表?
是为了防止暴力扫描全表,比如把订单表数据存到一个订单表中,要查询某个区间的数据,如果查询普通表则需要扫描全表,如果查询的是分区表,只需要按分区查询即可,可以提高查询效率。而分区表又分为静态分区和动态分区,静态分区就是插入数据的时候需要手动指定分区,动态分区在插入数据的时候则不需要手动指定。
单分区表:
顾名思议就是根据一个字段进行分区,使用关键字partitioned by(),创建单分区表:
create table day_table (id int, content string) partitioned by (dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
加载数据:
insert单条插入的方式往分区表中插入数据:
insert into day_table partition (dt = "9-26") values(1,"abc");
insert into day_table partition (dt = "9-26") values(2,"bcd");
insert into day_table partition (dt = "9-27") values(3,"xxx");
insert into day_table partition (dt = "9-27") values(4,"yyy");
hive > select * from day_table;
OK
1 abc 9-26
2 bcd 9-26
3 xxx 9-27
4 yyy 9-27
Time taken: 1.068 seconds, Fetched: 4 row(s)
hive >
load批量插入的方式往分区表中插入数据:
先在HDFS集群中创建好数据
[root@client ~]# hdfs dfs -put ceshi /root/
[root@client ~]# hdfs dfs -cat /root/ceshi
5 hahaha
6 hehehe
7 heihei
8 hiahia
[root@client ~]#
hive中执行:
load data local inpath "/root/ceshi" into table day_table partition (dt="9-27");
执行结果:
hive> load data local inpath "/root/ceshi" into table day_table partition (dt="9-27");
Loading data to table test.day_table partition (dt=9-27)
Partition test.day_table{dt=9-27} stats: [numFiles=3, numRows=0, totalSize=49, rawDataSize=0]
OK
Time taken: 1.762 seconds
hive> select * from day_table;
OK
1 abc 9-26
2 bcd 9-26
3 xxx 9-27
4 yyy 9-27
5 hahaha 9-27
6 hehehe 9-27
7 heihei 9-27
8 hiahia 9-27
NULL NULL 9-27
Time taken: 0.131 seconds, Fetched: 9 row(s)
hive>
创建好分区表之后,可以根据分区号来进行查询数据:
hive> select * from day_table where dt='9-26';
OK
1 abc 9-26
2 bcd 9-26
Time taken: 0.81 seconds, Fetched: 2 row(s)
hive> select * from day_table where dt='9-27';
OK
3 xxx 9-27
4 yyy 9-27
5 hahaha 9-27
6 hehehe 9-27
7 heihei 9-27
8 hiahia 9-27
NULL NULL 9-27
Time taken: 0.18 seconds, Fetched: 7 row(s)
hive>
根据分区表删除数据
ALTER TABLE day_table DROP PARTITION (dt="9-27");
执行结果:
hive> ALTER TABLE day_table DROP PARTITION (dt="9-27");
Dropped the partition dt=9-27
OK
Time taken: 0.429 seconds
hive> select * from day_table;
OK
day_table.id day_table.content day_table.dt
1 abc 9-26
2 bcd 9-26
Time taken: 0.098 seconds, Fetched: 2 row(s)
hive>
多分区表:
多分区表就是根据多个字段进行分区,比如又两个分区:dt和hour,数据是首先根据dt来分区,如果dt相同,就根据hour来进行分区。
创建多分区表:
create table day_hour_table (id int, content string) partitioned by (dt int,hour int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
插入数据
insert into day_hour_table partition(dt=9,hour=1) values(1,"a2 bc");
insert into day_hour_table partition(dt=9,hour=2) values(3,"a2 bc");
insert into day_hour_table partition(dt=8,hour=1) values(3,"a2 bc");
insert into day_hour_table partition(dt=8,hour=2) values(3,"a2 bc");
查询结果:
hive> select * from day_hour_table;
OK
day_hour_table.id day_hour_table.content day_hour_table.dt day_hour_table.hour
3 a2 bc 8 1
3 a2 bc 8 2
1 a2 bc 9 1
3 a2 bc 9 2
Time taken: 0.1 seconds, Fetched: 4 row(s)
hive>
从结果可以看出插入的四条数据一共有两个大分区(dt=8分区和dt=9分区),每个大的分区又分别有两个小分区(dt=8:hour=1,hour=2;dt=9:hour=1,hour=2)
load批量插入的方式往分区表中插入数据:
load data local inpath "/root/ceshi" into table day_table partition (dt=10,hour=10);
执行结果:
hive> load data local inpath "/root/ceshi" into table day_hour_table partition (dt=10,hour=10);
Loading data to table test.day_hour_table partition (dt=10, hour=10)
Partition test.day_hour_table{dt=10, hour=10} stats: [numFiles=1, numRows=0, totalSize=37, rawDataSize=0]
OK
Time taken: 0.4 seconds
hive> select * from day_hour_table;
OK
day_hour_table.id day_hour_table.content day_hour_table.dt day_hour_table.hour
5 hahaha 10 10
6 hehehe 10 10
7 heihei 10 10
8 hiahia 10 10
NULL NULL 10 10
3 a2 bc 8 1
3 a2 bc 8 2
1 a2 bc 9 1
3 a2 bc 9 2
Time taken: 0.124 seconds, Fetched: 9 row(s)
hive>
根据分区号查询数据:
hive> select * from day_hour_table where dt = 10;
OK
day_hour_table.id day_hour_table.content day_hour_table.dt day_hour_table.hour
5 hahaha 10 10
6 hehehe 10 10
7 heihei 10 10
8 hiahia 10 10
NULL NULL 10 10
Time taken: 0.125 seconds, Fetched: 5 row(s)
hive> select * from day_hour_table where dt = 8 and hour = 1 ;
OK
day_hour_table.id day_hour_table.content day_hour_table.dt day_hour_table.hour
3 a2 bc 8 1
Time taken: 0.269 seconds, Fetched: 1 row(s)
hive>
根据分区号删除数据:
ALTER TABLE day_table DROP PARTITION (dt=10,hour=10);
hive> ALTER TABLE day_hour_table DROP PARTITION (dt=10,hour=10);
Dropped the partition dt=10/hour=10
OK
Time taken: 0.223 seconds
hive> select * from day_hour_table;
OK
day_hour_table.id day_hour_table.content day_hour_table.dt day_hour_table.hour
3 a2 bc 8 1
3 a2 bc 8 2
1 a2 bc 9 1
3 a2 bc 9 2
Time taken: 0.106 seconds, Fetched: 4 row(s)
hive>
创建\添加分区
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION ‘location’][, PARTITION partition_spec [LOCATION ‘location’], …];
创建一个空分区:
ALTER TABLE day_hour_table ADD PARTITION (dt=10000, hour=2000);
hive> ALTER TABLE day_hour_table ADD PARTITION (dt=10000, hour=2000);
OK
Time taken: 0.689 seconds
hive> select * from day_hour_table;
OK
3 a2 bc 8 1
3 a2 bc 8 2
1 a2 bc 9 1
3 a2 bc 9 2
Time taken: 1.48 seconds, Fetched: 4 row(s)
然后将数据上传到空分区对应的目录下,分区表中就会显示数据:
[root@client ~]# cat ceshi
5 hahaha
6 hehehe
7 heihei
8 hiahia
[root@client ~]# hdfs dfs -put ceshi /user/hive/warehouse/test.db/day_hour_table/dt=10000/hour=2000
[root@client ~]#
hive> select * from day_hour_table;
OK
5 hahaha 10000 2000
6 hehehe 10000 2000
7 heihei 10000 2000
8 hiahia 10000 2000
NULL NULL 10000 2000
3 a2 bc 8 1
3 a2 bc 8 2
1 a2 bc 9 1
3 a2 bc 9 2
Time taken: 0.186 seconds, Fetched: 9 row(s)
hive>
创建一个空分区并且将空分区指向数据位置:
ALTER TABLE day_hour_table ADD PARTITION (dt=10000, hour=2000) location "/test"
总结:往分区中添加数据有四种方式:
(1)insert 指定分区
(2)load data 指定分区
(3)查询已有表的数据,insert到新表中
from day_hour_table insert into table newt partition(dt=01,hour=9898) select id,content
(4)alter table add partition创建空分区,然后使用HDFS命令往空分区目录中上传数据
(5)创建分区,并且指定分区数据的位置
动态分区表
相对于静态分区表,动态分区表的插入数据要简单得多,因为不需要手动指定分区,在插入数据的时候hive自动根据字段名进行分区。 (注意:插入数据指的是from insert 方式插入,而不是使用load data方式加载数据到表中,后面会解释)
在创建分区表之前首先得执行下面两条命令:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
第一条命令是开启动态分区,第二条命令是将开启非严格模式:
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nostrict;
hive>
静态分区表中,一个文件数据只能导入到某一个分区中,并且分区是用户指定的,这种方式不够灵活,业务场景比较局限。假设有如下数据:
001 mozhaojian man 10 Angelababy,Dilireba,zhangxinyi Angelababy:qingdao,Dilireba:xinjiang,zhangxinyi:haibuzhidao zhongguo,shandong,qingdao
002 mozhaojian2 female 20 fengjie,yujie fengjie:American,yujie:长沙 zhongguo,shandong,qingdao
003 mozhaojian3 female 30 fengjie,yujie fengjie:American,yujie:长沙 zhongguo,shandong,qingdao
动态分区可以根据数据本身的特征自动来划分分区,比如我们可以指定按照数据中的年龄、性别来动态分区,会产出3个不同的分区
male 10
001 mozhaojian male 10 Angelababy,Dilireba,zhangxinyi Angelababy:qingdao,Dilireba:xinjiang,zhangxinyi:haibuzhidao zhongguo,shandong,qingdao
female 20
002 mozhaojian2 female 20 fengjie,yujie fengjie:American,yujie:长沙 zhongguo,shandong,qingdao
female 30
003 mozhaojian3 female 30 fengjie,yujie fengjie:American,yujie:长沙 zhongguo,shandong,qingda
下面创建动态分区表,静态分区与动态分区创建表的语句是一模一样的:
CREATE TABLE gfstbl_dynamic(
id INT,
name STRING,
gfs ARRAY<STRING>,
address MAP<STRING,STRING>,
info STRUCT<country:String,province:String,city:String>
)
partitioned by (sex string,age INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
执行结果
hive> CREATE TABLE gfstbl_dynamic(
> id INT,
> name STRING,
> gfs ARRAY<STRING>,
> address MAP<STRING,STRING>,
> info STRUCT<country:String,province:String,city:String>
> )
> partitioned by (sex string,age INT)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ' '
> COLLECTION ITEMS TERMINATED BY ','
> MAP KEYS TERMINATED BY ':'
> LINES TERMINATED BY '\n';
OK
Time taken: 0.848 second
动态分区表gfstbl_dynamic创建好了之后怎么往表中插入数据呢?
前面说了插入数据不能用load data方式? 是因为这种方式只是将数据上传到HDFS指定目录中,我们之前使用load data往分区表导入数据的时候,都是要指定partition分区的,这样他才会知道将数据上传到HDFS的哪一个分区。
但是如果我们还是采用load data指定分区的话,那就不是动态分区表,还依然是静态分区表所以得采用 from insert的方式插入数据。
创建一张普通的非分区表:
CREATE TABLE gfstbl_pt(
id INT,
name STRING,
sex string,
age INT,
gfs ARRAY<STRING>,
address MAP<STRING,STRING>,
info STRUCT<country:String,province:String,city:String>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
执行结果:
hive> CREATE TABLE gfstbl_pt(
> id INT,
> name STRING,
> sex string,
> age INT,
> gfs ARRAY<STRING>,
> address MAP<STRING,STRING>,
> info STRUCT<country:String,province:String,city:String>
> )
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ' '
> COLLECTION ITEMS TERMINATED BY ','
> MAP KEYS TERMINATED BY ':'
> LINES TERMINATED BY '\n';
OK
Time taken: 0.151 seconds
加载数据到普通表gfstbl_pt中,创建数据:
[root@client ~]# cat gfsDynamic
001 mozhaojian man 10 Angelababy,Dilireba,zhangxinyi Angelababy:qingdao,Dilireba:xinjiang,zhangxinyi:haibuzhidao zhongguo,shandong,qingdao
002 mozhaojian2 female 20 fengjie,yujie fengjie:American,yujie:长沙 zhongguo,shandong,qingdao
003 mozhaojian3 female 30 fengjie,yujie fengjie:American,yujie:长沙 zhongguo,shandong,qingdao
[root@client ~]#
加载数据:
hive> load data local inpath "/root/gfsDynamic" into table gfstbl_pt;
Loading data to table test.gfstbl_pt
Table test.gfstbl_pt stats: [numFiles=1, totalSize=331]
OK
Time taken: 3.082 seconds
hive> select * from gfstbl_pt;
OK
1 mozhaojian man 10 ["Angelababy","Dilireba","zhangxinyi"] {"Angelababy":"qingdao","Dilireba":"xinjiang","zhangxinyi":"haibuzhidao"} {"country":"zhongguo","province":"shandong","city":"qingdao"}
2 mozhaojian2 female 20 ["fengjie","yujie"] {"fengjie":"American","yujie":"长沙"} {"country":"zhongguo","province":"shandong","city":"qingdao"}
3 mozhaojian3 female 30 ["fengjie","yujie"] {"fengjie":"American","yujie":"长沙"} {"country":"zhongguo","province":"shandong","city":"qingdao"}
Time taken: 0.769 seconds, Fetched: 3 row(s)
hive>
采用 from insert的方式插入数据:
from gfstbl_pt
insert into gfstbl_dynamic partition(sex,age)
select id,name,gfs,address,info,sex,age
插入完成后查询数据并查看分区:
hive> select * from gfstbl_dynamic;
OK
2 mozhaojian2 ["fengjie","yujie"] {"fengjie":"American","yujie":"长沙"} {"country":"zhongguo","province":"shandong","city":"qingdao"} female 20
3 mozhaojian3 ["fengjie","yujie"] {"fengjie":"American","yujie":"长沙"} {"country":"zhongguo","province":"shandong","city":"qingdao"} female 30
1 mozhaojian ["Angelababy","Dilireba","zhangxinyi"] {"Angelababy":"qingdao","Dilireba":"xinjiang","zhangxinyi":"haibuzhidao"} {"country":"zhongguo","province":"shandong","city":"qingdao"} man 10
Time taken: 0.465 seconds, Fetched: 3 row(s)
hive> show partitions gfstbl_dynamic;
OK
sex=female/age=20
sex=female/age=30
sex=man/age=10
Time taken: 0.131 seconds, Fetched: 3 row(s)
hive>
我们可以看到根据sex和age分了三个区。
分桶表
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中对于hive中每一个表、分区都可以进一步进行分桶。
创建分桶表之前首先得开启分桶:
set hive.enforce.bucketing=true;
执行:
hive> set hive.enforce.bucketing=true;
创建样例数据:
[root@client ~]# cat bucketData
1,tom,11,189
2,cat,22,189
3,dog,33,189
4,hive,44,189
5,hbase,55,189
6,mr,66,188
7,alice,77,188
8,scala,88,188
[root@client ~]#
创建原始表:
CREATE TABLE original( id INT, name STRING, age INT,height DOUBLE)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
加载数据到原始表中( LOAD DATA LOCAL INPATH “/root/bucketData” into table original;):
hive> LOAD DATA LOCAL INPATH "/root/bucketData" into table original;
Loading data to table test.original
Table test.original stats: [numFiles=1, totalSize=110]
OK
Time taken: 0.353 seconds
hive> select * from original;
OK
1 tom 11 189.0
2 cat 22 189.0
3 dog 33 189.0
4 hive 44 189.0
5 hbase 55 189.0
6 mr 66 188.0
7 alice 77 188.0
8 scala 88 188.0
Time taken: 0.129 seconds, Fetched: 8 row(s)
创建分桶表:
CREATE TABLE psnbucket( id INT, name STRING, age INT)
CLUSTERED BY (age) INTO 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
插入数据:
insert into table psnbucket select id, name, age from original;
查看分桶表中的数据:
hive> select * from psnbucket;
OK
8 scala 88
4 hive 44
7 alice 77
3 dog 33
6 mr 66
2 cat 22
5 hbase 55
1 tom 11
从分桶表中的数据可以分析出:8 scala 88,4 hive 44这两条记录在一个桶中,因为我们在创建分桶表的时候根据id指定了四个分桶,88%4=44%4,所以这两条记录在同一个桶中,后面的6条记录同理。
分桶表的作用:
1、可以提高两个分桶表join的效率,前提是两个分桶表的桶数相同,并且两个分桶表的都是根据同一字段进行分桶的。这样,在join的时候,只需根据桶号进行将桶中的数据join即可,而不用对全表进行笛卡儿积了,这样大大地提高了join的效率。
2、随机抽样:select * from bucket_table tablesample(bucket 1 out of 4 on columns);
TABLESAMPLE语法:
TABLESAMPLE(BUCKET x OUT OF y)
x:表示从哪个bucket开始抽取数据
y:必须为该表总bucket数的倍数或因子
例:
当表总bucket数为32时
TABLESAMPLE(BUCKET 3 OUT OF 8),抽取哪些数据?
共抽取4(32/8)个bucket的数据,抽取第3、11、19、27个bucket的数据
结合刚才的分桶表psnbucket,一共有4个桶,表中数据:
hive> select * from psnbucket;
OK
8 scala 88
4 hive 44
7 alice 77
3 dog 33
6 mr 66
2 cat 22
5 hbase 55
1 tom 11
执行select * from psnbucket tablesample(bucket 2 out of 4 on age);
TABLESAMPLE(bucket 2 out of 4 on age)共抽取4/4=1个bucket的数据,从2号桶开始抽取:
hive> select * from psnbucket tablesample(bucket 2 out of 4 on age);
OK
7 alice 77
3 dog 33
Time taken: 0.199 seconds, Fetched: 2 row(s)
select * from psnbucket tablesample(bucket 1 out of 2 on age);
TABLESAMPLE(bucket 1 out of 2 on age)共抽取4/2=2个bucket的数据,从1号桶开始抽取:
hive> select * from psnbucket tablesample(bucket 1 out of 2 on age);
OK
8 scala 88
4 hive 44
6 mr 66
2 cat 22
Time taken: 0.075 seconds, Fetched: 4 row(s)














 1732
1732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









