



PIR被动红外传感器检测空间范围高清示意图
- 基于真实菲涅尔透镜结构的3D可视化 | 多视角展示
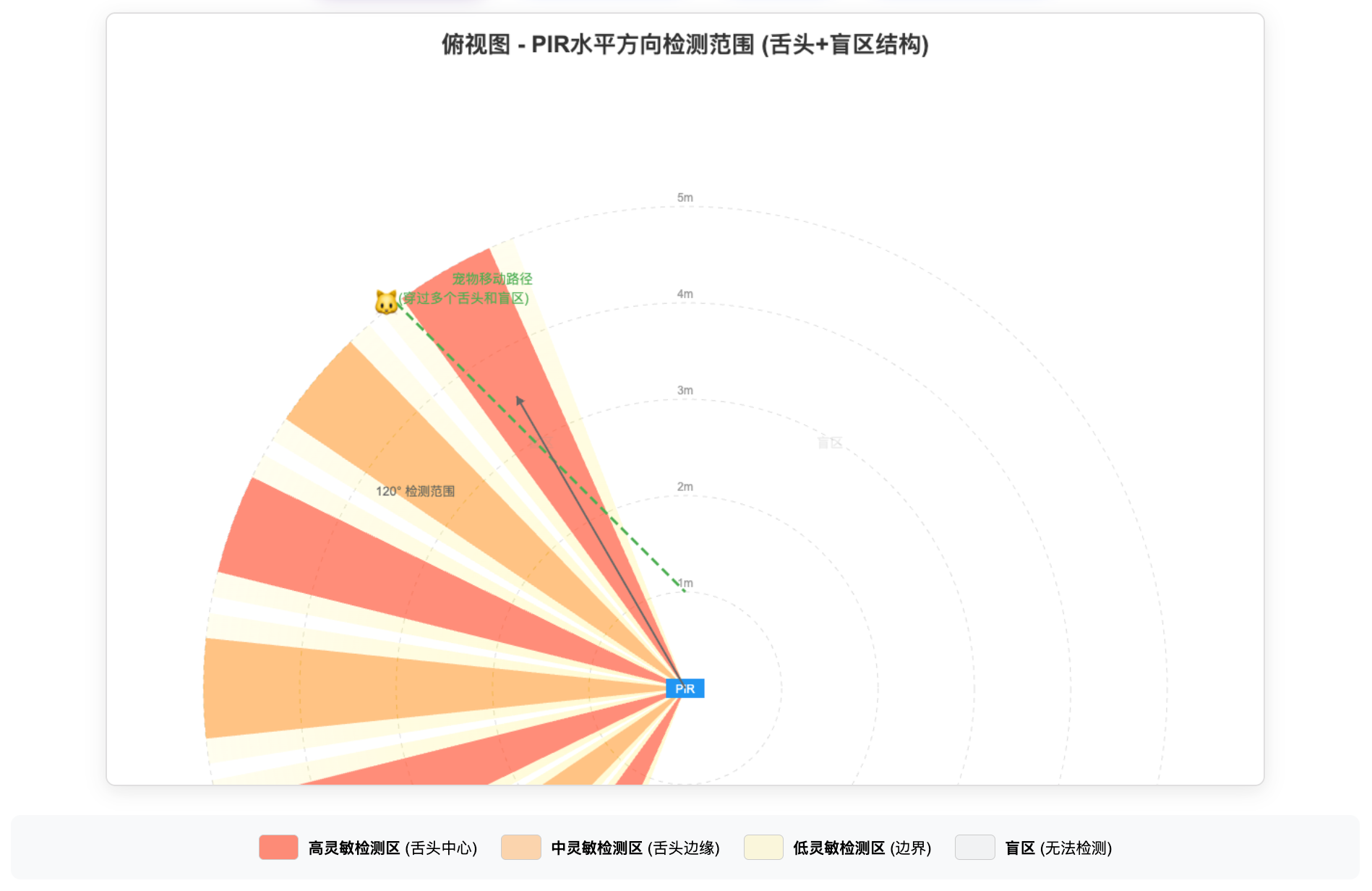
俯视图 (水平方向)
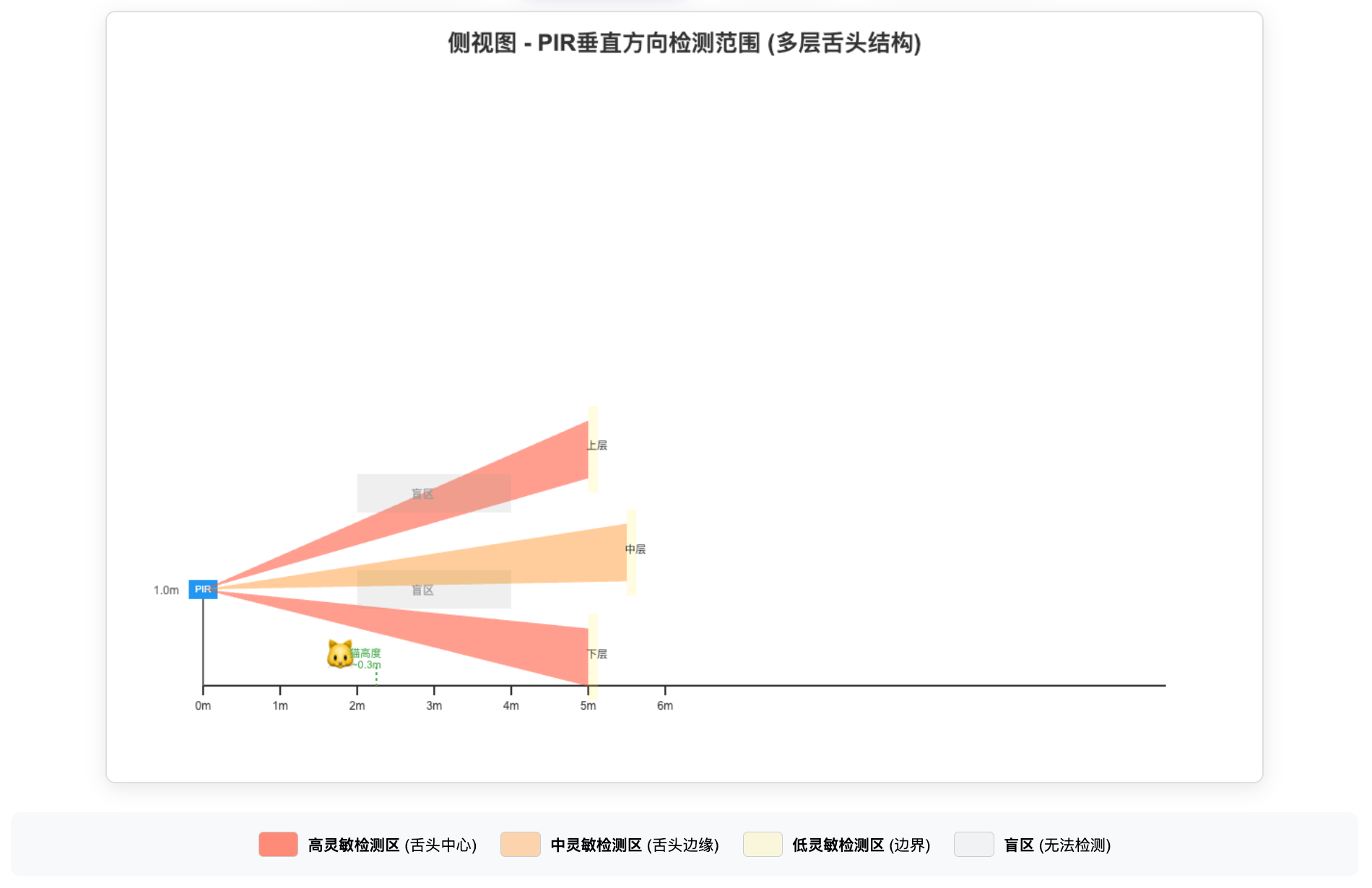
侧视图 (垂直方向)
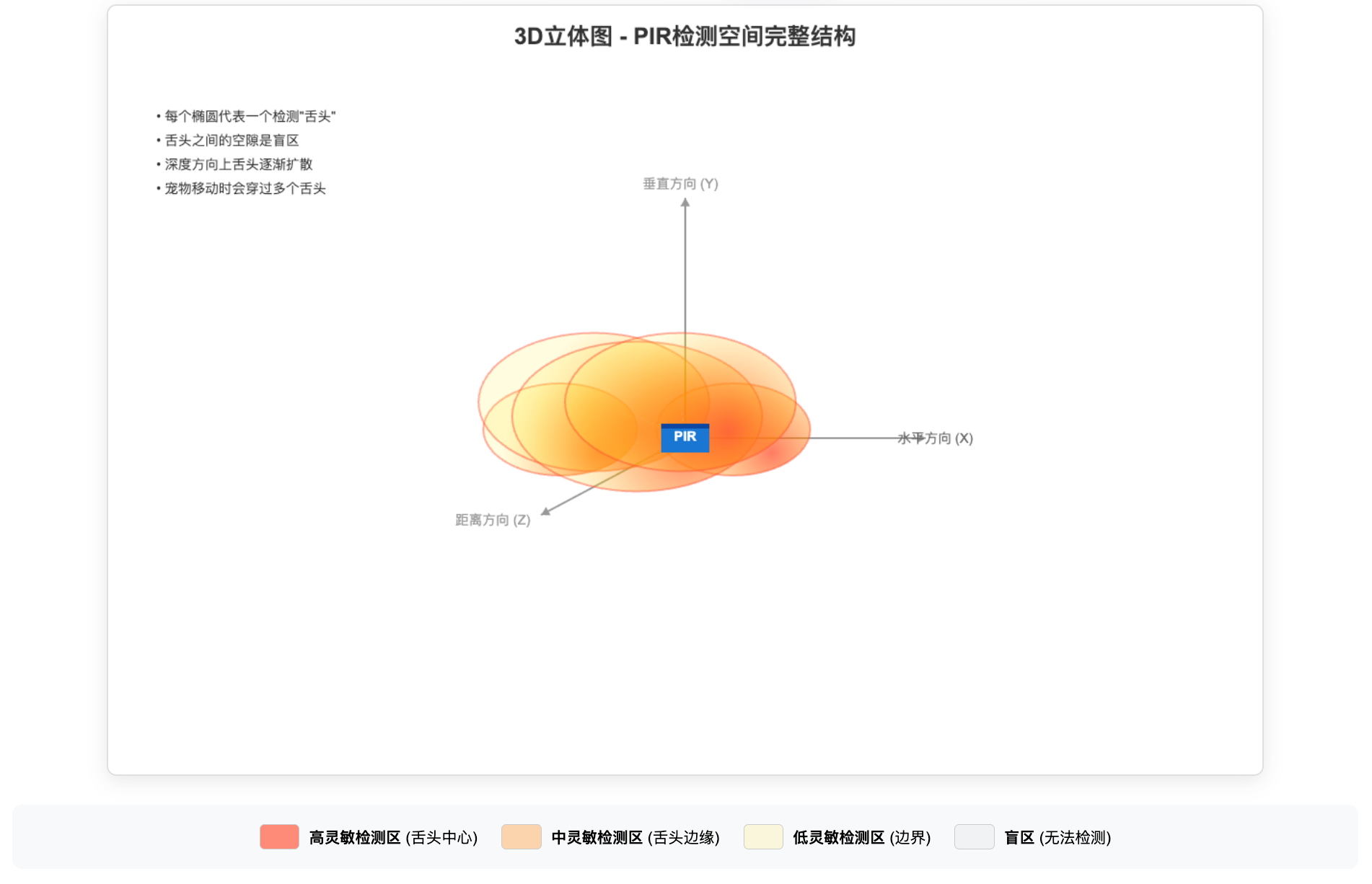
3D立体图
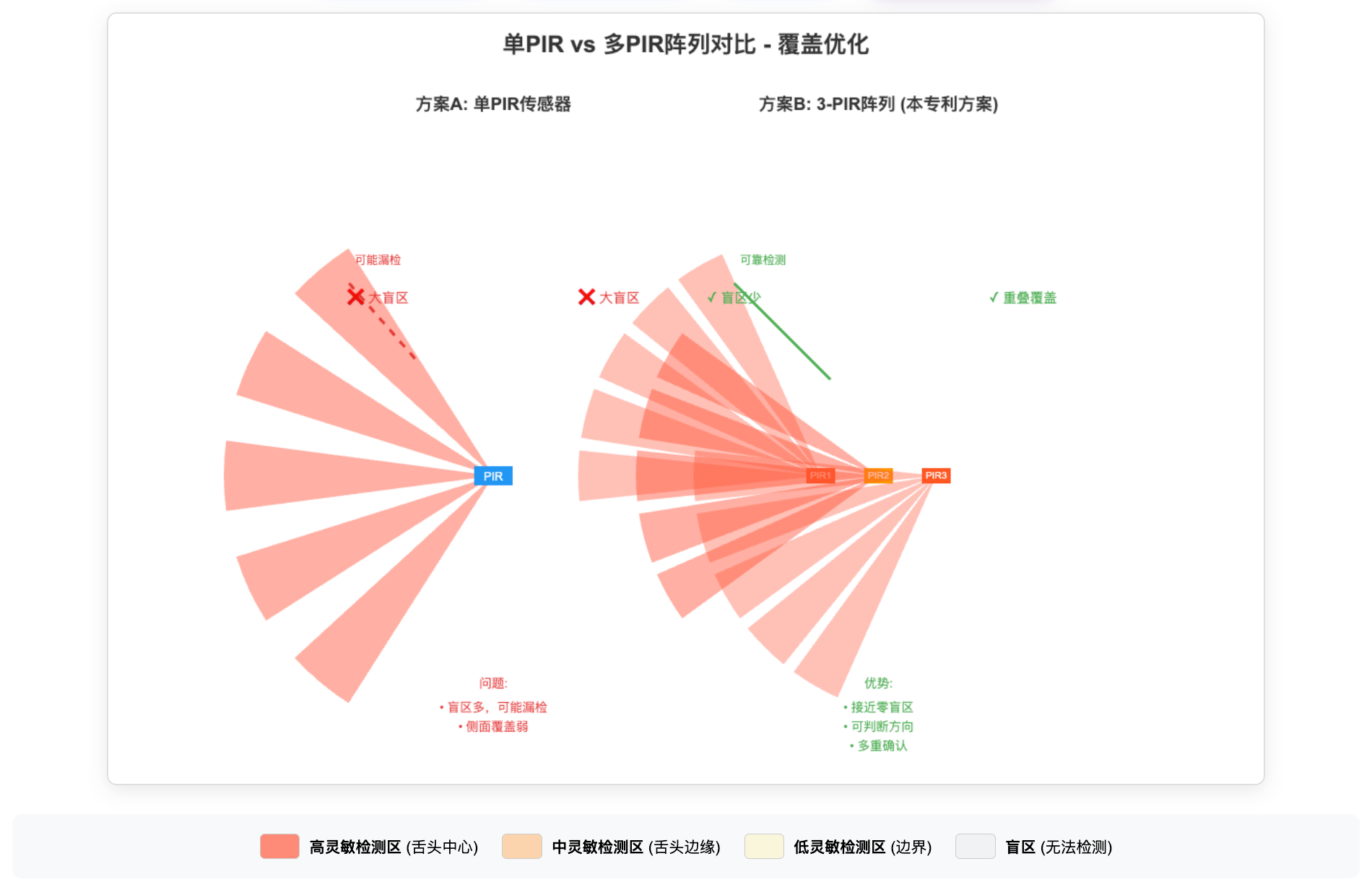
单PIR vs 多PIR对比
检测参数
📐 水平检测角度
典型范围:90° - 120°
窄角型:60° - 90°
宽角型:120° - 180°
📏 垂直检测角度
典型范围:60° - 90°
幕帘型:15° - 30°
半球型:90° - 110°
📍 检测距离
最小距离:0.5m - 1m
最大距离:5m - 12m
最佳距离:2m - 5m
🎯 检测区数量
标准型:6-12个扇区
精密型:16-24个扇区
每个扇区宽度:8° - 15°
💡 关键技术特点
1. 多舌头结构:PIR通过菲涅尔透镜将探测区域分成多个独立的扇形"舌头",每个舌头之间存在盲区。
2. 运动检测原理:物体移动时会依次穿过多个检测区和盲区,产生连续的脉冲信号,这是判断有效移动的关键特征。
3. 距离特性:距离越远,舌头之间的盲区越宽;距离越近,检测更密集。
4. 应用优势:适合"只检测移动"的应用场景,自动过滤静止物体的误触发。

















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









