








本文字数:9454;估计阅读时间:24 分钟
审校:大平
我们非常激动地分享在23.10版本中的一系列令人惊叹的功能。
发布概要:
- 新增23个新功能
- 实现了26项性能优化
- 修复了60处bug
以下是一小部分突出的功能... 但是此版本包含新的 SHOW MERGES 和SHOW SETTINGS 命令,新的 byteSwap、arrayRandomSample、jsonMergePatch、formatQuery、formatQuerySingleLine函数,argMin 和 argMax作为组合器,带有分区的参数化 ALTER 命令,具有更好名称的 untuple 函数,强制执行投影,允许没有主键的表,还有更多。
新的贡献者
和往常一样,我们向23.10中的所有新贡献者表示热烈欢迎!ClickHouse的流行在很大程度上要归功于社区的努力。看到社区不断壮大总是令人敬畏的。
如果你在这里看到自己的名字,请与我们联系...但我们也会在Twitter等地找到你。
AN, Aleksa Cukovic, Alexander Nikolaev, Avery Fischer, Daniel Byta, Dorota Szeremeta, Ethan Shea, FFish, Gabriel Archer, Itay Israelov, Jens Hoevenaars, Jihyuk Bok, Joey Wang, Johnny, Joris Clement, Lirikl, Max K, Priyansh Agrawal, Sinan, Srikanth Chekuri, Stas Morozov, Vlad Seliverstov, bhavuk2002, guoxiaolong, huzhicheng, monchickey, pdy, wxybear, yokofly
最大三角形三桶(Largest Triangle Three Buckets)
由Sinan贡献
最大三角形三桶是一种降采样数据以便更容易进行可视化的算法。它试图保留初始数据的视觉相似性,同时减少点的数量。特别是,它似乎非常擅长保留局部极小值和极大值,这在其他降采样方法中经常丢失。
我们将通过Kaggle SF Bay Area Bike Share数据集来看看它是如何工作的,该数据集包含一个跟踪在每分钟的每个站点里可用停车位数量的CSV文件。
让我们创建一个数据库:
CREATE DATABASE BikeShare;
USE BikeShare;然后创建一个名为status的表,由status.csv文件填充:
create table status engine MergeTree order by (station_id, time) AS
from file('Bay Area Bikes.zip :: status.csv', CSVWithNames)
SELECT *
SETTINGS schema_inference_make_columns_nullable=0;
SELECT formatReadableQuantity(count(*))
FROM status
┌─formatReadableQuantity(count())─┐
│ 71.98 million │
└─────────────────────────────────┘原始数据
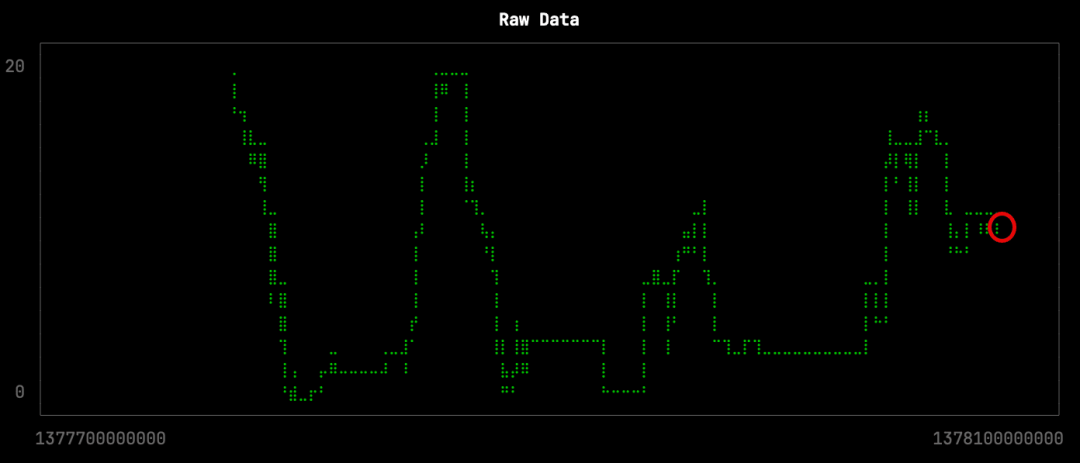
首先,让我们看一下某个站点在几天内的原始数据。以下查询返回4,537个点,存储在raw.sql文件中:
from BikeShare.status select toUnixTimestamp64Milli(time), docks_available
where toDate(time) >= '2013-08-29' and toDate(time) <= '2013-09-01'
and station_id = 70
FORMAT CSV我们可以通过运行以下查询来可视化随时间变化的可用停车位:
clickhouse local --path bikeshare.chdb < raw.sql |
uplot line -d, -w 100 -t "Raw Data"
接下来,我们将看看:如果我们将点的数量减少大约10倍会发生什么,我们可以通过对10分钟的时间段内的点进行平均来实现。这个查询将存储在avg.sql文件中,如下所示:
WITH buckets AS (
SELECT
toStartOfInterval(time, INTERVAL 10 minute) AS bucket,
AVG(docks_available) AS average_docks_available,
AVG(toUnixTimestamp64Milli(time)) AS average_bucket_time
FROM BikeShare.status
where toDate(time) >= '2013-08-29' and toDate(time) <= '2013-09-01'
AND (station_id = 70)
GROUP BY bucket
ORDER BY bucket
)
SELECT average_bucket_time, average_docks_available
FROM buckets
FORMAT CSV我们可以这样生成可视化:
clickhouse local --path bikeshare.chdb < avg.sql |
uplot line -d, -w 100 -t "Average every 5 mins"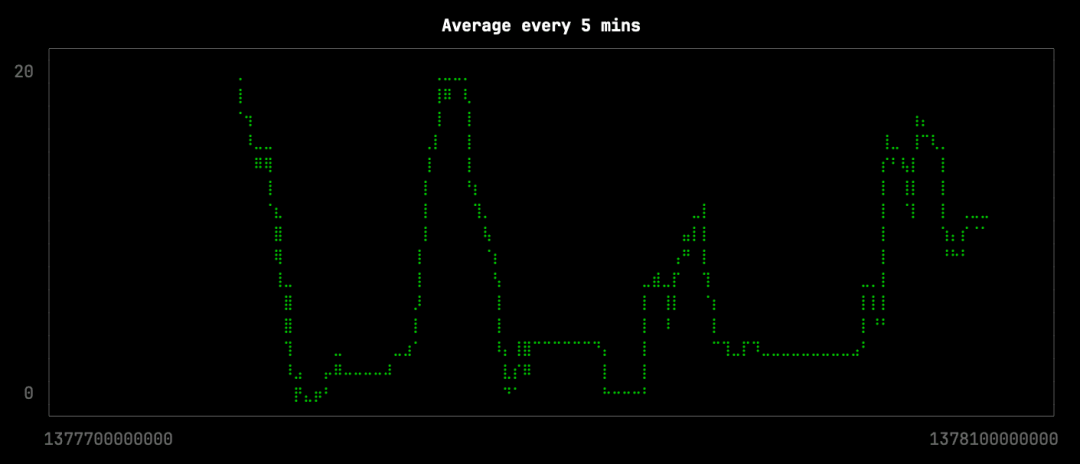
这种降采样效果并不太差,但它失去了曲线形状中一些更微妙的变化。在原始数据可视化中,缺失的变化用红色圈出:

让我们看看Largest Triangle Three Buckets算法的效果。查询(lttb.sql)如下所示:
from BikeShare.status
select untuple(arrayJoin(
largestTriangleThreeBuckets(50)(
toUnixTimestamp64Milli(time), docks_available
)))
where toDate(time) >= '2013-08-29' and toDate(time) <= '2013-09-01' AND station_id = 70
FORMAT CSV然后我们可以生成这样的可视化:
clickhouse local --path bikeshare.chdb < lttb.sql |
uplot line -d, -w 100 -t "Largest Triangle Three Buckets"
从视觉检查来看,这个可视化版本只缺少以下本地最小值:
arrayFold
由Lirikl贡献
ClickHouse提供了带有许多扩展和强大改进的SQL,使其更适合用于分析任务。ClickHouse SQL的一个示例是对数组的广泛支持。数组在其他编程语言(如Python和JavaScript)的用户中是众所周知的。它们通常用于以一种简洁而直接的方式,对各种问题进行建模和求解。ClickHouse有超过70个用于处理数组的函数,其中许多函数都是高阶函数,提供了很高的抽象水平,使您能够以简洁和声明性的方式表达,满足对数组进行复杂操作的需求。我们自豪地宣布,这个数组函数家族现在有了一个新的、期待已久的、最强大的成员:arrayFold。
arrayFold等效于JavaScript中的Array.reduce函数,用于通过在累积方式下将lambda函数应用于数组元素,从而从左到右折叠或减少数组中的元素,从最左侧的元素开始,并在处理每个元素时累积结果。这个累积过程可以被认为是将数组元素一起 folding。
以下是一个简单的例子,我们在其中使用 arrayFold 来计算数组 [10, 20, 30] 的所有元素的总和:
SELECT arrayFold((acc, v) -> (acc + v), [10, 20, 30], 0::UInt64) AS sum
┌─sum─┐
│ 60 │
└─────┘请注意,在上述 arrayFold 的示例调用中,我们传递了一个lambda函数 (acc, v) -> (acc + v) 和一个初始累加器值 0。
然后,lambda函数被调用,其中 acc 设置为初始累加器值 0,v 设置为第一个(最左侧)数组元素 10。接下来,lambda函数被调用,其中 acc 设置为前一步的结果,v 设置为第二个数组元素 20。这个过程继续进行,从左到右迭代地折叠数组元素,直到达到数组的末尾,产生最终结果 60。
这个图表展示了我们lambda函数体中的 + 运算符如何在每个迭代步骤中累积应用于初始累加器和所有从左到右的数组元素:

我们只是用上面的例子作为介绍。我们本可以使用arraySum或arrayReduce(sum)来计算所有数组元素的总和。但 arrayFold 更为强大。它是ClickHouse数组函数家族中最通用和灵活的成员之一,可用于执行各种数组操作,如聚合、过滤、映射、分组以及更复杂的任务。
提供自定义折叠函数(lambda函数形式)以及在每个迭代步骤中保持、检查和塑造折叠状态(累加器)的可能性是一种强大的组合,可以用简洁且可组合的方式,进行复杂的数据处理。我们通过一个更复杂的示例进行演示。大约一年前,我们向社区提出了一个问题,要求其构建一个能重现 git blame 命令的查询,并会给第一个提出解决方案的人快递一件T恤。我们甚至提到:
“从提交历史中重建这个命令特别具有挑战性 - 尤其是因为ClickHouse目前没有一个能够以当前状态迭代的arrayFold函数。”
现在,你有机会赢得T恤 🤗
以下是一个相关且简化的例子,模拟了一个由ClickHouse驱动的文本编辑器,提供无限的时间/版本旅行,我们仅存储每行的更改,并利用 arrayFold 轻松重建每个版本(或时间点)的完整文本。
我们创建用于存储行更改历史记录的表(对于每个版本,我们还可以使用DateTime字段来跟踪更改的时间):
CREATE OR REPLACE TABLE line_changes
(
version UInt32,
line_change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3),
line_number UInt32,
line_content String
)
ENGINE = MergeTree
ORDER BY time;我们存储了一份行的更改历史:
INSERT INTO default.line_changes VALUES
(1, 'Add' , 1, 'ClickHouse provides SQL'),
(2, 'Add' , 2, 'with improvements'),
(3, 'Add' , 3, 'that makes it more friendly for analytical tasks.'),
(4, 'Add' , 2, 'with many extensions'),
(5, 'Modify', 3, 'and powerful improvements'),
(6, 'Delete', 1, ''),
(7, 'Add' , 1, 'ClickHouse provides a superset of SQL');我们创建了三个用于操作数组内容的用户定义函数(我们仅出于可读性考虑创建了这些UDF;或者,我们可以将它们的主体嵌入到下面的主查询中):
-- add a string (str) into an array (arr) at a specific position (pos)
CREATE OR REPLACE FUNCTION add AS (arr, pos, str) ->
arrayConcat(arraySlice(arr, 1, pos-1), [str], arraySlice(arr, pos));
-- delete the element at a specific position (pos) from an array (arr)
CREATE OR REPLACE FUNCTION delete AS (arr, pos) ->
arrayConcat(arraySlice(arr, 1, pos-1), arraySlice(arr, pos+1));
-- replace the element at a specific position (pos) in an array (arr)
CREATE OR REPLACE FUNCTION modify AS (arr, pos, str) ->
arrayConcat(arraySlice(arr, 1, pos-1), [str], arraySlice(arr, pos+1));我们创建了一个使用 arrayFold 的参数化视图的主查询:
CREATE OR REPLACE VIEW text_version AS
WITH T1 AS (
SELECT arrayZip(
groupArray(line_change_type),
groupArray(line_number),
groupArray(line_content)) as line_ops
FROM (SELECT * FROM line_changes
WHERE version <= {version:UInt32} ORDER BY version ASC)
)
SELECT arrayJoin(
arrayFold((acc, v) ->
if(v.'change_type' = 'Add', add(acc, v.'line_nr', v.'content'),
if(v.'change_type' = 'Delete', delete(acc, v.'line_nr'),
if(v.'change_type' = 'Modify', modify(acc, v.'line_nr', v.'content'), []))),
line_ops::Array(Tuple(change_type String, line_nr UInt32, content String)),
[]::Array(String))) as lines
FROM T1;我们穿越文本的各个版本:
SELECT * FROM text_version(version = 2);
┌─lines─────────────────────────────────────────────┐
│ ClickHouse provides SQL │
│ that makes it more friendly for analytical tasks. │
└───────────────────────────────────────────────────┘
SELECT * FROM text_version(version = 3);
┌─lines─────────────────────────────────────────────┐
│ ClickHouse provides SQL │
│ with improvements │
│ that makes it more friendly for analytical tasks. │
└───────────────────────────────────────────────────┘
SELECT * FROM text_version(version = 7);
┌─lines─────────────────────────────────────────────┐
│ ClickHouse provides a superset of SQL │
│ with many extensions │
│ and powerful improvements │
│ that makes it more friendly for analytical tasks. │
└───────────────────────────────────────────────────┘在上面的主查询中,我们使用了ClickHouse中的一个典型设计模式,即使用groupArray聚合函数将表的特定行值(暂时)转换为数组。然后,可以通过数组函数方便地进行处理,并通过arrayJoin聚合函数将结果转换回各个表行。请注意,我们如何利用 arrayFold 来累积重建文本版本,从一个空数组作为初始累加器值开始,并使用累加器数组内的位置表示行号。
导入Numpy数组
由Yarik Briukhovetskyi贡献
今年早些时候,曾在一个系列的共两部分的博客里,我们探讨了ClickHouse对矢量的支持。作为其中的一部分,我们将来自LAION数据集的超过20亿个矢量,及其相应的元数据加载到了ClickHouse中。该数据集包含了超过20亿个图像,及其标题的矢量嵌入,是从分布式爬取中收集的。这些嵌入是使用多模型生成的,允许用户通过文本搜索图像,反之亦然。
这些矢量以 npy 格式的Numpy数组分布在流行的平台HuggingFace上。每个矢量还有相应的元数据,以Parquet文件的格式存储,其中包含标题、图像的高度或宽度以及图像和文本之间的相似性分数等属性。
为了在当时将这些数据插入ClickHouse,我们不得不编写Python代码将 npy 文件与Parquet文件合并,目的是将所有列合并到一个表中。虽然ClickHouse对Parquet有很好的支持,但不支持 npy 格式。为了增加难度,npy 文件只设计为包含浮点数数组。因此,数据集的连接需要基于行位置完成。虽然Python方法足够,并且可以很容易地并行化处理超过2300组文件的合并,但当我们不能只用ClickHouse本地方法解决问题时,我们总是感到沮丧!这个特定的问题对于其他Hugging Face数据集也很常见,这些数据集包含嵌入和元数据。因此,希望以轻量级、无代码的方式将这些数据加载到ClickHouse。
在23.10中,ClickHouse现在支持 npy 文件,使我们能够重新审视这个问题。
对于LAION数据集,文件以四位数字后缀编号,例如text_emb_0023.npy,metadata_0023.parquet,具有共同的后缀表示一个子集。对于每个子集,我们有3个文件:一个用于图像嵌入的 npy 文件,一个用于文本嵌入的文件,以及一个Parquet元数据文件。
SELECT array AS text_emb
FROM file('input/text_emb/text_emb_0000.npy')
LIMIT 1
FORMAT Vertical
Row 1:
──────
text_emb: [-0.0126877,0.0196686,..,0.0177155,0.00206757]
1 row in set. Elapsed: 0.001 sec.
SELECT *
FROM file('input/metadata/metadata_0000.parquet')
LIMIT 1
FORMAT Vertical
SETTINGS input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference = 1
Row 1:
──────
image_path: 185120009
caption: Color version PULP FICTION alternative poster art
NSFW: UNLIKELY
similarity: 0.33966901898384094
LICENSE: ?
url: http://cdn.shopify.com/s/files/1/0282/0804/products/pulp_1024x1024.jpg?v=1474264437
key: 185120009
status: success
width: 384
height: 512
original_width: 768
original_height: 1024
exif: {"Image Orientation": "Horizontal (normal)", "Image XResolution": "100", "Image YResolution": "100", "Image ResolutionUnit": "Pixels/Inch", "Image YCbCrPositioning": "Centered", "Image ExifOffset": "102", "EXIF ExifVersion": "0210", "EXIF ComponentsConfiguration": "YCbCr", "EXIF FlashPixVersion": "0100", "EXIF ColorSpace": "Uncalibrated", "EXIF ExifImageWidth": "768", "EXIF ExifImageLength": "1024"}
md5: 46c4bbab739a2b71639fb5a3a4035b36
1 row in set. Elapsed: 0.167 sec.ClickHouse文件读取和查询执行在性能上高度并行化。无序读取通常是必不可少的,以实现快速解析和读取。然而,为了连接这些数据集,我们需要确保所有文件按顺序读取,以便允许按行号连接。因此,我们需要使用max_threads=1。窗口函数 row_number() OVER () AS rn 为我们提供了一个行号,我们可以在其上连接我们的数据集。因此,我们的查询以替代自定义Python脚本的方式为:
INSERT INTO FUNCTION file('0000.parquet')
SELECT *
FROM
(
SELECT
row_number() OVER () AS rn,
*
FROM file('input/metadata/metadata_0000.parquet')
) AS metadata
INNER JOIN
(
SELECT *
FROM
(
SELECT
row_number() OVER () AS rn,
array AS text_emb
FROM file('input/text_emb/text_emb_0000.npy')
) AS text_emb
INNER JOIN
(
SELECT
row_number() OVER () AS rn,
array AS img_emd
FROM file('input/img_emb/img_emb_0000.npy')
) AS img_emd USING (rn)
) AS emb USING (rn)
SETTINGS max_threads = 1, input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference = 1
0 rows in set. Elapsed: 168.860 sec. Processed 2.82 million rows, 3.08 GB (16.68 thousand rows/s., 18.23 MB/s.)在这里,我们将具有后缀 0000 的 npy 和parquet文件连接起来,并将结果输出到新的 0000.parquet 文件中。这个示例可以很容易地适应直接从Hugging Face读取文件。
关于性能的一个小注释。上述方法并没有比原始的Python实现方式(耗时227秒)快得多,并且在内存效率上也较低,因为前者是一次处理一个块的连接 - 在这方面,我们的Python脚本,在这个问题上受益于作为问题定制的自定义解决方案。我们还被迫使用了单个线程执行读取以保留行顺序。然而,这是通用的,对于大多数数据集来说已经足够用了。对于那些希望在多个文件之间并行处理过程的人,也可以应用一个相对简单的bash命令。
Meetup 活动报名
好消息:ClickHouse Shenzhen User Group第1届 Meetup 已经开放报名了,将于2024年1月6日在深圳市南山区海天二路33号 腾讯滨海大厦举行,扫码免费报名


联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









