








本文字数:13234;估计阅读时间:34 分钟
作者:Dale McDiarmid & Ryadh Dahimene
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

简介
在生产环境中操作任何复杂的技术堆栈而没有适当的可观察性,就好比在没有仪器的情况下驾驶飞机。虽然这样做可能有效,飞行员也经过训练,但风险/回报比远非有利,应始终将其视为最后的手段。

作为可观察性的初始支柱,集中式日志记录可用于各种目的:从调试生产事件、解决客户支持问题、减轻安全漏洞,甚至了解客户如何使用产品。
任何集中式日志存储的最重要特性是其能够快速聚合、分析和搜索来自不同来源的大量日志数据。这种集中化简化了故障排除,使得更容易准确定位服务中断的根本原因。无需看更远,只需看Elastic、Datadog和Splunk,它们利用了这个价值主张获得了巨大的成功。
随着用户越来越注重价格,发现这些现成解决方案的成本相对较高且不可预测,与它们带来的价值相比,成本高效且可预测的日志存储,其中查询性能是可以接受的,比以往任何时候都更有价值。
在这篇文章中,我们介绍了CGW堆栈(ClickHouse、Grafana、WarpStream或“不会错”),并演示了当与存储和计算分离相结合时,对典型日志数据的压缩率超过10倍的优势,使得ClickHouse Cloud开发层实例可以舒适地承载超过1.5TiB的日志数据(假设列数与我们的样本数据相似,大约为50亿行):将其压缩到不到100GiB。一个完全并行化的查询执行引擎,结合低级别的优化,确保对这些数据量上的大多数典型SRE查询的查询性能保持在1秒以下,正如我们的基准所示。
在我们的基准测试中,通过多达14倍的压缩比,这个集群(允许高达1TiB的压缩数据)潜在地可以存储高达14TiB的未压缩日志数据。用户可以利用这些多余的容量进一步增加存储密度,如果查询性能不是关键问题,也可以简单地将其用于延长数据保留时间。我们展示了与其他解决方案相比的巨大节省,例如Elastic和Datadog,对于相同的数据量,它们的成本是原来的23倍到42倍。
虽然ClickHouse可以作为一个独立的日志存储引擎使用,但我们意识到用户通常更喜欢一种架构,即数据在插入ClickHouse之前首先在Kafka中进行缓冲。这提供了许多好处,主要是在吸收流量峰值的同时保持对ClickHouse的插入负载恒定,并允许将数据转发到其他下游系统。在我们提出的架构中,希望尽可能降低成本和操作,我们考虑了一个Kafka实现,也将存储和计算分开:WarpStream。我们将其与我们的标准建议一起使用,即用于日志收集的OTEL和用于可视化的Grafana。
为什么选择ClickHouse?
作为高性能的OLAP数据库,ClickHouse用于许多用例,包括时间序列数据的实时分析。它的多样化的用例帮助推动了大量的分析功能,这些功能有助于查询大多数数据类型。这些查询功能和由于列式设计和可自定义编解码器而产生的非常高的压缩率,越来越多地导致用户选择ClickHouse作为日志数据存储。通过分离存储和计算,并利用对象存储作为其主要数据存储,ClickHouse Cloud进一步提高了这种成本效益。
尽管我们过去通常看到大型CDN提供商使用ClickHouse来存储日志,但随着日志解决方案的成本越来越受关注,我们现在越来越多地看到中小型企业也在考虑将ClickHouse作为日志存储替代方案。
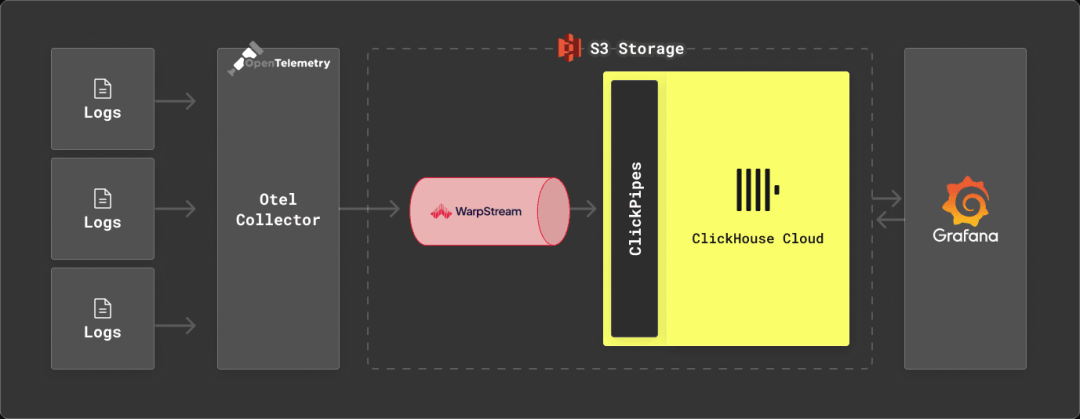
什么是WarpStream?
WarpStream是一个与Apache Kafka®协议兼容的数据流平台,可以直接运行在任何商品对象存储上。与ClickHouse一样,WarpStream是从头开始设计用于分析用例,并尽可能成本有效地管理大量机器生成的数据流。
WarpStream没有Kafka代理,而是有“代理”。代理是无状态的Go二进制文件(没有JVM!),可以使用Kafka协议,但与传统的Kafka代理不同,任何WarpStream代理都可以作为任何主题的“领导者”,为任何消费者组提交偏移量,或者作为集群的协调者。没有一个代理是特殊的,所以根据CPU使用率或网络带宽来自动扩展它们是微不足道的。
这是由于WarpStream将计算与存储以及数据与元数据分开。每个WarpStream“虚拟集群”的元数据存储在一个定制的元数据数据库中,该数据库是从头开始编写的,以最有效和最具成本效益的方式解决这个确切的问题。
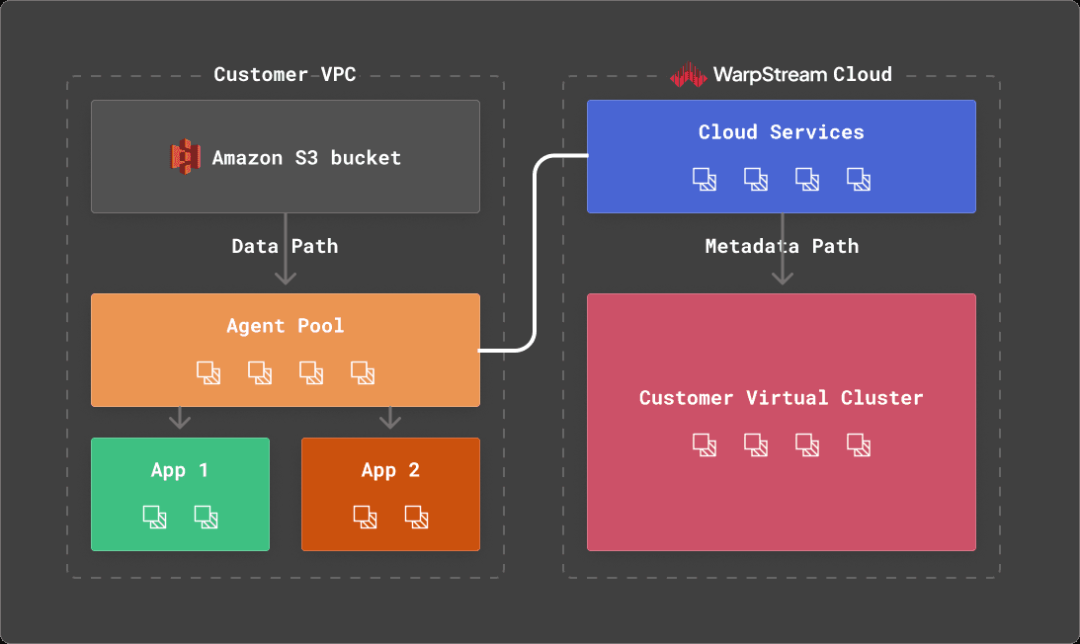
WarpStream使用对象存储作为主要且唯一的存储层,没有本地磁盘,这使得与其他Apache Kafka实现相比,它在分析数据方面表现得更加突出。
具体来说,WarpStream使用对象存储作为存储层和网络层,完全避免了区域间带宽成本,而这些费用往往可以轻松占据传统Apache Kafka实现的总成本的80%。此外,代理的无状态性使得将工作负载扩展到每秒多GB的数据是切实可行的(甚至容易)。
这些属性使得WarpStream非常适合日志记录解决方案,其中吞吐量往往相当大,价格敏感性至关重要,并且几秒钟的交付延迟是完全可以接受的。
对于希望部署WarpStream进行测试的用户,可以按照这些说明在Fly.io上部署测试集群,也可以按照这些说明在Railway上部署。
ClickHouse Cloud开发层
ClickHouse Cloud允许用户将ClickHouse部署为存储和计算分离的服务。虽然用户可以控制为生产层分配的CPU和内存,或者允许其在不使用时自动动态扩展,但开发层为我们的成本效益日志存储提供了理想的解决方案。建议将存储限制为1TiB,计算限制为4个CPU和16 GiB的内存,此实例类型的价格不能超过193美元/月(假设使用了全部1TiB)。对于其他用例,由于服务在不使用时可以处于空闲状态,因此成本通常低于此。我们假设持续的日志摄取的性质使这不可行。尽管如此,对于需要存储高达14TiB原始日志数据的用户来说,此服务非常理想,考虑到ClickHouse实现的预期14倍压缩比。
请注意,开发层与生产层相比使用了较少数量的复制节点 - 2个而不是3个。这种可用性水平对于日志记录用例来说也足够,其中复制因子为2通常足以满足SLA要求。最后,压缩数据的有限存储量允许开发一个简单的成本模型,我们将在下面介绍。
示例数据集
为了为ClickHouse Cloud中的日志记录用例基准测试开发层实例,我们需要一个代表性数据集。为此,我们使用了一个公开可用的Web服务器访问日志数据集。虽然这个数据集的模式很简单,但它等同于常见的nginx和Apache日志。
54.36.149.41 - - [22/Jan/2019:03:56:14 +0330] "GET /filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,27|%DA%A9%D9%85%D8%AA%D8%B1%20%D8%A7%D8%B2%205%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,p53 HTTP/1.1" 200 30577 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" "-"
31.56.96.51 - - [22/Jan/2019:03:56:16 +0330] "GET /image/60844/productModel/200x200 HTTP/1.1" 200 5667 "https://www.zanbil.ir/m/filter/b113" "Mozilla/5.0 (Linux; Android 6.0; ALE-L21 Build/HuaweiALE-L21) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.158 Mobile Safari/537.36" "-"
31.56.96.51 - - [22/Jan/2019:03:56:16 +0330] "GET /image/61474/productModel/200x200 HTTP/1.1" 200 5379 "https://www.zanbil.ir/m/filter/b113" "Mozilla/5.0 (Linux; Android 6.0; ALE-L21 Build/HuaweiALE-L21) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.158 Mobile Safari/537.36" "-"这个3.5GiB的数据集包含大约1000万行日志,并涵盖2019年的4天。更重要的是,列的基数和数据的周期性模式代表了真实数据。利用一个公开可用的脚本,我们已将此数据集转换为CSV*以简化插入。各个文件的大小保持可比。下面显示了生成的ClickHouse模式:
CREATE TABLE logs
(
`remote_addr` String,
`remote_user` String,
`runtime` UInt64,
`time_local` DateTime,
`request_type` String,
`request_path` String,
`request_protocol` String,
`status` UInt64,
`size` UInt64,
`referer` String,
`user_agent` String
)
ENGINE = MergeTree
ORDER BY (toStartOfHour(time_local), status, request_path, remote_addr)这代表了一个朴素的、非优化的模式。在我们的测试中,还有可能进行进一步的优化,可以提高压缩率约5%。但上述模式代表了新用户的入门体验。因此,我们测试的是最不利的配置。可以在这里找到替代方案,展示了压缩的变化。
我们已复制了这些数据,以涵盖一个月的时间,以便我们可以预测更典型的保留间隔。虽然这会导致固有数据模式的重复,但这被认为对我们的测试足够,并且类似于日志记录用例中看到的典型的每周周期性。
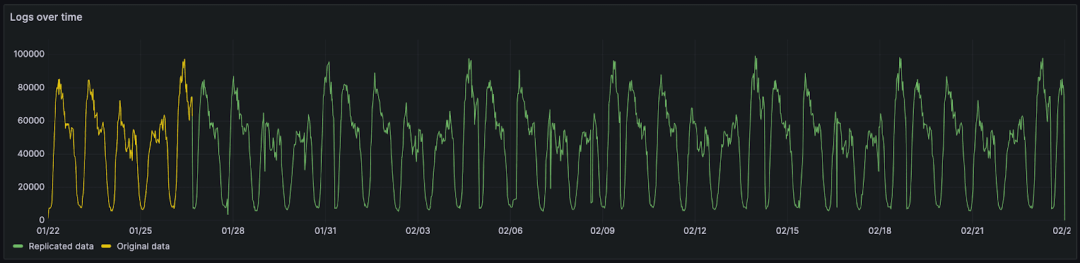
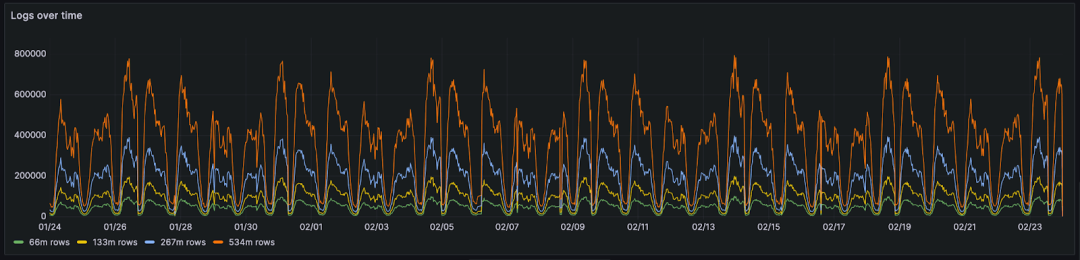
本月的数据包括 6600 万行和 20GiB 的原始 CSV/log 数据。为了复制这些数据以进行更大规模的测试并保持其数据属性,我们使用了一种简单的技术。与其简单地复制数据,我们将现有数据与一个顺序已被随机化的副本进行合并。这涉及一个简单的脚本,逐行迭代遍历两个授权文件和随机化文件。来自随机化文件和授权文件的行被复制到目标文件中。两者的“配对行”都被分配了授权文件中的日期。这确保了上面显示的周期模式得以保留。这与简单地复制行形成对比,简单地复制行会导致重复的行相邻放置。这会有利于压缩并提供不公平的比较 - 随着数据的复制而恶化。下面,我们展示了使用上述技术复制的相同数据,分别为 1.33 亿、5.34 亿和 10 亿行日志。
加载日志数据使用ClickPipes - 不到一分钟的数据管道
用于我们基准测试的所有文件都可在S3存储桶s3://datasets-documentation/http_logs/中下载,以允许用户复制测试。这些数据以CSV格式提供方便。对于希望将这些数据加载到代表性环境中的用户,我们提供了以下实用程序。这将数据推送到WarpStream实例,如下所示。
clickpipes -broker $BOOTSTRAP_URL -username $SASL_USERNAME -password $SASL_PASSWORD -topic $TOPIC -file data-66.csv.gz
wrote 0 records in 3.5µs, rows/s: 0.000000
generated schema: [time_local remote_addr remote_user runtime request_type request_path request_protocol status size referer user_agent]
wrote 10000 records in 63.2115ms, rows/s: 158198.854156
wrote 20000 records in 1.00043025s, rows/s: 19991.397861
wrote 30000 records in 2.000464333s, rows/s: 14996.517996
wrote 40000 records in 3.000462042s, rows/s: 13331.279947
wrote 50000 records in 4.000462s, rows/s: 12498.556286消费WarpStream中的数据,用户可以反过来使用ClickPipes,ClickHouse Cloud的本地摄取工具,将这些数据插入到ClickHouse中。我们在下面进行演示。
对于只想对ClickHouse进行测试的用户,可以使用单个命令从ClickHouse客户端加载示例数据文件,如下所示。
INSERT INTO logs FROM INFILE 'data-66.csv.gz' FORMAT CSVWithNames压缩
为了评估ClickHouse的存储效率,我们展示了上述数据集中日志事件数量增加时表的未压缩和压缩大小。这里的未压缩大小可以类比为CSV或原始日志格式中的原始数据量(虽然略小)。
SELECT
table,
formatReadableQuantity(sum(rows)) AS total_rows,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.parts
WHERE (table LIKE 'logs%') AND active
GROUP BY table
ORDER BY sum(rows) ASC
┌─table─────┬─total_rows─────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ logs_66 │ 66.75 million │ 1.27 GiB │ 18.98 GiB │ 14.93 │
│ logs_133 │ 133.49 million │ 2.67 GiB │ 37.96 GiB │ 14.21 │
│ logs_267 │ 266.99 million │ 5.42 GiB │ 75.92 GiB │ 14 │
│ logs_534 │ 533.98 million │ 10.68 GiB │ 151.84 GiB │ 14.22 │
│ logs_1068 │ 1.07 billion │ 20.73 GiB │ 303.67 GiB │ 14.65 │
│ logs_5340 │ 5.34 billion │ 93.24 GiB │ 1.48 TiB │ 16.28 │
└───────────┴────────────────┴─────────────────┴───────────────────┴───────┘我们的压缩比约为14倍,不论数据量如何增加,都保持不变。我们的最大数据集,包含超过50亿行和1.5TiB的未压缩数据,具有更高的压缩率。我们将这归因于由于最初的样本大小仅为1000万行而导致的数据中更多的重复。请注意,通过进一步的模式优化,可以使磁盘上的数据总大小提高约5%。
重要的是,即使是我们最大的数据集也消耗不到我们开发服务存储的10%,不到100GiB。如果需要,用户可以以极小的成本增加保留时间达十个月(见下文的成本分析)。
可视化日志数据
对于可视化,我们建议使用Grafana和官方的ClickHouse插件。为了在代表性查询负载下评估ClickHouse的性能,我们利用以下仪表板。这包含7个可视化,每个都使用各种聚合:
-
显示随时间变化的日志的折线图
-
显示总入站IP地址的指标
-
显示访问的前5个网站路径的条形图
-
多线图显示随时间变化的状态代码
-
多线图显示随时间变化的平均和第99个响应时间
-
每种HTTP请求类型传输的数据量作为条形图
-
按计数排列的顶部IP地址的条形图
每个可视化背后的完整查询可以在此找到。(https://github.com/ClickHouse/simple-logging-benchmark/tree/main/queries)
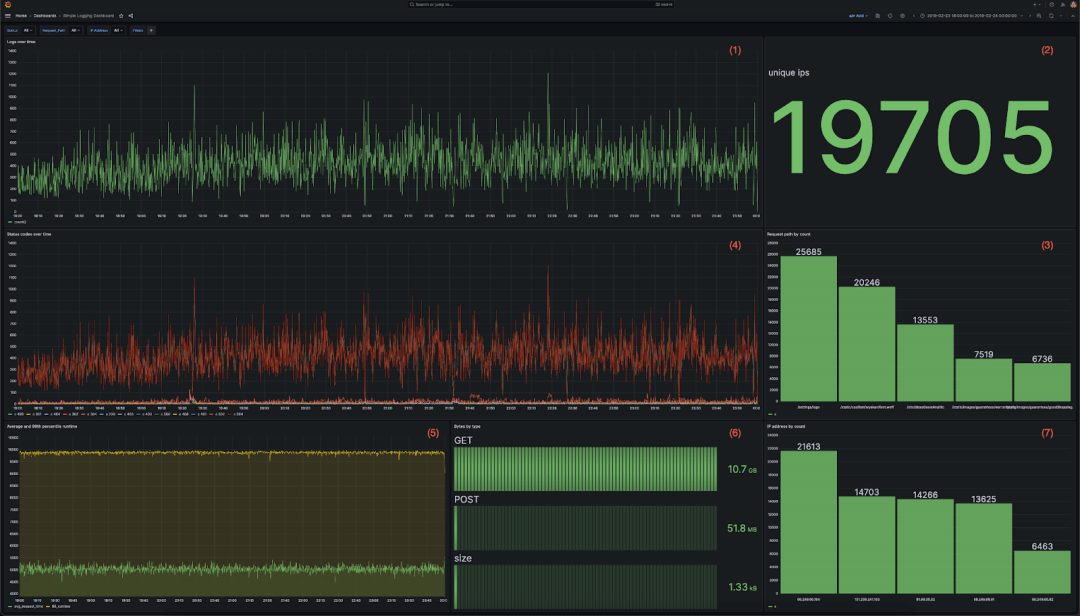
然后,我们将此仪表板提交给一系列用户下钻,以复制用户诊断特定问题的情况。我们捕获结果查询,并将其用于下面的基准测试。下面显示了操作序列。所有筛选器是累积的,因此复制了用户逐步操作的过程:
-
打开仪表板,查看最近6小时的数据。
-
通过过滤404状态码(即status=404)来查找错误。
-
通过为request_path添加额外的筛选器来隔离错误。
-
通过使用remote_addr列筛选到特定IP来隔离受影响的用户。
-
通过记录响应时间超过4秒的访问来评估SLA违规情况。
-
缩小到一个月的数据,以识别随时间变化的模式。
尽管这些行为是人为的,没有特定的事件,但它们旨在模拟SRE使用集中式日志记录解决方案的典型使用模式。可以在这里找到完整的结果查询。(https://github.com/ClickHouse/simple-logging-benchmark/tree/main/queries)
下面,我们评估了这些查询在不断增加的日志量下的性能。
查询性能
在该仪表板中包含7个图表和6个下钻功能,总共触发了42次查询。这些查询按照用户使用仪表板的方式执行,即同时运行7个查询,并启用相应的下钻功能。在执行任何查询负载之前,我们都会确保清空所有缓存(包括文件系统缓存)。每个查询会执行3次。下面我们列出了不断增加的数据量下的平均性能,但完整结果可以在此找到。
所有测试均可使用此存储库中提供的脚本进行复现。下面我们展示了不断增加的日志量下的平均性能、95th 和 99th 百分位的性能。
| Rows (millions) | Uncompressed data (GiB) | 95th | 99th | Average |
|---|---|---|---|---|
| 66.75 | 18.98 | 0.36 | 0.71 | 0.1 |
| 133.5 | 37.96 | 0.55 | 1.04 | 0.14 |
| 267 | 75.92 | 0.78 | 1.72 | 0.21 |
| 534 | 151.84 | 1.49 | 3.82 | 0.4 |
| 1095.68 | 303.67 | 5.18 | 8.42 | 1.02 |
| 5468.16 | 1515.52 | 31.05 | 47.46 | 5.48 |
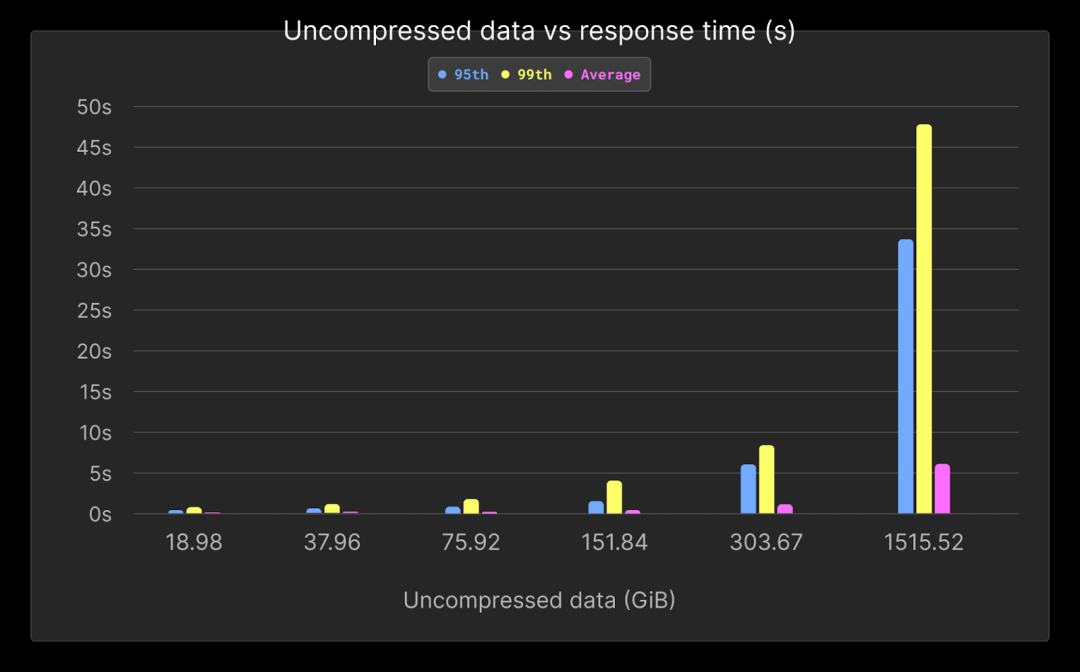
平均性能在所有查询中保持在1秒以下,直到10亿行。如图所示,随着数据量增加,大多数查询的性能并没有明显下降,这要归功于ClickHouse的稀疏索引,表现比线性更好。
更高的百分位数可以归因于冷查询,在我们的基准测试中没有预热时间。如下图所示,这些较慢的查询也与我们最后的下钻行为相关联,其中我们将数据可视化超过30天。这种访问类型通常不频繁,SRE更专注于较短的时间范围。尽管如此,即使在我们的最大测试中(1.5TiB),平均性能也保持在6秒以下。
下面,我们展示了不同下钻和数据量的仪表板可视化的平均性能。
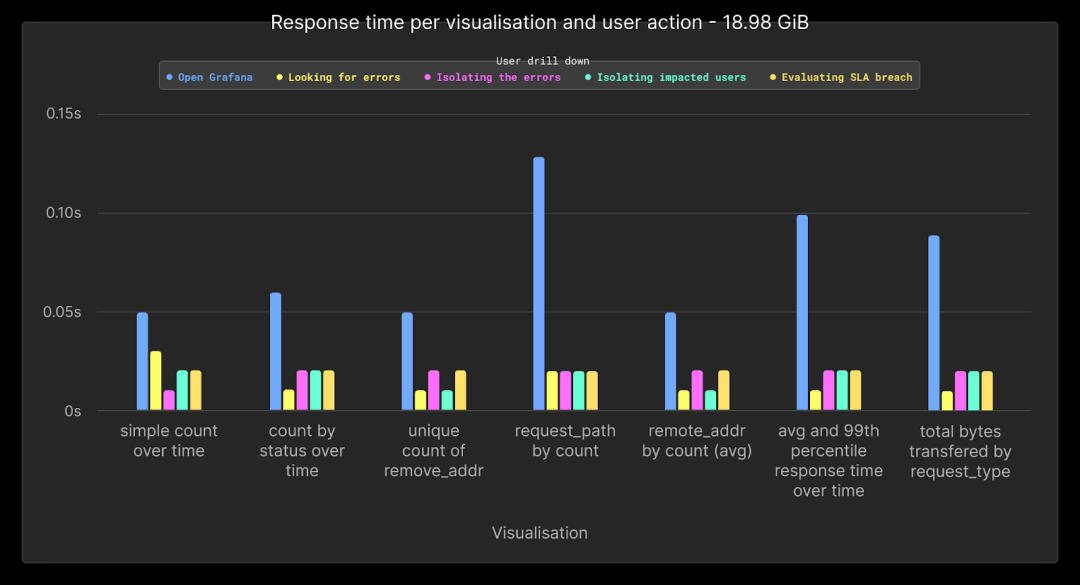
在6600万行或19GB数据时,所有查询的性能平均在0.1秒以下。
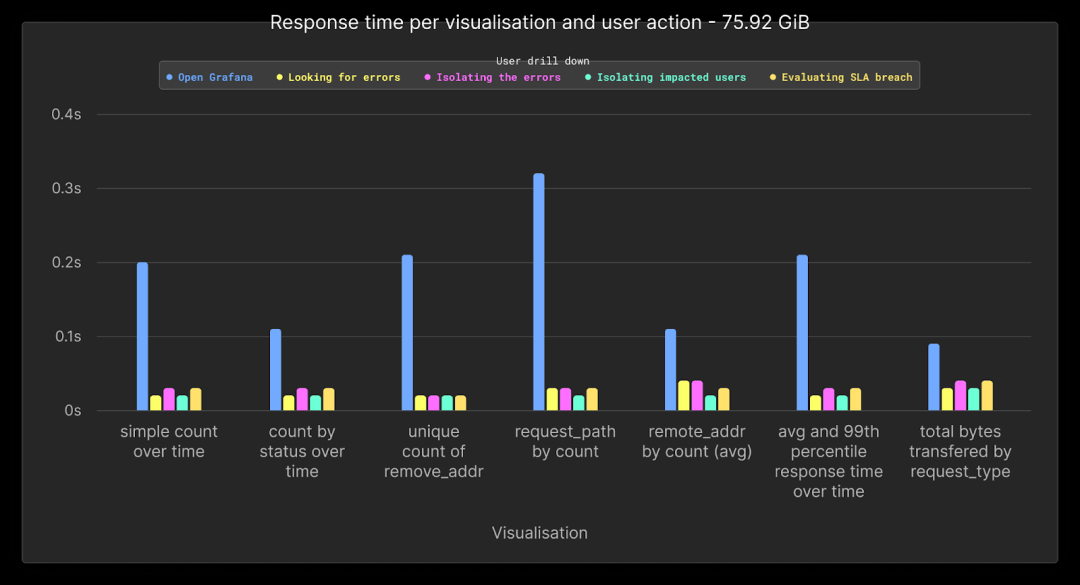
将数据量增加4倍后,26700万行或76GB的性能保持与先前的测试相当。尽管数据增加,所有查询的性能仍然可比。
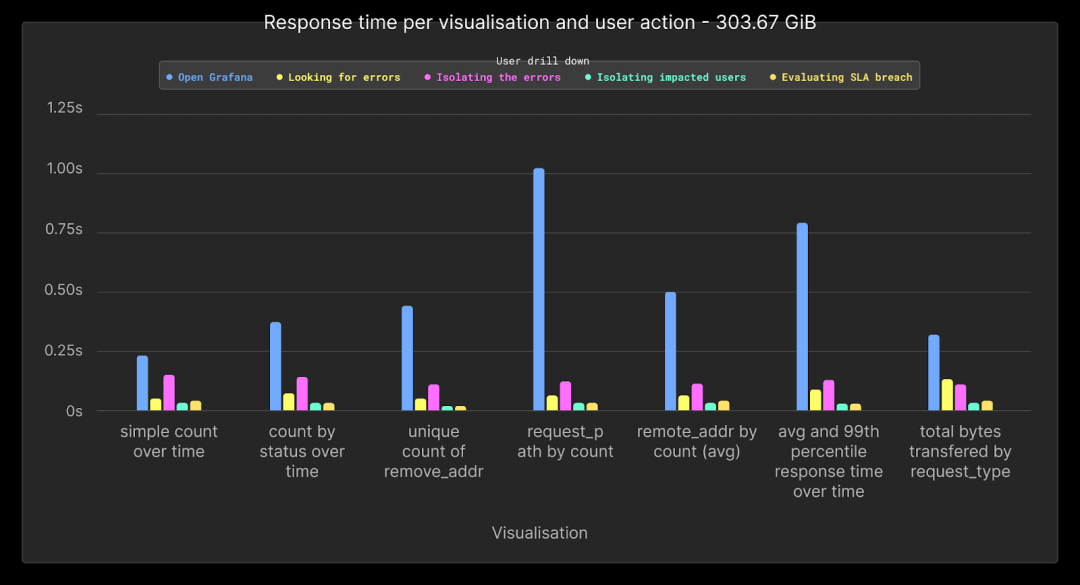
如果我们将数据量进一步增加4倍至300GB或约10亿行,则所有查询的性能平均保持在1秒以下。
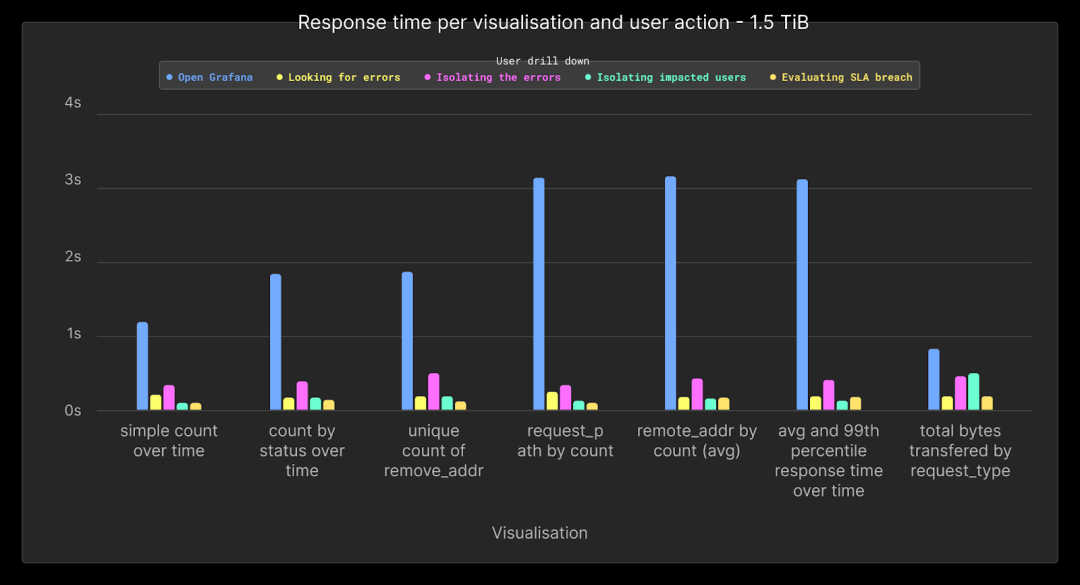
对于最后的测试,我们将容量增加到1.5TiB的未压缩数据或53亿行。与打开仪表板时相关的查询(在此期间仅应用了时间以外的筛选器)是最慢的查询,大约为1.5到3秒。所有涉及下钻的查询都在1秒内轻松完成。
敏锐的读者会注意到,我们上面没有包含最后一组查询的性能,这些查询与用户“缩小”以覆盖整个月份相关联。这些是最昂贵的查询,其时间会扭曲上面的图表。因此,我们在下面单独呈现这些查询的结果。
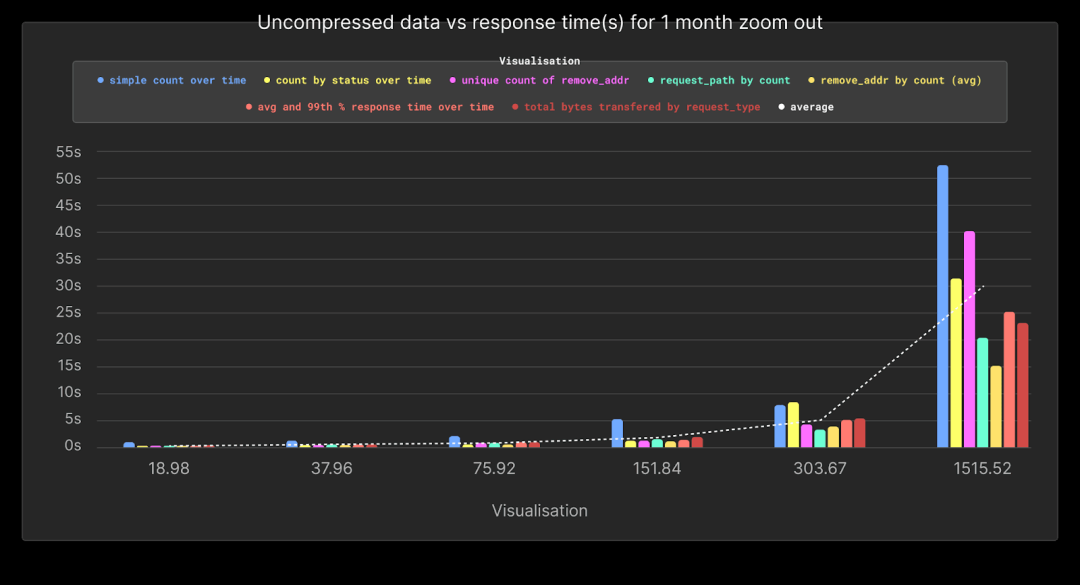
如图所示,此操作的性能严重取决于所查询数据的量,直到较大的1.5TiB负载,性能平均保持在5秒以下。我们预计这些查询,涵盖全数据集,将不频繁,并且不是常规SRE工作流程的典型部分。但是,即使这些查询很少,我们可以采取措施利用ClickHouse功能来提高其性能。我们将在下文中探讨这些措施,以更大的数据集为背景。
提高查询性能
以上结果显示,我们大多数仪表板查询的性能平均在几秒钟以下。我们的“放大”查询,其中我们的 SRE 试图在整个月份内识别趋势,最多需要 50 秒。虽然这不是完全的线性扫描,因为我们仍然在应用过滤器,但这个特定的查询受到 CPU 的限制,因为我们的开发服务中的每个节点只有两个核心。默认情况下,查询仅在查询的接收节点上执行。因此,这些查询将从在集群中分配计算,使得四个核心被分配给聚合。
在 ClickHouse Cloud 中,可以通过使用并行副本来实现这一点。此功能允许聚合查询的工作在集群中的所有节点之间分布,从同一单个分片读取。尽管这个功能目前还处于试验阶段,但在 ClickHouse Cloud 中的一些工作负载中已经在使用,并且预计将很快普遍提供。
下面,我们展示了当并行副本被启用时,如何使用完整的集群资源执行作为最终放大步骤的所有查询的结果。这些结果是针对 1.5TiB 的最大数据集的。完整的结果可以在这里找到。(https://github.com/ClickHouse/simple-logging-benchmark/blob/main/results/parallel_replicas.md)
| simple count over time | count by status over time | unique count of remote_addr | request_path by count | remote_addr by count | average and 99th percentile response time transferred over time | total bytes transferred by request_type | |
|---|---|---|---|---|---|---|---|
| With Parallel Replicas | 24.8 | 10.81 | 10.84 | 9.74 | 9.75 | 9.31 | 8.89 |
| No Parallel Replicas | 52.46 | 31.35 | 40.26 | 20.41 | 15.14 | 25.29 | 23.2 |
| Speedup | 2.12 | 2.9 | 3.71 | 2.1 | 1.55 | 2.72 | 2.61 |
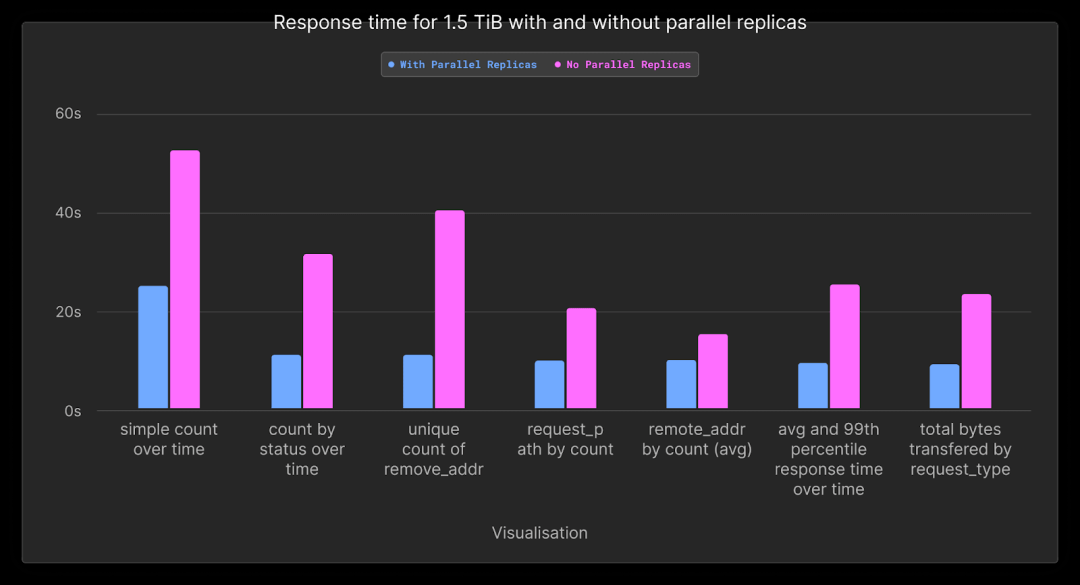
如图所示,启用并行副本将我们的查询平均加速了2.5倍。这确保了我们的查询最多在24秒内响应,大多数在10秒内完成。请注意,根据我们的测试,只有当需要聚合大量行时,并行副本才能提供好处。对于其他较小的数据集,分发的成本超过了好处。在ClickHouse的未来版本中,我们计划使此功能的使用更加自动化,而不是依赖用户根据数据量手动应用适当的设置。
成本分析
ClickHouse
利用ClickHouse Cloud的开发层的成本主要由计算单元主导,另外还有存储的额外费用。相对而言,由于ClickHouse云中使用了对象存储,因此此工作负载的存储成本很小。因此,鼓励用户在不担心累积成本的情况下延长数据保留时间。
-
每小时0.2160美元。假设我们的服务始终处于活动状态,这大约是0.2160美元 x 24 x 30 = 155.52美元
-
每月压缩数据每TiB 35.33美元
基于此,我们可以使用简单的计算来估算我们对早期数据量的成本。
| Uncompressed size (GiB) | Compressed size (GiB) | Number of rows (millions) | Retain cost (1 month) for compute ($) | Storage cost ($) | Total Cost per month ($) |
|---|---|---|---|---|---|
| 18.98 | 1.37 | 66.75 | 155.52 | 0.05 | 155.57 |
| 37.96 | 2.96 | 133.49 | 155.52 | 0.1 | 155.62 |
| 75.92 | 5.42 | 267 | 155.52 | 0.19 | 155.71 |
| 151.84 | 10.68 | 534 | 155.52 | 0.37 | 155.89 |
| 303.67 | 20.73 | 1070 | 155.52 | 0.72 | 156.24 |
| 1515.52 | 93.24 | 5370 | 155.52 | 3.22 | $158.74 |
| 14336 | 1024 | 58976 | 155.52 | 35.33 | $190.85 |
如前所述,这里的未压缩大小可以被视为CSV和非结构化格式的原始日志格式的等效。显然,我们这里的存储成本是很小的,对于我们最大的测试案例,即包含1.5TiB未压缩数据的情况,只需3美元。
上表中的最后一行将展示如果我们利用开发层提供的全部1TiB压缩存储空间的成本。这可以通过延长数据的保留时间或增加每月的数据量来实现,这相当于超过580亿行数据和14TiB未压缩日志。这仍然只需要每月190美元。由于对象存储成本低廉,这仅比存储我们最大的1.5TiB未压缩测试案例多出32美元!
WarpStream
WarpStream的定价工作更简单,没有复杂的查询需要运行。在这种情况下,WarpStream充当了一种成本高效且可扩展的缓冲区。我们假设在传输过程中的压缩比为4倍,因为数据不是以列形式组织的,并且客户端可能会根据其配置生成或消耗小批量数据。最后,我们还假设48小时的保留时间足够,因为WarpStream只是作为ClickHouse前的临时缓冲区,而不是最终目的地。以下是完整14TiB数据的成本。
| Uncompressed Size (GiB) | Throughput MiB/s | Compute cost for agent($) | Storage cost (2 days) ($) | S3 API Costs | Total Cost per month ($) |
|---|---|---|---|---|---|
| 18.98 | 1.8Kib/s | $21.4 | $0.007 | $58 | $80 |
| 37.96 | 3.6KiB/s | $21.4 | $0.014 | $58 | $80 |
| 75.92 | 7KiB/s | $21.4 | $0.028 | $58 | $80 |
| 151.84 | 14KiB/s | $21.4 | $0.057 | $58 | $80 |
| 303.67 | 29KiB/s | $21.4 | $0.116 | $58 | $80 |
| 1515.52 | 146KiB/s | $21.4 | $0.58 | $58 | $80 |
| 14336 | 1.38 MiB/s | $21.4 | $5.49 | $58 | $85 |
上面使用了 Fly.io 2x shared-cpu-1x,配备了 2GiB 的 RAM。
需要注意的是,WarpStream 计算和 S3 API 成本相对来说是“固定”的成本,工作负载的大小可以进一步增长 5-10 倍,而这两项成本都不会增加。这是因为我们至少需要运行两个代理以确保高可用性。然而,即使在这个设置中使用的两个小代理也可以轻松容忍每秒 10-20MiB 的写入量,这比最高行的数量要大一个数量级。因此,计算成本保持不变。
此外,S3 API 成本也基本上是固定的,因为代理必须每 250 毫秒生成一个文件,无论负载如何。然而,随着写入量的增加,批处理也会增加,直到工作负载的总写入吞吐量超过每个文件的最大摄入大小(8MiB)之前,成本都保持不变。
总结
以下是 CGW 堆栈在各种日志容量下的每月总成本。
| Uncompressed size (GiB) | WarpStream cost per month ($) | ClickHouse cost per month ($) | Total cost ($) |
|---|---|---|---|
| 18.98 | 80 | 155.57 | 235.57 |
| 37.96 | 80 | 155.62 | 235.62 |
| 75.92 | 80 | 155.71 | 235.71 |
| 151.84 | 80 | 155.89 | 235.89 |
| 303.67 | 80 | 156.24 | 236.89 |
| 1515.52 | 80 | 158.74 | 238.74 |
| 14336 | 85.43 | 190.85 | 276.28 |
上述成本不包括 OTEL 收集器(或等效物)的成本,我们假设这些收集器将在边缘运行,并且代表着可以忽略的开销。
成本比较
为了提供一些相对比较的元素,我们决定将我们的 CGW 堆栈的成本与日志领域的两个领先解决方案进行比较,即 Datadog 和 Elastic Cloud。
读者应记住,我们在这里并不进行完全一致的苹果对苹果比较,因为 Elastic 和 Datadog 都提供了除主要存储/查询功能以外的全面日志用户体验。另一方面,所呈现的两个替代解决方案都不包括 Kafka 或与 Kafka 兼容的排队机制。
然而,从功能的角度来看,主要目标是相同的,而 CGW 对于核心日志使用案例来说是一个有效的替代方案。我们根据公开可用的定价计算器数据和以下假设在下表中显示了成本差异:
-
每月 CGW 成本:包括上述 Warpstream 和 ClickHouse Cloud 的成本,并假设使用 Grafana Cloud 免费版实例。
-
每月 Elastic Cloud 成本:假设运行在通用硬件配置文件上的 Elastic 标准层(最低层),具有 2 个可用性区域和 1 个免费的 Kibana 实例。我们还假设数据的压缩比为 1:1。
-
每月 Datadog 成本:假设仅有 30 天的保留期,并且有一年的承诺期(30 天是 datadoghq.com/pricing 上公开价格列出的最高周期)。
-
此外,所呈现的两个替代解决方案都不包括必须单独部署和评估的 Kafka 或与 Kafka 兼容的排队机制的成本。我们放弃了替代解决方案的这部分成本。
| Uncompressed size (GiB) | Compressed size (GiB) | Number of rows (millions) | CGW Cost Per Month ($) | Elastic Cloud Cost Per Month ($) | Elastic Cloud / CGW multiple | Datadog Cost Per Month ($) | Datadog / CGW multiple |
|---|---|---|---|---|---|---|---|
| 18.98 | 1.37 | 66.75 | 241 | $82 | x 0.3 | $143 | x 0.6 |
| 37.96 | 2.96 | 133.49 | 241.05 | $82 | x 0.3 | $143 | x 0.6 |
| 75.92 | 5.42 | 267 | 241.14 | $131 | x 0.5 | $234 | x 1.0 |
| 151.84 | 10.68 | 534 | 241.32 | $230 | x 1.0 | $415 | x 1.7 |
| 303.67 | 20.73 | 1070 | 241.67 | $428 | x 1.8 | $776 | x 3.2 |
| 1515.52 | 93.24 | 5370 | 244.17 | $3,193 | x 13.1 | $5,841 | x 23.9 |
| 14336 | 1024 | 58976 | 276.28 | $6,355 | x 23.0 | $11,628 | x 42.1 |
如上所示,对于任何小型工作负载(<150 GiB 未压缩数据),CGW 堆栈几乎固定的成本并不合理,而替代解决方案更具吸引力。然而,一旦超过这个阈值,我们很快就会观察到成本增长速度高于替代解决方案管理的数据量,对于 1.5 TiB 的日志数据,达到了 Elastic Cloud 的 23 倍和 Datadog 的 42 倍。
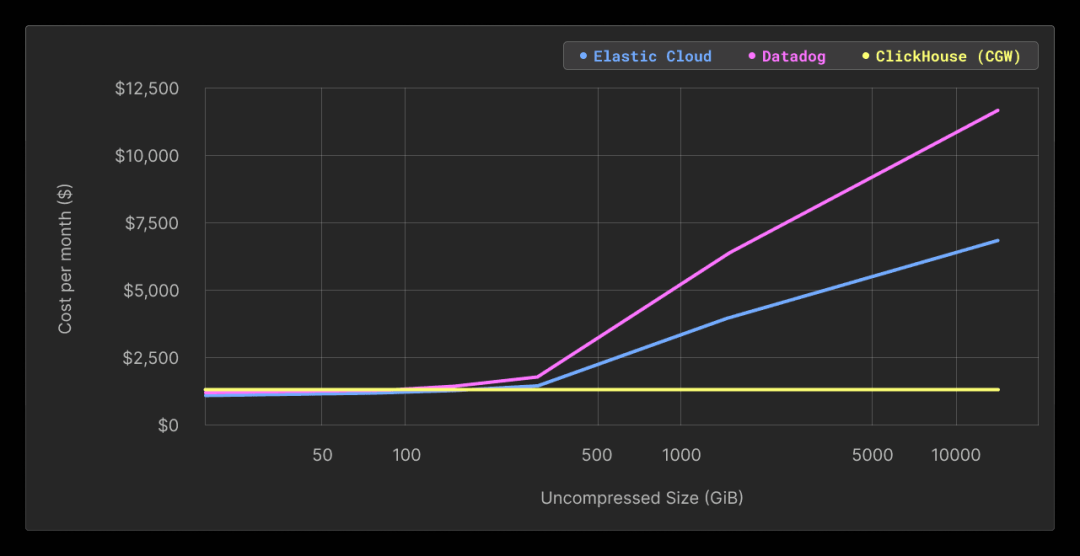
基于上述结果,我们得出结论,CGW 堆栈提供了一种成本效益高的替代方案,可以轻松扩展到多 TB 规模,而不会增加成本。成本的可预测性为那些预计系统增长并希望避免未来出现意外的用户提供了明显的优势。在超过这个规模之后,用户总是可以决定升级到生产级别的 ClickHouse Cloud 服务,以跟上不断增长的数据量。我们预计在这种情况下的成本节省将更加可观,正如大型 CDN 提供商使用 ClickHouse 存储日志所证明的那样。
除了成本效益之外,拥有完全成熟的现代分析存储意味着您可以将用例扩展到基本的日志存储和检索之外,从 ClickHouse 充满活力的集成生态系统中获益。一个例子是,您可以决定使用 S3 表函数将大量日志以 Parquet 格式存储在远程对象存储桶中,以进行存档,从而扩展您的保留能力。
结论
在本文中,我们介绍了 CGW 堆栈,这是一个基于 ClickHouse Cloud、WarpStream 和 Grafana 的日志解决方案。如果使用 ClickHouse Cloud 开发服务,这个堆栈为每月存储高达 14TiB 未压缩数据提供了一种高效的方式,成本不到 300 美元。这比可比较的 Elastic Cloud 部署要高出 23 倍,比同等数据量的 DataDog 要便宜多达 42 倍。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求















 5398
5398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









