






SOLOarXiv上有两篇,SOLOv1和SOLOv2,近期看到TPAMI官网接受了SOLO,是前面两个版本的集合版。
SOLO: A Simple Framework for Instance Segmentation
阿德莱德大学和字节跳动实验室的。
一、相关背景
1.图像分割:
1)语义分割
按照语义,为图像中的每个像素分配标签。
2)实例分割
不分割背景,需要标注出图上同一实例类别的不同个体,比如人1,人2。
3)全景分割
语义分割和实例分割的结合,即要对所有目标和背景都检测出来,又要区分出同个类别中的不同实例。对背景做语义分割,对前景做实例分割。

二、相关工作
- 自顶向下top-down:“先检测,后分割”,首先检测边界框,然后在每个bbox中分割实例掩码。例如Fast R-CNN等。
- 自底向上bottom-up:首先为每个像素分配一个嵌入向量,然后将属于不同实例的像素推远,把属于同一个实例的拉近,从而将像素聚类到单个实例中,之后需要分组后处理来分开每个实例。例如SGN等。
三、出发点
主流的实例分割方法,都是分步实现、不直接的,前者严重依赖于精确的边界框检测,后者依赖于每个像素的嵌入学习和分组处理。
因此,本文旨在直接、快速的实例分割。
四、方法
过程:
1.图像中实例之间的基本区别是什么?
以 MS COCO数据集为例,验证集中共有36,780个实例:
- 98.3%的实例对的中心距离大于30个像素。
- 对于其余1.7%的实例对,其中40.5%的大小比例大于1.5倍。
**结论:**在大多数情况下,图像中的两个实例要么有不同的中心位置,要么有不同的对象大小。
**反思:**是否可以直接通过中心的位置和对象的大小来区分实例?
2.根据基本区别制定方法
根据中心位置和实例大小进行分割。
**中心位置:**图像可以划分为S×S个网格,得到S^2个中心位置类别。如果对象实例中心落在某个网格中,那这个网格的类别就可以作为实例的类别,并且每个网格需要在输出通道中对应属于该位置实例的mask。
这种方法自然会输出所有尺度实例的精确掩码,而不受边界框位置和尺度的限制。

对象大小: 采用特征金字塔(feature pyramid network,FPN)来区分具有不同大小的对象实例,以便将不同大小的对象分配给不同level的特征图,作为对象大小类别。
五、具体做法
将实例分割转化为根据中心位置和实例大小进行分割。
根据中心位置进行分割可以转化为两个问题:类别预测+实例 mask 生成。
如果实例的中心落到网格中,则这个网格要 输出实例类别(semantic category)+ 分割实例(segmenting instance)。

类别: C维输出分别代表每个类别的置信得分,C是类别数量,那输出就是S×S×C。
Mask: 最多总共会有S^2个预测的mask。实例掩码输出具有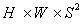
维度。
对应关系: 实例掩码第k个通道将负责在网格(i,j)上分割实例,其中k=(i-1)·S+j。为此,在语义类别和类不可知的掩码之间建立了一对一的对应关系。
实例大小: 使用 FPN 作为 backbone,FPN 在每个层级产生固定通道但不同大小的特征图(通道通常为256),这些特征图作为上述两个并行预测 head 的输入。同一个head的不同层的参数是共享的。不同层的网格数不同。
遇到问题: 普通的卷积操作具有空间不变性,但是由于需要对不同位置的网格进行分类,要在卷积操作中具有位置敏感性。
解决方案: 输入图像与x坐标组成的张量和y坐标组成的张量连接,再传入网络。如果原始大小为H×W×D,则新的大小变为H×W×(D+2),其中最后两个通道为x、y像素坐标。
六、训练标签
类别预测分支: 网络需要给每个网格预测对象类别概率。以( i , j )位置为例,如果该网格落入任何Ground Truth实例mask的中心区域,则视为正样本,否则为负样本。可以从groud truth中提取每个正样本的类别。
Mask预测分支: 每个正样本有一个实例二进制分割mask,负样本没有mask,按顺序排列。
七、损失函数

其中,前者是用于分类的Focal loss,后者是用于mask预测的loss:

i,j是网格k的横纵坐标,N是正样本的个数,p和m分别是类别和mask。1是指示函数,如果括号里成立则为1,否则为0。也就是只计算正样本网格的mask的损失dmask的平均值。dmask本文中对比了二值交叉熵(Binary Cross Entropy,BCE)、Focal loss和Dice Loss,Dice Loss效果最好。
 其中D是dice系数,一般dice系数计算公式是:
其中D是dice系数,一般dice系数计算公式是:

八、其他改进
1.按照基本原理提出了三种不同的SOLO变体。
1)Decoupled SOLO (解耦SOLO):
出发点: 给定一个预定义的网格数例如S=20,普通的SOLO输出400个通道图。预测有些冗余,因为在大多数情况下,对象在图像中是稀疏的。因此提出解耦solo。
—原始输出tensor :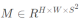
—经过解耦之后的输出:分别对应于两个坐标的 tensor:
所以,输出空间降了。
对于落到网格( i , j )中的目标:
—原始SOLO 在输出M 的第 k 个通道分割其 mask:k=(i-1)*S+j.
—经过解耦之后的该对象的预测 mask 被定义为X,Y特征图中第j,i个通道的元素级别的相乘:

2)Dynamic SOLO(动态SOLO):
出发点:普通SOLO中,最后一层用了11的卷积,但是这个卷积核是不变的。
改进:卷积核也通过学习产生,提高灵活性和自适应特性,使得kernel根据输入图像的变化而变化。
上面的分支预测kernel,大小为SSD,其中D是kernel参数数量;下面的分支预测特征。之后将特征与上面预测得到的张量中11*D的元素进行卷积。
3)Decoupled Dynamic SOLO:
G和F分别分成A组,每一组进行卷积,卷积出来每一组再相乘。
2.矩阵NMS(非最大值抑制)算法
提出了一种高效、有效的矩阵NMS(非最大值抑制)算法,来抑制重复的预测。
现有方法的缺点:多类NMS和mask NMS的顺序操作和递归操作会导致不可忽略的延迟;与边界框相比,计算每个掩模对的IoU需要更多的时间,从而导致了巨大的开销。
结果:在简单的python实现中,MatrixNMS在不到1ms内处理500个掩码,并比最近提出的FastNMS[25]高出0.4%的AP。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









