






HashCode
HashCode方法介绍
哈希值
- 是
JDK根据某种规则算出来的int类型的整数
Object类的API
@IntrinsicCandidate
public native int hashcode();
public int hashCode():调用底层C++代码计算出的一个随机数(常被人称作地址值)
HashCode方法改造
- 重写
hashCode方法 - 根据对象的属性值计算出的哈希值
HashCode原理解析
JDK7: 数组 + 链表JDK8: 数组 + 链表 / 红黑树
HashSet
HashSet1.7 版本原理解析: 数组 + 链表

HashSet 的添加过程 (JDK8版本以后)
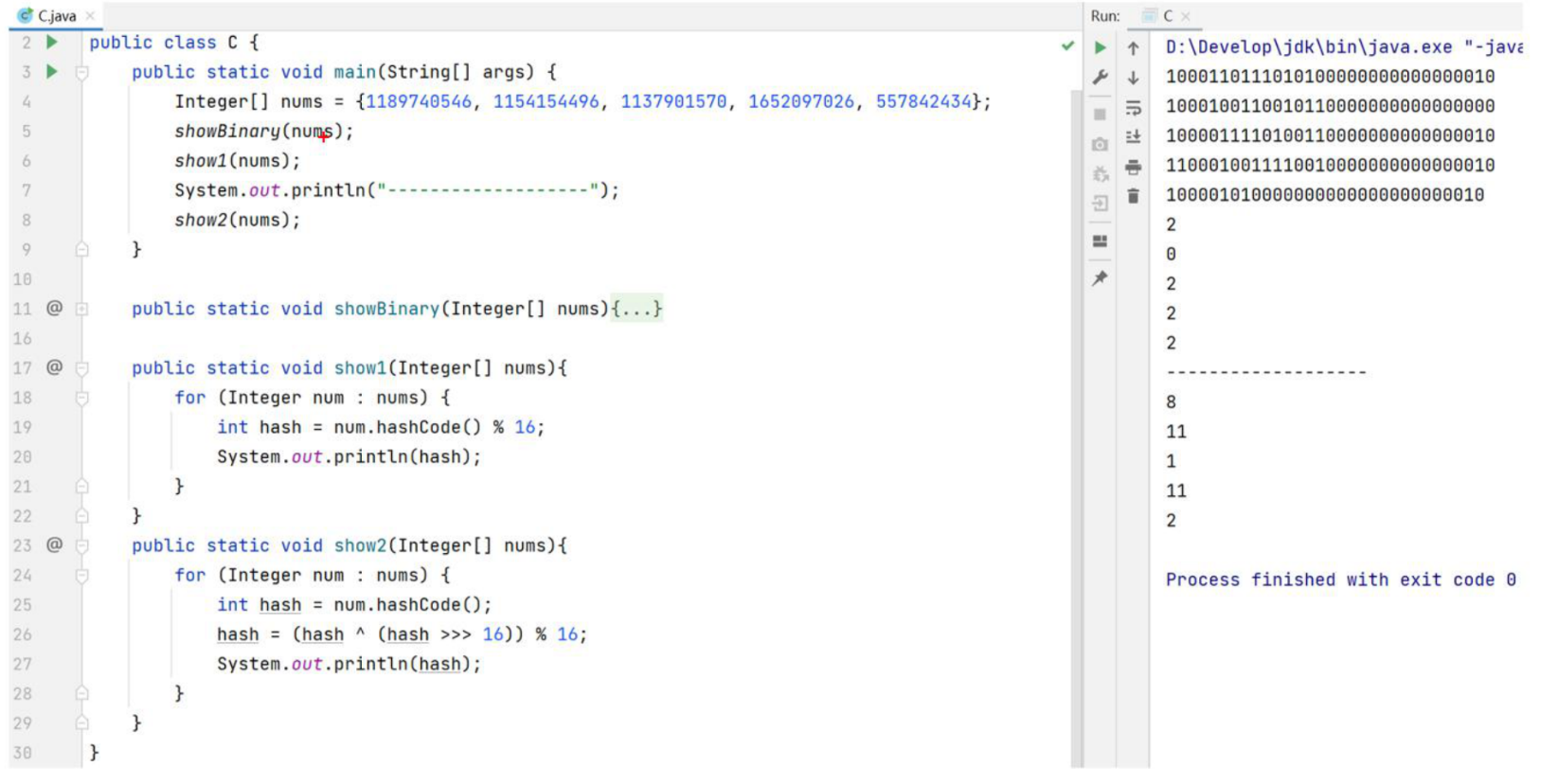
底层结构:哈希表(数组,链表,红黑树的结合体)
- 哈希表也叫做(散列表)
- 创建
HashSet集合,内部会存在一个长度为16个大小的数组 - 调用集合的添加方法,会拿着对象的
HashCdeo方法计算出应存入的索引位置(哈希值 % 数组长度)

- 判断索引位置元素是否是
null- 是 : 存入
- 不是 : 说明有元素, 调用
equals方法比较内容- 一样 : 不存
- 不一样 : 存入
如何能够提高查询性能?
- 扩容数组
- 扩容数组的条件:
- 当数组中的元素个数到达了 16 * 0.75 (加载因子)= 12, 扩容原数组2倍的大小
- 链表挂载的元素超过了8(阈值)个,并且数组长度没有超过64
- 链表转红黑树
- 链表挂载的元素超过了8(阈值)个,并且数组长度到达了64
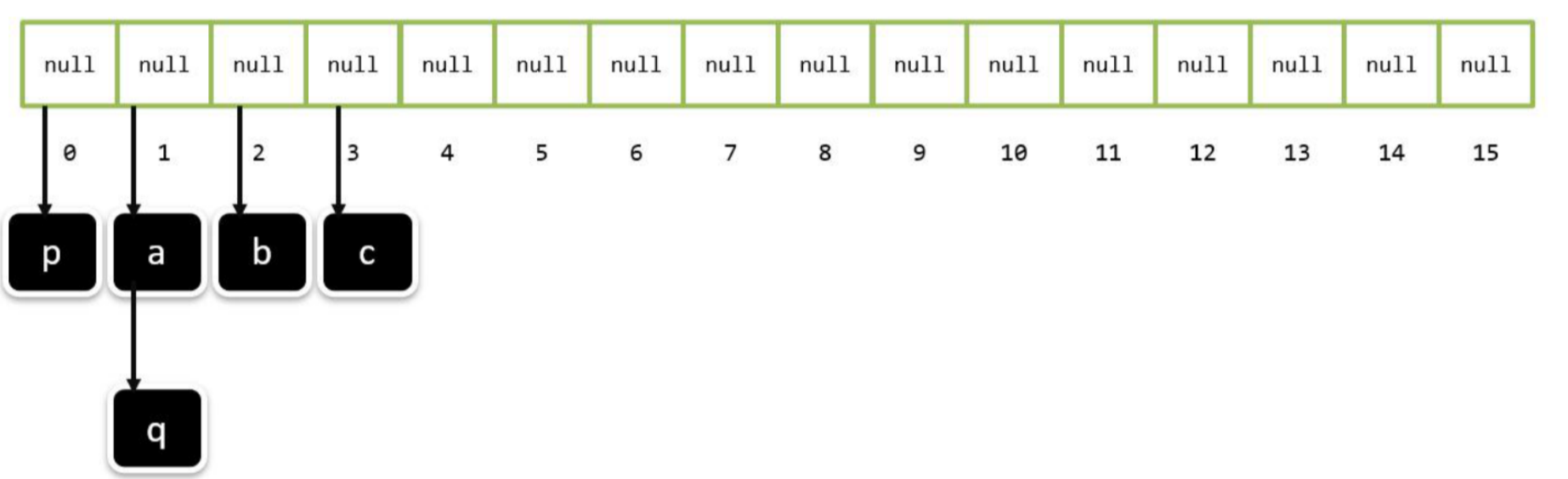
LinkedHashSet
概述和特点
- 有序,不重复,无索引。
- 这里的有序指的是保证存储和取出的元素顺序一致
- 原理:底层数据结构依然是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
该选用何种集合
- 如果想要集合中的元素可重复
用ArrayList集合,基于数组的。 (用的最多)
- 如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
用LinkedList集合,基于链表的。
- 如果想对集合中的元素去重
用HashSet集合,基于哈希表的。 (用的最多)
- 如果想对集合中的元素去重,而且保证存取顺序
用LinkedList集合,基于哈希表和双链表,效率低于HashSet.
- 如果想对集合中的元素进行排序
用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。
可变参数
- 可变参数用在形参中可以接收多个数据。
- 可变参数的格式:
数据类型...参数名称 - 传输参数非常灵活,方便,可以不传输参数,可以传输1个或者多个,也可以传输一个数组
- 可变参数在方法内部本质上就是一个数组
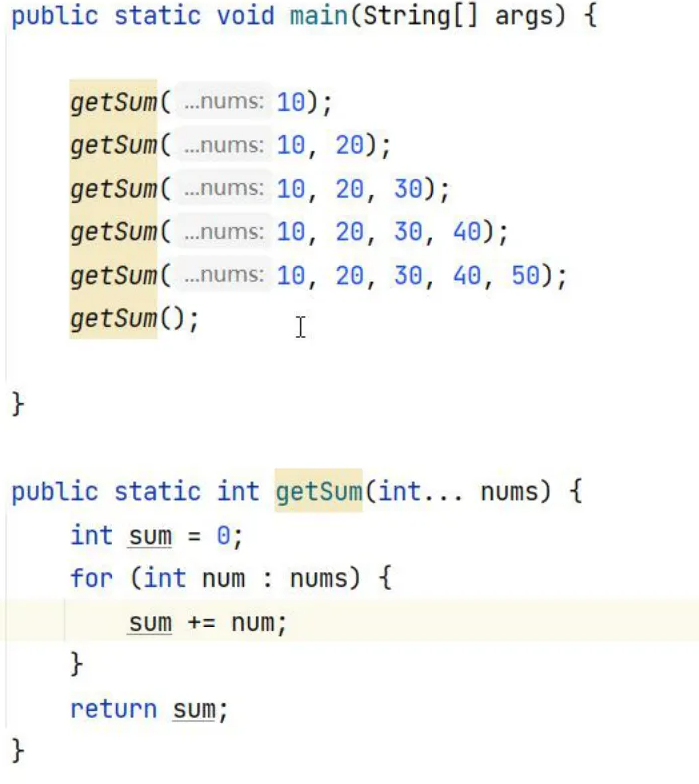
注意事项:
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面

collections集合工具类
java.utils.Collections: 是集合工具类- 作用:
Collections并不属于集合,是用来操作集合的工具类。

Map集合
Map集合是一种双列集合,每个元素包含两个数据Map集合的每个元素的格式:key :value(键 (键值对元素)
-key(键):不允许重复
-value(值):允许重复
- 键和值是一 一对应的,每个键只能找到自己对应的值key + value这个整体我们称之为"键值对"或者"键值对对象", 在Java中使用Entry对象表示
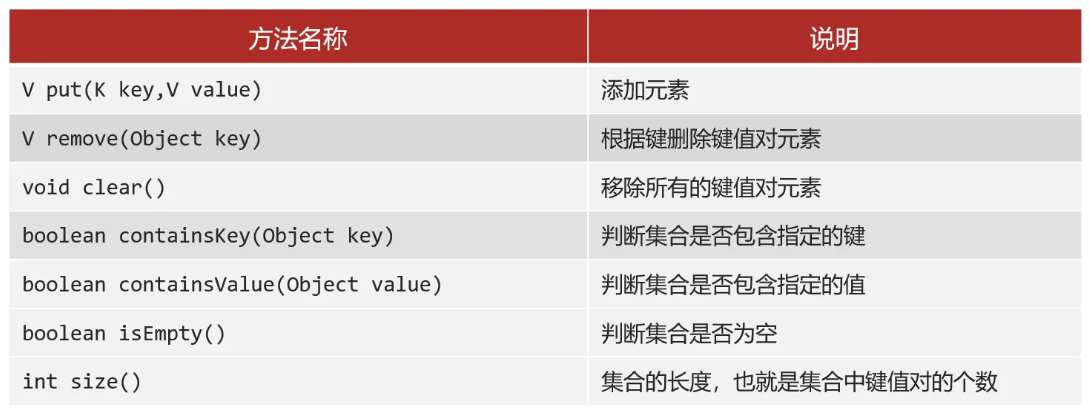
Map的常见API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的
重点
- Map集合中所有的数据结构, 都只针对于键有效
- HashMap : 键 --> 哈希表
- TreeMap : 键 --> 红黑树
- LinkedHashMap : 键 --> 哈希表 + 双向链表
细节
- put() : 添加 \ 修改
- 添加键
- 键不存在: 直接存储
- 键存在: 键不变, 新值覆盖旧值.
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("张三", "北京");
map.put("李四", "北京");
map.put("王五", "上海");
System.out.println(map);
map.remove("李四");
System.out.println(map);
System.out.println(map.isEmpty());
System.out.println(map.size());
System.out.println(map.containsKey("王五"));
System.out.println(map.containsValue("上海"));
map.clear();
System.out.println(map);
System.out.println(map.isEmpty());
System.out.println(map.size());
System.out.println(map.containsKey("王五"));
System.out.println(map.containsValue("上海"));
}
}
Map集合的三种遍历方式
通过键找值
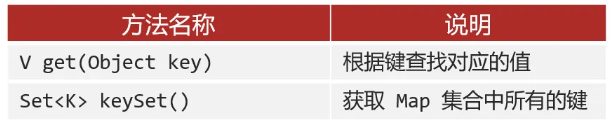
- 调用
keySet方法获取所有的键(得到的是set集合) - 遍历set集合,获取每一个键
- 遍历的过程中调用get方法,根据键找值
public static void main(String[] args) {
HashMap<Student, String> map = new HashMap<>();
map.put(new Student("张三", 23), "北京");
map.put(new Student("李四", 24), "上海");
map.put(new Student("王五", 25), "广州");
// 1. 通过map集合的keySet方法, 获取所有的键
Set<Student> keySet = map.keySet();
// 2. 遍历set集合, 获取每一个键
for (Student key : keySet) {
// 3. 通过map集合的get方法, 根据键查找对应的值
String value = map.get(key);
System.out.println(key + "---" + value);
}
}
通过键值对对象获取键和值


- 调用
entrySet方法获取所有的键值对对象
(得到的是set集合)
- 遍历Set集合,获取每一个键值对对象
- 通过键值对对象的
getKey()getValue()获取键和值
/*
Map集合的第二种遍历方式 :
1. 通过Map集合的entrySet方法, 获取所有的键值对对象 --> 返回的是set集合
2. 遍历set集合, 获取每一个键值对对象
3. 通过键值对对象获取键和值.
*/
public static void main(String[] args) {
TreeMap<Student, String> map = new TreeMap<>();
map.put(new Student("李四", 24), "上海");
map.put(new Student("张三", 23), "北京");
map.put(new Student("王五", 25), "广州");
// 1. 通过Map集合的entrySet方法, 获取所有的键值对对象 --> 返回的是set集合
Set<Map.Entry<Student, String>> entrySet = map.entrySet();
// 2. 遍历set集合, 获取每一个键值对对象
for (Map.Entry<Student, String> entry : entrySet) {
// 3. 通过键值对对象获取键和值.
System.out.println(entry.getKey() + "---" + entry.getValue());
}
}
通过foreEach方法遍历

public static void main(String[] args) {
LinkedHashMap<Student, String> map = new LinkedHashMap<>();
map.put(new Student("李四", 24), "上海");
map.put(new Student("张三", 23), "北京");
map.put(new Student("王五", 25), "广州");
map.forEach(new BiConsumer<Student, String>() {
@Override
public void accept(Student key, String value) {
System.out.println(key + "---" + value);
}
});
System.out.println("---------------------");
map.forEach((k, v) -> System.out.println(k + "---" + v));
}
注意
- 双列集合的数据结构,都只针对于键有效,和值没有关系
TreeMap: 键(红黑树)HashMap: 键(哈希表)LinkedHashMap: 键(哈希表+双向链表)
HashMap底层是哈希表结构的- 依赖
hashCode方法和equals方法保证键的唯一 - 如果键存储的是自定义对象,需要重写
hashCode和equals方法
如果值存储自定义对象,不需要重写hashCode和equals方法

Stream流
- 配合
Lambda表达式,简化集合和数组操作
Stream流思想
- 将数据到流中 (获取流对象)
- 中间方法
- 终结方法
获取Stream流对象

获取Stream流对象: 将数据放在流中
-
集合获取Stream流对象
`Collection` : 直接调用默认方法 `stream()`即可 `Map` : 不能直接获取 `Stream`流对象, 只能间接获取 推荐: `map.entrySet().stream()` `map.keySet().stream();` // 只有键 `map.values().stream(); ` // 只有值 -
数组获取
Stream流对象`Arrays.stream`(数组); -
零散的数据获取
Stream流对象`Stream.of(1, 2, 3, 4, 5, 6);`
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("张三丰", 100);
map.put("张无忌", 35);
map.put("张翠山", 55);
map.put("王二麻子", 22);
map.put("张良", 30);
map.put("谢广坤", 55);
Stream<Map.Entry<String, Integer>> s1 = map.entrySet().stream();
s1.forEach(s -> System.out.println(s.getKey() + "---" + s.getValue()));
System.out.println("----------------------");
Integer[] arr = {11, 22, 33, 44, 55};
Stream<Integer> s2 = Arrays.stream(arr);
s2.forEach(s -> System.out.println(s));
System.out.println("----------------------");
Stream<Integer> s3 = Stream.of(1, 2, 3, 4, 5, 6);
s3.forEach(s -> System.out.println(s));
}
Stream流中间操作方法
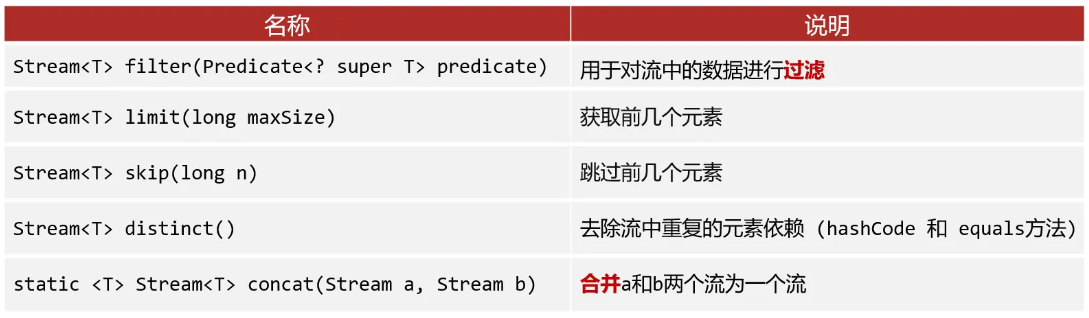
- 中间方法调用完成后返回新的
Stream流可以继续使用,支持链式编程
注意事项
- 如果流对象已经被消费过(使用过), 就无法再次使用了
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("林青霞");
list.add("张曼玉");
list.add("王祖贤");
list.add("柳岩");
list.add("张敏");
list.add("张无忌");
// 需求1:取前4个数据组成一个流
Stream<String> s1 = list.stream().limit(4);
// 需求2:跳过2个数据组成一个流
Stream<String> s2 = list.stream().skip(2);
// 需求3:合并需求1和需求2得到的流,并把结果在控制台输出
// Stream.concat(s1, s2).forEach(s -> System.out.println(s));
// 需求4:合并需求1和需求2得到的流,并把结果在控制台输出,要求字符串元素不能重复
Stream.concat(s1, s2).distinct().forEach(s -> System.out.println(s));
System.out.println(list.stream().count());
}
private static void method() {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "张良", "王二麻子", "谢广坤", "张三丰", "张翠山");
// 需求: 筛选出张开头的元素, 并且只要三个字的人名
list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(s -> System.out.println(s));
}
Stream流终结操作方法

Stream收集操作
- 把
Stream流操作后的结果数据转回到集合 Stream流操作,不会修改数据源

- 把
Stream流操作后的结果转回到集合

Collectors工具类提供了具体的收集方式

/*
保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值
*/
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("zhangsan,23");
list.add("lisi,24");
list.add("wangwu,25");
Map<String, Integer> map = list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
String[] arr = s.split(",");
int age = Integer.parseInt(arr[1]);
return age >= 24;
}
}).collect(Collectors.toMap(new Function<String, String>() {
@Override
public String apply(String s) {
return s.split(",")[0];
}
}, new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split(",")[1]);
}
}));
System.out.println(map);
}
private static void method() {
Set<Integer> set = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10)
.filter(s -> s % 2 == 0)
.collect(Collectors.toSet());
System.out.println(set);
}















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









