



❝
不调参数不训练,把梯度下降翻译成小作文批注——大模型:我骂我自己还越骂越强?
第一阶段:识别核心概念
论文的motivation分析
- 痛点 1:快速对齐。 现有 RLHF、DPO 等方法要想让大模型符合人类偏好,必须重新训练或微调权重;这既耗算力,又难以跟随需求变化。
- 痛点 2:反馈解释性。 训练阶段常用的“奖励分数”是纯数字,模型无法理解“为什么好、哪里坏”,导致改进过程不透明。
- 目标: 作者希望在推理阶段就能让模型边生成边自我纠偏,而且反馈应当是可读、可解释的文本,让模型自己“看懂”并迭代。
论文主要贡献点分析
| 类型 | 摘要式描述 | 关键技术/方法 | 重要结果或意义 |
|---|---|---|---|
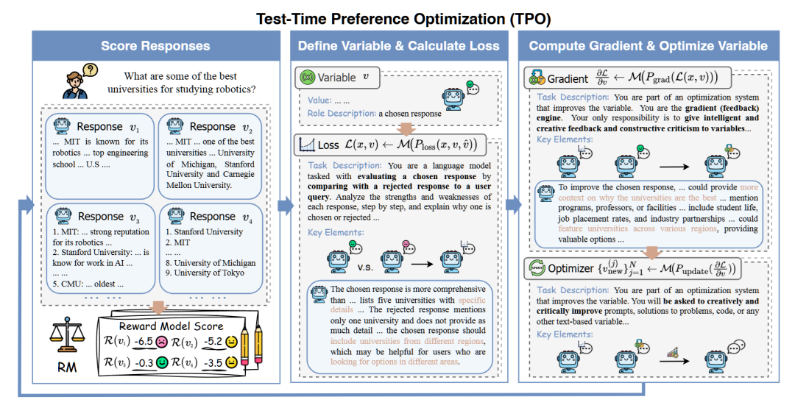
| 框架创新 | 提出 Test-time Preference Optimization (TPO):推理时对齐,无需改权重 | “文本损失 + 文本梯度 + 文本更新”三段式交互;利用奖励模型打分、政策模型自评 | 首次把“梯度下降”完全翻译成自然语言链式提示,实现“在场学习” |
| 交互机制 | 将数字奖励→“文本批评”,再→“改进建议” | 设计三类提示:Loss(批评)、Grad(提炼要点)、Update(重写输出) | 证明模型能连读带改,逐步提高奖励分数 |
| 实证性能 | 在 AlpacaEval 2、Arena-Hard、HH-RLHF 等六套基准上评测 | 未对齐的 Llama-3.1-70B-SFT + 2 步 TPO | 反超同尺寸的 Instruct 版本;小模型 Mistral-22B + TPO 刷新多项榜单 |
| 计算效率 | 仅靠推理算力,计算量 < 训练式 DPO 的 0.01% | 宽度(采样数)深度(迭代轮)可自由伸缩 | 为“用算力换效果”提供新维度,适合资源受限场景 |
理解难点识别
| 难点 | 说明 | 挑战点 |
|---|---|---|
| “文本梯度” | 把数字奖励“翻译”为自然语言理由,再让模型把理由提炼成可执行指令 | 如何保证指令既准确又可操作 |
| 变量重分布 | 不调参数,而靠上下文 Prompt 重分配概率质量 | 理解“上下文=参数”的思想转换 |
| 宽度-深度平衡 | 采样更多 vs. 多轮修订,二者如何权衡 | 衡量成本与收益 |
| 策略-奖励循环 | 模型先生成→奖励模型打分→再生成批评→改写 | 多重模型协同下的稳定性 |
概念依赖关系
1. 基础组件
- 政策模型(LLM):负责生成答案、解读批评、重写输出
- 奖励模型:向政策模型提供分数(人类偏好的替身)
2. 三步循环
- 文本损失:Chosen vs. Rejected → 为什么好/坏
- 文本梯度:从批评提炼“改进要点”
- 变量更新:依据要点重写多个候选,再打分
3. 依赖路径
- 没有奖励模型就没有批评 → 没有批评就无法产生梯度 → 没有梯度就无法更新输出
4. 最佳切入点
- 文本梯度机制是整条链的“发动机”,既连接数字世界与文字世界,又驱动输出迭代,是后续深入解释的首要核心概念。
第二阶段:深入解释核心概念
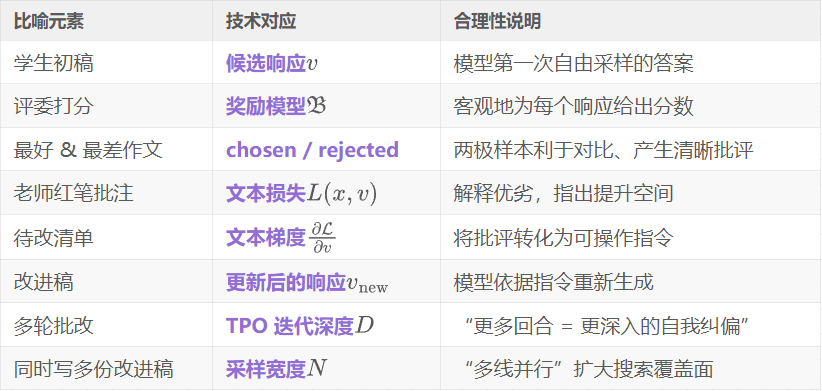
设计生活化比喻
“论文批改小组”
❝
场景:想像一位学生,正在课堂上参加“即时论文改写”竞赛。
- 学生先写出 初稿(对应模型第一次生成的答案)。
- 评委老师(奖励模型)快速给每篇作文 打分,选出最好与最差。
- 老师随后用红笔写下哪里写得好、哪里要改(文本损失)。
- 学生把老师的批注提炼成一张待改清单(文本梯度):哪些句子要扩充?有哪些逻辑要调整?
- 根据清单,学生立刻重写多份改进稿再交上去。
- 评委再次打分,如此循环 1–2 轮,直到计时结束,交出最高分作文。
这个课堂竞赛,就是 TPO 在推理时进行“自我批改”的缩影。
深入技术细节
说明技术实现中的关键步骤
1. 原始公式
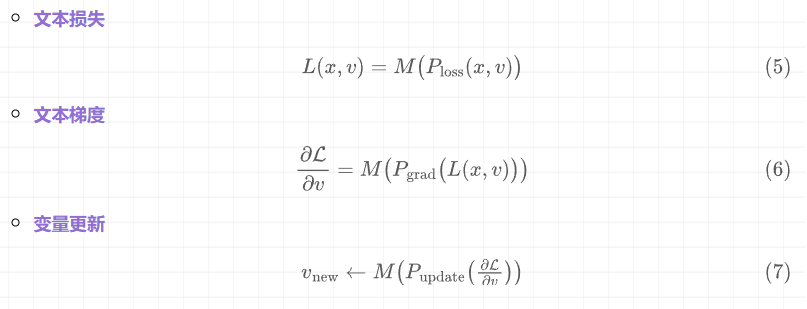
2. 符号替换版(自然语言解释)

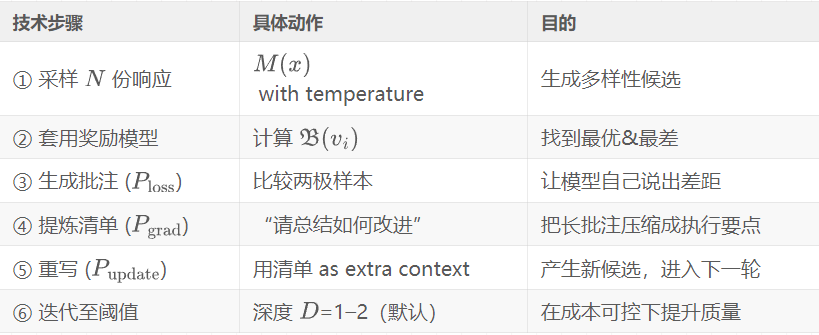
3. 关键步骤拆解
将技术细节与比喻相互映射
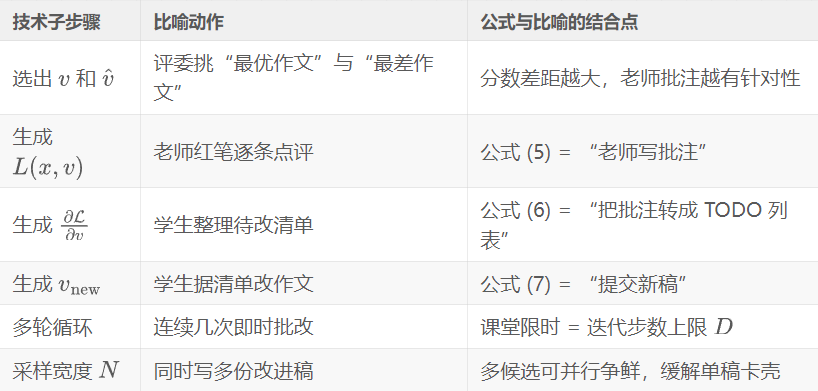
比喻优势与局限
- 优势:读者熟悉“老师改作文”流程,天然理解“批注→改稿→再评分”的闭环。
- 局限:现实课堂里老师是人,批注质量有随机性;TPO 中批注和改稿都由同一个大模型完成,存在自洽性风险,但比喻无法展示这一点。
总结

第三阶段:详细说明流程步骤
❝
目标:让从未读过原文的读者,仅凭下文即可写出可运行的 TPO 伪代码,并在本地复现论文主要实验。
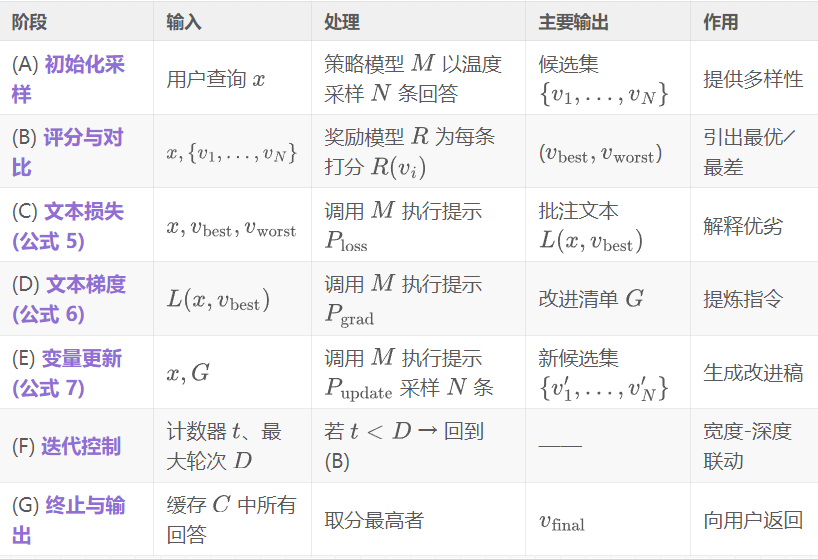
❝
原论文默认 , ;宽度╱深度可按算力调节。
# 输入: 用户问题 x
# 参数: 采样数 N, 迭代深度 D
# 模型: 策略模型 M, 奖励模型 R
# 提示模板: P_loss, P_grad, P_update
C = {} # 缓存 <答案, 分数>
# ---------- 初始化 ----------
V = \text{sample}(M, x, N) # (A)
for v in V:
C[v] = R(x, v) # (B)
for t in range(1, D+1):
v_best = \text{argmax}(C) # (B)
v_worst = \text{argmin}(C) # (B)
L_txt = M(P_{\text{loss}}(x, v_{\text{best}}, v_{\text{worst}})) # (C) 公式(5)
G_txt = M(P_{\text{grad}}(L_{\text{txt}})) # (D) 公式(6)
V_new = \text{sample}(M, P_{\text{update}}(x, G_{\text{txt}}), N) # (E) 公式(7)
for v in V_new:
C[v] = R(x, v) # 重新评分
# ---------- 结束 ----------
v_final = \text{argmax}(C) # (G)
return v_final
接口约定

端到端示例演练(, )
❝
用户输入:
轮次 1

轮次 2
- 加入缓存,重新找最优/最差,再走 C–E;
- 结束后,从缓存里挑总分最高的 ,返回给用户。
关键实现细节与调参建议

还原性检查
- 输入 → 输出链 已逐环给出;
- 伪代码中,每个函数输出直接喂入下一函数,无脱节;
- 按此步骤即可复现表 1 和表 2 的“D2-N5”行(若使用相同模型与数据集)。
题目:Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









