




Python
文档地址:https://www.python.org/doc/
中文文档地址:https://docs.python.org/zh-cn/3.8/py-modindex.html
python解析器
IDE:集成工具的缩写
作用:运行文件
- ipython:是一种交互式的解析器,可以实现变量自动保存、自动缩进
- cpython:c语言开发的官方解析器,应用广泛
- 其他解析器
一、注释
两种方式
# 单行注释
"""多行注释(三个双引号) """
'''多行注释(三个单引号)'''
# 快捷键:ctrl+/
二、变量
在程序中,数据都是临时存储在内存中,而变量就是一个存储数据的时候当前数据的内存地址的名字而已。
变量名=值 #这里没有说一定要指明变量的类型
变量名要符合标识符命名规则:
- 由数字、字母、下划线组成
- 不能是数字开头
- 不能使用内置关键字
- 严格区分大小写
命名习惯:
- 见名知意
- 大驼峰
- 小驼峰
- 下划线
三、数据类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rrGDIsU2-1635041569145)(%E7%AC%AC%E4%B8%80%E7%AB%A0.assets/image-20210906095622964.png)]](https://i-blog.csdnimg.cn/blog_migrate/54d86e342951387e2f9473fea6b9ac73.png)
字符串:String
元组型:数组
列表型:list类
字典型:map类
集合:set
布尔型:
代表False,数字代表0的,各种括号都是空的,这里的只有两个值,一个是True,一个是False检测数据类型:type(数据)
复数
定义一个复数
- 直接赋值给变量就可以了
- 使用complex
a=3+2j
print(a)
b=complex(3,4)
print(b)
(3+2j)
(3+4j)
获取复数的虚部和实部
a=3+2j
print(a)
print(a.real)
print(a.imag)
(3+2j)
3.0
2.0
四、输入输出
这里普通的输出,输出有三种方式
x =input('请输入一个整数')
print(x)
name='aabbcc'
age=20
str='我叫{},我今年{}岁'
print(str.format(name,age))
name='aabbcc'
age=20
print(f'我叫{name},今年{age}岁')
这里使用一个format函数,很灵活
s="今天在{}上课,上的是{}课"
print(s.format("6栋","python"))
今天在6栋上课,上的是python课
比较运算符
==表示字符相同而且对应的地址也要相同,equal表示字符相同就可以了。
- 使用的是$模板来实现变量输入
from string import Template
string =Template("祝你${x}快乐")
string.substitute(x='生日')
# 这个的好处就是可以随时改变x的数据类型以及数据
- 按照格式输入输出
import datetime
name = str(input("请输入您的姓名:"))
birthday =int(input("请输入您的出生年份:"))
age = datetime.date.today().year -birthday
print("%s您好! 您今年%d岁。"%(name,age))
这里是格式化输出
%s:字符串
%d:十进制整数
%f:浮点数
%c:字符
\n:换行
\t:制表符
输入
x =input('请输入一个整数')
print(x)
转换数据类型常见的函数
int()
float()
str()
list()
tuple() # 元组
eval() # 转换成原本的类型
五、运算
- 除法:
/表示带小数除法 //:表示整除- 次幂:2的8次幂表示:2**8
- 赋值运算,可以多个赋值,a=b=c=1; a,b,c,d=1,2,3,“aadd” ; 数据直接交换:x,y=y,x 可实现
- 逻辑运算:and 、or、not,表示与、或、非
in、not in表示在这个序列内就返回true,如果不是就返回false
for i in (1,23)
#for(int i=1;i<23;i++)
- 移位运算:左移变大,移动了多少次相当于乘多少次2;右移变小,相当于除于多少个2;空位都是补0
- 按位与、按位或、异或^、取反(按位取反+1)
- 动态变化:数据不会变,每一个数都有对应的地址,只是数字对应的标识会变
- ()表示范围或者表示优先级
# 讲一个运算逻辑
d=10
d*=1+2
print(d)
# 结果是30,首先算赋值运算右边的,再算左边的
六、条件语句
if……elif ……else
执行流程:当某一个代码符合条件就可以开始执行,而其他后面的代码都不会执行
age=50
if age < 18:
print(f'你的年龄是{age},你是童工')
elif (age>=18)and (age<=60):
print(f'你的年龄是{age},你是合法劳动人民')
else:
print(f'你的年龄是{age},你是退休工')
化简写法
elif 18<=age<=60
age=50
if age < 18:
print(f'你的年龄是{age},你是童工')
elif 18<=age<=60:
print(f'你的年龄是{age},你是合法劳动人民')
else:
print(f'你的年龄是{age},你是退休工')
随机数
random类
import random
x=random.randint(1,20)
print(x)
三目运算符
c=a if a>b else b
a=1
b=2
c=a if a>b else b
print(c)
七、循环
while语法
i=0;
while True:
if i==9:
break;
print(i)
i+=1 # 这里值得注意的是,i++是不存在的
-
break:终止循环
-
continu:终止当前的执行,循环的其他执行不受影响
for循环
for a in [1,10]:
print(a)
1
10
for i in range(1,10):# 这里值得注意的是,要使用range()函数
print(i)
while…else
循环正常结束之后才执行代码,不正常执行完不能执行代码
这是因为循环和else后面的内容有一定的依赖关系
# 正常结束的案例
i=0
while i<=5:
print(i)
i+=1
else:
print('end')
1
2
3
4
5
end
# break提前结束的案例
i=1
while i<=5:
if i==3:
print('发生错误')
break
print(i)
i+=1
else:
print('end')
1
2
发生错误
# continue提前结束的案例
i=0
while i<=5:
i+=1
if i==5:
print('发生错误')
break
print(i)
else:
print('end')
1
2
3
4
发生错误
for…else
和while一样,也是需要在程序正常结束的时候才会执行,如果程序不是正常结束的,else之后的东西是不会执行的.
for a in (1,10):
print(a)
else:
print('循环结束,打印响应')
八、字符串
- 单引号、双引号、三引号都可以引出字符串
name1='cch1'
name2="cch2"
name3='''cch3'''
- 输入输出
name=input('输入你的名字:')
print('我的名字是'+name)
print('我的名字是%s'%name)
print(f'我的名字是{name}')
-
[下标]
name[0]
九、切片
- 切片是指对操作的对象截取其中一部分的操作,字符串、列表、元组都支持切片。
语法
序列[开始位置的下表:结束位置的下表:步长]
注意的是:
- 不包含结束位置的下表对应的数据,正负数都可以
- 步长是选取间隙,默认是1(如果不写就是1),也可以自定义,正负数都可以
- 如果是负数,表示反向取值
- -1的小标默认是最后一个
str1='0123456'
print(str1[2:5:2])
# 结果是24
# 如果不写开始,默认从0开始
str1='0123456'
print(str1[:5:1])
# 结果是01234
# 如果不写结尾,默认选取到最后一个,而且包含最后一个
str1='0123456'
print(str1[3:])
# 结果是3456
# 如果步长为负数,表示倒序数数
str1='0123456'
print(str1[::-1])
# 结果是6543210
# 前面两个为负数
str1='0123456'
print(str1[-4:-1])
# 结果是345,因为不包含-1位置上的数,也就是不包含最后一个数字
# 三个数都是负数
str1='0123456'
print(str1[-4:-1:-1])
# 不能选取数据,因为两个方向互斥,从-4到-1是从左到右选取,但是-1步长表示从右向左选取
# 三个数都是负数
str1='0123456'
print(str1[-1:-4:-1])
# 543,因为选取的方向是一致的
十一、字符串str
常见的操作方法
查找
查找子串在字符串的位置或者出现的次数
-
find():检查某一个字串是否包含在字符串中,如果存在就返回到这个字串开始位置的下表,否则返回-1
-
注意:开始位置和结束位置可以省略,表示在整个字符串序列中查找
-
下面的是语法:
字符串序列.find(字串,开始位置下标,结束位置的下标)
# 这里可以省略开始和结束的位置的下标,
string='asdffgghfj'
print(string.find('sdf',2))
# 返回-1,因为从2位置开始的字串中没有包含我们要求的字串‘sdf’
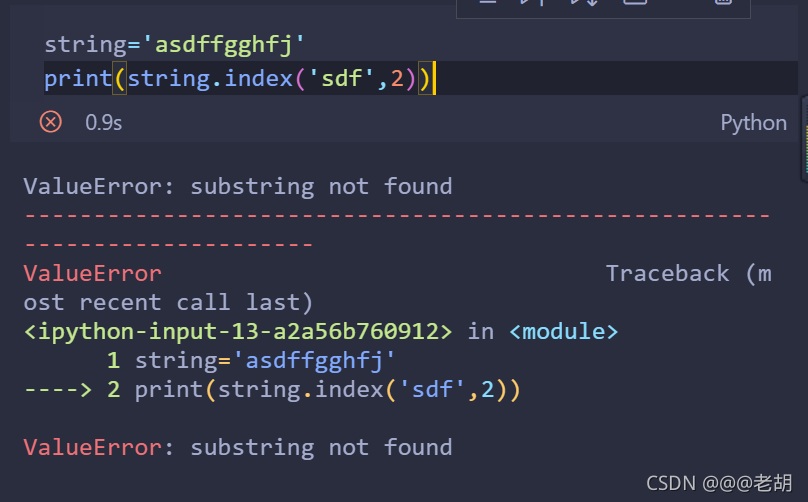
- index():检查某一个字串是否包含在这个字符串中,如果存在就返回这个字串开始的位置的下标,否则报错
- 下面是语法
字符串序列.index(字串,开始位置下标,结束位置的下标)
# 这里可以省略开始和结束的位置的下标,
string='asdffgghfj'
print(string.index('sdf',2))
- count():表示这个子串在字符串中出现的次数
- 如果不存在,次数是0
字符串序列.count(字串,开始位置下标,结束位置的下标)
# 这里可以省略开始和结束的位置的下标,
string='asdffgghfj'
print(string.count('sdf',2))
# 这里的结果是0
下面的功能和上面的对应功能是类似的,但是查找的方向是从右侧开始查找的,下表还是从左往右开始的
- rfind():
- rindex():
修改
- replace():替换,这个替换不会改变字串本身的值,它本身的函数会有一个返回值,表示修改后的结果,如果需要这个返回值,需要一个新的变量来赋值
- 这里也就是说,字符串是不可变类型,因为我们对字串的操作,都没有改变到它本身的值
- 语法如下:
字符串序列.replace(旧字符,新字符,替换次数)
# 替换次数可以不写,不写表示全部替换;如果替换次数>字串出现次数,表示全部替换,但是不会报错
string='asdffgghfj'
print(string.replace('f',' False '))
# 结果:asd False False ggh False j
- split():返回一个列表,这个方法会丢失分割的符号
- 语法:
string.split(分割的字符,num)
# num表示分割字符出现的次数,也就是返回的数据个数为num+1个
string='asd False False ggh False j'
print(string.split('False'))
# 输出结果:['asd ', ' ', ' ggh ', ' j'],这里可以看到,全部都分割了,而且False本身就已经去掉了
string='asd False False ggh False j'
print(string.split('False',2))
# 这里的结果是:['asd ', ' ', ' ggh False j'],这里可以看到,这里会返回2+1 个数据,也就是只分割前面的2个数据
- join():合并列表中的字串为一个大的字串
- 语法如下:
字符或者子串.join(多字串组成的序列)
# 字符或者子串 表示你想要用什么方法来连接这个序列里面的内容
list=['aa','bb','cc']
string='...'.join(list)
print(string)
# 结果是:aa...bb...cc
- capitalize():将第一个字符转换成大写字符,当然其他地方的大写字符也会转换成小写的。
- 语法如下:
字符串.capitalize()
string='asd False False ggh False j'
print(string.capitalize())
# Asd false false ggh false j
- title():将所有的字符的首字母转换换成大写字母,其他地方的大写字母会变成小写字母。
- 语法如下:
字符串.title()
string='asd False False ggh False j'
print(string.title())
# Asd False False Ggh False J
- lower():大写转小写
- upper():小写转大写
这里还要说一次:字符串的函数不会对字符串本身进行修改,而是会有一个返回值,修改后的结果就在返回值中。
-
删除字符串的空白字符
-
lstrip():删除左边的空白字符
-
rstrip():删除右边的空白字符
-
strip():删除左边和右边的空白字符
string=' asd False False ggh False j '
print(string.rstrip())
# asd False False ggh False j
- 字符串对齐
- ljust():返回一个原字符串左对齐,并且使用指定字符(默认空格)填充起对应长度的新字符
- 语法:
string.ljust(长度,填充字符)
string="aabbcc"
print(string.ljust(10,'*'))
# aabbcc****
- rjust():右边对齐
- center():中间对齐
string="aabbcc"
print(string.rjust(10,'*'))
# ****aabbcc
string="aabbcc"
print(string.center(10,'*'))
# **aabbcc**
string="aabbcc"
print(string.center(9,'*'))
# **aabbcc*
如果中间对齐,出现到填充字符字符为奇数的时候,是做不到绝对对齐的
判断
判断函数返回的结果为False或者是True
-
判断开头结尾
-
startswith():检查字串是否在指定的范围内以指定字串开头,是就返回True,否则返回False
-
语法:
string.startswith(子串,开始位置下标,结束位置下标)
# 后面两个参数可省略
- endswith():检查字串是否在指定的范围内以指定字串结尾,是就返回True,否则返回False
- 语法:
string.endswith(子串,开始位置下标,结束位置下标)
# 后面两个参数可省略
string='asd False False ggh False'
print(string.endswith('false'))
# False
这里值得注意的是,这里是严格区分大小写的
- 判断字符串是否全是字母或者数字
- isalpha():如果是全是至少一个字符并且所有字符都是所有字符,都是字母就返回真,否则返回假
- isdigit():如果全是数字就返回真。
string1='hello'
string2='hello123'
string3='Hello'
string4='123'
print(string1.isalpha())
print(string2.isalpha())
print(string3.isalpha())
print(string4.isdigit())
# True
# False
# True
# True
这个不论大小写
- isalnum():全都是字母或者是数字就是真
- isspace():全都是空白就是真
string1=' '
string2='hello123'
print(string1.isspace())# True
print(string2.isalnum())# True
十二、列表list
存储多个数据,并且数据是可以被修改的就是列表。
格式
[数据1,数据2,数据3……]
列表可以存储很多的数据,也可以存储不同数据类型的数据,但是在实际业务中,我们一般都是同一个列表存储同一种数据类型
常用操作
查找
下标
name=['aaa','bbb','ccc']
print(name[0])
# aaa
函数
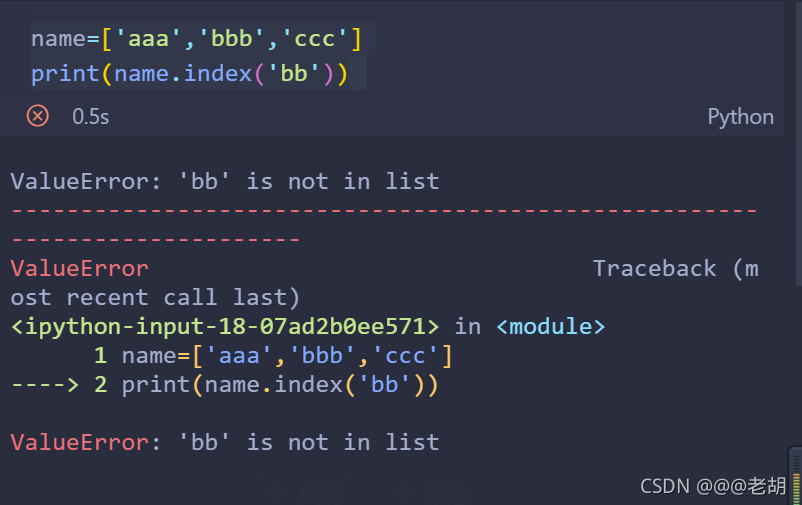
- index():返回指定的数据所在位置的下标,但是如果没有出现就会报错
- 语法:
list.index()
name=['aaa','bbb','ccc']
print(name.index('bb'))
- count():指定数据在当前列表出现的次数
- 语法:
list.count()
- len():范文列表的长度,表示列表数据的个数
- 语法:
len(list_name)
# 返回一个数字
name=['aaa','bbb','ccc']
print(len(name))
print(type(len(name)))
# 3
# <class 'int'>
判断
返回值位True或者False
- in:判断指定数据是否存在某一个列表序列,在就是真
- not in:判断指定数据不在某一个列表序列,不在就是真
- 语法
数据 in list_name
shuju1 not in list_name
name=['aaa','bbb','ccc']
print('aaa' in name)
print('aa' in name)
print('aa' not in name)
# True
# False
# True
增加
增加指定数据到列表
- append():列表结尾追加数据
- 语法:
list.append(数据)
name=['aaa','bbb','ccc']
name.append('ddd')
print(name)
# ['aaa', 'bbb', 'ccc', 'ddd']
可以追加列表序列
name=['aaa','bbb','ccc']
name.append([11,22])
print(name)
# ['aaa', 'bbb', 'ccc', [11, 22]]
注意的是,一次只能追加一个数据,不能同时追加多个数据
- extend():列表末尾追加数据
- 语法
list.extend(数据)
这里和上面不同的是,这里追加序列的时候,会把序列拆开
name=['aaa','bbb','ccc']
name.extend('ddd')
print(name)
# ['aaa', 'bbb', 'ccc', 'd', 'd', 'd']
# 这里的‘ddd’也算是一个序列,所以要拆开
name=['aaa','bbb','ccc',12]
name.extend([10,13])
print(name)
# ['aaa', 'bbb', 'ccc', 12, 10, 13]
name=['aaa','bbb','ccc',12]
name.extend(10)
print(name)
# TypeError: 'int' object is not iterable
# int不是可以迭代的类型,不能直接extend
name=['aaa','bbb','ccc',12]
name.extend(range(1,2))
print(name)
# ['aaa', 'bbb', 'ccc', 12, 1]
- insert():在指定位置中插入数据
- 语法:
list.insert(下标,数据)
name=['aaa','bbb','ccc',12]
name.insert(2,'ddd')
print(name)
# ['aaa', 'bbb', 'ddd', 'ccc', 12]
我们要注意的是,增加的这一部分其实是在列表本身中增加的,已经是修改了列表本身的数据了,这一点和str类型不一样
删除
- del :值得注意的是,这里删除之后再访问是会报错的
- 语法:
del 目标
del(目标)
# 删除指定位置的数据
del list[下标]
name=['aaa','bbb','ccc',12]
del name
print(name)
# NameError: name 'name' is not defined
name=['aaa','bbb','ccc',12]del name[0]print(name)# ['bbb', 'ccc', 12]
- pop:删除指定位置的数据,如果不指定默认删除最后一个数据;无论删除的是什么数据,pop都会返回这个被删除的数据
- 语法:
list.pop(下标)
name=['aaa','bbb','ccc',12]a=name.pop()print(name)print(a)# ['aaa', 'bbb', 'ccc']# 12
这个方法不能删除多个数据
- remove():删除指定的数据
- 语法:
list.remove(指定的数据)
name=['aaa','bbb','ccc',12]name.remove(12)print(name)# ['aaa', 'bbb', 'ccc']
- clear():清空列表,最后得到的是一个空列表,最后打印的时候是一个空列表,而不是报错
- 语法:
list.clear()
name=['aaa','bbb','ccc',12]name.clear()print(name)# []
删除数据也是在列表本身删除的
修改
- 修改指定位置的下表,直接用赋值语句就可
name=['aaa','bbb','ccc',12]name[0]='gdhhhr'print(name)# ['gdhhhr', 'bbb', 'ccc', 12]
- reverse():逆序排列
name=['aaa','bbb','ccc',12]name.reverse()print(name)# [12, 'ccc', 'bbb', 'aaa']
- sort():排序算法,默认是升序排序
- 语法:
list.sort(key=None,reverse=False)# key是在字典中按照字典某一个值来排序,reverse=False表示升序,reverse=True表示降序
name=[1,2,3,4,6,7,5]name.sort()print(name)# [1, 2, 3, 4, 5, 6, 7]
name=[1,2,3,4,6,7,5]name.sort(reverse=True)print(name)# [7, 6, 5, 4, 3, 2, 1]
复制
-
copy():复制函数有返回值,是复制之后的数据,一般用来保留源数据
-
语法:
list.copy()
列表的循环遍历
i=0name=[1,2,3,4,6,7,5]while i<len(name): print(name[i] ,end=' ') i+=1# 1 2 3 4 6 7 5
name=[1,2,3,4,6,7,5]for i in name: print(i,end=' ')# 1 2 3 4 6 7 5
列表嵌套
name=[[1,2,3],[23,34,45],[234,456,789]]for i in name: print(i,end=' ')# [1, 2, 3] [23, 34, 45] [234, 456, 789]
name=[[1,2,3],[23,34,45],[234,456,789]]for i in name: for j in i: print(j,end=' ')# 1 2 3 23 34 45 234 456 789
十三、元组tuple
存储多个数据,数据不能被修改的,用小括号
获取某一个下标的数据:tuple[i]
格式
使用小括号
name=(10,20)
这里要注意的是,如果定义的元组只有一个数据,这个数据后面也要添加逗号,不然这个数据的类型会为唯一的数据的数据类型
name=(10)name1=(10,)print(type(name))print(type(name1))# <class 'int'># <class 'tuple'>
元组的常用操作
因为元组不支持修改操作,只支持查找操作,所以这里的操作都是查找操作
- index():如果不存在这个数据会报错
- 语法
tuple.index(e,start,end)
a=(11,22,33,44)print(a.index(11))
-
count()
-
语法:
tuple.count()
- len()
- 语法:
tuple.len()
修改
元组中嵌套列表,这个列表内容是支持修改的
十四、字典 dict
- 字典的数据都是按照键值对的形式出现,字典的数据是没顺序的,不支持下标寻找数据
- 字典的符号是大括号
- 数据是各个键值对的形式出现
- 每一个键值对之间用逗号隔开
创建字典
a={'name':'Tom','age':20,'gender':'男'}a=dict()a={}
字典常见操作
字典是可变类型,也就是对字典的修改是在字典本身的数据上修改的,这一年和list一样
增
写法:dictName[key]=value
如果key存在就修改value,如果不存在就新增这个键值对
a={'name':'ccc','age':20}a['name']='cch'print(a)# {'name': 'cch', 'age': 20}
a={'name':'ccc','age':20}a['id']=1print(a)# {'name': 'ccc', 'age': 20, 'id': 1}
删
- del()删除字典或者指定的键值对
a={'name':'ccc','age':20}del(a)print(a)# NameError: name 'a' is not defined
a={'name':'ccc','age':20}del a['name']print(a)# {'age': 20}# 如果不存在就会报错
- clear()
a={'name':'ccc','age':20}a.clear()print(a)# {}
改
写法:字典序列[key]=value,其实和增加么有区别
a={'name':'ccc','age':20}a['name']='cch'print(a)# {'name': 'cch', 'age': 20}
查
- key查找,如果key不存在就会报错
a={'name':'ccc','age':20}print(a['name'])# ccc
- get():如果当前的key找不到或者不存在,就会返回第二个参数(也就是默认值),如果第二个参数省略None
- 语法
字典序列.get(key,默认值)
a={'name':'ccc','age':20}
print(a.get('id',1))
# 1
- keys():返回所有的keys,keys返回的是可以迭代的对象
a={'name':'ccc','age':20}
print(a.keys())
# dict_keys(['name', 'age'])
- values():返回当前字典的所有值,也是可迭代的对象
a={'name':'ccc','age':20}
print(a.values())
# dict_values(['ccc', 20])
- items():返回的是每一个键值对,也是可迭代的对象,里面的数据都是一个元组
a={'name':'ccc','age':20}
print(a.items())
# dict_items([('name', 'ccc'), ('age', 20)])
遍历
这里我解析的是拆包
a={'name':'ccc','age':20}
for key,value in a.items():
print(f'{key}={value}')
# name=ccc
# age=20
十五、集合 set
创建集合
- 创建集合可以使用
{}或者set(),但是如果要创建一个空的集合只能使用set(),因为{}用来创建一个空的字典 - 为什么需要集合:因为集合的数据可以去重,也就是数据中是没有重复的数据的
- 集合是没有顺序的,所以也不可以使用下标
- 集合是可变类型,也就是修改是在本来的集合中修改的
set1={12,10,28,28,28}
print(set1)
# {10, 12, 28}
set2=set()
print(set2)
# set()
set1={'abcfdhdjfdj'}
print(set1)
# {'abcfdhdjfdj'}
set2=set('qwert')
print(set2)
# {'q', 't', 'w', 'r', 'e'}
# 这里没有按照顺序来输出
集合的常见操作方法
增
- add():添加数据,因为集合有去重功能,所以如果是追加已经有的数据是不生效的
set1={12,23,45,2}
set1.add(10)
print(set1)
# {2, 10, 12, 45, 23}
set1={12,23,45,2}
set1.add(10,11)
print(set1)
# TypeError: add() takes exactly one argument (2 given)
- update():追加的是序列
set1={12,23,45,2}
set1.update([10,11])
print(set1)
# {2, 10, 11, 12, 45, 23}
删
- remove():删除指定的数据,如果数据不存在会报错
set1={12,23,45,2}
set1.remove(12)
print(set1)
# {2, 45, 23}
- discard():删除集合中指定给的数据,入股数据不存在也不会报错,只是会不操作而已
set1={12,23,45,2}
set1.discard(10)
print(set1)
# {2, 12, 45, 23}
- pop():随机删除一个数据,并且返回这个数据
set1={12,23,45,2}
num=set1.pop()
print(set1)
print(num)
# {12, 45, 23}
# 2
查找
- in:判断数据是不在是集合数列中
- not in:判断数据是否不在数据中
set1={12,23,45,2}
print(10 in set1)
print(10 not in set1)
# False
# True
十六、公共运算符
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jMs7B1v7-1635041569157)(%E7%AC%AC%E4%B8%80%E7%AB%A0.assets/image-20210929094723457.png)]](https://i-blog.csdnimg.cn/blog_migrate/79155da37aa5976f13557b229006aa12.png)
十七、公共方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qu0g8wJg-1635041569158)(%E7%AC%AC%E4%B8%80%E7%AB%A0.assets/image-20210929095120335.png)]](https://i-blog.csdnimg.cn/blog_migrate/2eacd85dfd6262ce36853ca6a3bc6ff6.png)
- range(start,end,step),如果只有一个数据表示end,然后开始是从0开始,不包含end的位置
for i in range(10):
print(i)
# 0 1 2 3 4 5 6 7 8 9
- enumerate():返回结果是一个元组,元组第一个数据是原迭代数据对象的下标,第二个数据是原迭代的数据,而且这里的start是代表下标的起始值
- 语法
enumerate(可遍历对象,start=0)
# start参数是用来设置数据的下标起始值,默认是0
list1=[1,2,3,4,5,6]
for i in enumerate(list1):
print(i,end=" ")
# (0, 1) (1, 2) (2, 3) (3, 4) (4, 5) (5, 6)
- 这个例子说明了下标从1开始迭代的情况
list1=[1,2,3,4,5,6]
for i in enumerate(list1,1):
print(i,end=" ")
# (1, 1) (2, 2) (3, 3) (4, 4) (5, 5) (6, 6)
十八、容器类型的转换
-
tuple():将数据转变成元组
-
list():将数据转变成列表
-
set():将数据转变成集合,可以去重
十九、推导式
在python中,只有列表、字典、集合才有推导式
推导式又叫生成式
推导式是为了化简代码来使用的。
列表推导式
=作用:用一个表达式创建一个有规律的列表或者控制一个有规律的列表。=
-
这里特别值得注意的是,这里的有规律说的是列表的内容是有规律的。
-
列表推导式又叫列表生成式
-
需求:生成一个有规律的列表
这里是常规的写法
list1=[]
i=0
while i<10:
list1.append(i)
i+=1
print(list1)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
这里演示一个推导式的实现
list1=[i for i in range(10)]
print(list1)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
带if的列表推导式
需求:创建0-10的偶数列表
- 使用range()步长实现
list1=[i for i in range(0,10,2)]
print(list1)
# [0, 2, 4, 6, 8]
- 使用if实现
list1=[i for i in range(0,10) if i%2==0]
print(list1)
# [0, 2, 4, 6, 8]
多个for循环实现列表推导式
需求:创建一个如下的列表:
[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
- 常规写法:
list2=[]
for i in range(1,3):
for j in range(3):
list2.append((i,j))
print(list2)
- 推导式
list1=[(i,j) for i in range(1,3) for j in range(3)]
print(list1)
字典推导式
字典推导式的作用:将两个列表快速合并成为一个字典
- 创建一个key是1-5的数字,value是这个数字的平分
dict1={i:i**2 for i in range(1,5)}
print(dict1)
# {1: 1, 2: 4, 3: 9, 4: 16}
- 将两个列表合并成为一个字典
list1=[1,2,3]
list2=[1,4,9]
dict2={list1[i]:list2[i] for i in range(len(list1))}
print(dict2)
# {1: 1, 2: 4, 3: 9}
- 列表的数据长度不一致的时候出现的情况
list1=[1,2,3]list2=[1,4]dict2={list1[i]:list2[i] for i in range(len(list1))}print(dict2)
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-14-96a775aca203> in <module>
1 list1=[1,2,3]
2 list2=[1,4]
----> 3 dict2={list1[i]:list2[i] for i in range(len(list1))}
4 print(dict2)
<ipython-input-14-96a775aca203> in <dictcomp>(.0)
1 list1=[1,2,3]
2 list2=[1,4]
----> 3 dict2={list1[i]:list2[i] for i in range(len(list1))}
4 print(dict2)
IndexError: list index out of range
所以我们在这里应该要注意到,如果两个列表的长度是相同的,可以随意取list1或者list2的长度,结果都是一样的,但是如果长度不一致,就要取长度比较短的那个列表的数据的长度,否则会出现报错
- 提取字典中目标数据
正常解题思路:
counts={'MBP':258,'HP':20,'LENOVO':199}
count1={}
for key,value in counts.items():
if value>100:
count1[key]=value
print(count1)
推导式:
counts={'MBP':258,'HP':20,'LENOVO':199}count1={key:value for key,value in counts.items() if value>100}print(count1)
结果:
{'MBP': 258, 'LENOVO': 199}
集合推导式
需求:创建一个集合,数据位列表数据的2次方,这里要注意的是,set是有去重效果的
list1=[1,1,2]set1={i**2 for i in list1}print(set1)# {1,4}
二十、函数
python中,函数必须是先定义再使用
格式
def 函数名(参数):
代码1
代码2
...
函数的返回值在python中是不用在函数名字前面写返回值的,直接return就可以了
函数的说明文档
查看函数说明文档
help(函数名字)
定义说明文档:当且仅当只能在函数的第一行缩进用多行注释的方式写才可以被当做说明文档
- 这里举一个例子
def delSameListElement(List1,temp):
"""
定义一个函数,表示删除一个列表中的重复数据。
它使用了一个temp来把list的的非重复数据挑出来。
"""
for i in List1:
if i in temp:
continue
else:
temp.append(i)
return 0;
temp=[]
List1 = [0, 1, 2, 3, 4, 1,1]
delSameListElement(List1,temp)
print(temp)
help(delSameListElement)
- 结果展示
[0, 1, 2, 3, 4]Help on function delSameListElement in module __main__:delSameListElement(List1, temp) 定义一个函数,表示删除一个列表中的重复数据。 它使用了一个temp来把list的的非重复数据挑出来。
函数的返回值
这里讲的函数的返回值是针对函数有多个返回值的情况。
如果有多个return的值,返回的是一个元组,return也可以返回列表、元组、字典等
def return_num(): return 1,2num1=return_num()print(num1)# (1, 2)
参数
位置参数
和我们正常的参数基本没有区别,也就是函数的调用的时候,参数的顺序要和函数本身的顺序是一致的,不然就会报错
关键字参数
函数的调用,通过”键=值“的形式加以指定,可以使得函数更加清晰,而且更加容易使用,也能清除参数的顺序的需求
def return_num(name,age,gender): print(f'名字:{name},年龄:{age},性别:{gender}')return_num('Rose',gender='女',age=20)#名字:Rose,年龄:20,性别:女
函数调用的时候,如果有位置参数,位置参数必须在关键字参数的见面,但是关键字参数之间不存在先后顺序
缺省参数
缺省参数也叫默认参数,用来定义函数,为函数提供默认值,函数调用的时候可以不传默认参数的值(注意:所有位置参数也必须要出现在默认参数值的前面,包括函数的定义和调用)
def return_num(name,age,gender='男'): print(f'名字:{name},年龄:{age},性别:{gender}')return_num('Tom',age=20)return_num('Rose',age=20,gender='女')
名字:Tom,年龄:20,性别:男名字:Rose,年龄:20,性别:女
函数调用的时候,如果缺省就会直接调用默认值
不定长参数
也叫可变参数,用于不确定调用的时候需要传递多少个参数,这个时候可以用包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会显得非常方便。
- 包裹位置传递-使用
*args
def return_num(*args): print(args)return_num('Tom',10)return_num('Rose',20,'女')
('Tom', 10)('Rose', 20, '女')
传入的参数都会被args变量收集,它会根据传进的参数的位置合并为一个元组,这就是包裹位置传递
- 包裹关键字传递
def return_num(**kwargs):
print(kwargs)
return_num(name='Tom',age=10)
{'name': 'Tom', 'age': 10}
最后返回的是一个字典类型
无论是包裹位子传递还是包裹关键字传递,都是一个组包的过程
拆包
- 元组拆包
def return_num():
return 100,200 #这里返回的是一个元组
num1,num2=return_num()
print(num1)
print(num2)
100
200
- 字典拆包
dict1={'name':'Tom','age':10}
a,b=dict1 #取出来的是keys
print(a)
print(b)
print(dict1[a])
print(dict1[b])
nameageTom10
交换变量值
- 借助第三个变量来存储数据,java经常使用
- 直接交换
a,b=1,20
a,b=b,a
print(a,b)
# 20 1
二十一、引用
在python中,值都是靠引用来传递的
我们可以用id()来判断两个变量是否是同一个值的引用,我们可以讲id理解为那块内存的地址的标识
- 不可变类型
a=1
b=a
print(id(a))
print(id(b))
a=2
print(b)#说明int类型是不可变的数据
print(id(a))
print(id(b))
140712497063728
140712497063728
1
140712497063760
140712497063728
我们可这样理解,我们每定义一个数据,就会开辟一个内存,变量是对这个数据的地址的引用。
int类型的数据是不可变数据
- 可变类型
aa=[11,22]bb=aaprint(id(aa))print(id(bb))aa.append(33)print(id(aa))print(id(bb))
2325297783432
2325297783432
2325297783432
2325297783432
引用当做实参
就是正常把变量传入到函数调用这边
二十二、可变和可变类型
- 可变类型
- 列表
- 字典
- 集合
- 不可变类型
- 整形
- 浮点型
- 字符串
- 元组
二十三、递归
学过省略
二十四、lambda表达式
和java的一样,当一个函数有一个返回值,并且只有一句代码,可以使用lambda
表达式
语法
这里值得注意的是:
- 表达式必须要有一个返回值
- 参数列表可有可无
lambda 参数列表:表达式
体验案例
- 无参数
def fn1():
return 200
print(fn1)
print(fn1())
fn2=lambda:100
print(fn2)
print(fn2())
<function fn1 at 0x00000229F25F4280>
200
<function <lambda> at 0x00000229F1A14F70>
100
- 有参数
def fn1(a,b): return a+bprint(fn1(1,2))fn2=lambda a,b:a+bprint(fn2(1,2))
33
- 默认参数
def fn1(a,b,c=100): return a+b+cprint(fn1(1,2))fn2=lambda a,b,c=100:a+b+cprint(fn2(1,2))
103103
- 可变参数 *args
def fn1(*args):
return args
print(fn1(1,2))
fn2=lambda *args:args
print(fn2(1,2))
(1, 2)
(1, 2)
def func(a,*b):
for item in b:
a += item# 拆包
return a
m = 0
print(func(m,1,1,2,3,5,7,12,21,33))
# 85
- 可变参数 *kwargs
def fn1(**kwargs):
return kwargs
dict1=fn1(name='Tom',age=20)
print(dict1)
fn2=lambda **kwargs:kwargs
print(fn2(name='Rose',age=10))
{'name': 'Tom', 'age': 20}{'name': 'Rose', 'age': 10}
lambda应用
带有判断的lambda
fn1=lambda a,b:a if a>b else bprint(fn1(1,290))# 290
列表数据按照字典key排序
students=[{'name':'Tom','age':10},{'name':'Rose','age':20},{'name':'Jack','age':30}]#按照name值升序排序students.sort(key=lambda x:x['name'])print(students)#按照name降序排序students.sort(key=lambda x:x['name'],reverse=True)print(students)
[{'name': 'Jack', 'age': 30}, {'name': 'Rose', 'age': 20}, {'name': 'Tom', 'age': 10}][{'name': 'Tom', 'age': 10}, {'name': 'Rose', 'age': 20}, {'name': 'Jack', 'age': 30}]
二十五、内置高阶函数
把函数作为参数传入,这样的函数叫做高阶函数,高阶函数是函数式编程的体现。
abs-不是高阶函数
对数字求绝对值
round-不是高阶函数
对函数进行四舍五入
print(round(1.5))# 2
map函数
- ==map(func,list)==是 Python 内置的高阶函数,它接收一个函数 func 和一个 list,并通过把函数 func 依次作用在 list 的每个元素上,得到一个新的 list(python2)或者迭代器(python3) 并返回。
# 这个的功能是把列表中的数据都变成它的平方值def f(x): return x*xprint(list(map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])))# [1, 4, 9, 10, 25, 36, 49, 64, 81]
注意:
- 由于list包含的元素可以是任何类型,因此,map() 不仅仅可以处理只包含数值的 list,事实上它可以处理包含任意类型的 list,只要传入的函数f可以处理这种数据类型。
reduce函数
reduce(func,list)其中func必须要有两个参数,每一次func的计算结果继续和序列的下一个元素做累计运算
import functools
list1=[1,2,3,4]
def fun(a,b):
return a+b
result=functools.reduce(fun,list1)
print(result)
# 10
import functools
list1=[1,2,3,4]
def fun(a,b):
return a-b
result=functools.reduce(fun,list1)
print(result)
# -8
filter函数
filter(func,list)函数用来过滤掉不符合条件的元素,返回一个filter对象,这里对象可以转换成其他的数据类型比如list
list1=[1,2,3,4,5,6,79.7]
def fun(x):
return x%2==0
result=filter(fun,list1)
print(result)
print(list(result))
<filter object at 0x000002011BE270A0>[2, 4, 6]
zip函数
-
函数原型:
zip(*iterables),可以传入不定长的参数 -
该函数以一系列列表作为参数,将列表中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
eval函数
-
eval(<字符串>)能够以Python表达式的方式解析并执行字符串,并将返回结果输出。 -
eval函数的作用是将输入的字符串转为Python语句,并执行该语句
二十六、文件操作
文件的基本操作
- 打开文件
- 读写等操作
- 关闭文件
打开
使用open函数,可以打开一个已经存在的文件,或者如果这个文件不存在可以创建一个新的文件
对象=open(name,mode)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等
快速体验
f=open('test.txt','w')f.write('cch')f.close()
访问模式
r:只读,如果文件不存在就会报错,r也不支持写,因为r代表只读
w:写,如果文件不存在,就会新建一个文件;如果文件存在,就会从头开始编辑,也就是原来的内容会被覆盖
a:追加,如果文件存在就追加,如果文件不存在就会新建并且写入
如果访问模式省略,表示文件只读(r)
带有b的:表示二进制文件形式
带有+的:表示可读可写模式
前缀的理解:后面的追加都是基于前缀的模式来进行拓展,都要满足前缀要求的条件
文件指针:r和w都是在文件开头,a是在文件结尾
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L5VDbCFk-1635041569159)(%E7%AC%AC%E4%B8%80%E7%AB%A0.assets/image-20211020211042979.png)]](https://i-blog.csdnimg.cn/blog_migrate/521e8e6e5571931b257bd7c19d950321.png)
f=open('test.txt','r')a=f.read()print(a)f.close()
cch
f=open('test.txt','a')f.write('cch')f.close()# cchcch
读
- read()
文件对象.read(num)# num表示从文件中读取数据的长度(单位是字节),如果没有传入num,表示读取全部内容
#txt中的内容I can't conceivable that the number of suicies has reached 30-year high in American
f=open('test.txt','r')a=f.read(10)print(a)f.close()#I can't co#这里值得注意的是,空格也是占用了一个字节的
- readlines()
可以按照行的方式把整一个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素,并且把换行符号一起返回打印出来
f=open('test.txt','r')a=f.readlines()print(a)f.close()
["I can't conceivable that the number of suicies has reached 30-year high in American\n", 'brilliance\n', 'universal\n', 'ultimate']
- readline()
默认第一次读第一行内容,第二次读第二行内容,以此类推
f=open('test.txt','r')a=f.readline()print(a)a=f.readline()print(a)f.close()
I can't conceivable that the number of suicies has reached 30-year high in Americanbrilliance
移动指针位置
- seek()
作用:用来移动文件指针
文件对象.seek(偏移量,起始位置)
起始位置:
- 0:文件开头
- 1:当前位置
- 2:文件结尾
- 开头
f=open('test.txt','r')
f.seek(2,0)
a=f.read()
print(a)
f.close()
这个例子代表的是,从开头位置开始,偏移2位也就是开头两个不能要,其他的都可以读取
can't conceivable that the number of suicies has reached 30-year high in American
brilliance
universal
ultimate
- 结尾
f=open('test.txt','r')
f.seek(0,2)
a=f.read()
print(a)
f.close()
二十七、面向对象
面向对象就是将编程当做一个事务,对于外界来讲,事务是直接使用的,不用去管他内部的情况,编程就是设置事务能做什么事情
二十八、类和对象
定义一个类和对象
- 创建经典类
类名遵循大驼峰的命名习惯
class 类名:
...
- 创建新式类
- 这种默认是继承object类,但是可以修改
class 类名(object):
...
- 创建对象
对象名=类名()
- 实例
# 定义一个类
class Wahser():
def wash(self):
print('洗衣服ing...')
# 定义一个对象
haier=Wahser()
haier.wash()
# 洗衣服ing...
self
self是指调用这个函数的对象
# 定义一个类
class Wahser():
def wash(self):
print('洗衣服ing...')
print(self)
# 定义一个对象
haier=Wahser()
print(haier)
haier.wash()
<__main__.Wahser object at 0x00000204C2298D00>
洗衣服ing...
<__main__.Wahser object at 0x00000204C2298D00>
添加或者获取属性
对象的属性既可以在类外面添加获取,也可以在类里面添加获取
在类外面添加并获取对象属性
#添加
对象名.属性名=值
#获取
对象名.属性名
# 定义一个类
class Wahser():
def wash(s):
print('洗衣服ing...')
# 定义一个对象
haier=Wahser()
haier.width=500
haier.higth=600
print(f'宽度{haier.width},高度{haier.higth}')
haier.wash()
宽度500,高度600
洗衣服ing...
在类里面获取对象属性-self
这里一定要注意的是,这里的属性一定要先定义好再调用
self.属性名
# 定义一个类
class Wahser():
def wash(self):
print('洗衣服ing...')
print(f'宽度{self.width},高度{self.higth}')
# 定义一个对象
haier=Wahser()
haier.width=500
haier.higth=600
haier.wash()
洗衣服ing...
宽度500,高度600
魔法方法
在python中,_xx_()的函数被叫做魔法方法,指的是具有特殊功能的函数
—init—()
- 这个是用来初始化对象的,可以用来设置类中本身就有的属性
—init—()方法在创建一个对象的时候是默认被调用的,不需要手动调用—init—(self)中的self的参数,不需要开发者传递,python解释器会自动把当前的对象传递过去
# 定义一个类
class Wahser():
def __init__(self) :
self.width=500
self.height=800
def info(self):
print(f'宽度{self.width},高度{self.height}')
def wash(self):
print('洗衣服ing...')
# 定义一个对象
haier=Wahser()
haier.info()
haier.wash()
宽度500,高度800
洗衣服ing...
带参数的—init—(self)
# 定义一个类
class Wahser():
def __init__(self,width,height) :
self.width=width
self.height=height
def info(self):
print(f'宽度{self.width},高度{self.height}')
def wash(self):
print('洗衣服ing...')
# 定义一个对象,因为在创建对象的时候就已经调用了__init__方法
haier=Wahser(100,200)
haier.info()
haier.wash()
宽度100,高度200
洗衣服ing...
—str—(self)
当print对选哪个的时候,我们默认会打印出内存地址,但是类定义了这个方法就会打印出这个方法中return的数据
# 定义一个类
class Wahser():
def __init__(self,width,height) :
self.width=width
self.height=height
def __str__(self) -> str:
return '这里是邮箱的说明书。。。'
def info(self):
print(f'宽度{self.width},高度{self.height}')
def wash(self):
print('洗衣服ing...')
# 定义一个对象
haier=Wahser(100,200)
print(haier)
haier.info()
haier.wash()
这里是邮箱的说明书。。。
宽度100,高度200
洗衣服ing...
—del—(self)
当删除对象的时候,python自动调用这个方法
# 定义一个类
class Wahser():
def __init__(self,width,height) :
self.width=width
self.height=height
def __str__(self) -> str:
return '这里是邮箱的说明书。。。'
def __del__(self):
print('对象被删除了')
def info(self):
print(f'宽度{self.width},高度{self.height}')
def wash(self):
print('洗衣服ing...')
# 定义一个对象
haier=Wahser(100,200)
print(haier)
haier.info()
haier.wash()
del haier
这里是邮箱的说明书。。。
宽度100,高度200
洗衣服ing...
对象被删除了
继承
# 定义一个父类animal
class animal():
def __init__(self,name) :
self.name=name# 动物都有名字
def info(self):
print(f'这个是{self.name}')
# 定义一个子类
class dogs(animal):
pass
dog=dogs('dog')
dog.info()
#这个是dog
单继承
- 一个父类只有一个子类就是单继承,上面animal和dogs就是单继承
多继承
- 一个子类有多个父类
- 当一个类有多个父类的时候,默认使用第一个父类的同名的属性和方法
重写
- 子类可以重写父类同名的方法和属性,当调用同名的方法和属性的时候,父类的会被子类的覆盖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dzxVIZVd-1635041569160)(%E7%AC%AC%E4%B8%80%E7%AB%A0.assets/image-20211023163600202.png)]](https://i-blog.csdnimg.cn/blog_migrate/2fc0499a5f6d30bb773721013419908b.png)
- 子类如何调用父类的同名的方法和属性
# 定义一个父类animal
class Animals():
def __init__(self) :
self.name='动物'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
# 定义一个子类
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
def make_Dogs(self):
# 如果先调用父类属性和方法,父类属性会覆盖掉子类的属性,所以在调用属性之前,要先调用自己的子类进行初始化
self.__init__()
self.info()
def make_Animals(self):
# 调用父类方法,但是为了保证调用到的属性也是父类的属性,所以必须在调用的方法之前调用到父类的初始化
Animals.__init__(self)
Animals.info(self)
dog=Dogs()
dog.make_Dogs()
dog.make_Animals()
#这个是狗
#这个是动物
多层继承
允许多层继承,只要有继承关系,子类就可以调用到所有父类的方法和属性
查看继承关系
类名.__mro__
print(dogs.__mro__)
#(<class '__main__.dogs'>, <class '__main__.animal'>, <class 'object'>)
super()
#有参数
super(当前所在类的类名,self).同名方法
#无参数
super().同名方法
- 用来调用父类方法
- 这里其实有相当于用父类来覆盖掉子类的感觉
- 在多层继承中,如果想要调用父类的父类中的同名方法,只需要在直接父类中也用super语法就可以了
这里演示的是有参数的
# 定义一个父类animal
class Animals():
def __init__(self) :
self.name='动物'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
# 定义一个子类
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
def make_Dogs(self):
super(Dogs,self).__init__()
super(Dogs,self).info()
# def make_Dogs(self):
# # 如果先调用父类属性和方法,父类属性会覆盖掉子类的属性,所以在调用属性之前,要先调用自己的子类进行初始化
# self.__init__()
# self.info()
# def make_Animals(self):
# # 调用父类方法,但是为了保证调用到的属性也是父类的属性,所以必须在调用的方法之前调用到父类的初始化
# Animals.__init__(self)
# Animals.info(self)
dog=Dogs()
dog.make_Dogs()
# dog.make_Animals()
#这个是动物
这里演示的是无参数的
# 定义一个父类animal
class Animals():
def __init__(self) :
self.name='动物'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
# 定义一个子类
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
def make_Dogs(self):
super().__init__()
super().info()
# def make_Dogs(self):
# # 如果先调用父类属性和方法,父类属性会覆盖掉子类的属性,所以在调用属性之前,要先调用自己的子类进行初始化
# self.__init__()
# self.info()
# def make_Animals(self):
# # 调用父类方法,但是为了保证调用到的属性也是父类的属性,所以必须在调用的方法之前调用到父类的初始化
# Animals.__init__(self)
# Animals.info(self)
dog=Dogs()
dog.make_Dogs()
# dog.make_Animals()
私有属性
-
设置一些属性或者方法让不被子类继承
-
设置私有属性的方法:在属性名和方法名前面加上两个下划线
# 定义一个父类animal
class Animals():
def __init__(self) :
self.__skin='毛发'#这是一个私有属性
self.name='动物'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
# 定义一个子类
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
def make_Dogs(self):
super().__init__()
super().info()
dog=Dogs()
dog.make_Dogs()
print(dog.__skin)
这个是动物
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-18-ba391c645d4c> in <module>
20 dog=Dogs()
21 dog.make_Dogs()
---> 22 print(dog.__skin)
AttributeError: 'Dogs' object has no attribute '__skin'
获取和修改私有属性
私有属性不可以被继承,但是可以在类中通过get_xx(获取私有属性)和set_xx(修改私有属性)
# 定义一个父类animal
class Animals():
def __init__(self) :
self.__skin='毛发'#这是一个私有属性
self.name='动物'# 动物都有名字
def info(self):
print(f'这个是{self.name}')
def get_skin(self):
return self.__skin
def set_skin(self,skin):
self.__skin=skin
# 定义一个子类
class Dogs(Animals):
pass
dog=Dogs()
dog.set_skin('棕色毛发')
print(dog.get_skin())
# 棕色毛发
封装
- 将属性和方法写到类中
多态
在python中,多态不一定来源于继承,但是最好来源于继承
- 多态是一种使用对象的方式,子类重写父类的方法,调用不同的子类对象的相同父类方法,可以产生不同的执行结果
class Dog(object):
def work(self):
pass
class DrugDog(Dog):
def work(self):
print('追查毒品')
class ArmyDog(Dog):
def work(self):
print('追查犯人')
class Persion(object):
def work_with_dog(self,dog):
dog.work()
persion =Persion()
dog=ArmyDog()
persion.work_with_dog(dog)
dog=DrugDog()
persion.work_with_dog(dog)
追查犯人
追查毒品
类属性和实例属性
类属性
-
类属性是类对象所拥有的属性,它被这个类的所有实例对象所公有
-
类属性可以使用类对象或者实例对象访问
# 定义一个类animal
class Animals():
tooth=10# 类属性
print(Animal.tooth)#类访问
cat=Animals()
print(cat.tooth)#实例访问
dog=Animals()
print(dog.tooth)
#10
#10
#10
修改类属性
类属性只能通过类来修改,不能通过实例对象修改,如果听过实例对象修改,意思就是创建了一个实例属性
# 定义一个类animal
class Animals():
tooth=10# 类属性
Animals.tooth=14
print(Animals.tooth)
cat=Animals()
print(cat.tooth)
dog=Animals()
dog.tooth=20#创建了一个实例属性tooth=20
print(cat.tooth)
print(dog.tooth)
14
14
14
20
类方法和静态方法
类方法
- 需要用装饰器
@classmethod来标识的才是类方法,对于类方法,第一个参数必须是类对象,一般一cls作为第一个参数 - 类方法一般配合类属性使用
# 定义一个类animal
class Animals():
__tooth=10# 类属性
@classmethod
def get_tooth(cls):
return cls.__tooth
cat=Animals()
result=cat.get_tooth()
print(result)
#10
静态方法
- 静态方法需要通过装饰器
@staticmethod来装饰,静态方法不需要传递类对象也不需要传递1实例对象(形参没有self、cls) - 静态方法也能够通过实例对象和类对象去访问
# 定义一个类animal
class Animals():
@staticmethod
def get_static():
print('静态方法')
cat=Animals()
cat.get_static()
Animals.get_static()
静态方法
静态方法
二十九、异常
try:
可能发生错误的代码
except:
如果出现异常执行的代码
try:
f=open('test1.txt','r')
except:
f=open('test1.txt','w')
捕获指定异常
try:
可能发生错误的代码
except (异常类型1,异常类型2) as result:
print(result)#打印捕获的异常的信息
注意:
- 如果尝试执行的代码异常类型和想要捕获的类型不一致,就没有办法捕获异常
- 一般来讲try下方只放一行代码
捕获所有的异常
Exception是所有程序异常的父类
try:
可能发生错误的代码
except Exception as result:
print(result)#打印捕获的异常的信息
else
else表示如果没有异常要执行的代码
try:
可能发生错误的代码
except Exception as result:
print(result)#打印捕获的异常的信息
else:
没有异常需要执行的代码块
finally
finally表示无论是否异常都要执行的代码。例如关闭文件
try:
可能发生错误的代码
except Exception as result:
print(result)#打印捕获的异常的信息
else:
没有异常需要执行的代码块
finally:
无论是否异常都要执行的代码块
自定义异常
在python中,抛出自定义异常的语法是raise 异常对象
# 自定义一个异常类,要继承Exceptipon
class shortInputError(Exception):
def __init__(self,length,min_len ) :
self.length=length
self.min_len=min_len
def __str__(self) :
return f'你输入的长度是{self.length},不能少于{self.min_len}个字符'
def main():
try:
con=input('请输入密码:')
if len(con)<8:
raise shortInputError(len(con),8)
except Exception as result:
print(result)
else:
print('密码输入正确')
main()
三十、模块
导模块方式
- import 模块名
import time
time.功能
import time
print(time.time())
- from 模块名 import 功能名
from time import time
直接功能调用
from time import time
print(time())
- from 模块名 import*
from time from *
直接功能调用
from time import *
print(time())
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
from time import time as t
print(t())
模块定位的顺序
当导入一个模块的时候,python解析器对模块的搜索顺序是:
- 当前目录
- 如果不在当前目录,python就搜索shell变量PYTHONPATH下的每一个目录(安装目录)
- 如果找不到,python就会查看默认路径
注意:
- 自己的文件名最好不要和已经有的模块名重复,否则会导致已有的模块无法使用(因为搜索路径由近及远)
- 如果
from 模块名 import 功能,如果功能名字重复,调用的是最后定义或者导入的功能- 这里值得注意的是,就算是同名的变量,也是会对模块进行覆盖的,因为我们的内容是通过
引用来定义的,当我们的名字相同的时候,也就是引用相同,就会导致后来的东西覆盖掉原来的东西,所以我们在定义名字的时候一定要注意最好不要和模块同名
—all—
如果一个模块文件中有这个变量,当使用from xxx import *导入的时候,只能导入这个列表中的元素,这里值得注意的是,这个模块的命名,只能是以.py为后缀来命名,不能以其他任何形式后缀命名
__all__=['testA']
def testA():
print('testA')
def testB():
print('testB')
from module1 import *
testA()
testB()
testA
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-10-5967f3f88564> in <module>
1 from module1 import *
2 testA()
----> 3 testB()
NameError: name 'testB' is not defined
三十一、包
包将有联系的模块组织到一起,也就是放在同一个文件夹中,并且这个文件夹创建一个名字为__init__.py文件,那么这个文件夹就称作包
创建包
- 创建一个
mypackage包 - 创建
__init__.py、module1.py、module2.py文件 - 写入代码
def module1_test():
print('这个是module1方法')
def module2_test():
print('这个是module2方法')
导入包
- 方法一
import 包名.模块名
包名.模块名.目标
import mypackage.module1
mypackage.module1.module1_test()
- 方法二
注意:必须在__init__.py文件中添加__all__=[],控制允许导入的模块列表,如果不设置,代表所有模块都不能通过
from 包名 impor*
模块名.目标
# 控制包的导入行为
__all__=['module1']
from mypackage import*
module1.module1_test()
这个是module1方法
三十二、其他知识
—dict—
- 类或者实例对象都有的
- 用来收集类对象或者实例对象属性、方法以及对应的值,从而返回一个字典
class Dog(object):
a=1
def work(self):
print('正在工作')
dog=Dog()
print(Dog.__dict__)
{'__module__': '__main__', 'a': 1, 'work': <function Dog.work at 0x00000270150CA790>, '__dict__': <attribute '__dict__' of 'Dog' objects>, '__weakref__': <attribute '__weakref__' of 'Dog' objects>, '__doc__': None}
python的日期和时间
- Python 提供了一个
time和calendar模块可以用于格式化日期和时间。 - 时间间隔是以秒为单位的浮点小数。
- 每个时间戳都以自从1970年1月1日(历元)经过了多长时间来表示
- Python 的 time 模块下有很多函数可以转换常见日期格式。如函数
time.time()用于获取当前时间戳,
import time
ticks=time.time()
print ("当前时间为:",ticks)
# 当前时间为: 1634655386.6290803
时间元组
很多Python函数用一个元组装起来的9组数字处理时间:
| 序号 | 字段 | 值 |
|---|---|---|
| 0 | 4位数年 | 2008 |
| 1 | 月 | 1 到 12 |
| 2 | 日 | 1到31 |
| 3 | 小时 | 0到23 |
| 4 | 分钟 | 0到59 |
| 5 | 秒 | 0到61 (60或61 是闰秒) |
| 6 | 一周的第几日 | 0到6 (0是周一) |
| 7 | 一年的第几日 | 1到366 (儒略历) |
| 8 | 夏令时 | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
上述也就是struct_time元组。这种结构具有如下属性:
| 序号 | 属性 | 值 |
|---|---|---|
| 0 | tm_year | 2008 |
| 1 | tm_mon | 1 到 12 |
| 2 | tm_mday | 1 到 31 |
| 3 | tm_hour | 0 到 23 |
| 4 | tm_min | 0 到 59 |
| 5 | tm_sec | 0 到 61 (60或61 是闰秒) |
| 6 | tm_wday | 0到6 (0是周一) |
| 7 | tm_yday | 1 到 366(儒略历) |
| 8 | tm_isdst | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
获取当前时间
import time
localtime = time.localtime(time.time())
print ("本地时间为 :", localtime)
本地时间为 : time.struct_time(tm_year=2021, tm_mon=10, tm_mday=19, tm_hour=23, tm_min=0, tm_sec=35, tm_wday=1, tm_yday=292, tm_isdst=0)
获取格式化的时间
你可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
import time
localtime = time.asctime( time.localtime(time.time()) )
print ("本地时间为 :", localtime)
# 本地时间为 : Tue Oct 19 23:03:06 2021
格式化日期
time.strftime(format[, t])
import time
# 格式化成2016-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) )
# 格式化成Sat Mar 28 22:24:24 2016形式
print(time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()) )
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y")))
2021-10-19 23:07:24
Tue Oct 19 23:07:24 2021
1459175064.0
python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00-59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
获取某月的日历
import calendar
cal = calendar.month(2016, 1)
print ("以下输出2016年1月份的日历:")
print (cal)
以下输出2016年1月份的日历:
January 2016
Mo Tu We Th Fr Sa Su
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30 31
Time模块
Time 模块包含了以下内置函数,既有时间处理的,也有转换时间格式的:
| 序号 | 函数及描述 |
|---|---|
| 1 | time.altzone 返回格林威治西部的夏令时地区的偏移秒数。如果该地区在格林威治东部会返回负值(如西欧,包括英国)。对夏令时启用地区才能使用。 |
| 2 | [time.asctime(tupletime]) 接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串。 |
| 3 | time.clock( ) 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 |
| 4 | [time.ctime(secs]) 作用相当于asctime(localtime(secs)),未给参数相当于asctime() |
| 5 | [time.gmtime(secs]) 接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0 |
| 6 | [time.localtime(secs]) 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。 |
| 7 | time.mktime(tupletime) 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数)。 |
| 8 | time.sleep(secs) 推迟调用线程的运行,secs指秒数。 |
| 9 | [time.strftime(fmt,tupletime]) 接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。 |
| 10 | time.strptime(str,fmt=’%a %b %d %H:%M:%S %Y’) 根据fmt的格式把一个时间字符串解析为时间元组。 |
| 11 | time.time( ) 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | time.tzset() 根据环境变量TZ重新初始化时间相关设置。 |
Time模块包含了以下2个非常重要的属性:
| 序号 | 属性及描述 |
|---|---|
| 1 | time.timezone 属性 time.timezone 是当地时区(未启动夏令时)距离格林威治的偏移秒数(>0,美洲<=0大部分欧洲,亚洲,非洲)。 |
| 2 | time.tzname 属性time.tzname包含一对根据情况的不同而不同的字符串,分别是带夏令时的本地时区名称,和不带的。 |
日历(Calendar)模块
此模块的函数都是日历相关的,例如打印某月的字符月历。
星期一是默认的每周第一天,星期天是默认的最后一天。更改设置需调用calendar.setfirstweekday()函数。模块包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串格式的year年年历,3个月一行,间隔距离为c。 每日宽度间隔为w字符。每行长度为21* W+18+2* C。l是每星期行数。 |
| 2 | calendar.firstweekday( ) 返回当前每周起始日期的设置。默认情况下,首次载入 calendar 模块时返回 0,即星期一。 |
| 3 | calendar.isleap(year) 是闰年返回 True,否则为 False。>>> import calendar >>> print(calendar.isleap(2000)) True >>> print(calendar.isleap(1900)) False |
| 4 | calendar.leapdays(y1,y2) 返回在Y1,Y2两年之间的闰年总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星期的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。第一个是该月的星期几的日期码,第二个是该月的日期码。日从0(星期一)到6(星期日);月从1到12。 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) 相当于 print calendar.calendar(year,w=2,l=1,c=6)。 |
| 9 | calendar.prmonth(year,month,w=2,l=1) 相当于 print calendar.month(year,month,w=2,l=1) 。 |
| 10 | calendar.setfirstweekday(weekday) 设置每周的起始日期码。0(星期一)到6(星期日)。 |
| 11 | calendar.timegm(tupletime) 和time.gmtime相反:接受一个时间元组形式,返回该时刻的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
其他相关模块和函数
在Python中,其他处理日期和时间的模块还有:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









