






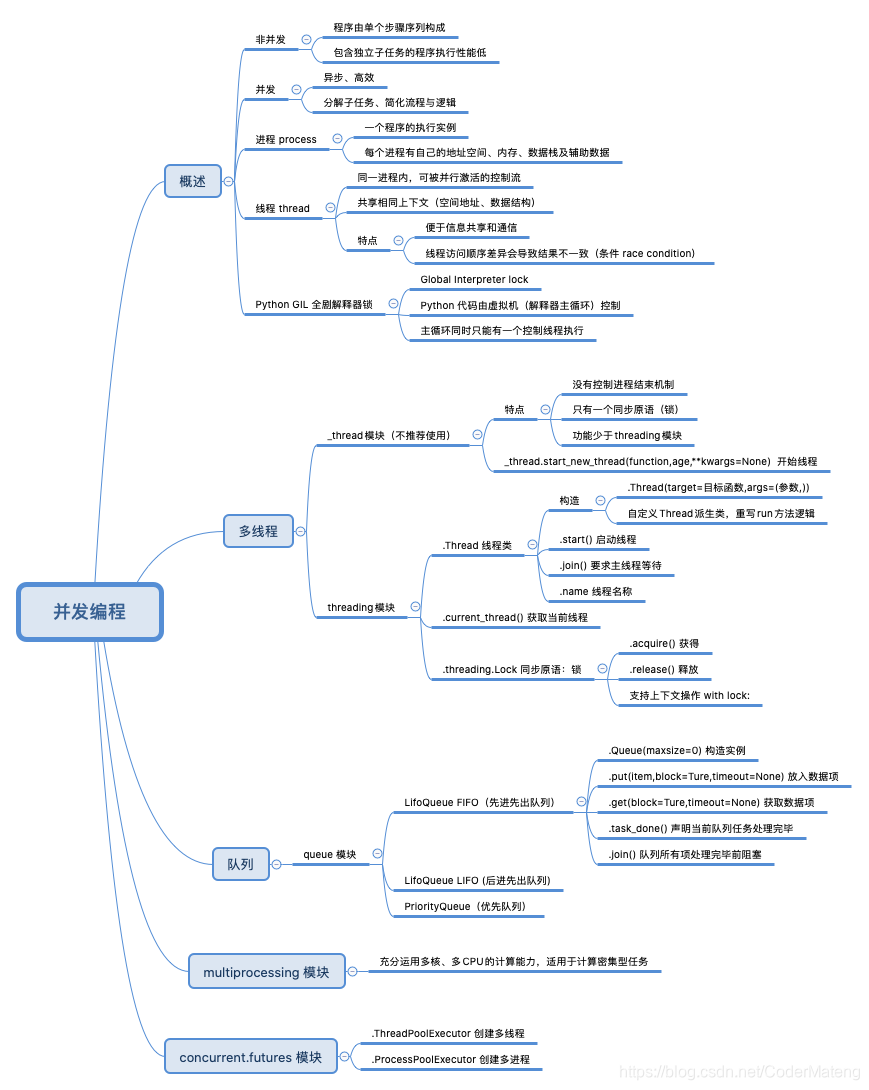
_thread模块实现多线程(由于功能不全,不推荐使用)
import _thread
import time
def worktime(n):
print(f'函数执行开始于{time.ctime()}')
time.sleep(n)
print(f'函数执行结束于{time.ctime()}')
def main():
print(f'【主函数】执行开始于{time.ctime()}')
_thread.start_new_thread(worktime,(2,))
_thread.start_new_thread(worktime,(4,))
time.sleep(5) #由于thread功能不全,需要设置睡眠时间,来等待线程执行完毕
print(f'【主函数】执行结束于{time.ctime()}')
if __name__ == '__main__':
main()
结论:实现多线程开始执行,于逐一执行比较,总体所用时间减少。
threading模块
threading.Thread() 实现多线程:
import threading
import time
def worktime(n):
print(f'{threading.current_thread()}函数执行开始于{time.ctime()}')#可以通过threading.current_thread获取当前正在执行 线程名称
time.sleep(n)
print(f'{threading.current_thread()}函数执行结束于{time.ctime()}')
def main():
print(f'【主函数】执行开始于{time.ctime()}')
threads = [] #首先建立一个空列表,之后把线程加入列表,然后通过遍历列表执行线程
t1 = threading.Thread(target=worktime,args=(2,)) #创建第一个线程
threads.append(t1) #将线程加入列表
t2 = threading.Thread(target=worktime, args=(4,)) # 创建第二个线程
threads.append(t2) # 将线程加入列表
for t in threads:#通过遍历列表来执行所有线程
t.start()#线程执行命令
for t in threads:
t.join()#让主函数等所有线程执行完毕再结束
print(f'【主函数】执行结束于{time.ctime()}')
if __name__ == '__main__':
main()
结论:实现多线程开始执行,于逐一执行比较,总体所用时间减少。
threading.Thread()派生(创建类) 实现多线程:
import threading
import time
def worktime(n):
print(f'{threading.current_thread()}函数执行开始于{time.ctime()}')#可以通过threading.current_thread获取当前正在执行 线程名称
time.sleep(n)
print(f'{threading.current_thread()}函数执行结束于{time.ctime()}')
class MyThread(threading.Thread):#创建一个类,继承threading.Thread
def __init__(self,func,args):#指定委托函数是什么,参数是什么
threading.Thread.__init__(self)#想让threading.Thread执行它自己的init构造函数
self.func = func
self.args = args
def run(self):
self.func(*self.args)#由于参数是元组形式,传入时需要用*解剖
def main():
print(f'【主函数】执行开始于{time.ctime()}')
threads = [] #首先建立一个空列表,之后把线程加入列表,然后通过遍历列表执行线程
t1 = MyThread(worktime,(2,))#通过类创建第一个线程
threads.append(t1) #将线程加入列表
t2 = MyThread(worktime,(4,)) #通过类创建第二个线程
threads.append(t2) # 将线程加入列表
for t in threads:#通过遍历列表来执行所有线程
t.start()#线程执行命令
for t in threads:
t.join()#让主函数等所有线程执行完毕再结束
print(f'【主函数】执行结束于{time.ctime()}')
if __name__ == '__main__':
main()
结论:实现多线程开始执行,于逐一执行比较,总体所用时间减少。
同步原语:锁(避免多线程同时执行时导致结果不一致)
import threading
import time
import random
eggs = []
lock = threading.Lock()#同步原语:锁
def put_egg(n,list):
lock.acquire()#每个线程执行时,获得锁,并且锁上,避免别的线程执行结果的干扰
for i in range(1,n+1):
time.sleep(random.randint(0,2))#用睡眠时间表示真实情况下每个线程执行需要的时间
list.append(i)
lock.release()#每个线程执行结束之后,要把锁打开
def main():
threads = []
for i in range(3):
t = threading.Thread(target=put_egg,args=(5,eggs))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(eggs)
if __name__ == '__main__':
main()
结论:通过锁进行多线程运行,并未对期待结果产生影响。
Queue队列
FIFO queue:(先进先出队列)
import threading
import queue
import time
import random
def producer(data_queue):#依次将随机产生的数字放入队列
for i in range(5):
time.sleep(0.5)#生产者每隔半秒钟向队列中放入一个随机数
item = random.randint(1,100)
data_queue.put(item)
print(f'{threading.current_thread().name}在队列中放入数据{item}')
def consumer(data_queue):#从队列中取出数据
while True:
try:
item = data_queue.get(timeout = 3)#设置一个超时功能,设为3秒
print(f'{threading.current_thread().name}从队列中移除了数据{item}')
except queue.Empty:#捕获一个异常信息,当队列空了,没有数据可取时,跳出循环
break
else:
data_queue.task_done()#声明正常情况下,当前数据项已经处理完毕
def main():
q = queue.Queue()#构造接收,处理对象的队列
threads = []
p = threading.Thread(target=producer,args=(q,))#创建生产者线程
p.start()#执行生产者线程
for t in range(2):#创建两个消费者线程
c = threading.Thread(target=consumer,args=(q,))
threads.append(c)
for t in threads:
t.start()#执行消费者线程
for t in threads:
t.join()#让主线程等待消费者线程执行完毕
q.join()#让主线程等待生产者线程执行完毕
if __name__ == '__main__':
main()
结论:符合先进先出队列特征。
multiprocess多线程模块:(适用于计算密集型任务,使用方法于threading类似)
import multiprocessing
import time
def func(n):
print(f'{multiprocessing.current_process().name}开始执行于{time.ctime()}')
time.sleep(n)
print(f'{multiprocessing.current_process().name}结束执行于{time.ctime()}')
def main():
print(f'主函数执行于{time.ctime()}')
processes = []
p1 = multiprocessing.Process(target=func,args=(2,))
processes.append(p1)
p2 = multiprocessing.Process(target=func, args=(4,))
processes.append(p2)
for p in processes:
p.start()
for p in processes:
p.join()
print(f'主函数结束于{time.ctime()}')
if __name__ == '__main__':
main()
concurrent.futures 模块
import concurrent.futures
import time
numbers = list(range(1,11))#在列表中生成数字1-10
def count(n):
for i in range(10000000):
i += i
return i * n
def worker(x):
result = count(x)
print(f'数字:{x} 的计算结果是:{result}')
#顺序执行,不使用多进程或者多线程
def sequential_execution():
start_time = time.clock()
for i in numbers:
worker(i)
print(f'顺序执行花费时间为:{time.clock() - start_time}秒')
#线程池执行
def threading_execution():
start_time = time.clock()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:#使用concurrent.futures.ThreadPoolExecutor创建线程,并设置最大线程数为5
for i in numbers:
executor.submit(worker,i)#使用执行器来执行函数
print(f'顺序执行花费时间为:{time.clock() - start_time}秒')
#进程池执行
def process_execution():
start_time = time.clock()
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor: #使用concurrent.futures.ProcessPoolExecutor创建进程,并设置最大线程数为5
for i in numbers:
executor.submit(worker, i)#使用执行器来执行函数
print(f'顺序执行花费时间为:{time.clock() - start_time}秒')
if __name__ == '__main__':
sequential_execution()
#threading_execution()
#process_execution()
结论:依次执行任务每种方法后比较其所花费时间。得知,计算密集型任务首选多进程,IO密集型任务首选多线程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









