







目录
前言
Kafka是一个高性能,多副本,可复制的分布式消息系统。在整个系统中,涉及到多处选举机制,被不少人搞混,这里总结一下,本篇文章大概会从三个方面来讲解。
-
Controller控制器(Broker)选举机制
-
Partition Replicates分区副本选举机制
-
消费者组选举机制
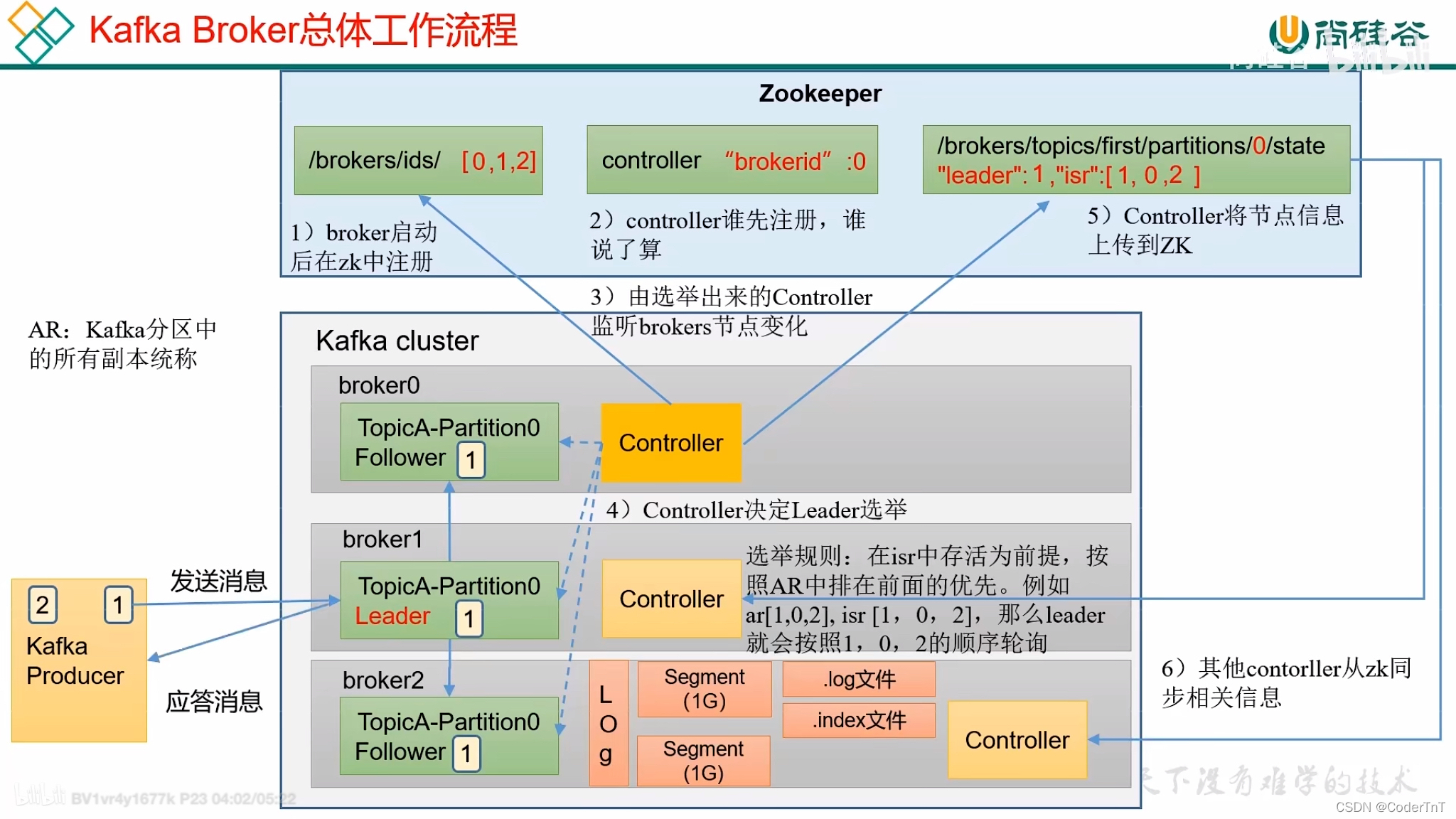
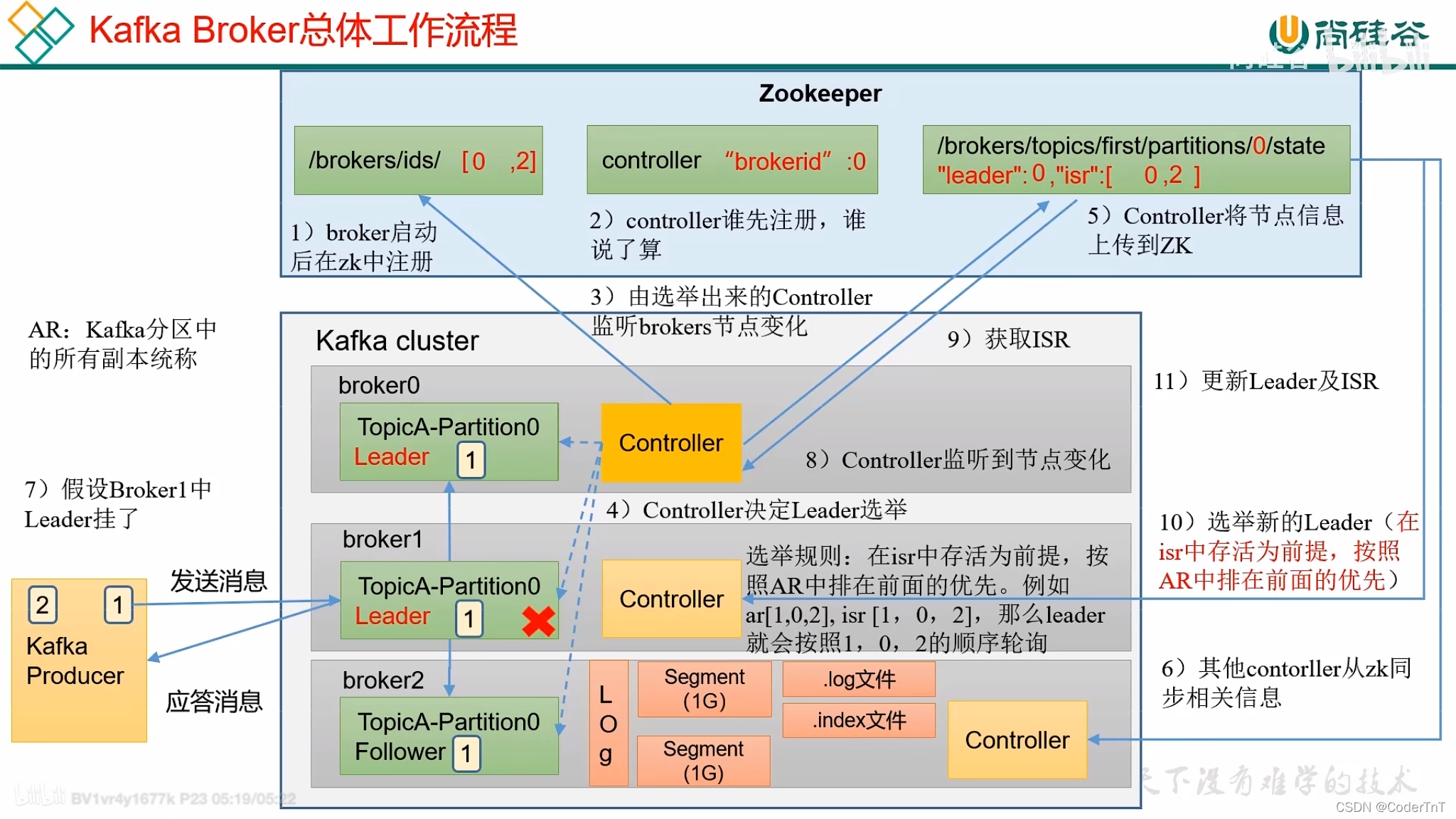
假设Borker1中的leader 挂掉的场景 流程如下图继续选leader主:
控制器选举(Kafka核心总控制器Controller)
在Kafka集群中会有一个或者多个broker,其中有一个broker是在Zookeeper的帮助下会被选举为控制器(Kafka Controller),它负责管理和协调整个Kafka集群中所有分区和副本的状态。
Controller选举机制
集群中第一个启动的Broker会通过在Zookeeper中创建临时节点/controller来让自己成为控制器,其他Broker启动时也会在zookeeper中创建临时节点,但是发现节点已经存在,所以它们会收到一个异常,意识到控制器已经存在,那么就会在Zookeeper中创建watch对象,便于它们收到控制器变更的通知。
那么如果控制器由于网络原因与Zookeeper断开连接或者异常退出,那么其他broker通过watch收到控制器变更的通知,就会去尝试创建临时节点/controller,如果有一个Broker创建成功,那么其他broker就会收到创建异常通知,也就意味着集群中已经有了控制器,其他Broker只需创建watch对象即可。
如下图举例(建立Kafka集群过程略,背景为创建3个kafka broker,1个zookeeper集群环境,在zookeeper中的节点信息为):
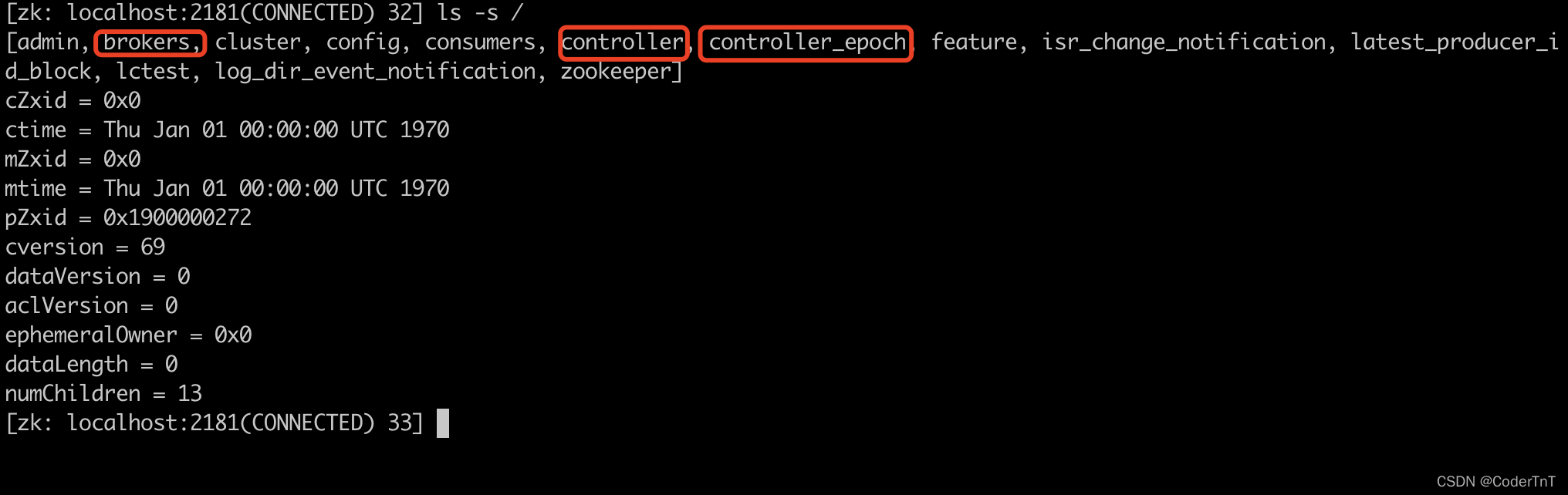
查看zk中 /controller保存的kafka信息如图:
 kafka server.properties中配置broker.id 为2 的broker机器被设置为Controller。
kafka server.properties中配置broker.id 为2 的broker机器被设置为Controller。
Controller防止控制器脑裂机制
如果控制器所在broker挂掉了或者Full GC停顿时间太长超过zookeepersession timeout出现假死,Kafka集群必须选举出新的控制器,但如果之前被取代的控制器又恢复正常了,它依旧是控制器身份,这样集群就会出现两个控制器,这就是控制器脑裂问题。
解决方法如下:
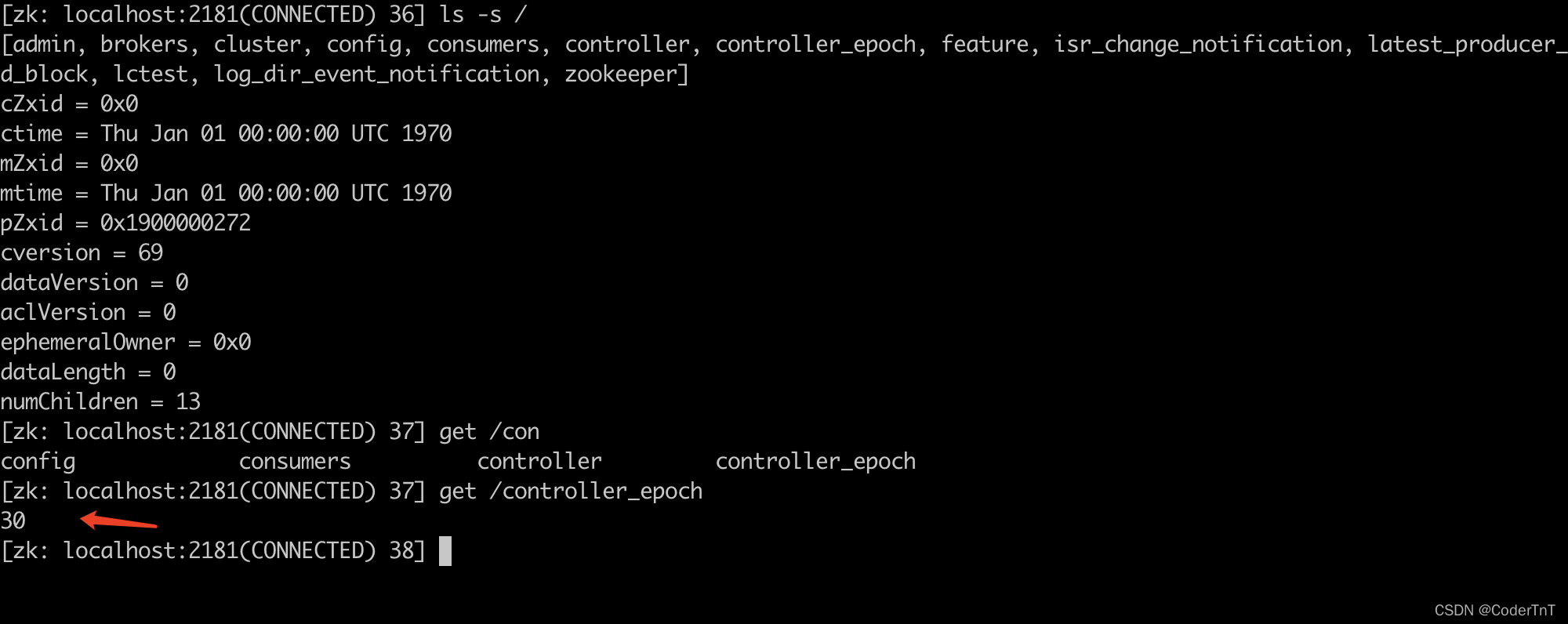
为了解决Controller脑裂问题,ZooKeeper中还有一个与Controller有关的持久节点/controller_epoch,存放的是一个整形值的epoch number(纪元编号,也称为隔离令牌),集群中每选举一次控制器,就会通过Zookeeper创建一个数值更大的epoch number,如果有broker收到比这个epoch数值小的数据,就会忽略消息。
如下图举例标记内容 当前epoch number为30:
Kafka Controller控制器的职责
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
- 监听broker相关的变化。为Zookeeper中的
/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。 - 监听topic相关的变化。为Zookeeper中的
/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化。例如如图举例/brokers/topics节点内容: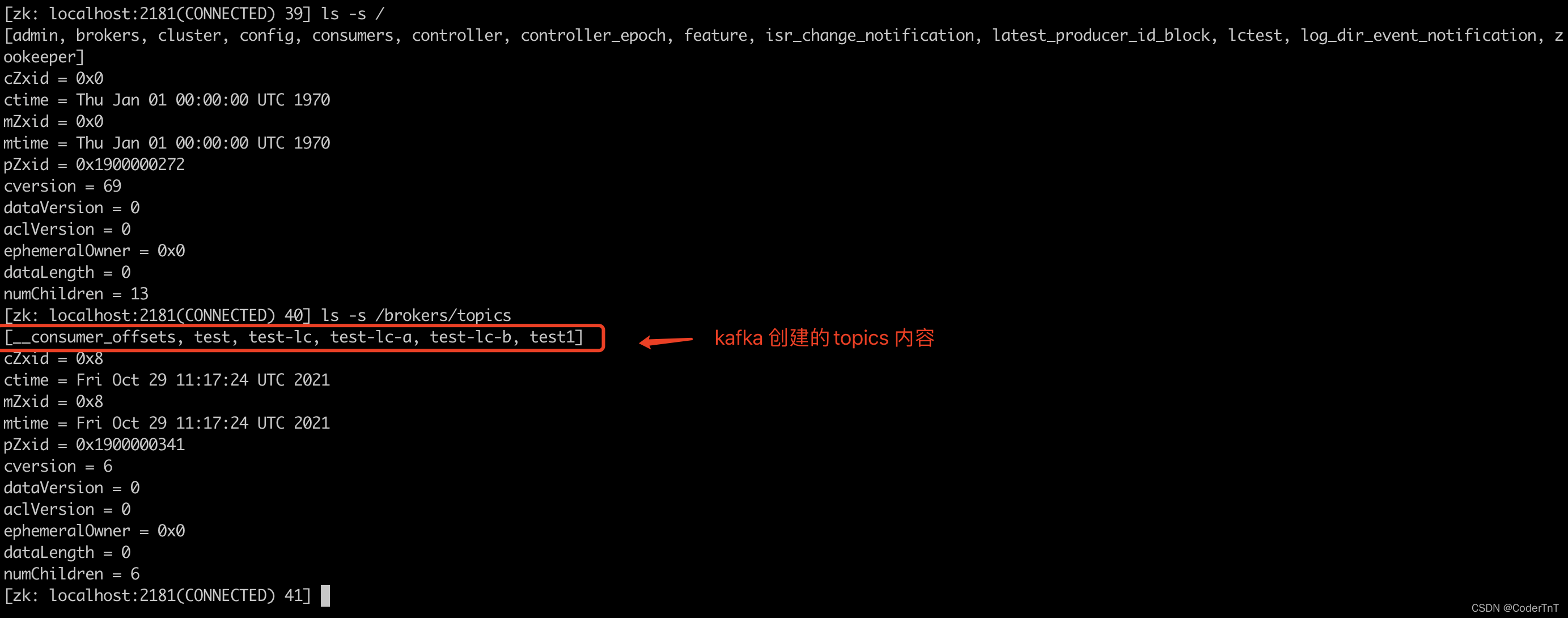
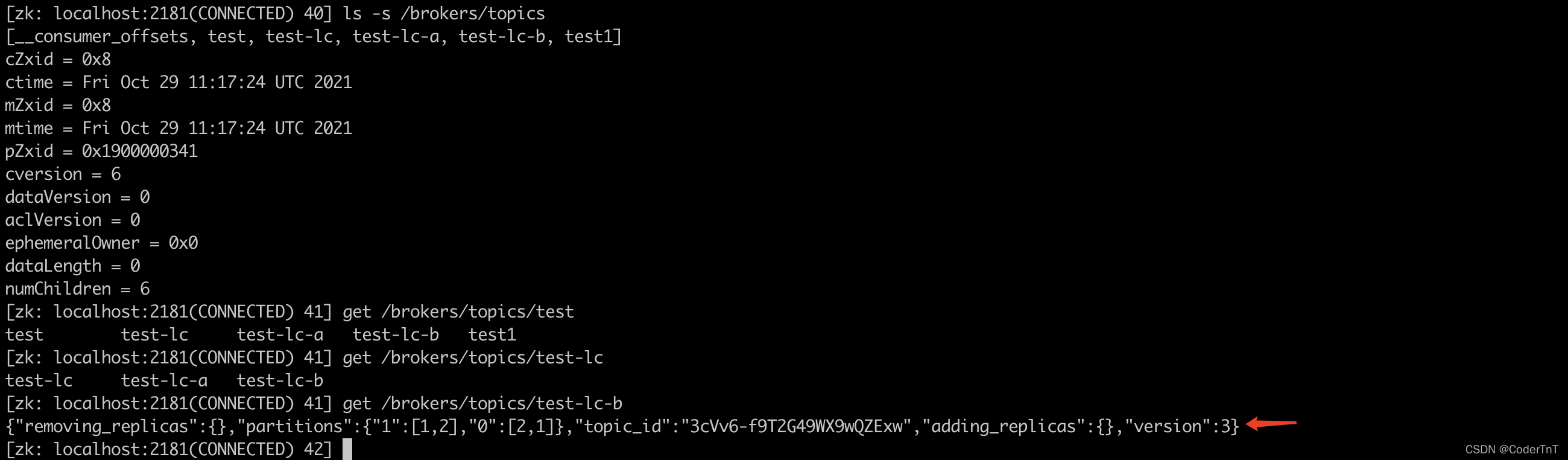 某个topic 的分区信息等内容;为Zookeeper中的
某个topic 的分区信息等内容;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。 - 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的
/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。 - 更新集群的元数据信息,同步到其他普通的broker节点中。
Kafka Controller控制器的作用(同上职责)
Kafka控制器的作用是管理和协调Kafka集群,具体如下:
- 主题管理:创建、删除Topic,以及增加Topic分区等操作都是由控制器执行。
- 分区重分配:执行Kafka的reassign脚本对Topic分区重分配的操作,当使用
kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责分区的重新分配,也是由控制器实现 - 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息
- 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本
- Preferred leader选举:因为在Kafka集群长时间运行中,broker的宕机或崩溃是不可避免的,leader就会发生转移,即使broker重新回来,也不会是leader了。在众多leader的转移过程中,就会产生leader不均衡现象,可能一小部分broker上有大量的leader,影响了整个集群的性能,所以就需要把leader调整回最初的broker上,这就需要Preferred leader选举。
如果集群中有一个Broker发生异常退出了,那么控制器就会检查这个broker是否有分区的副本leader,如果有那么这个分区就需要一个新的leader,此时控制器就会去遍历其他副本,决定哪一个成为新的leader,同时更新分区的ISR集合。
如果有一个Broker加入集群中,那么控制器就会通过Broker ID去判断新加入的Broker中是否含有现有分区的副本,如果有,就会从分区副本中去同步数据。
Partition Replicates副本选举机制
Kafka Controller感知到分区leader所在的broker挂了(controller监听了很多zk节点可以感知到broker存活),controller会从每个parititon的replicas副本列表中取出第一个broker作为leader,当然这个broker需要也同时在ISR列表里。
由Kafka Controller控制器执行partition副本选举过程
-
从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合。
-
调用配置的分区选择算法选择分区的leader。
小插叙:Unclean leader选举
ISR是动态变化的,所以ISR列表就有为空的时候,ISR为空说明leader副本也挂掉了。此时Kafka要重新选举出新的leader。但ISR为空,怎么进行leader选举呢?
Kafka把不在ISR列表中的存活副本称为“非同步副本”,这些副本中的消息远远落后于leader,如果选举这种副本作为leader的话就可能造成数据丢失。所以Kafka broker端提供了一个参数unclean.leader.election.enable,用于控制是否允许非同步副本参与leader选举;如果开启,则当 ISR为空时就会从这些副本中选举新的leader,这个过程称为 Unclean leader选举。
可以根据实际的业务场景选择是否开启Unclean leader选举。一般建议是关闭Unclean leader选举,因为通常数据的一致性要比可用性重要。
消费者组选举
在Kafka的消费端,会有一个消费者协调器以及消费组,组协调器(Group Coordinator)需要为消费组内的消费者选举出一个消费组的leader。
如果消费组内还没有leader,那么第一个加入消费组的消费者即为消费组的leader,如果某一个时刻leader消费者由于某些原因退出了消费组,那么就会重新选举leader,选举方式如下:
private val members = new mutable.HashMap[String, MemberMetadata]
leaderId = members.keys.headOption在组协调器中消费者的信息是以HashMap的形式存储的,其中key为消费者的member_id,而value是消费者相关的元数据信息。而leader的取值为HashMap中的第一个键值对的key(等同于随机)。
注:消费者组的Leader和Group Coordinator没有直接关联。消费组的leader主要负责Rebalance过程中消费分配方案的制定。
Kafka协调器
Kafka中主要有两种协调器:
-
组协调器(Group Coordinator)
-
消费者协调器(Consumer Coordinator)
Kafka为了更好的实现消费组成员管理、位移管理以及Rebalance等,broker服务端引入了组协调器(Group Coordinator),消费端引入了消费者协调器(Consumer Coordinator)。
每个broker启动时,都会创建一个组协调器实例,负责监控这个消费组里的所有消费者的心跳以及判断是否宕机,然后决定开启消费者Rebalance。
每个Consumer启动时,会创建一个消费者协调器(Consumer Coordinator)实例并会向Kafka集群中的某个节点发送FindCoordinatorRequest请求来查找对应的组协调器(Group Coordinator),并跟其建立网络连接。部分内容参看:kafka(16) Kafka Consumer Rebalance_CoderTnT的博客-CSDN博客
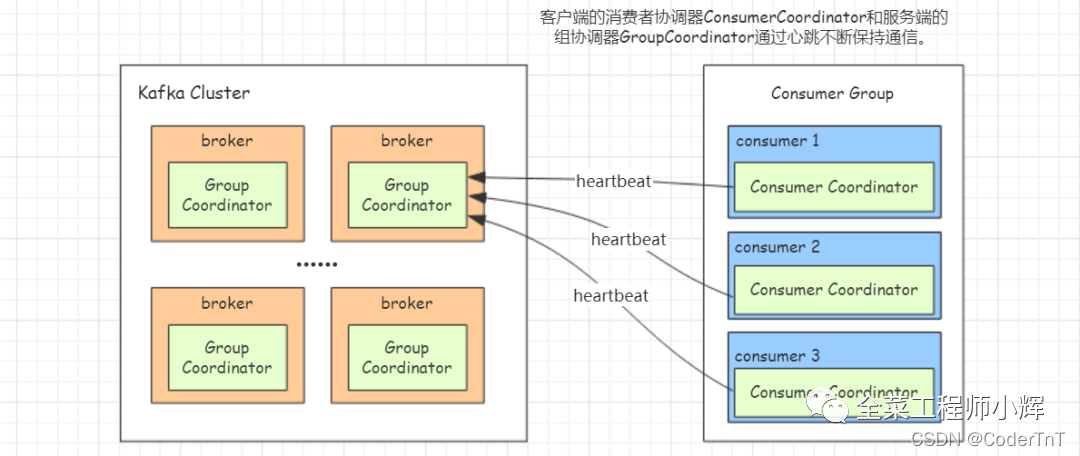
客户端的消费者协调器和服务端的组协调器会通过心跳保持通。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









