



 本文详细介绍了LSTM(长短期记忆网络)和GRU(门控循环单元)的工作原理,这两种模型旨在解决传统RNN在处理长距离依赖时遇到的梯度消失问题。LSTM通过细胞状态和门控机制有效地传递和管理长期信息,而GRU则通过重置门和更新门简化了这一过程。LSTM和GRU在自然语言处理等领域的应用中表现出色,能够更好地捕捉序列数据中的长期依赖关系。
本文详细介绍了LSTM(长短期记忆网络)和GRU(门控循环单元)的工作原理,这两种模型旨在解决传统RNN在处理长距离依赖时遇到的梯度消失问题。LSTM通过细胞状态和门控机制有效地传递和管理长期信息,而GRU则通过重置门和更新门简化了这一过程。LSTM和GRU在自然语言处理等领域的应用中表现出色,能够更好地捕捉序列数据中的长期依赖关系。
RNN有不能处理长依赖的问题,长短期记忆LSTM是一种特殊的RNN,适用于学习长期依赖。所有RNN都有循环神经网络模型的链式形式,在RNN中,循环可以是简单的tanh层
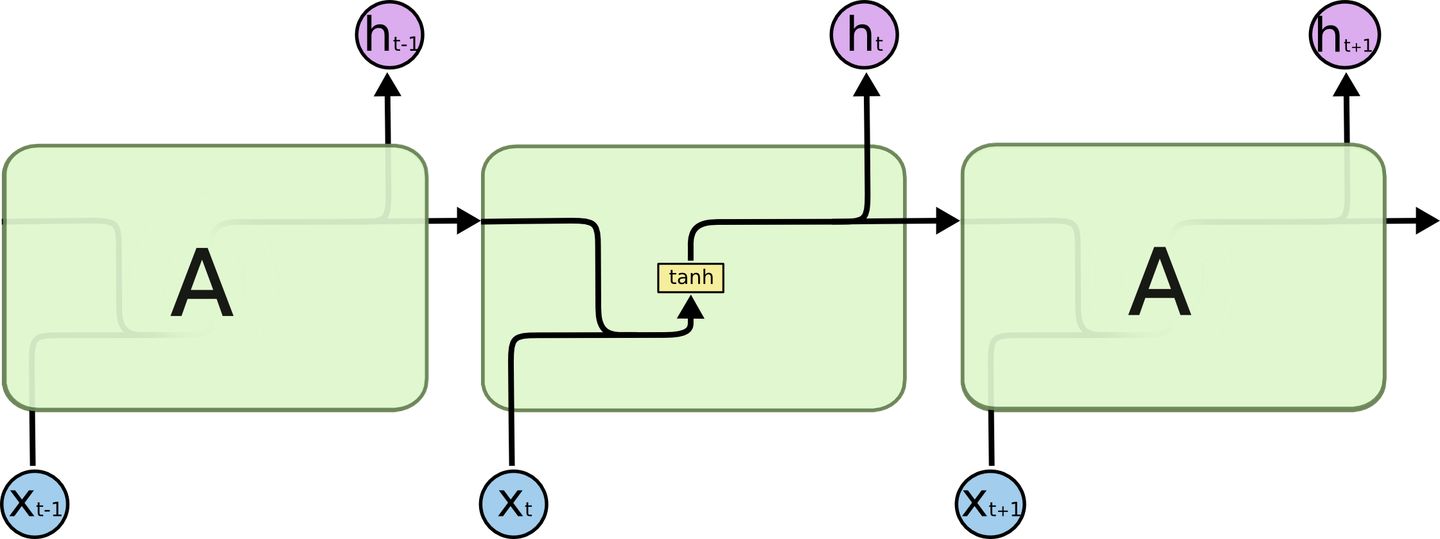
LSTM也有这种链式结构,但循环单元有着一种不同的结构。里面不再是只有单一的神经网络层,里面有四个,并且他们都以非常简单的方式起作用。
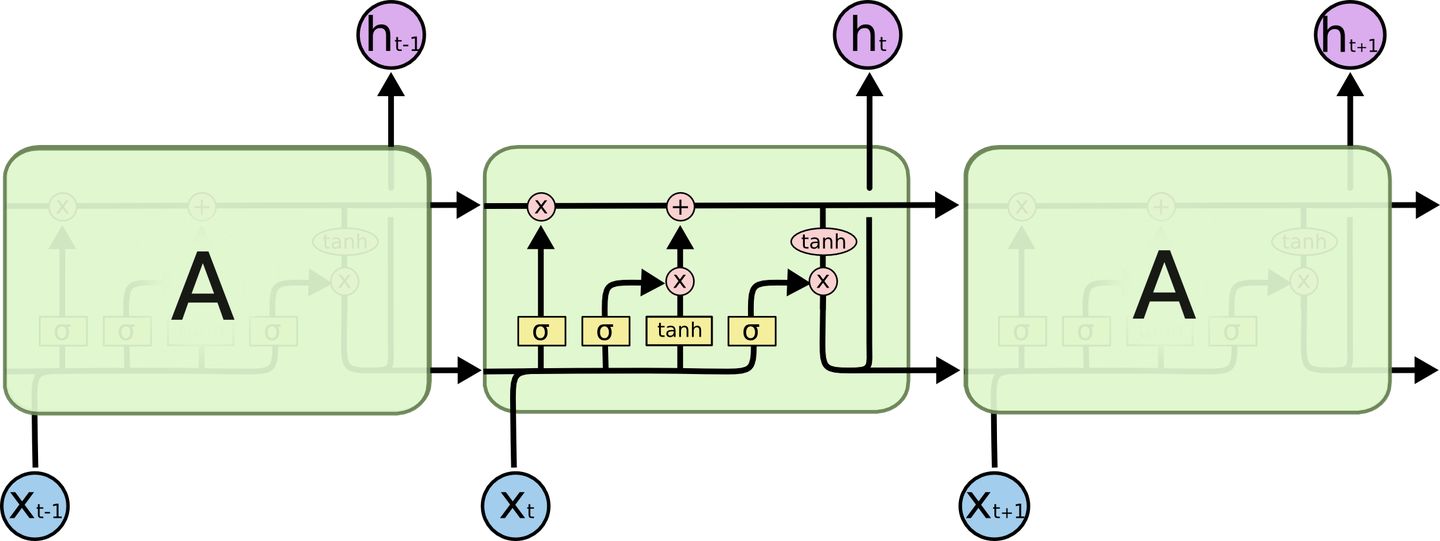

在上面的图中,每行都有一个箭头,从一个结点的输出到另外的结点的输入。粉色的圆代表结点操作,比如向量相加,而黄色的长方形是学习的神经网络层。 线的合并代表链接,而箭头的分叉代表内容复制后流向不同的位置。
lstm背后的核心思想
lstm关键之处在于cell的状态,即图中贯穿顶部的那条水平线。cell的状态像是一条传送带,它贯穿整条链,其中只发生一些小的线性作用。信息流过这条线而不改变是非常容易的。如下图所示
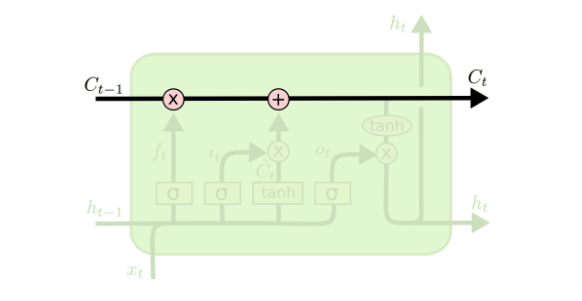
LSTM也有能力移除或增加信息到cell状态中,由被称为门的结构精细控制。门是一种让信息可选地通过的方法。它们由一个sigmoid神经网络层和一个点乘操作组成。
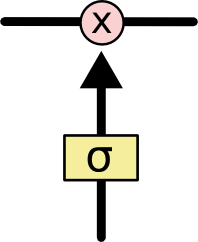
sigmod层输出[0, 1]区间内的数,描述了每个部分中应该通过的比例。输出0意味着“什么都不能通过”,而输出1意味着“让所有东西通过”。一个LSTM有四个这样的门,以保护和控制cell的状态。
顾名思义,lstm为什么叫长短期记忆网络,是因为lstm有对长期记忆的处理,就像最上面的传送带。当然也有对短期记忆进行处理,选择性的保留和添加。
深入理解lstm
LSTM的第一步是决定我们需要从cell状态中扔掉什么样的信息。这个决策由一个称为“遗忘门(forget gate)”的sigmoid层决定。输入ht-1和xt,输出一个0和1之间的数。1代表“完全保留这个值”,而0代表“完全扔掉这个值”。
比如对于一个基于上文预测最后一个词的语言模型。cell的状态可能包含当前主题的信息,来预测下一个准确的词。而当我们得到一个新的语言主题的时候,我们会想要遗忘旧的主题的记忆,应用新的语言主题的信息来预测准确的词。
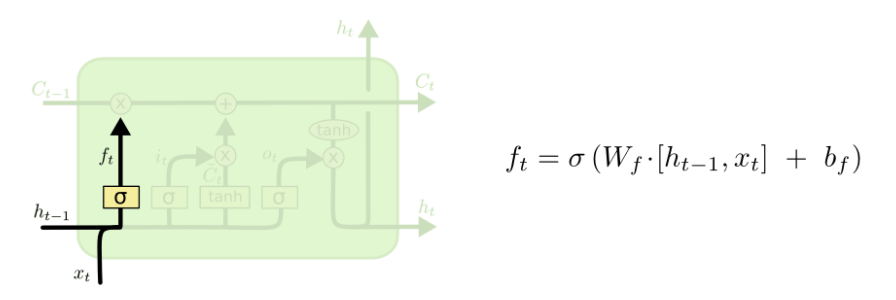
第二步是决定我们需要在cell state里存储什么样的信息。这个问题有两个部分。第一,一个sigmoid层调用“输入门(input gate)”以决定哪些数据是需要更新的。然后,一个tanh层为新的候选值创建一个向量 Ct ,这些值能够加入state中。下一步,我们要将这两个部分合并以创建对state的更新。
比如还是语言模型,可以表示为想要把新的语言主题的信息加入到cell state中,以替代我们要遗忘的旧的记忆信息。
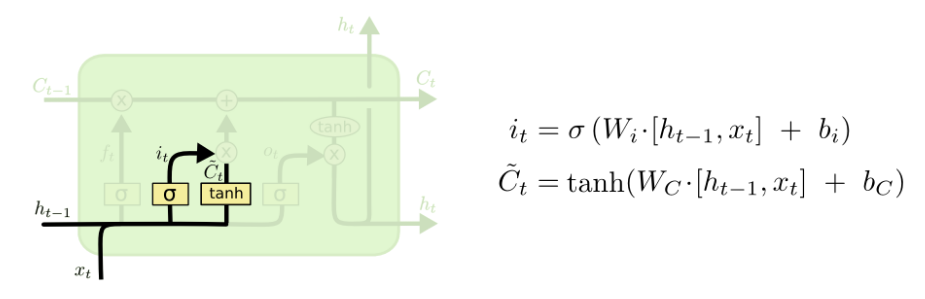
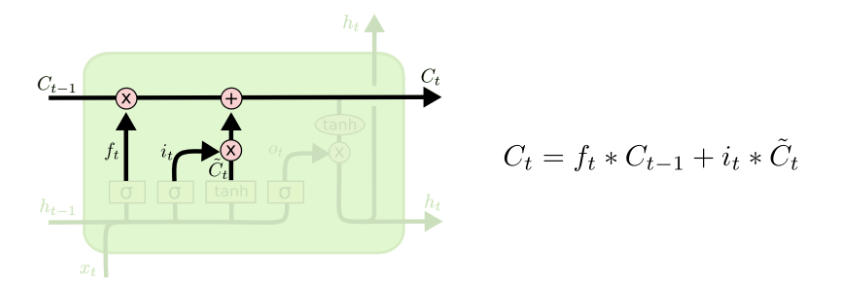
在决定需要遗忘和需要加入的记忆之后,就可以更新旧的cell state Ct-1到新的cell state ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/4e5e3d127aa4e03428847672adcfc09b.png) 了。在这一步,我们把旧的state
了。在这一步,我们把旧的state ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/95b13f8d5e02f1f1d4c42913ac51ecdf.png) 与
与 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/85263e464100d1779627fc39d27b03c7.png) 相乘,遗忘我们先前决定遗忘的东西,然后我们加上
相乘,遗忘我们先前决定遗忘的东西,然后我们加上 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/d0f4c78f1f2f9f6eb592fbaca61bbb72.png) ,这可以理解为新的记忆信息,当然,这里体现了对状态值的更新度是有限制的,我们可以把
,这可以理解为新的记忆信息,当然,这里体现了对状态值的更新度是有限制的,我们可以把 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/1bd9fa2522f525ecaa58ce52975d422a.png) 当成一个权重。
当成一个权重。
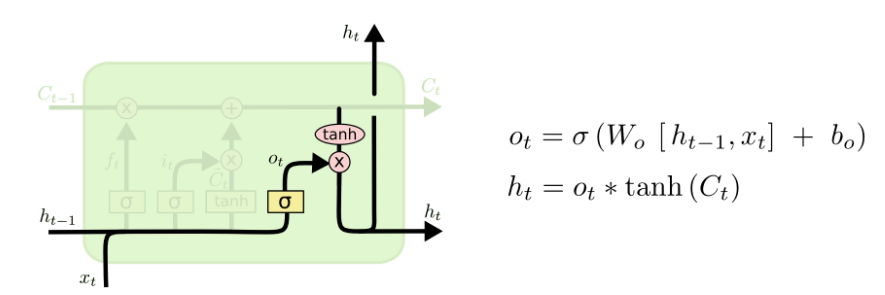
最后,我们需要决定要输出的东西。这个输出基于我们的cell state,但会是一个过滤后的值。首先,我们运行一个sigmoid层,这个也就是输出门(output gate),以决定cell state中的那个部分是我们将要输出的。然后我们把cell state放进tanh(将数值压到-1和1之间),最后将它与sigmoid门的输出相乘,这样我们就只输出了我们想要的部分了。
lstm如何避免梯度消失和梯度爆炸
传统的RNN是用覆盖的的方式计算状态:St=f(St-1,xt),也就是说,这有点类似于复合函数,那么根据链式求导的法则,复合函数求导:设![[公式]](https://i-blog.csdnimg.cn/blog_migrate/b1546fe57556d315e29ee6712725da66.png) 和
和![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ac4bed4b4c33bd53f3bdd4090014b8b8.png) 为
为![[公式]](https://i-blog.csdnimg.cn/blog_migrate/79271a73b75b1b2971964504afad8a27.png) 的可导函数,则
的可导函数,则![[公式]](https://i-blog.csdnimg.cn/blog_migrate/11c9ab4be3c7ba27009b4b38ed756b26.png) ,他们是一种乘积的方式,那么如果导数都是小数或者都是大于1的数的话,就会使得总的梯度发生vanishing或explosion的情况,当然梯度爆炸(gradient explosion)不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩),但是梯度消失做不到,这个时候就要用lstm了。
,他们是一种乘积的方式,那么如果导数都是小数或者都是大于1的数的话,就会使得总的梯度发生vanishing或explosion的情况,当然梯度爆炸(gradient explosion)不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩),但是梯度消失做不到,这个时候就要用lstm了。
在lstm中,我们发现,状态S是通过累加的方式来计算的,。那这样的话,就不是一直复合函数的形式了,它的的导数也不是乘积的形式,这样就不会发生梯度消失的情况了。
LSTM的变种gru
循环门单元,组合了遗忘门和输入门到一个单独的更新门中,合并了cell state和hidden state,并且做了一些其他的改变。结果模型比标准LSTM模型更简单,并且正越来越受欢迎,下面详细说明:
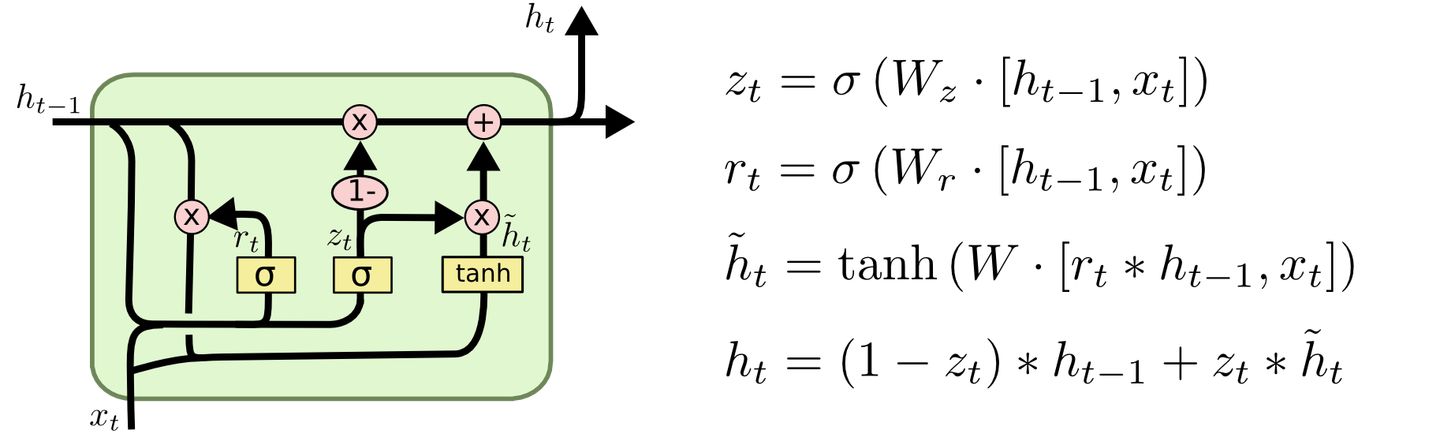
首先介绍GRU的两个门,分别是reset gate rt 和update gate ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/c70a860e521f601ee3b82d8d220d47c0.png) ,计算方法和LSTM中门的计算方法一致:
,计算方法和LSTM中门的计算方法一致:

然后是计算候选隐藏层(candidate hidden layer) ht ,这个候选隐藏层 和LSTM中的 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ca18424a26a396f533705c9399bf08ae.png) 是类似,可以看成是当前时刻的新信息,其中
是类似,可以看成是当前时刻的新信息,其中 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/3419f1ce819a9c222dfacec4fd70a6a7.png) 用来控制需要 保留多少之前的记忆,比如如果 为0,那么
用来控制需要 保留多少之前的记忆,比如如果 为0,那么 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/df17ae4b1f883c4508b95a98a4b3a028.png) 只包含当前词的信息:
只包含当前词的信息:
最后 zt 控制需要从前一时刻的隐藏层 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/520210355d7a41455b3182bf173caef4.png) 中遗忘多少信息,需要加入多少当前 时刻的隐藏层信息 ,最后得到
中遗忘多少信息,需要加入多少当前 时刻的隐藏层信息 ,最后得到 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/168a9ff82dd822bd905503b263038928.png) ,直接得到最后输出的隐藏层信息, 需要注意这里与LSTM的区别是GRU中没有output gate:
,直接得到最后输出的隐藏层信息, 需要注意这里与LSTM的区别是GRU中没有output gate:
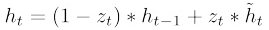
一般来说那些具有短距离依赖的单元reset gate比较活跃(如果 rt 为1,而 为0 那么相当于变成了一个标准的RNN,能处理短距离依赖),具有长距离依赖的单元update gate比较活跃。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









