







1. KNN算法简介
K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。其指导思想是”近朱者赤,近墨者黑“,即由你的邻居来推断出你的类别。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
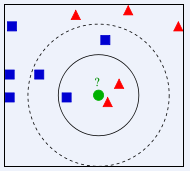
如下图所示,如何判断绿色圆应该属于哪一类,是属于红色三角形还是属于蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被判定为属于红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆将被判定为属于蓝色四方形类。
2. 算法描述
-
算距离:给定待分类样本,计算它与已分类样本中的每个样本的距离;
-
找邻居:圈定与待分类样本距离最近的K个已分类样本,作为待分类样本的近邻;
-
做分类:根据这K个近邻中的大部分样本所属的类别来决定待分类样本该属于哪个分类;
3. 算法的关键
(1) K值的选取
K:临近数,即在预测目标点时取几个临近的点来预测。
-
如果当K的取值过小时,一旦有噪声得成分存在们将会对预测产生比较大影响,例如取K值为1时,一旦最近的一个点是噪声,那么就会出现偏差,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
-
如果K的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大,容易引起欠拟合。这时与输入目标点较远实例也会对预测起作用,使预测发生错误。K值的增大就意味着整体的模型变得简单;如果K=N的时候,那么就是取全部的实例,即为取实例中某分类下最多的点,就对预测没有什么实际的意义了;
-
K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。
不能过小,不能过大,需交叉验证确定K值
(2) 样本特征要做归一化处理
样本有多个参数,每一个参数都有自己的定义域和取值范围,他们对距离计算的影响不一样,如取值较大的影响力会盖过取值较小的参数。所以样本参数必须做一些 scale 处理,最简单的方式就是所有特征的数值都采取归一化处置。 x n e w = x − m i n m a x − m i n x_{new}= {x-min \over max-min} xnew=max−minx−min
(3) 需要一个距离函数以计算两个样本之间的距离
通常使用的距离函数有:欧氏距离、余弦距离、汉明距离、曼哈顿距离等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,汉明距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高,如运用大边缘最近邻法或者近邻成分分析法。
4. 算法的缺点
-
KNN算法是最简单有效的分类算法,简单且容易实现。当训练数据集很大时,需要大量存储空间,而且需要计算待测样本和训练数据集中所有样本的距离,所以非常耗时。
-
KNN对于随机分布的数据集分类效果较差,对于类内间距小,类间间距大的数据集分类效果好,而且对于边界不规则的数据效果好于线性分类器。
-
KNN对于样本不均衡的数据效果不好,需要进行改进。改进的方法时对k个近邻数据赋予权重,比如距离测试样本越近,权重越大。















 7474
7474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









