






本文主要是为了帮助那些开始阅读文献但没有头绪的,也不知道从哪里开始读起的同学,文中列举的论文都是我挑选并读过的,给各位做一个参考,其中必定也有疏漏,请见谅!
1.文献下载途径
1.1 https://arxiv.org/list/cs.CV/recent 该网站是一个paper发行之前的预印本,几乎最新的动向上面基本都有。几乎所有的paper上面都能找到,按标题搜索即可。
1.2 谷歌学术镜像 http://scholar.hedasudi.com 备用选项
2、文献列表
最好是按照顺序来读,不要跳跃的太厉害。
| No. | Reading Method | Title | Model | Year |
| 1 | Intensive Reading | Deep Learning | / | 2015 |
| 2 | Intensive Reading | ImageNet Classification with Deep Convolutional Neural Networks | AlexNet | 2012 |
| 3 | Intensive Reading | Very deep convolutional networks for large-scale image recognition | VGG | 2014 |
| 4 | Intensive Reading | Deep residual learning for image recognition | ResNet | 2016 |
| 5 | Intensive Reading | Going deeper with convolutions | GoogLeNet | 2014 |
| 6 | Seletive Reading | Rethinking the Inception Architecture for Computer Vision | Inception V3 | 2016 |
| 7 | Skimming | Inception-v4, inception-ResNet and the impact of residual connections on learning | Inception V4 | 2017 |
| 8 | Intensive Reading | Batch normalization: Accelerating deep network training by reducing internal covariate shift | Inception V2(BN) | 2015 |
| 9 | Intensive Reading | Aggregated residual transformations for deep neural networks | ResNeXt | 2016 |
| 10 | Intensive Reading | Squeeze-and-Excitation Networks | SENet | 2017 |
| 11 | Intensive Reading | Densely connected convolutional networks | DensenNet | 2017 |
| 12 | Intensive Reading | Rich feature hierarchies for accurate object detection and semantic segmentation | R-CNN | 2014 |
| 13 | Intensive Reading | Fast R-CNN | Fast R-CNN | 2015 |
| 14 | Skimming | Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | Faster R-CNN | 2016 |
| 15 | Intensive Reading | You Only Look Once: Unified, Real-Time Object Detection | YOLO V1 | 2015 |
| 16 | Intensive Reading | YOLO9000: Better, faster, stronger | YOLO V2 | 2016 |
| 17 | Intensive Reading | MobileNets: Efficient convolutional neural networks for mobile vision applications | MobileNet V1 | 2017 |
| 18 | Seletive Reading | MobileNetV2: Inverted Residuals and Linear Bottlenecks | MobileNet V2 | 2018 |
| 19 | Skimming | Searching for mobileNetV3 | MobileNet V3 | 2019 |
| 20 | Intensive Reading | ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices | ShuffleNet V1 | 2017 |
| 21 | Intensive Reading | Shufflenet V2: Practical guidelines for efficient cnn architecture design | ShuffleNet V2 | 2018 |
| 22 | Intensive Reading | EfficientNet: Rethinking model scaling for convolutional neural networks | EfficientNet V1 | 2019 |
| 23 | Intensive Reading | EfficientNetV2: Smaller Models and Faster Training | EfficientNet V2 | 2021 |
| 24 | Seletive Reading | Efficient Estimation of Word Representations in Vector Space | Word2Vec | 2013 |
| 25 | Skimming | Neural architecture search with reinforcement learning | NAS | 2017 |
| 26 | Intensive Reading | Learning Transferable Architectures for Scalable Image Recognition | NASNet | 2018 |
| 27 | Intensive Reading | MixUp: Beyond empirical risk minimization | MixUP | 2018 |
| 28 | Intensive Reading | Fully Convolutional Networks for Semantic Segmentation | FCN | 2015 |
| 29 | Intensive Reading | U-Net: Convolutional Networks for Biomedical Image Segmentation | U-Net | 2015 |
| 30 | Seletive Reading | SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation | SegNet | 2016 |
| 31 | Intensive Reading | Attention is all you need | Transformer | 2017 |
| 32 | Intensive Reading | An image is worht 16 X 16 words : Transformers for Image Recognition At Scale | ViT | 2020 |
| 33 | Skimming | Generative adversarial networks | GAN | 2014 |
| 34 | Seletive Reading | Rethinking Atrous Convolution for Semantic Image Segmentation | DeepLab V3 | 2017 |
| 35 | Intensive Reading | Encoder-decoder with atrous separable convolution for semantic image segmentation | DeepLab V3+ | 2018 |
| 36 | Intensive Reading | Pyramid scene parsing network | PSPNet | 2017 |
| 37 | Intensive Reading | Swin Transformer: Hierarchical Vision Transformer using Shifted Windows | Swin Transformer | 2021 |
| 38 | Seletive Reading | Unsupervised representation learning with deep convolutional generative adversarial networks | DCGAN | 2016 |
| 39 | Intensive Reading | Bottleneck Transformers for Visual Recognition | BoTNet | 2021 |
| 40 | Intensive Reading | MLP-Mixer: An all-MLP Architecture for Vision | MLP-mixer | 2021 |
| 41 | Seletive Reading | Do You Even Need Attention A Stack of Feed-Forward Layers DoesSurprisingly Well on ImageNet | / | 2021 |
| 42 | Seletive Reading | Distilling the Knowledge in a Neural Network | Knowledge Distillation | 2015 |
| 43 | Intensive Reading | Training data-efficient image transformers& distillation through attention | DeiT | 2021 |
| 44 | Intensive Reading | CvT: Introducing Convolutions to Vision Transformers | Cvt | 2021 |
3.总结概括
3.1当你读完paper以后要记得总结,需要一个文献阅读的记录表,表头如下,尽量简单的几句话概括paper的精髓。
| No. | Reading Method | Time | Model | Title | Authors | Year | Journal | Key Words | Abstract | "approach/ |
| technique" | Method overview | Conclusion | Gap | My Comments | Data and Code | Mind Mapping | ||||
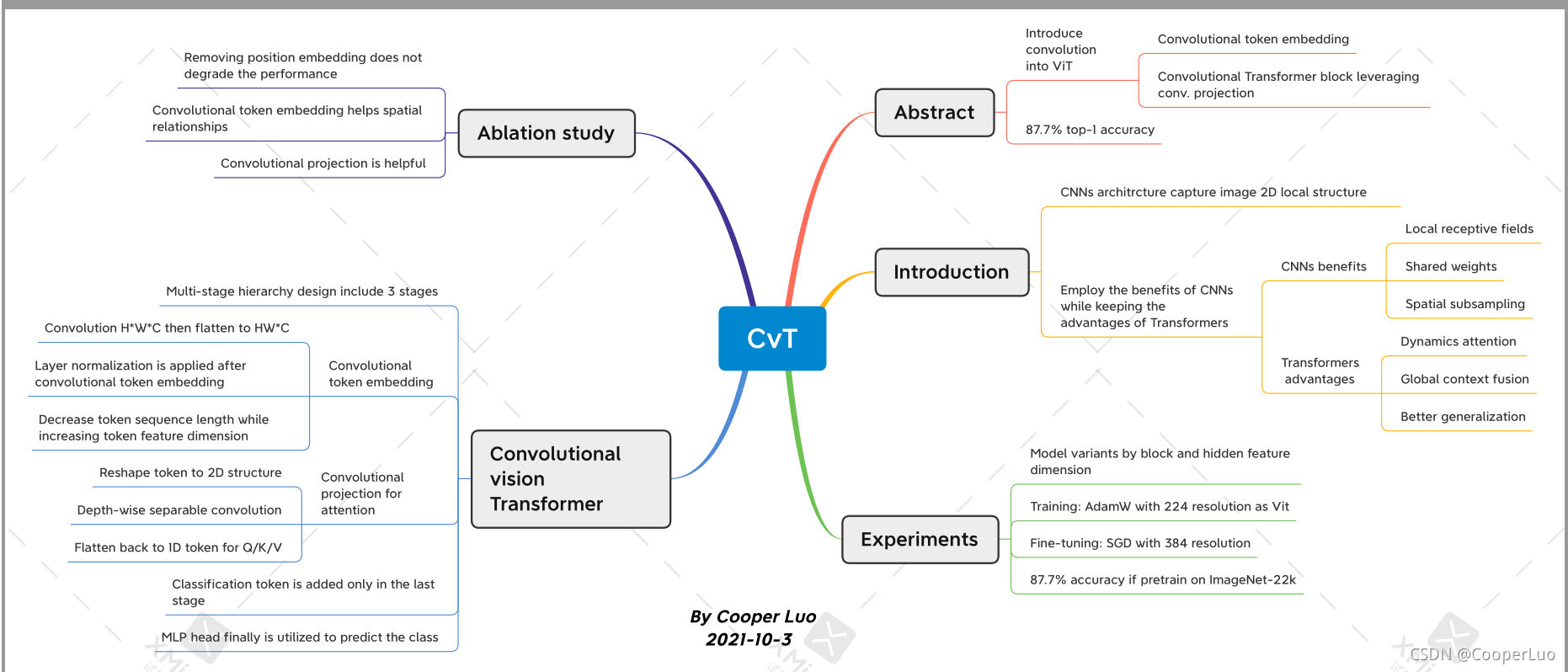
3.2 思维导图
我使用的免费版的xmind,虽然不能插入图片和公式有点麻烦,有条件可以买付费版。
4.代码实现
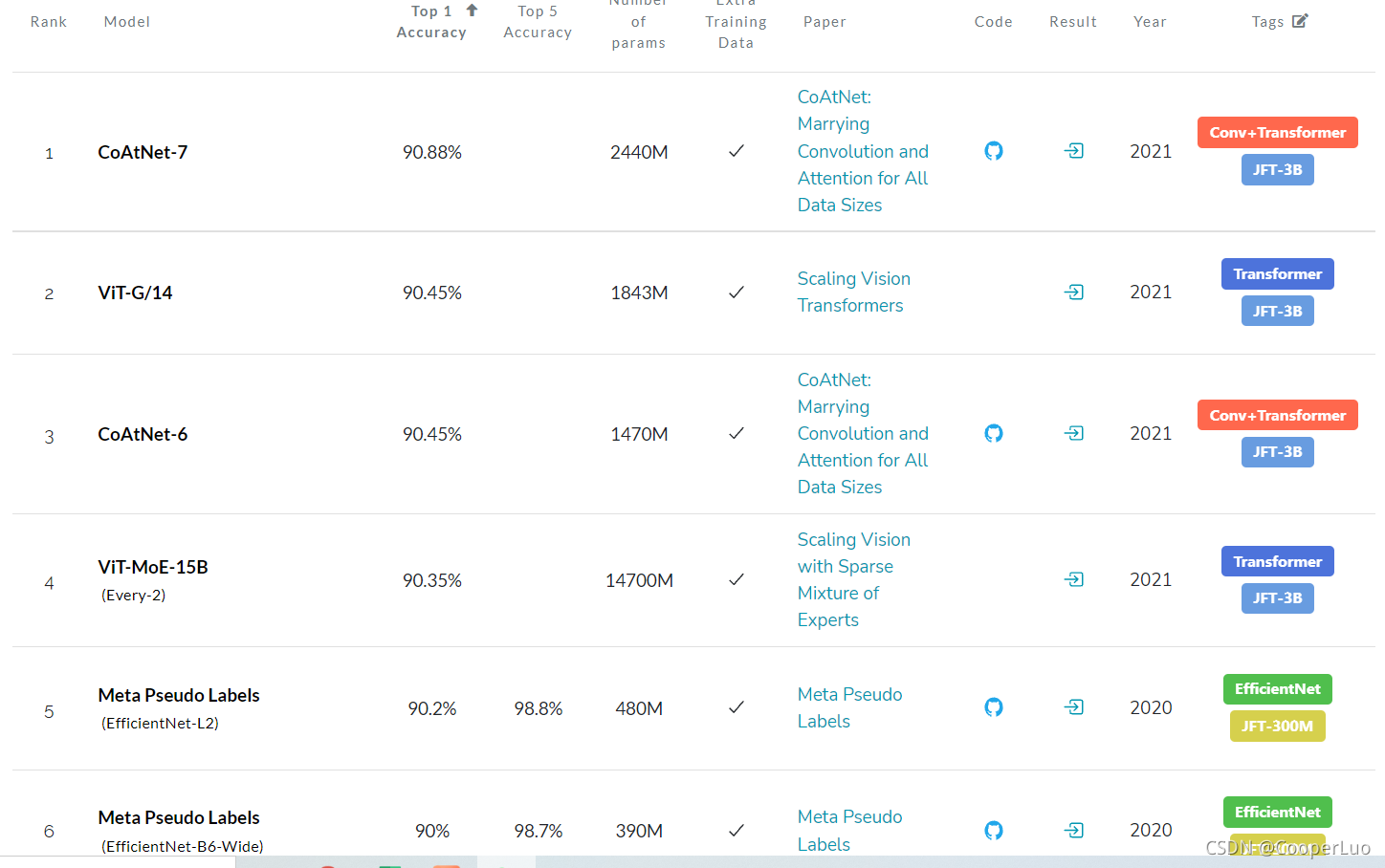
paper当中的源码一般是开源的,作者一般会在paper当中提供提供的GitHub。但pytorch和TensorFlow版本有时候只有一种,这对刚好不熟悉的另一种的同学可能有些困难,这时候可以去paperwithcode上面查找,一般多个框架下的代码实现均有。https://paperswithcode.com/sota这个网站还可以看到正确率排名,可以帮助我们及时的跟进学术最前沿。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









