







看到一篇好的帮助理解协议逆向的文章,比较能够帮助理解协议逆向的过程,所以将文章中的东西扒下来顺便总结。
工具
捕获协议流量
在这篇文章中,将使用SuperFunkyChat应用程序,它是一个 C# 二进制协议应用程序,可用于学习协议逆向工程。
该应用程序将在 Windows、Linux 和 OS X 上运行。可以从GitHub下载最新的预构建应用程序和源代码。只需确保选择适合平台的发行二进制文件即可。需要安装.NET Core,以便应用程序正常工作。
安装并解压所有内容后,应该在 SuperFunkyChat 文件夹中看到以下文件。
kkb@kkb-ubuntu:~/SuperFunkyChat$ ls
ChatClient.deps.json ChatServer.dll
ChatClient.dll ChatServer.pdb
ChatClient.pdb ChatServer.runtimeconfig.json
ChatClient.runtimeconfig.json LICENSE
ChatProtocol.dll Microsoft.Extensions.CommandLineUtils.dll
ChatProtocol.pdb README.md
ChatServer.deps.json在开始捕获数据包之前,先启动聊天服务器。作者使用的是 Linux,因此在命令前面添加前缀dotnet,以便应用程序知道使用 .NET Core 来运行应用程序。
kkb@kkb-ubuntu:~/SuperFunkyChat$ dotnet ChatServer.dll
ChatServer (c) 2017 James Forshaw
WARNING: Don't use this for a real chat system!!!
Running server on port 12345 Global Bind False好启动并运行了服务器之前启动 Wireshark,捕获应用程序协议流量。
开始嗅探本地主机以太网适配器上的流量Loopback:lo。继续双击本地以太网适配器并确保正在捕获数据包。

在另一个控制台中启动我们的聊天客户端并指定我们想要使用的用户名以及我们想要连接的主机名。在这种情况下,用户名将是“ test ”,将连接到我的“ locahost ”实例,因为那是聊天服务器所在的位置。
kkb@kkb-ubuntu:~/SuperFunkyChat$ dotnet ChatClient.dll test localhost
ChatClient (c) 2017 James Forshaw
WARNING: Don't use this for a real chat system!!!
Connecting to localhost:12345
>如果操作正确,应该在运行聊天服务器的控制台中看到类似的输出。
Connection from 127.0.0.1:46251 to
Received packet ChatProtocol.HelloProtocolPacket
Hello Packet for User: test HostName: kkb-ubuntu现在客户端已成功连接到我们的服务器,应该能够在 Wireshark 中看到一些网络流量。

能够捕获连接流量,并且应该能够看到客户端如何连接服务器并向服务器进行身份验证。为了确保有足够的数据来处理和分析,让我们发送一些聊天消息,然后键入/quit以断开连接并捕获断开连接的流量。
> This is a test message!
> Hello - testing!
> /quit
Server> : Don't let the door hit you on the way out!在发送消息并退出会话的同时,应该在聊天服务器控制台中看到类似于以下输出的内容。
Received packet ChatProtocol.MessageProtocolPacket
Received packet ChatProtocol.MessageProtocolPacket
Received packet ChatProtocol.GoodbyeProtocolPacket
Closing Client现在已经通过应用程序生成了更多网络流量,停止在 Wireshark 中捕获数据包,接下来开始分析应用程序协议流量。
分析协议流量
看一下生成的流量,可以大致了解客户端和服务器之间发生的通信。
右键单击第一个数据包,然后跟随 TCP 流。可以看到流量的十六进制/ASCII 表示形式。

跟踪 TCP 流后,应该会看到一些文本,包括设备的名称、发送的消息以及一些服务器响应。颜色代表流量的方向,红色是Client -> Server,蓝色是Server -> Client。

可以看到网络协议的 ASCII 表示形式,但这不是所需要的。由于要对应用程序协议进行逆向工程,因此需要查看从客户端和服务器发送的数据包中包含的所有内容。
WHY?
看一下 TCP 流。您注意到流中"......"的了吗?这个单点字符替代了 Wireshark 无法表示为 ASCII 的数据。所以正在研究的网络协议并不是一个单纯基于文本的协议。
实际上在此协议中看到文本的唯一原因是因为这是一个聊天应用程序 - 主要用于发送文本!这意味着在数据包标头或正文中发送的控制信息可能是十六进制的。
tips:
请注意,这个二进制协议很容易区分。有大量协议也可以纯粹作为基于文本的协议工作,并且有些协议都是二进制/十六进制的。
“如果协议已加密,该怎么办?”
到那时,有大量的工作需要完成,这可能会成为一项非常艰巨的任务。在某些情况下,它甚至不可能被打破。当然,如果加密是本地开发的,您可能可以考虑尝试绕过它(不要使用自己的加密货币!),但这仍然需要大量时间和经验。
我们从学习基础知识开始。如果想要更多练习,那么我建议从已经有详细记录的协议(比如一些已经公开实现规范或RFC文档的协议)开始。这是拥有可以确认自己逆向的效果的方法。
另外,如果不熟悉基于socket软件开发,推荐使用纯文本协议,例如 IRC 协议(RFC1459)。
首先 - 将对话仅与Client隔离。服务器侦听 TCP 12345,因此要选择向该端口发送流量的对话。
通过单击“Entire conversation (190 bytes) ”下拉菜单并选择适当的方向来隔离对话。

一旦对话被隔离,应该只看到红色,这将是的客户端 -> 服务器流量。

在隔离对话之后,现在可以开始挖掘我们的数据包。为了能够成功地对协议进行逆向工程,需要能够看到协议发送的所有字节。
在“Show and save data as”下拉列表中,单击并选择“Hex Dump”。
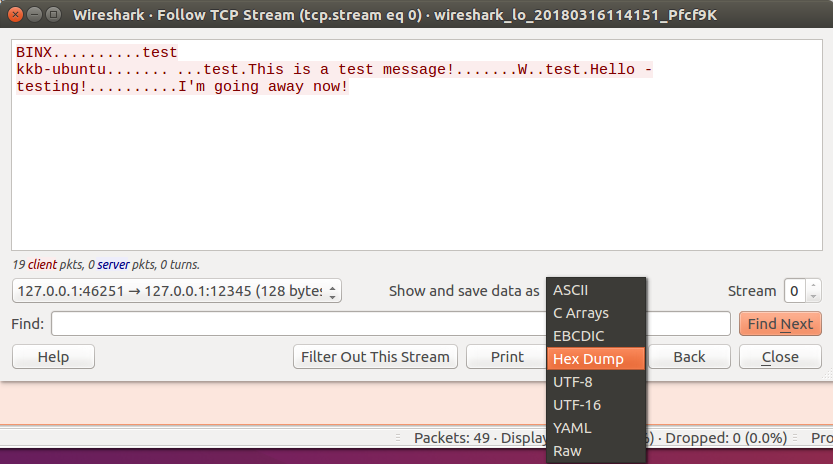
这样做的目的是能够同时获得流量和发送的每个数据包的十六进制和 ASCII 表示形式。这样至少可以了解协议数据包的结构、它使用了什么命令等。

推断协议结构
现在知道这个协议是文本/二进制,可以开始通过查看数据包/十六进制来确定协议的结构。
首先看一下前几个数据包。
00000000 42 49 4e 58 BINX
00000004 00 00 00 12 ....
00000008 00 00 05 d6 ....
0000000C 00 .
0000000D 04 74 65 73 74 0a 6b 6b 62 2d 75 62 75 6e 74 75 .test.kk b-ubuntu
0000001D 00 .
0000001E 00 00 00 1e ....
00000022 00 00 09 f9 ....
00000026 03 .
00000027 04 74 65 73 74 17 54 68 69 73 20 69 73 20 61 20 .test.Th is is a
00000037 74 65 73 74 20 6d 65 73 73 61 67 65 21 test mes sage!查看第一个块,有 4 个字节长,并以四个字符BINX开头。看起来这 4 个字符在数据包数据的其余部分中没有重复,因此可以假设这是将客户端连接到服务器时用于区分有效连接的命令。
接下来的两个块也是 4 字节长,后面是 1 字节大小的块,最后是包含大部分可读文本的更大的块。
下一个块似乎也是一个 1 字节大小的块 - 这是一个空字节\x00……但这似乎也是文本块的一部分。这可能是发送 Hello 数据包时的字符串终止符。
现在就知道,可以将十六进制转储分成 3 个单独的数据包。connection packet、Hello packet和Chat packet。
----------------------------------------------------------------------------- <- Connection Packet
00000000 42 49 4e 58 BINX
----------------------------------------------------------------------------- <- Hello Packet
00000004 00 00 00 12 ....
00000008 00 00 05 d6 ....
0000000C 00 .
0000000D 04 74 65 73 74 0a 6b 6b 62 2d 75 62 75 6e 74 75 .test.kk b-ubuntu
0000001D 00 .
----------------------------------------------------------------------------- <- Chat Packet
0000001E 00 00 00 1e ....
00000022 00 00 09 f9 ....
00000026 03 .
00000027 04 74 65 73 74 17 54 68 69 73 20 69 73 20 61 20 .test.Th is is a
00000037 74 65 73 74 20 6d 65 73 73 61 67 65 21 test mes sage!通过观察发现,貌似这个协议的所有数据包都有四个部分,但是Connection 数据包除外。现在已经将数据包分开并对该结构有了一些基本了解,接下来深入研究每个块并弄清楚它们代表什么。
首先查看 00000004处的四字节块。前3个字节都是空的,所以里面确实没有数据。最后有一个十六进制值0x12。wireshark会将不是ASCII编码的数据显示为”.“所以这个地方显示为....
所以,如果0x12不是ASCII的话,他有可能是十进制,转换后是18,但是这意味着什么呢?
为了更好地理解这一点,首先需要了解 TLV 或Type-Length-Value。也称为标签、长度值。对于 TCP 协议,TLV 是一种用于某些协议中可选信息元素的编码方案。
这在 TCP 等基于流的协议中是必要的,因为它允许应用程序或客户端和服务器知道需要从连接读取多少数据来处理协议。
类型和长度的大小是固定的(通常为1-4字节),而值字段的大小是可变的。这些字段的使用方式如下:
- type:二进制代码,通常只是字母数字,表示消息的这一部分所代表的字段类型。
- length:值字段的大小,通常以字节为单位。
- value:包含消息这部分数据的可变大小的字节序列。
所以,看上去这个0x12可能代表着值字段的长度为18bytes,但是可以看到0000000D 到 0000001D 中只有17个bytes,所以并不符合,为什么呢?
查看这些协议,当内容不相符时,数据会令人困惑。为了更好地理解为什么只有 17 字节而不是 18 字节的数据,需要了解可变长度缓冲区是如何在堆栈上分配的。对于可变长度缓冲区 Variable-Length Buffers,应用程序为存储的数据分配正确大小的缓冲区。通常在 TCP 协议中使用此方法,因此没有固定的缓冲区,如果为缓冲区提供太多数据来保存,则可能导致缓冲区溢出。如果应用程序错误地计算缓冲区大小,也可能会发生缓冲区溢出。
回到我们分析的协议中 - 该块分配了 18 个字节的数据,17 个字节用于传递的数据,以及另一个字节,通常是空终止符 Null Terminator,它会阻止缓冲区读取传递的分配的数据 - 从而阻止缓冲区溢出的发生。
现在假设第一个块是基于 TLV 的长度,同样假设文本部分是值。
00000004 00 00 00 12 .... <- Length
00000008 00 00 05 d6 .... <- ?
0000000C 00 . <- ?
0000000D 04 74 65 73 74 0a 6b 6b 62 2d 75 62 75 6e 74 75 .test.kk b-ubuntu <- Value
0000001D 00那么另外两个块是什么呢?由于第一个块是十进制,那么第二个和第三个块也应该是十进制表示形式,因为 Wireshark 用符号替换了数据,因此它们没有 ASCII 表示形式.。
如果我们获取第二个块数据0x05D6并将其转换为十进制,那么我们会得到1494。1494到底和什么有关?
看下一个块,会发现0x00实际就是0。
现在对这些块的用途感到非常困惑。此时需要做的是通过编写解析器将每个数据包与另一个数据包进行比较,该解析器应该解析我们的数据包并写出它的值,以便可以将它们与流中的其他数据包进行比较。(逆向工程中最核心的部分)
同时这也将有助于巩固已经对数据包中其他块所做的假设,并进一步帮助理解其他部分。
协议数据结构拆分
现在知道这个协议是文本/二进制,可以开始通过查看数据包/十六进制来确定协议的结构。
首先看一下前几个数据包。
00000000 42 49 4e 58 BINX
00000004 00 00 00 12 ....
00000008 00 00 05 d6 ....
0000000C 00 .
0000000D 04 74 65 73 74 0a 6b 6b 62 2d 75 62 75 6e 74 75 .test.kk b-ubuntu
0000001D 00 .
0000001E 00 00 00 1e ....
00000022 00 00 09 f9 ....
00000026 03 .
00000027 04 74 65 73 74 17 54 68 69 73 20 69 73 20 61 20 .test.Th is is a
00000037 74 65 73 74 20 6d 65 73 73 61 67 65 21 test mes sage!查看第一个块,有 4 个字节长,并以四个字符BINX开头。看起来这 4 个字符在数据包数据的其余部分中没有重复,因此可以假设这是将客户端连接到服务器时用于区分有效连接的命令。
接下来的两个块也是 4 字节长,后面是 1 字节大小的块,最后是包含大部分可读文本的更大的块。
下一个块似乎也是一个 1 字节大小的块 - 这是一个空字节\x00……但这似乎也是文本块的一部分。这可能是发送 Hello 数据包时的字符串终止符。
现在就知道,可以将十六进制转储分成 3 个单独的数据包。connection packet、Hello packet和Chat packet。
----------------------------------------------------------------------------- <- Connection Packet
00000000 42 49 4e 58 BINX
----------------------------------------------------------------------------- <- Hello Packet
00000004 00 00 00 12 ....
00000008 00 00 05 d6 ....
0000000C 00 .
0000000D 04 74 65 73 74 0a 6b 6b 62 2d 75 62 75 6e 74 75 .test.kk b-ubuntu
0000001D 00 .
----------------------------------------------------------------------------- <- Chat Packet
0000001E 00 00 00 1e ....
00000022 00 00 09 f9 ....
00000026 03 .
00000027 04 74 65 73 74 17 54 68 69 73 20 69 73 20 61 20 .test.Th is is a
00000037 74 65 73 74 20 6d 65 73 73 61 67 65 21 test mes sage!通过观察发现,貌似这个协议的所有数据包都有四个部分,但是Connection 数据包除外。现在已经将数据包分开并对该结构有了一些基本了解,接下来深入研究每个块并弄清楚它们代表什么。
让我们首先查看 00000004处的四字节块。前3个字节都是空的,所以里面确实没有数据。最后有一个十六进制值0x12。wireshark会将不是ASCII编码的数据显示为”.“所以这个地方显示为....
所以,如果0x12不是ASCII的话,他有可能是十进制,转换后是18,但是这意味着什么呢?
为了更好地理解这一点,首先需要了解 TLV 或Type-Length-Value。也称为标签、长度值。对于 TCP 协议,TLV 是一种用于某些协议中可选信息元素的编码方案。
这在 TCP 等基于流的协议中是必要的,因为它允许应用程序或客户端和服务器知道需要从连接读取多少数据来处理协议。
类型和长度的大小是固定的(通常为1-4字节),而值字段的大小是可变的。这些字段的使用方式如下:
- type:二进制代码,通常只是字母数字,表示消息的这一部分所代表的字段类型。
- length:值字段的大小,通常以字节为单位。
- value:包含消息这部分数据的可变大小的字节序列。
所以,看上去这个0x12可能代表着值字段的长度为18bytes,但是可以看到0000000D 到 0000001D 中只有17个bytes,所以并不符合,为什么呢?
查看这些协议,当内容不相符时,数据会令人困惑。为了更好地理解为什么只有 17 字节而不是 18 字节的数据,需要了解可变长度缓冲区是如何在堆栈上分配的。对于可变长度缓冲区 Variable-Length Buffers,应用程序为存储的数据分配正确大小的缓冲区。通常在 TCP 协议中使用此方法,因此没有固定的缓冲区,如果为缓冲区提供太多数据来保存,则可能导致缓冲区溢出。如果应用程序错误地计算缓冲区大小,也可能会发生缓冲区溢出。
回到我们分析的协议中 - 该块分配了 18 个字节的数据,17 个字节用于传递的数据,以及另一个字节,通常是空终止符 Null Terminator,它会阻止缓冲区读取传递的分配的数据 - 从而阻止缓冲区溢出的发生。
现在假设第一个块是基于 TLV 的长度,同样假设文本部分是值。
00000004 00 00 00 12 .... <- Length
00000008 00 00 05 d6 .... <- ?
0000000C 00 . <- ?
0000000D 04 74 65 73 74 0a 6b 6b 62 2d 75 62 75 6e 74 75 .test.kk b-ubuntu <- Value
0000001D 00那么另外两个块是什么呢?由于第一个块是十进制,那么第二个和第三个块也应该是十进制表示形式,因为 Wireshark 用符号替换了数据,因此它们没有 ASCII 表示形式.。
如果我们获取第二个块数据0x05D6并将其转换为十进制,那么我们会得到1494。1494到底和什么有关?
看下一个块,会发现0x00实际就是0。
现在对这些块的用途感到非常困惑。此时需要做的是通过编写解析器将每个数据包与另一个数据包进行比较,该解析器应该解析我们的数据包并写出它的值,以便可以将它们与流中的其他数据包进行比较。(逆向工程中最核心的部分)
同时这也将有助于巩固已经对数据包中其他块所做的假设,并进一步帮助理解其他部分。
解析协议内容
对于这一部分,将使用 Python 来读取和解析 Wireshark PCAP 文件。但在此之前,需要将所有数据包字节导出到文件中。
为此,在流窗口的“Show and save data as”部分中,单击下拉菜单并选择“Raw”。
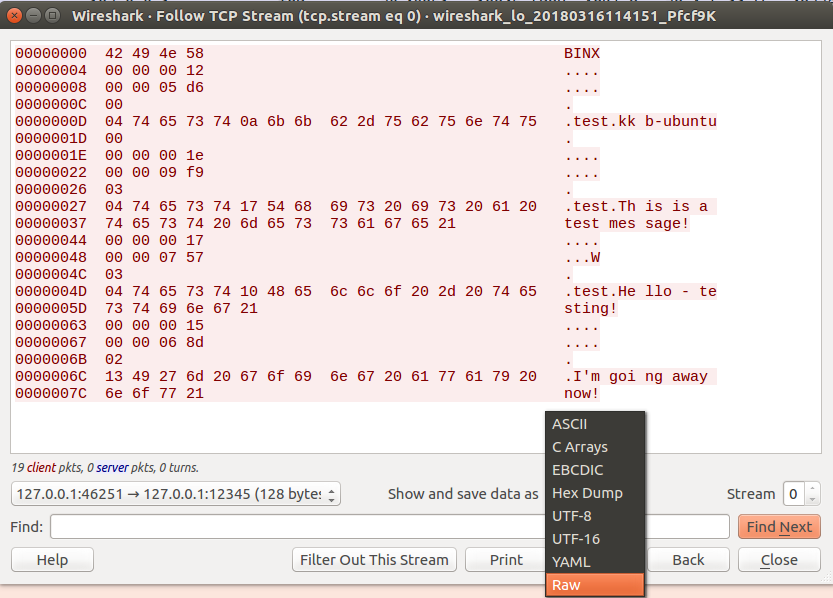
现在应该只能看到网络协议的原始二进制数据。
完成后,只需单击“Save as. ”并将文件另存为“ outbound.bin ”。
保存文件后,让我们打开终端控制台,并使用xxd工具针对 bin 文件检查是否成功转储了所需的数据。
kkb@kkb-ubuntu:~$ xxd outbound.bin
00000000: 4249 4e58 0000 0012 0000 05d6 0004 7465 BINX..........te
00000010: 7374 0a6b 6b62 2d75 6275 6e74 7500 0000 st.kkb-ubuntu...
00000020: 001e 0000 09f9 0304 7465 7374 1754 6869 ........test.Thi
00000030: 7320 6973 2061 2074 6573 7420 6d65 7373 s is a test mess
00000040: 6167 6521 0000 0017 0000 0757 0304 7465 age!.......W..te
00000050: 7374 1048 656c 6c6f 202d 2074 6573 7469 st.Hello - testi
00000060: 6e67 2100 0000 1500 0006 8d02 1349 276d ng!..........I'm
00000070: 2067 6f69 6e67 2061 7761 7920 6e6f 7721 going away now!能够成功保存来自 pcap 的所有协议流量。现在可以开始编写 Python 脚本,该脚本将读取 bin 文件,并按网络字节顺序读取二进制数据。“network byte order”采用 Big Endian,与 x86 和 x64 进程中使用的 Little Endian 不同。
Python 脚本将类似于以下脚本:
from struct import unpack
import sys
import os
# Read a fixed number of bytes, dictated by "l"
def read_bytes(f, l):
bytes = f.read(l)
if len(bytes) != l:
raise Exception("Not enough bytes in stream")
return bytes
# Unpack a 4 byte integer in network byte order
def read_int(f):
return unpack("!i", read_bytes(f, 4))[0]
# Read a single byte
def read_byte(f):
return ord(read_bytes(f, 1))
filename = sys.argv[1]
file_size = os.path.getsize(filename)
f = open(filename, "rb")
print ("Connection: %s" % read_bytes(f, 4))
# Keep reading until file is empty.
while f.tell() < file_size:
length = read_int(f)
val1 = read_int(f)
val2 = read_byte(f)
data = read_bytes(f, length - 1)
print("Len: %d, Val1: %d, Val2: %d, Data: %s" % (length, val1, val2, data))三个方法:
- read_bytes:它接受两个参数;从中读取字节的文件,以及从“l”传递的要读取的字节数。
- read_int:解压四个字节并将其作为整数读入。
- read_byte:它只是读取一个字节的数据。
将“ filename ”设置为等于用户从命令行传递的文件名,并将其设置为“ f ”。
文件打开后,读取前 4 个字节,应该是连接命令“ BINX ”,然后将其打印到控制台。
接下来,迭代该文件,直到它为空并且没有更多的字节可供读取。在迭代文件时,做了一些事情:
- 按网络字节顺序解压数据包的前四个字节,以整数形式读取字节并将其设置为长度。从技术上讲,这应该是指示数据长度的数据包的第一个块,正如在结构分析期间假设的那样。
- 解压数据包的接下来的四个字节,将它们作为整数读取并将其设置为“ Val1”,这是第一个未知值。
- 读取下一个单字节块,并将其设置为“ Val2 ”,这是第二个未知值。
- 使用在块一中找到的长度减一来读取数据包数据的其余部分。请记住需要减去添加的额外字节 - 假设其中是空字符串终止符。
- 在代表单个数据包的单行上打印出长度、未知值 1 和 2 以及数据。
总的来说,该脚本非常简单,能够快速解析数据包中的所有数据,然后可以使用这些数据与其他数据包进行比较。继续运行 Python 脚本,并将 bin 文件的名称也包含在命令中。
kkb@kkb-ubuntu:~$ python3 protocol_parse.py outbound.bin
Connection: b'BINX'
Len: 18, Val1: 1494, Val2: 0, Data: b'\x04test\nkkb-ubuntu\x00'
Len: 30, Val1: 2553, Val2: 3, Data: b'\x04test\x17This is a test message!'
Len: 23, Val1: 1879, Val2: 3, Data: b'\x04test\x10Hello - testing!'
Len: 21, Val1: 1677, Val2: 2, Data: b"\x13I'm going away now!"以易于阅读的格式打印了每个数据包的长度、未知值和数据。现在可以继续确定协议结构。
结构推断
已经解析了协议数据结构,现在看看发送的第一个连接数据包:
Len: 18, Val1: 1494, Val2: 0, Data: b'\x04test\nkkb-ubuntu\x00'对第一个块的假设是正确的,事实上它为空终止符提供了发送的数据的长度+1!注意数据包中的\x00并不是终止符!!!!空终止符实际上是在服务器收到这个包17位之后自己打印出来的。
还可以看到,使用脚本处理后,来自 Wireshark 的不可打印数据现在实际上以十六进制显示。能够帮助更好地了解协议的结构以及它传递的数据。
如果仔细观察数据包的“DATA”部分,会看到三个十六进制字节;\x04,\n和\x00。注意这些字节所在的位置。如果要转换\x04为十进制,则等于4,这将是我们用户名的确切长度!\n只是一个换行符,并且\x00是字符串的终止符 - 在本例中是连接到聊天服务器的用户名和设备的终止符。
由此看来,数据中的第一个字节似乎是用户名的长度。可以通过查看我们发送的下一个数据包(即我们的聊天消息)来验证这一点。
Len: 30, Val1: 2553, Val2: 3, Data: b'\x04test\x17This is a test message!'用户名“ test ”有 4 个字符长,所以\x04再次出现!再往下看,另一个十六进制字节,这次转换为十进制后就是我们发送的消息的确切长度。\x17转换后就是23
现在知道数据包的数据部分也在 TLV 上,这让服务器知道需要为用户名和消息分配多少数据才能适合堆栈 - 防止缓冲区溢出。
现在知道这些提供了数据的长度,让我们做一些数学运算,看看它是否确实符合长度值显示的内容。因此,用户名的 4 个字符和数据的 23 个字符将是4 + 23 = 27。等等,27?但长度数据包显示 30……我们错过了什么?
Length 是否也添加了Val2中的值?这是有道理的,因为4 + 23 + 3 = 30。是的,现在我们知道长度是这样计算的:Val2 + Username Length + Message Length = Data Length。
那么现在的问题是,Val2代表什么?回顾一下解析的数据并比较每个数据包的Val2值。
kkb@kkb-ubuntu:~$ python3 read_protocol.py outbound.bin
Connection: b'BINX'
Len: 18, Val1: 1494, Val2: 0, Data: b'\x04test\nkkb-ubuntu\x00'
Len: 30, Val1: 2553, Val2: 3, Data: b'\x04test\x17This is a test message!'
Len: 23, Val1: 1879, Val2: 3, Data: b'\x04test\x10Hello - testing!'
Len: 21, Val1: 1677, Val2: 2, Data: b"\x13I'm going away now!"看一下数据包 2 和数据包3。Val2值是相同的 - 都显示3。虽然其他数据包显示其他值,但它们似乎在 的范围内0-9。
数据包 1 和数据包 2 都是聊天消息,可以假设Val2是客户端/服务器正在执行的命令的表示。3 是聊天消息,0 可能是连接命令,2 可能是退出命令!
| Command # | Direction | Description |
| 0 | Outbound | Connection of Client to Server 客户端与服务器的连接 |
| 2 | Both | Sent when /quit command is used for both server/client 当服务器/客户端都使用 /quit 命令时发送 |
| 3 | Both | Sent when a message is sent to the server and received by clients 当消息发送到服务器并被客户端接收时发送 |
现在已经确定了 90% 的协议结构,剩下的就是弄清楚Val1是什么。
这个值是校验和(checksum)的可能性有多大?。
因为我们正在发送聊天消息,所以必须有某种校验和来验证从客户端发送到服务器的数据没有被修改或损坏!
先了解一下校验和。
校验和通常用于确保网络协议传递的数据的完整性。如果协议采用明文形式,那么这对于服务器来说是防止中间人攻击的好方法。
现在,如果这个协议使用 SSL,那么我们可能会立即放弃,除非我们发现某种Padding Oracle Attack,它允许我们传递加密或明文数据并得到相反的结果,让我们了解加密的功能。现在校验和一般使用使用哈希算法,例如 SHA1 或 SHA2
如果校验和使用具有复杂输入的安全哈希算法,那么尝试拦截数据并更改它,甚至制作自己的数据包几乎是不可能的。但是,如果网络协议使用易于猜测或自定义的滚动校验和,那么如果清楚它是如何运作的,那么从技术上讲,保护措施将不存在。
举以下两个例子:
使用具有复杂输入的安全哈希算法进行校验和:
假设银行系统对每笔交易使用校验和。它通过从用户会话中获取以下内容并将其附加到字符串中来计算每个数据包的校验和:username;hostname;time
一旦提供了值,它就会生成字符串的 SHA1 哈希值,从而提供:fd8f04e9c574b265fa07a69d164f3cd8c2665f84。
祝你好运,尝试找出这个校验和,甚至尝试破解它!这应该是计算校验和的方式。
这基本是不可能的!!!!
使用自定义滚动算法的校验和:
假设银行系统认为使用安全校验和会占用太多资源……因此决定选择自己的自定义滚动校验和生成器
该校验和只是获取消息中数据的每个字节,将字节转换为十进制,最后将它们相加
假设传递的消息的test十六进制为74 65 73 74。将其转换为十进制,我们得到116 + 101 + 115 + 116 = 448
由于数字是整数,因此似乎很容易猜到。作为攻击者,如果知道这一点,该数据的完整性将不安全,因为可以轻松地编辑或创建具有有效校验和的自定义数据包!
“自定义滚动算法”看起来与聊天协议数据包中的Val1值非常相似。
让我们回顾一下解析后的数据包,特别是连接数据包,因为它更小并且更容易测试。
Len: 18, Val1: 1494, Val2: 0, Data: b'\x04test\nkkb-ubuntu\x00'Val1的值为1494。因此,将数据的十六进制表示并将其转换为十进制。以下是我们数据的十六进制表示:
04 74 65 73 74 0a 6b 6b 62 2d 75 62 75 6e 74 75 00现在将其转换为十进制表示形式,如下所示:
4 116 101 115 116 10 107 107 98 45 117 98 117 110 116 117 0这些整数相加,我们得到的值与Val1=1494完全相同!Val1是通过取每个字节的十进制值并将其求和计算得出的校验和。
协议结构图推断
现在已经弄清楚了协议的结构,可以创建一个简单的图表,可以使用它作为网络协议数据包的结构的视觉辅助。
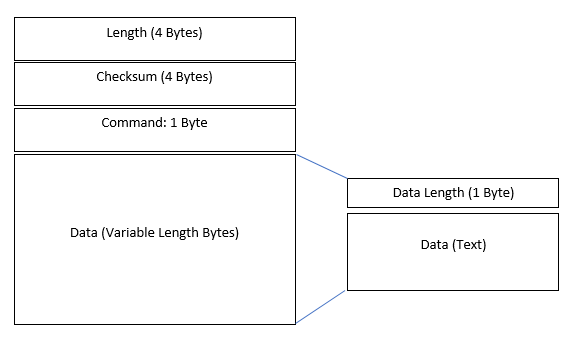
因此,经过大量工作后,终于对聊天应用程序的出站数据包的结构及其包含的内容有了足够的了解。可以假设它们与入站类似。
对于黑客来讲,这时就可以开始拦截数据包,并开始寻找协议中的漏洞,例如缓冲区溢出、整数溢出、命令注入等。

















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









