







目录
LCR 062. 实现 Trie (前缀树)
题目描述:
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
输入
inputs = ["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
inputs = [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过3 * 104次
实现代码与解析:
trie
class Trie {
// 根据节点为默认的0位置,
int[][] son; // son[i][j], 当前节点i,路径为j(字母 - 'a‘),下一个节点为son[i][j];
int[] cnt;
int idx;
int N = 2010;
/** Initialize your data structure here. */
public Trie() {
son = new int[N][26];
cnt = new int[N];
}
/** Inserts a word into the trie. */
public void insert(String word) {
int k = 0;
for (int i = 0; i < word.length(); i++) {
int j = word.charAt(i) - 'a';
if (son[k][j] == 0) son[k][j] = ++idx;
k = son[k][j];
}
cnt[k]++;
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
int k = 0;
for (int i = 0; i < word.length(); i++) {
int j = word.charAt(i) -'a';
if (son[k][j] == 0) return false;
k = son[k][j];
}
if (cnt[k] == 0) return false; // 这里是判断是否是一个单词,而不是只是前缀
return true;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String prefix) {
int k = 0;
for (int i = 0; i < prefix.length(); i++) {
int j = prefix.charAt(i) -'a';
if (son[k][j] == 0) return false;
k = son[k][j];
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/原理思路:
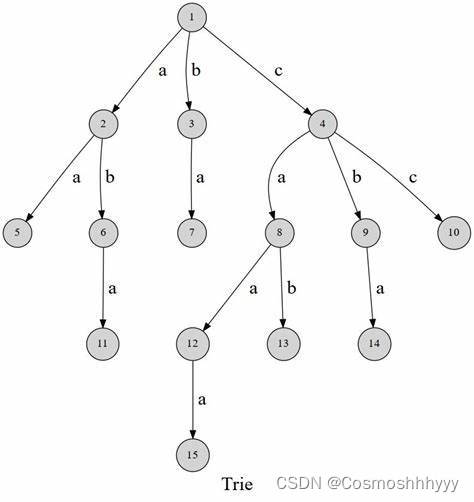 图片来源于网络,这个图还是很直观的,很多图吧字母写在节点上其实是错误的,写在路径上才是对的。
图片来源于网络,这个图还是很直观的,很多图吧字母写在节点上其实是错误的,写在路径上才是对的。
因为26个字母是有限的,所以很多单词前缀是相同的,可以合并的,就可以用一颗树来表示,其实有点像哈夫曼树,只不过不再是01,而是26个字母而已。
理解代码的核心,理解每个数组的含义。
int[][] son; // son[i][j], 当前节点i,路径为j(字母 - 'a‘),下一个节点为son[i][j];
int[] cnt; // snt[i], 以节点i为结尾的单词数量;
默认0节点为根节点。
初始化:
每个节点最多26个孩子,没多少,所以直接初始化出来即可。 son = new int[N][26];
insert:
遍历(char c: str),然后建树,如果当前节点没有孩子为c的孩子,那么就构建一个节点,下标为++idx,如果有,那么就不用再构建,直接利用原本的即可。同时向下再去构建,直到构建完成。说明到了结尾,那么cnt[k]++,当前节点为结尾的单词个数+1。
public void insert(String word) {
int k = 0;
for (int i = 0; i < word.length(); i++) {
int j = word.charAt(i) - 'a';
if (son[k][j] == 0) son[k][j] = ++idx;
k = son[k][j];// 进入下一层
}
cnt[k]++;
}search:
和insert相同,只不过这里是判断,而不是构建。判断路径是否存在 and 判断以word末尾字母结尾的节点的单词是否已经存在(判断cnt)。
public boolean search(String word) {
int k = 0;
for (int i = 0; i < word.length(); i++) {
int j = word.charAt(i) -'a';
if (son[k][j] == 0) return false;
k = son[k][j];
}
if (cnt[k] == 0) return false;
return true;
}startsWith:
这个就更简单了,只需要判断路径是否存在即可,因为只判断浅醉是否已经存在过,不用在乎是否已经有这个单词。
public boolean startsWith(String prefix) {
int k = 0;
for (int i = 0; i < prefix.length(); i++) {
int j = prefix.charAt(i) -'a';
if (son[k][j] == 0) return false;
k = son[k][j];
}
return true;
















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











