










并发编程
因为我自己学过几遍了,同时操作系统学校教的也不错,所以一些理论性的东西就记得很简洁通俗,适合有基础的人看。
不想多写那么多难以理解的东西,尽量用白话去解释。
标签太多了,就不在文章头部放标签了,可以在左侧自行点击目录查看所需。
进程、线程
对比
简单来说,就像一个软件启动就是一个进程,线程就是软件中的不同功能。
-
线程是调度的最小单位,进程则是用于资源分配的最小单位。
-
进程拥有共享资源,如内存空间,线程在进程的内部,所以通过其拥有的内存,即可进行通信。不同的计算机上的进程需要通过协议通信,如http。
异步
简单来说,就是不需要等待返回结果。
就比网络爬虫,你发送一个请求,它需要很久才能返回回来,难道你在等待的时候什么时候都不做就会照成cpu浪费,效率也低。这时候就可以开个新线程处理其他事情。
当然,不是什么适合都开线程合适,线程切换也是有开销的。
同时,单核下,线程切换只是为了让其他进程可以执行,多核下跑的多线程才是我们平时认知,提升效率。
多线程 三种 实现方法
继承 Thread 的方法
- 自定义类继承 Thread 重写run方法
- new子类,然后调用 start() 方法,启动线程
- 对象setName(“线程1”) 可以设置线程名字,在类中可以用getName() 来获取
例:
package com.study;
// 自定义类继承 Thread
public class MyThread extends Thread{
// 重写run方法
@Override
public void run() {
super.run();
for (int i = 0; i < 100; i++) {
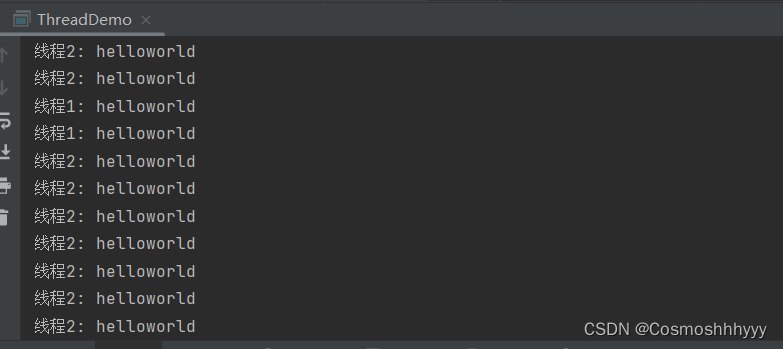
System.out.println(getName() + ": helloworld");
}
}
}
package com.study;
public class ThreadDemo {
public static void main(String[] args) {
// new子类
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
// 设置线程名字
t1.setName("线程1");
t2.setName("线程2");
// 调用 start() 方法,启动线程
t1.start();
t2.start();
}
}
运行截图:
实现 Runnable接口 的方法(推荐使用)
- 定义一个类实现Runnable接口
- 重写run方法
- 创建自己的类对象
- 创建Thread对象,开启线程
注意:也可以setName,但是要记住,这种方法,类中不能直接使用getName方法,因为并没有继承Thread,自然类中没有此方法。但是可以在类中获取当前正在运行线程的对象,来获取name。
例子:
package com.study.threaddemo2;
// 定义一个类实现Runnable接口
public class MyRun implements Runnable{
// 重写run方法
@Override
public void run() {
for (int i = 0; i < 100; i++) {
Thread h = Thread.currentThread(); // 获取当前线程的对象
System.out.println(h.getName() + ":helloworld");
}
}
}
package com.study.threaddemo2;
public class Test2 {
public static void main(String[] args) {
// 创建自己的类对象
MyRun r1 = new MyRun();
MyRun r2 = new MyRun();
// 创建Thread对象
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r2);
// 设置线程名字
t1.setName("线程1");
t2.setName("线程2");
// 开启线程
t1.start();
t2.start();
}
}
运行截图: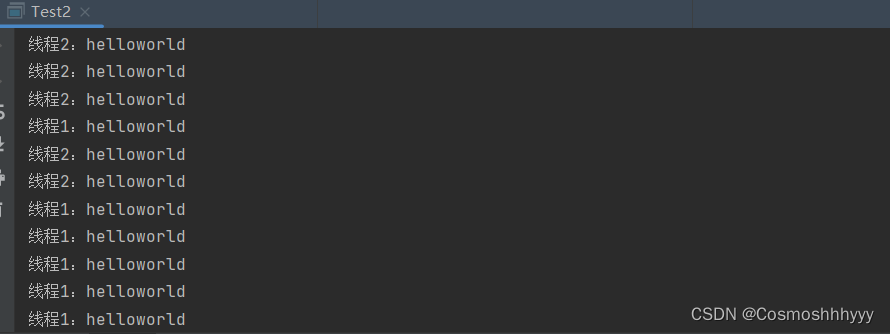
runnable原理
和thread内部一致,如果从传入了able,就会赋值给Thread中的target变量,执行之前会判断,如果不为空,就执行able的run方法。

实现 Callable接口 并利用 FutureTask类 来接收返回值 的方法
- 实现Callable接口
- 重写call方法,有返回值
- 创建自己类的对象
- 创建FutureTask对象(管理多线程运行结果)
- 创建Thread类对象且启动
注意:Callable泛型,填入返回的类型。
例子:
package com.study.threaddemo3;
import java.util.concurrent.Callable;
// 实现Callable接口
public class MyCallable implements Callable<Integer> {
// 重写call方法
public Integer call() {
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += i;
}
return sum;
}
}
package com.study.threaddemo3;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Test3 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建自己类的对象
MyCallable mc = new MyCallable();
// 创建FutureTask对象
FutureTask<Integer> ft = new FutureTask<>(mc);
// 创建Thread类对象且启动
Thread t1 = new Thread(ft);
t1.start();
// 获取返回值
Integer res = ft.get();
System.out.println(res);
}
}
运行结果:

我的理解 和 总结
继承Thread类 的方法,实际就是自己创建了一个流水线,并同时创建了任务,也就是流水线运输和处理的内容。 自然我们可以在流水线中知道此流水线的名字。
实现Runnable接口 的方法,实际是创建了一个任务,我们还需要创建流水线,去运行此任务。 我们不能根据任务就知道运行此任务的流水线名字,因为可能有多个流水线执行此任务,所以我们要先获取正在执行此任务的流水线,这样就能知道正在运行的流水线名了。
实现Callable接口 的方法,此方法就可以用FutureTask这个员工来获得流水线处理任务后的结果(返回值),弥补了上面两种方法的不足。
这样解释是不是很好理解呢?当然这只是通俗的解释一下,方便理解,具体原理肯定还是要看代码的。
可以根据每种方法的优缺点来进行选择使用。

Thread 中的各种方法
- setName() 设置名字 getName() 获取名字
默认是Thread-序号,Thread本身构造方法也可传入名字来设置,可以在继承它的子类构造方法中利用super来调用。 - static Thread currentThread() 静态的,获取当前正在执行的线程的对象
jvm虚拟机启动后,会自动调用多个线程,其中就包含main来执行main方法中的代码。 - static void sleep(long time) 哪条线程执行到此方法,就会停留对应时间,单位毫秒ms
睡眠过后对于线程或被自动唤醒。
1、2两个方法在介绍线程创建时已经展示过,这里展示一下sleep方法的使用。
package com.study.threaddemo4;
public class Test4 {
public static void main(String[] args) throws InterruptedException {
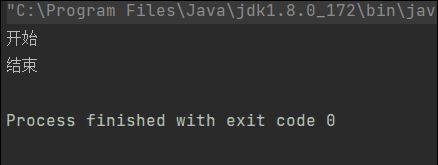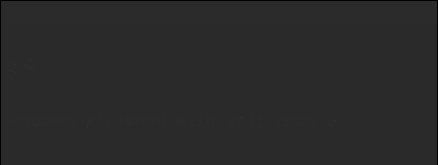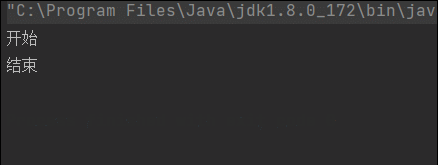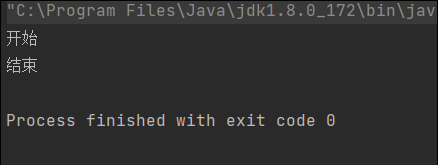
System.out.println("开始");
Thread.sleep(5000);
System.out.println("结束");
}
}
运行结果:
“开始” 打印后,main线程睡眠5s, 然后自动唤醒后,打印"结束"。
内部细节
线程栈之间是相互独立的,堆内的数据是共享的。
lambda 写法
Thread t = new Thread(() -> {
log.debug("running");
}, "tname");
t.start();
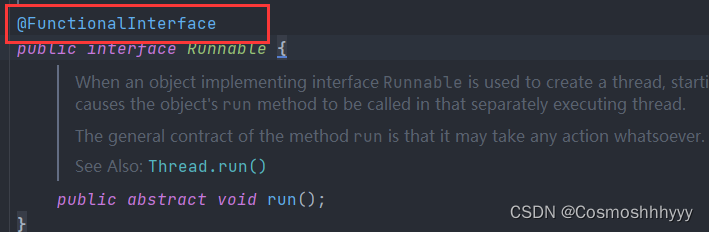
接口上只有一个方法时时,上面会有这个注解,就可以用lamdba。
线程运行
进程的交替运行,我们控制不了,任何一个进程都有可能将运行。
查看和杀死进程
windows:
tasklist 查看进程
taskkill 杀死进程
jps 查看Java进程
linux:
ps -fe 查看所有进程
ps -fe | grep java 查看java进程
ps -fT -p <PID> 查看某个进程(PID)的所有线程
kill 杀死进程
top 动态查看进程信息
top 按大写 H 切换是否显示线程
top -H -p <PID> 查看某个进程(PID)的所有线程信息
java自带的:
jps 查看java进程信息
jstack <PID> 查看该进程的全部线程信息,不过只是那一刻的
jconsole 连接远程进程查看
先上传一个java程序。
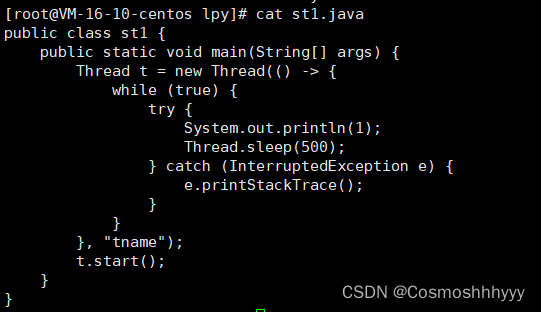
java -Djava.rmi.server.hostname=`ip地址` -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=`连接端口` -Dcom.sun.management.jmxremote.ssl=是否安全连接 -Dcom.sun.management.jmxremote.authenticate=是否认证 java类
赋值这段,然后把地址等换成自己的(去掉引号),设置端口号,是否安全连接或认证自己用false即可。
java -Djava.rmi.server.hostname=172.18.0.1 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=12345 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false st1
打开自己设置的防火墙,把设置的端口号打开。
firewall-cmd --add-port=12345/tcp --permanent
firewall-cmd --reload
systemctl restart firewalld.service
云服务,记得去控制台也开启。
打开jconsole
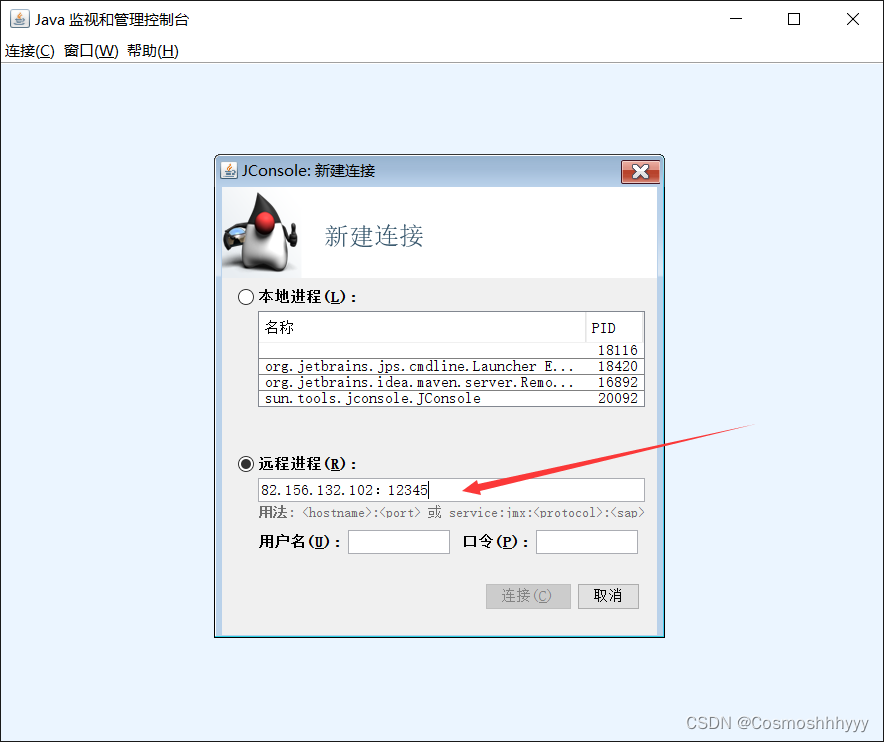
离谱,就是连不上,不知道什么原因,暂时不弄了。
线程运行原理
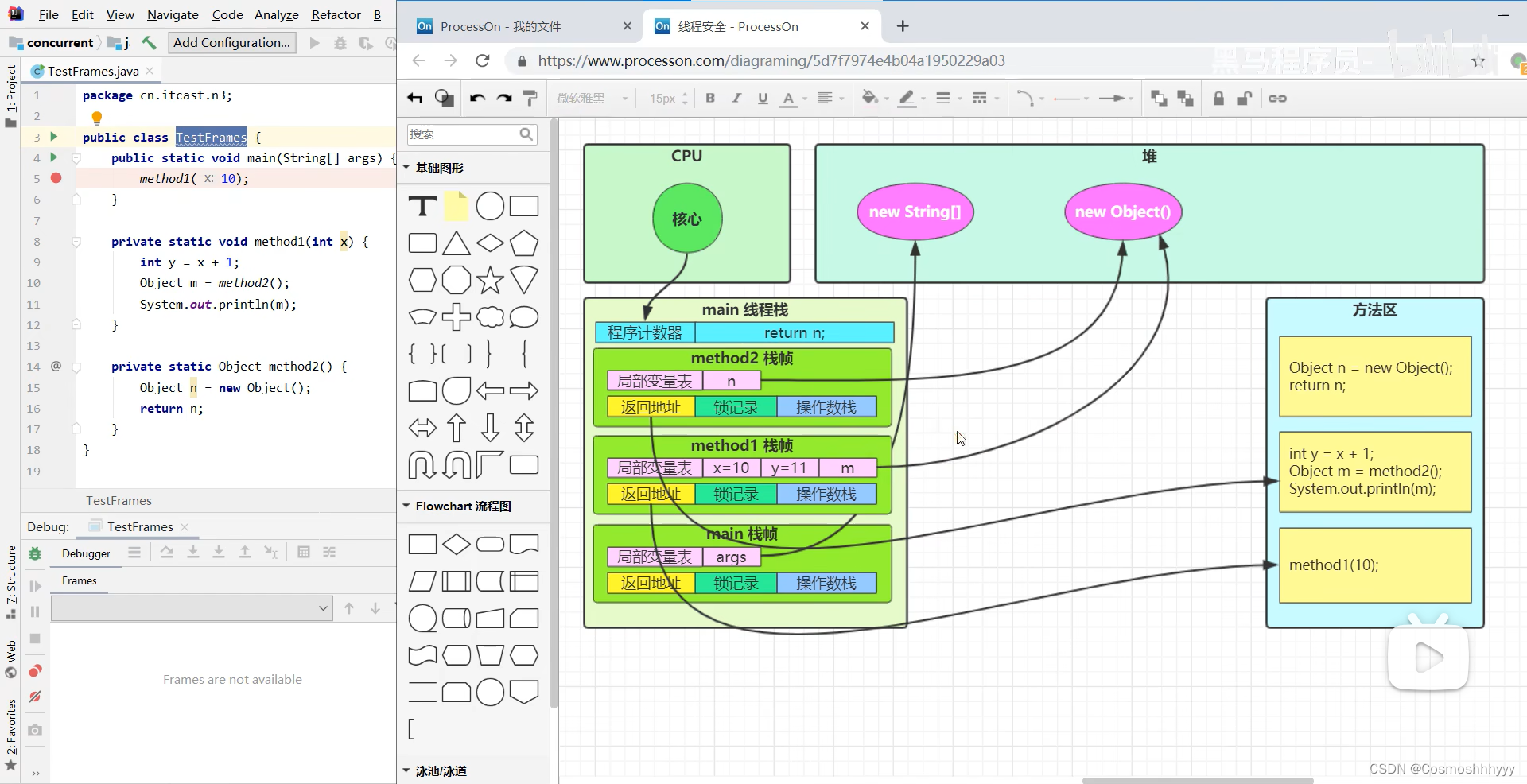
栈帧
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
所以一个栈对应一个线程,随机调用。
内存图
上下文切换
因为以下一些原因导致 cpu 不再执行当前的线程,转而执行另一个线程的:
- 线程的 cpu 时间片用完
- 垃圾回收
- 有更高优先级的线程需要运行
- 线程自己调用了 sleep、yield、wait、join、park、synchronized、lock 等方法
当 Context Switch 发生时,需要由操作系统保存当前线程的状态,并恢复另一个线程的状态,Java 中对应的概念就是程序计数器(Program Counter Register),它的作用是记住下一条 jvm 指令的执行地址,是线程私有的。
- 状态包括程序计数器、虚拟机栈中每个栈帧的信息,如局部变量、操作数栈、返回地址等
- Context Switch 频繁发生会影响性能
sleep 与 yield
sleep
- 调用 sleep 会让当前线程从 Running进入 Timed Waiting 状态(阻塞)
- 其它线程可以使用 interrupt 方法打断正在睡眠的线程,这时 sleep 方法会抛出 InterruptedException
- 睡眠结束后的线程未必会立刻得到执行
- 建议用 TimeUnit 的 sleep 代替 Thread 的 sleep 来获得更好的可读性
yield
- 调用 yield 会让当前线程从 Running 进入 Runnable就绪状态,然后调度执行其它线程
- 具体的实现依赖于操作系统的任务调度器
线程优先级 - 线程优先级会提示(hint)调度器优先调度该线程,但它仅仅是一个提示,调度器可以忽略它
- 如果 cpu 比较忙,那么优先级高的线程会获得更多的时间片,但 cpu 闲时,优先级几乎没作用
线程优先级
- 线程优先级会提示(hint)调度器优先调度该线程,但它仅仅是一个提示,调度器可以忽略它
- 如果 cpu 比较忙,那么优先级高的线程会获得更多的时间片,但 cpu 闲时,优先级几乎没作用
打断标记
睡眠中的线程被打断时,会抛出异常,把打断标记置为false,而不是变为true,wait和join也是。
打断 sleep,wait,join 的线程
这几个方法都会让线程进入阻塞状态
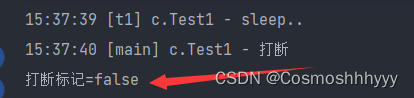
打断 sleep 的线程, 会清空打断状态,以 sleep 为例。
import lombok.extern.slf4j.Slf4j;
@Slf4j(topic = "c.Test1")
public class st2 {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
log.debug("sleep..");
try {
Thread.sleep(1000); // wait join
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1");
t1.start();
Thread.sleep(1000);
log.debug("打断");
t1.interrupt();
System.out.println("打断标记=" + t1.isInterrupted());
}
}
而打断正常线程时,其实并没有打断,只是改变打断标记,线程还会继续运行,需要我们手动利用打断标记的布尔值去判断进行打断。
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
while (true) {
if (Thread.currentThread().isInterrupted()) {
log.debug("打断标记判断为真,退出循环");
break;
}
}
}, "t1");
t1.start();
Thread.sleep(1000);
log.debug("打断");
t1.interrupt();
}
}

两阶段终止
在了解完打断后,我们可以知道,打断正常和阻塞中的线程时,情况是不一样的,想要利用打断标记停止一个线程,要考虑两种情况,正常就不用说了,在睡眠时,被打断后,打断标记重置为false,所以在异常处理中,再打断一次,即可改变打断标记,随后的循环中结束线程。
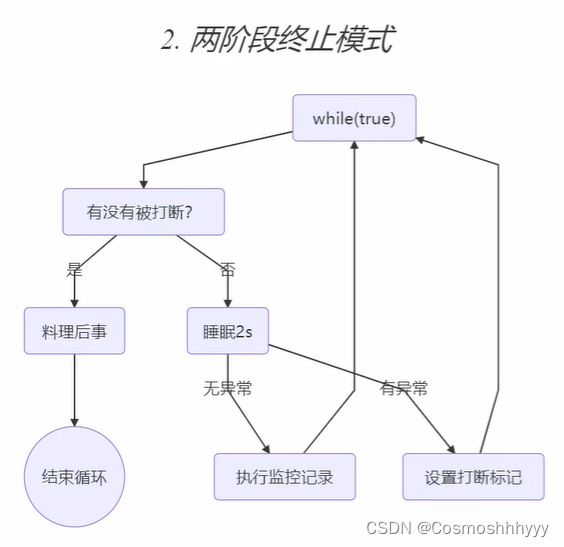
package com.leran;
import lombok.extern.slf4j.Slf4j;
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
TwoInt twoInt = new TwoInt();
twoInt.start();
Thread.sleep(3000);
twoInt.stop();
}
}
@Slf4j(topic = "c.TwoInt")
class TwoInt {
private Thread t1;
public void start() {
t1 = new Thread(() -> {
while (true) {
if (Thread.currentThread().isInterrupted()) {
log.debug("被打断");
break;
}
try {
Thread.sleep(1000);
log.debug("监控");
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt(); // 重新打断一次,在正常运行状态下
}
}
}, "t1");
t1.start();
}
public void stop(){
t1.interrupt();
}
}
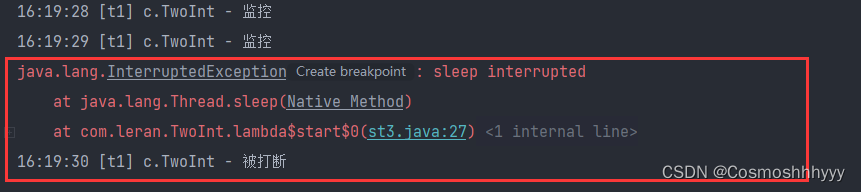
注意
isInterrupted() 判断是否打断不会清空打断标记。
interrupted() 是静态方法,和上面功能一样,但是会清空打断标记。
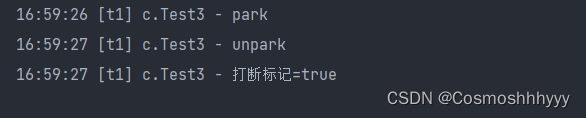
打断park线程
park是LockSupport类中的静态方法,用于暂停当前线程,处于wait状态。
只有打断标记为false的线程才能被park。
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
log.debug("park");
LockSupport.park();
log.debug("unpark");
log.debug("打断标记=" + Thread.currentThread().isInterrupted()); // true;
LockSupport.park(); // true 无法park
log.debug("unpark"); // 直接会运行这个
}, "t1");
t1.start();
Thread.sleep(1000);
t1.interrupt(); // 打断
}
}

看起来和打断正常运行的线程差不多。
第二个park未执行,因为打断标记为true,可以用Thread.interrupted()获取后重置标记。
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
log.debug("park");
LockSupport.park();
log.debug("unpark");
log.debug("打断标记=" + Thread.interrupted()); // true ,然后重置为false
LockSupport.park(); // 可以park
log.debug("unpark"); // 直接会运行这个
}, "t1");
t1.start();
Thread.sleep(1000);
t1.interrupt(); // 打断
}
}
过时方法
stop()
suspend()
resume()
已过时,不建议使用,容易造成线程死锁。
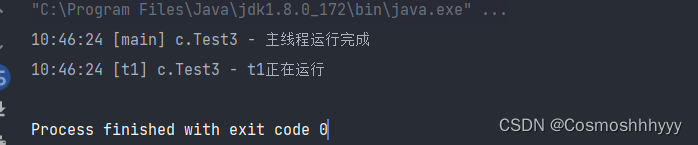
守护线程
Java 进程需要等待所有线程都运行结束,才会结束。
有一种特殊的线程叫做守护线程,只要其它非守护线程运行结束了,即使守护线程的代码没有执行完,也会强制结束。
import java.util.concurrent.locks.LockSupport;
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
while(true) {
log.debug("t1正在运行");
try {
Thread.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t1");
t1.setDaemon(true);
t1.start();
Thread.sleep(1);
log.debug("主线程运行完成");
}
}
在主线程运行完后,t1作为守护线程随之结束。
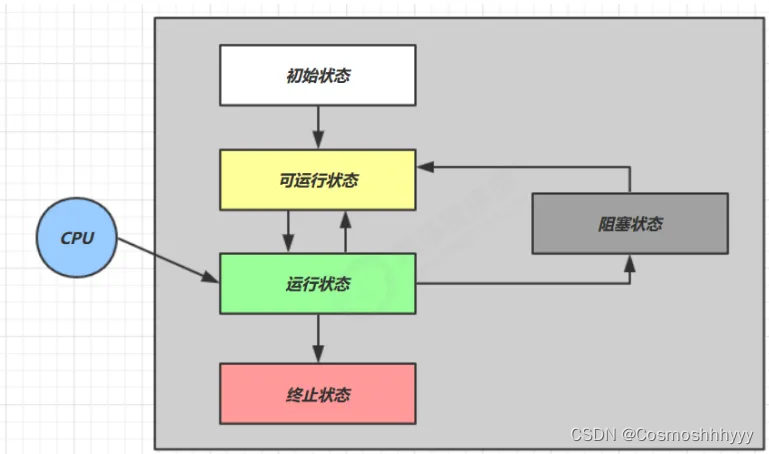
线程状态
- 新建:线程实例创建
- 就绪:调用start方法
- 运行:被CPU选中运行
- 阻塞:线程竞争锁失败进入阻塞
- 等待:使用sleep或者wait方法
- 有限等待:使用sleep方法并设置了时间
- 销毁:线程执行完销毁
多线程的安全问题
学过操作系统应该都知道,分时系统,线程切换造成的安全问题,这里就不再赘述,大家都知道。
java例子:
@Slf4j(topic = "c.Test3")
public class st3 {
static int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 15000; i++) {
count++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 15000; i++) {
count--;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
log.debug(String.valueOf(count));
}
}

正常情况下,一个++,一个–,应该答案为0,但是由于线程切换,造成了读写不一致问题。
synchronized
synchronized俗称对象锁,只有获取了锁的线程才能执行被锁住的代码。
有且只有一个线程能获取对象锁。既可以让线程之间互斥访问被锁住的对象。
即使线程切换,没有锁也运行不了临界区中的代码,这样就可以保证读写的原子性,那么就一定正确。
代码示例
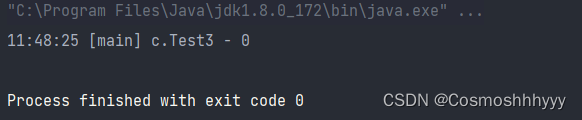
@Slf4j(topic = "c.Test3")
public class st3 {
static int count = 0;
static Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
synchronized (lock) {
count++;
}
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
synchronized (lock){
count--;
}
}
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("{}",count);
}
}
面向对象改进:
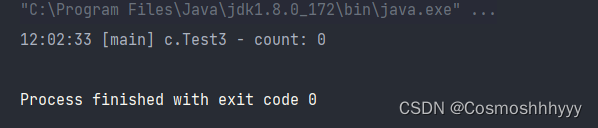
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
Lock lock = new Lock();
Thread t1 = new Thread(() -> {
for (int j = 0; j < 5000; j++) {
lock.incr();
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int j = 0; j < 5000; j++) {
lock.decr();
}
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("count: {}" , lock.getCount());
}
}
class Lock{
private int count = 0;
public void incr() {
synchronized(this) {
count++;
}
}
public void decr() {
synchronized (this) {
count--;
}
}
public int getCount() {
return count;
}
}
一样的只不过,在类方法里调用,锁的是当前对象this。
方法上加synchronized
加在普通方法上是对象锁,加载静态方法上是类锁。
而不加锁的方法不受任何影响。
class Test{
public synchronized void test() {
}
}
等价于
class Test{
public void test() {
synchronized(this) {
}
}
}
class Test{
public synchronized static void test() {
}
}
等价于
class Test{
public static void test() {
synchronized(Test.class) {
}
}
}
注意:不要有误区,不要认为类锁被锁后其类对应的所有对象锁也不能再执行,类锁锁住的是类对象,也是一个对象而已,也就是Class c = xx.getClass()这个对象。
所以我认为没必要区分什么锁类锁对象啥的,都是锁一个对象。只不过一个锁的该类的对象,一个锁的该类的Class对象。不过我们通常将锁一个类叫做类锁而已。
线程八锁
"线程八锁"通常是指Java中关于多线程同步的八种情况,这些情况是基于对象锁的不同组合而产生的。这些情况包括对实例方法和静态方法的访问,以及对普通对象和Class对象的访问。
对于非静态同步方法,锁的是当前实例对象。
对于静态同步方法,锁的是当前类的Class对象。
对于同步方法块,锁的是括号里配置的对象。
下面我们就来全面解析吧。
No.1
class Number{
public synchronized void a() {
log.debug("1");
}
public synchronized void b() {
log.debug("2");
}
}
public static void main(String[] args) {
Number n1 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n1.b(); }).start();
}
a、b锁对象,互斥,执行顺序随机。
答案:
1、2 或
2、1
No.2
class Number{
public synchronized void a() {
sleep(1);
log.debug("1");
}
public synchronized void b() {
log.debug("2");
}
}
public static void main(String[] args) {
Number n1 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n1.b(); }).start();
}
a、b锁对象、互斥,执行顺序随机。
答案:1s、1、2 或
2、1s、1
No.3
class Number{
public synchronized void a() {
sleep(1);
log.debug("1");
}
public synchronized void b() {
log.debug("2");
}
public void c() {
log.debug("3");
}
}
public static void main(String[] args) {
Number n1 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n1.b(); }).start();
new Thread(()->{ n1.c(); }).start();
}
a、b锁对象,c普通方法,同一对象的a、b互斥、普通方法不受影响,随时可以执行。
答案:3、2、1s、1 或
3、1s、1、2 或
2、3、1s、1
No.4
class Number{
public synchronized void a() {
sleep(1);
log.debug("1");
}
public synchronized void b() {
log.debug("2");
}
}
public static void main(String[] args) {
Number n1 = new Number();
Number n2 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n2.b(); }).start();
}
a、b锁对象,但是调用对象不同,互不影响。
答案:
2、1s、1
No.5
class Number{
public static synchronized void a() {
sleep(1);
log.debug("1");
}
public synchronized void b() {
log.debug("2");
}
}
public static void main(String[] args) {
Number n1 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n1.b(); }).start();
}
a锁对象、b锁类(Class对象),互不影响。
答案:
2、1s、1
No.6
class Number{
public static synchronized void a() {
sleep(1);
log.debug("1");
}
public static synchronized void b() {
log.debug("2");
}
}
public static void main(String[] args) {
Number n1 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n1.b(); }).start();
}
a、b锁类,互斥,执行顺序随机。
答案:
1s、1、2 或
2、1s、1
No.7
class Number{
public static synchronized void a() {
sleep(1);
log.debug("1");
}
public synchronized void b() {
log.debug("2");
}
}
public static void main(String[] args) {
Number n1 = new Number();
Number n2 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n2.b(); }).start();
}
a锁类、b锁对象,但是调用对象和方法都不同,互不影响。
答案:
2、1s、1
No.8
class Number{
public static synchronized void a() {
sleep(1);
log.debug("1");
}
public static synchronized void b() {
log.debug("2");
}
}
public static void main(String[] args) {
Number n1 = new Number();
Number n2 = new Number();
new Thread(()->{ n1.a(); }).start();
new Thread(()->{ n2.b(); }).start();
}
a、b都是锁类、虽然是不同对象调用,但是他俩锁的类,互斥,执行顺序随机。
答案:
1s、1、2
2、1s、1
线程安全问题
分析
局部变量是安全的,成员变量并不安全。
切记,方法是拷贝执行的,方法内部的局部的变量并不共享,所以是安全的,但如果方法调用成员变量,成员变量在堆中,操作的是同一个,这就会有安全问题。
也就是说,一个变量只被一个线程调用,是安全的。
list不安全的(成员):
class ThreadUnsafe {
ArrayList<String> list = new ArrayList<>();
public void method1(int loopNumber) {
for (int i = 0; i < loopNumber; i++) {
// { 临界区, 会产生竞态条件
method2();
method3();
// } 临界区
}
}
private void method2() {
list.add("1");
}
private void method3() {
list.remove(0);
}
}
list安全的(局部):
class ThreadSafe {
public final void method1(int loopNumber) {
ArrayList<String> list = new ArrayList<>();
for (int i = 0; i < loopNumber; i++) {
method2(list);
method3(list);
}
}
private void method2(ArrayList<String> list) {
list.add("1");
}
private void method3(ArrayList<String> list) {
list.remove(0);
}
}
不过不是绝对的,如果子类继承并重写的方法3,那么局部变量被暴露给了其他线程,就会出现安全问题。
所以private和final的作用的体现出来了。
class ThreadSafe {
public final void method1(int loopNumber) {
ArrayList<String> list = new ArrayList<>();
for (int i = 0; i < loopNumber; i++) {
method2(list);
method3(list);
}
}
private void method2(ArrayList<String> list) {
list.add("1");
}
private void method3(ArrayList<String> list) {
list.remove(0);
}
}
class ThreadSafeSubClass extends ThreadSafe{
@Override
public void method3(ArrayList<String> list) {
new Thread(() -> {
list.remove(0);
}).start();
}
}
常见的线程安全类
- String
- Integer
- StringBufffer
- Random
- Vector
- Hashtable
多个线程调用同一实例下,这些类是安全的,因为其方法都是原子性的。
不过多个方法组合并不安全。
线程安全类方法组合
并不安全
例如:
Hashtable table = new Hashtable();
// 线程1,线程2
if( table.get("key") == null) {
table.put("key", value);
}
很明显,两个线程如果都读取完null切换线程,那么就会put。
不可变类型
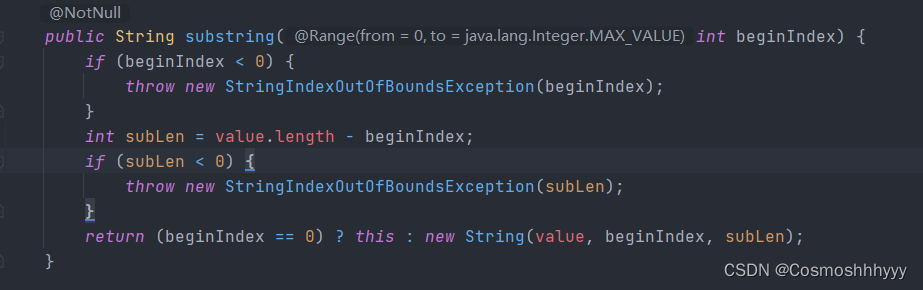
像String,Integer是不可变的,肯定是安全的。
他内部方法源码都是创建一个新对象返回,所以看起来像我们修改了一样。
例如这个subString方法,如果不是截取全部,返回一个新对象。
所以那么加final的类一定安全么?
显然是不一定的,final对应引用类型只是保证其指向不变,但其内部的属性还是可以改变的,所以不安全。
Monitor
java对象头
普通对象
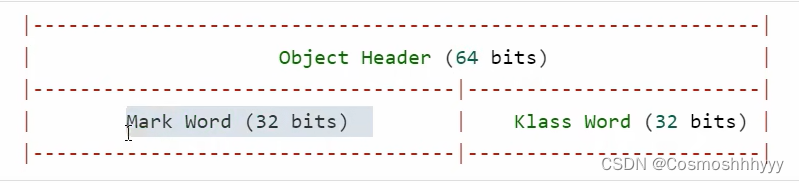
Mark Word 主要用来存储对象自身的运行时数据、klass word就是指向该对象的类型。
数组对象

mark word
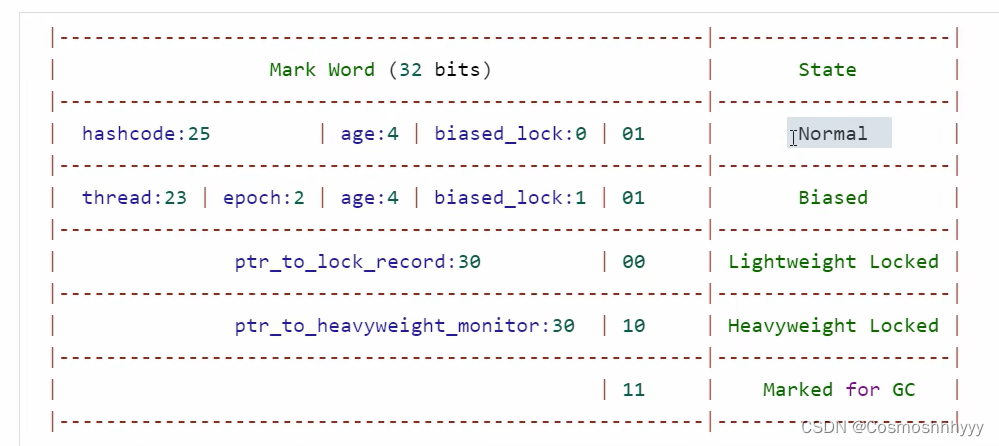
不同对象状态下结构和含义不同。
Monitor(锁、管程)
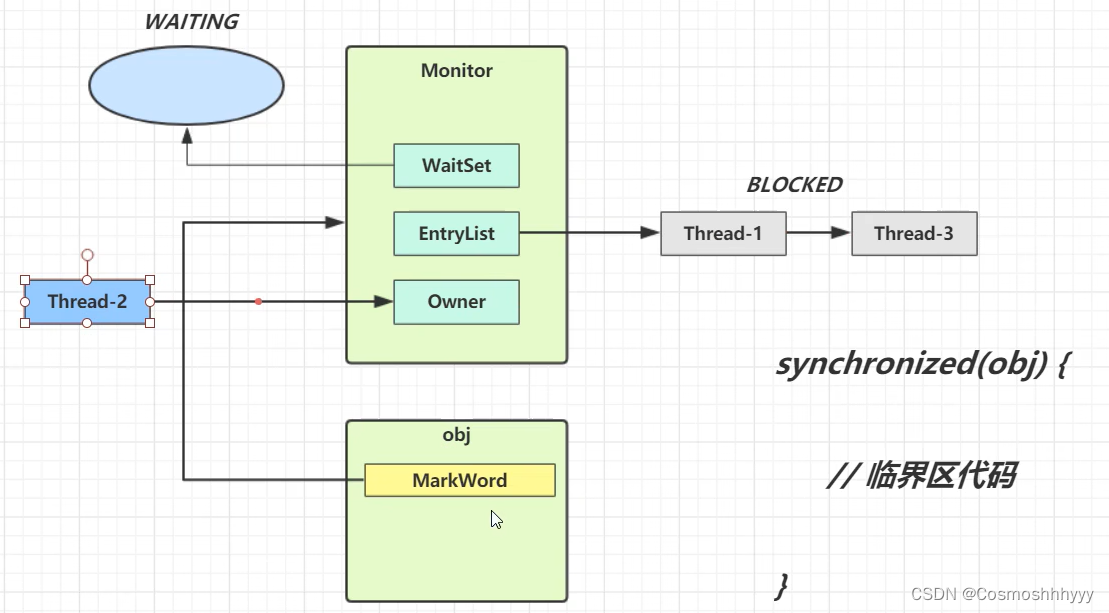
-
当synchronized锁一个对象(重量级锁)时会关联一个操作系统的Monitor对象,对象头中markword中ptr_to_heavyweight_montior就会指向对应monitor对象。
-
同时将Monitor中的owner给对应线程,表示该锁现在对应线程拥有。
-
如果现在有其他线程尝试加锁,会发现对象指向的Monitor中的owner并不是该线程,就会让该线程进入等待队列,线程阻塞。
-
如果该锁被释放,那么等待队列中的线程将被唤醒重写争取锁。
锁的类型
重量级锁、轻量级锁、偏向锁。
加锁过程:偏向->轻量级->重量级
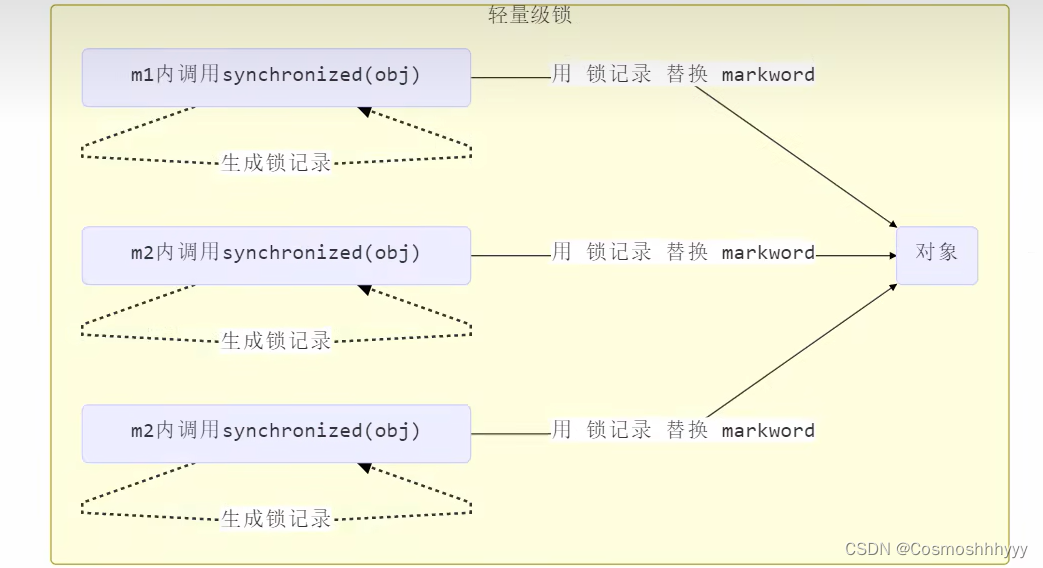
轻量级锁
轻量级锁的使用场景:如果一个对象虽然有多线程要加锁,但加锁的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化。
轻量级锁对使用者是透明的,即语法仍然是 synchronized,锁的升级什么的不用我们考虑。
static final Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// 同步块 A
method2();
}
}
public static void method2() {
synchronized( obj ) {
// 同步块 B
}
}
每一个线程的栈帧中都会包含一个锁记录结构,记录对象头中的markword。
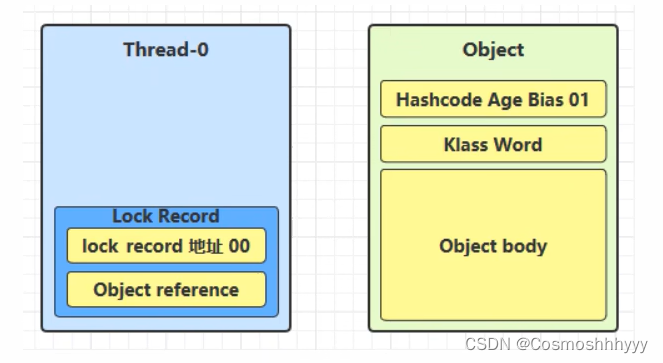
锁记录中Object reference指向锁对象,并尝试用 cas 交换 Object 的 Mark Word,将Mark Word的值存入锁记录中。
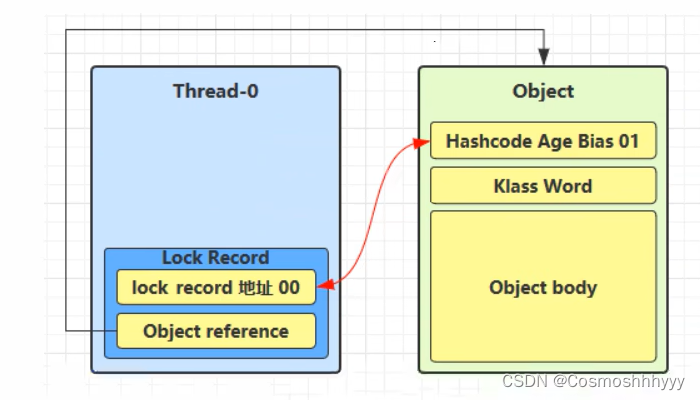
若cas成功,对象头中存储锁地址和锁状态00(轻量级),表示该线程给此对象加锁。
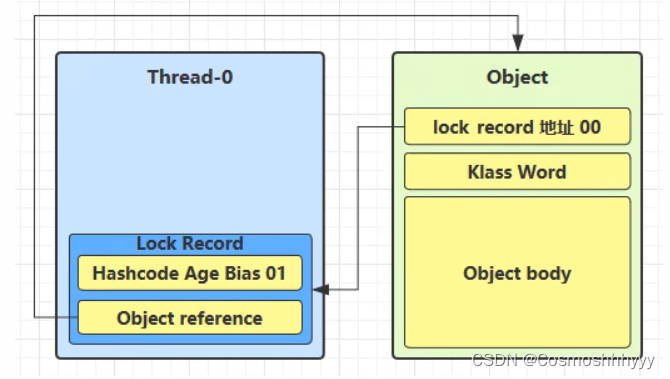
如果 cas 失败,有两种情况:
- 如果是其它线程已经持有了该 Object 的轻量级锁,这时表明有竞争,进入锁膨胀过程。
- 如果是自己执行了 synchronized 锁重入,那么再添加一条 Lock Record 作为重入的计数。
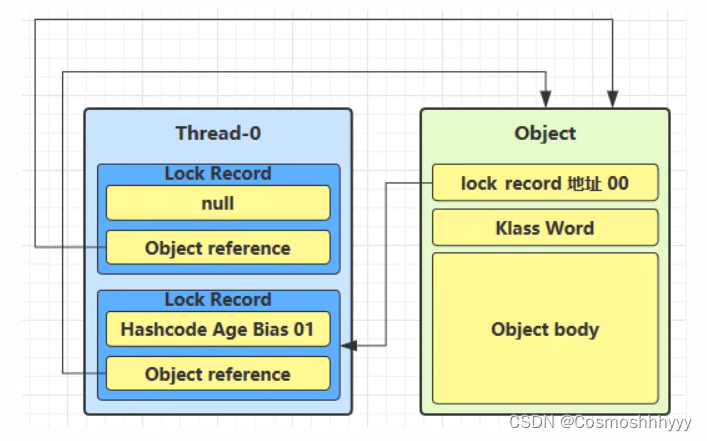
当退出 synchronized 代码块(解锁时)如果有取值为 null 的锁记录,表示有重入,这时重置锁记录,表示重入计数减一。

当退出 synchronized 代码块(解锁时)锁记录的值不为 null,这时使用 cas 将 Mark Word 的值恢复给对象头
- 成功,则解锁成功。
- 失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程。
重量级锁
如果在尝试加轻量级锁的过程中,CAS操作无法成功,这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争),这时会进行锁膨胀,将轻量级锁膨胀为重量级锁。
static Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// 同步块
}
}
当 Thread-1 进行轻量级加锁时,Thread-0 已经对该对象加了轻量级锁。
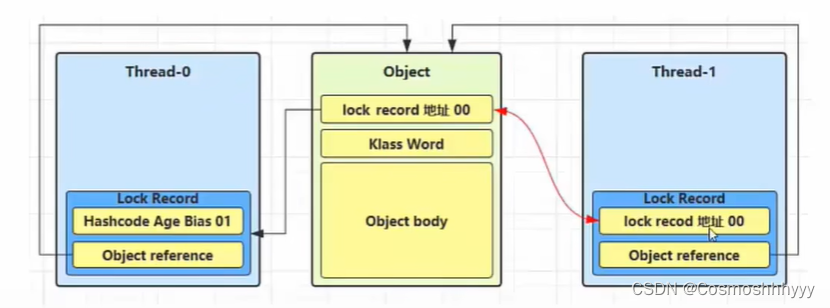
这时Thread-1就会CAS失败,进入锁膨胀过程。
- Object 对象申请 Monitor 锁,让 Object 指向重量级锁地址
- 然后自己进入 Monitor 的 EntryList BLOCKED
- Object 对象头锁标记变为10(重量级)
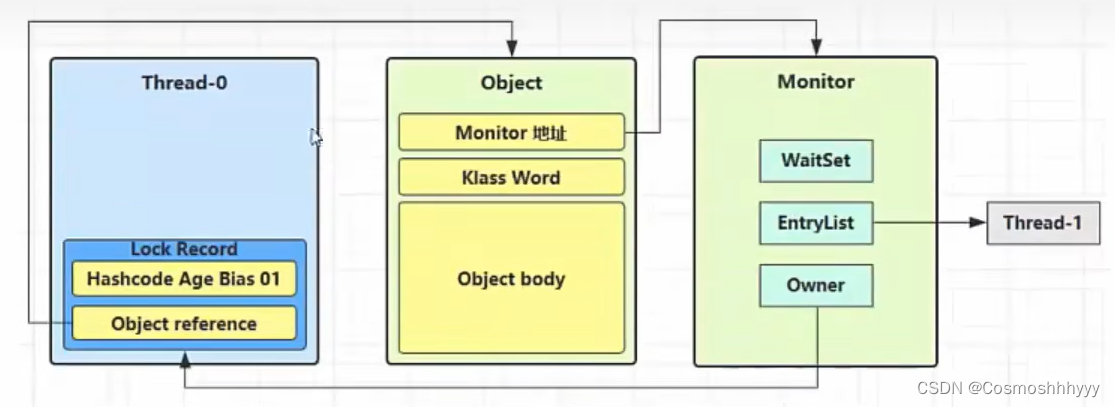
当 Thread-0 退出同步块解锁时,使用 CAS 将 Mark Word 的值恢复给对象头,失败。这时会进入重量级解锁流程,即按照 Monitor 地址找到 Monitor 对象,设置 Owner 为 null,唤醒 EntryList 中 BLOCKED 线程。
简单来说,我们可以简化一下:
- 就是没竞争时,自己正常加锁运行解锁即可,同一线程有锁的重入,防止没必要的加锁解锁过程。
- 如果有竞争时,新线程进入阻塞队列等待,当解锁时,唤醒阻塞队列中的线程。
自旋优化
重量级锁竞争的时候,可以使用自旋(不断的循环尝试获取重量级锁)来进行优化,如果当前线程自旋成功(当前持有锁的线程释放了锁),这时当前线程就可以避免阻塞。(阻塞再恢复,会进行上下文切换,耗费性能)
但是自旋也是会消耗性能的,尤其是进程非常多的时候,一堆进程在不断循环等待锁被释放,优点就是及时,一释放锁就能感应到。
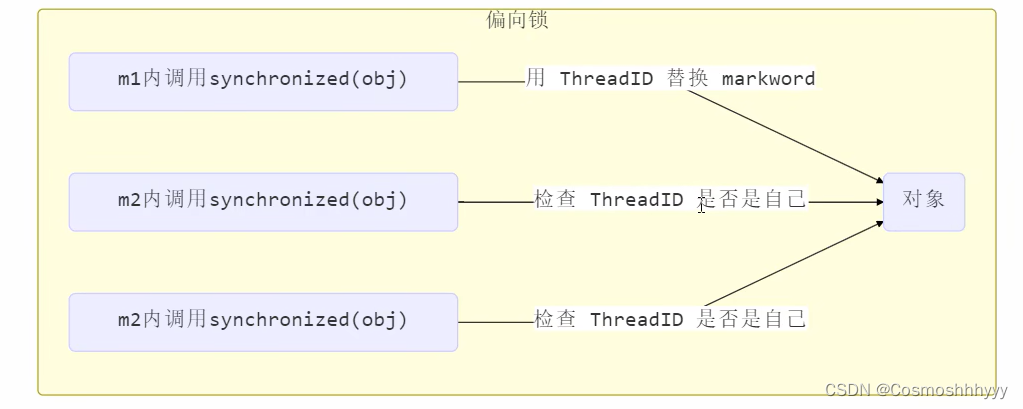
偏向锁
在锁重入时,会产生锁记录,每次都需要尝试CAS,虽然会失败,但是CAS这个操作是没必要的。
优化:
将对象头中记录持有该锁的线程id,如果发生锁的重入,检测对象头,若是自己的,那么就不用再CAS了。
对比:
偏向锁的细节

一个对象创建时:
-
如果开启了偏向锁(默认开启),那么对象创建后,markword 值为 0x05 即最后 3 位为 101,这时它的 thread、epoch、age 都为 0。
-
偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加 VM 参数 -XX:BiasedLockingStartupDelay=0 来禁用延迟。
-
如果没有开启偏向锁,那么对象创建后,markword 值为 0x01 即最后 3 位为 001,这时它的 hashcode、age 都为 0,第一次用到 hashcode 时才会赋值。
-
正常状态对象一开始是没有 hashCode 的,第一次调用才生成。
-
调用了 hashCode() 后会撤销该对象的偏向锁。
从图中也可以看出,偏向锁的markword没有位置可以放hashcode了,除非转变为轻量级锁,所以调用对象的hashCode会撤销他的偏向锁。
偏向锁的撤销
除了上面说的调用hashCode,也可用 让其他线程使用偏向锁,这时偏向锁会升级为普通锁。
不过两个线程需要错开加锁,不然会升级为重量级锁。
批量重偏向
可用发现,就算错开没用竞争,那么锁也会从偏向锁转变为普通锁,那其实锁的转变也是消耗性能的,所以就有了偏向锁的重偏向这个功能。
如果对象被多个线程访问,但没有竞争(错开),这时偏向了线程 T1 的对象仍有机会重新偏向 T2,重偏向会重置对象的 Thread ID 为 T2线程。
当某对象(这一类的不同对象)撤销偏向锁阈值超过20次后,jvm会觉得,我是不是偏向错了,于是会在给这些对象加锁的时候重新偏向至新加锁线程。
批量撤销
当相同类型不同对象撤销偏向锁阈值超过 40 次后,jvm 会这样觉得,自己确实偏向错了,根本就不该偏向,这个锁竞争太激烈了。于是整个类的所有对象都会变为不可偏向的,新建的该类型对象也是不可偏向的(轻量级)。
锁消除
简单来说,当jvm调用某方法达到一定阈值,就会用记时编译器优化,发现锁加和不加没有影响时,就会去除掉锁。
public class MyBenchmark {
static int x = 0;
public void a() throws Exception {
x++;
}
public void b() throws Exception {
Object o = new Object();
synchronized (o) {
x++;
}
}
}
比如Object为局部变量,根本不会逃离此方法作用范围,不能被共享,那加不加锁没啥意义,jvm就会去除掉锁去运行,从而优化性能。
wait/notify
这块比较简单,就不在把所有例子都写上了。

要注意区分waitSet和EntryList中的线程,一个获得了锁但是wait释放了锁进入等待notify唤醒状态,一个是正在等待获得锁。
不过相同点就是他们都处于阻塞状态,一个是等待阻塞,一个是同步阻塞。 不占用时间片。
- BLOCKED 线程会在 Owner 线程释放锁时唤醒
- WAITING 线程会在 Owner 线程调用 notify 或 notifyAll 时唤醒,但唤醒后并不意味者立刻获得锁,仍需进入EntryList 重新竞争
所以只有获取了锁的线程才能wait,如果我们不手动notify,将永远沉睡下去。
api
- obj.wait() 让进入 object 监视器的线程到 waitSet 等待
- obj.notify() 在 object 上正在 waitSet 等待的线程中挑一个唤醒
- obj.notifyAll() 让 object 上正在 waitSet 等待的线程全部唤醒
wait可用传入参数,表示等待时间ms,如果到了时间没有被唤醒,那么主动唤醒自己。
它们都是线程之间进行协作的手段,都属于 Object 对象的方法。必须获得此对象的锁,才能调用这几个方法。
wait vs sleep
sleep(long n) 和 wait(long n) 的区别
- sleep 是 Thread 方法,而 wait 是 Object 的方法
- sleep 不需要强制和 synchronized 配合使用,但 wait 需要和 synchronized 一起用
- sleep 在睡眠的同时,不会释放对象锁的,但 wait 在等待的时候会释放对象锁
- 它们状态 TIMED_WAITING
手写消息队列
操作系统的生产者-消费者模式而已。
生产者:不断判断队列中是否有空余位置,若没有进入等待,若有放入一个产品到队列,然后唤醒消费者消费。
消费者:不断判断队列中是否有产品,若没有进入等待,若有则拿走一个产品,然后唤醒生产者生产品。
package com.消息队列;
import java.util.LinkedList;
public class Test {
}
class MessageQueue {
private final int capacity; // 最大容量
private final LinkedList<Message> dq = new LinkedList<>(); // 存放消息的队列
public MessageQueue(int capacity) {
this.capacity = capacity;
}
/**
* 队列中取出产品
* @return
*/
public Message take(){
synchronized (dq) {
while (dq.isEmpty()) {
try {
dq.wait(); // 若为空,一直等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Message first = dq.getFirst(); // 获取产品
dq.notifyAll(); // 唤醒等待dq锁的线程
return first;
}
}
/**
* 队列中放入产品
* @param message
*/
public void put(Message message){
synchronized (dq) {
while (dq.size() >= capacity) {
try {
dq.wait(); // 若无容量了,该线程进入等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
dq.addLast(message); // 放入产品
dq.notifyAll(); // 唤醒等待dq锁的线程
}
}
}
final class Message {
private final int id; // id
private final Object object; // 任务
public Message(int id, Object object) {
this.id = id;
this.object = object;
}
public int getId() {
return id;
}
public Object getObject() {
return object;
}
@Override
public String toString() {
return "Message{" +
"id=" + id +
", object=" + object +
'}';
}
}
sync已经保证了对于队列操作的互斥,所以其实不wait也可以,一直循环等到线程切换皆可,但是太浪费cpu了。
生产者和消费者都是等待的dq的锁,所以notifyAll的时候,唤醒所有线程,被选中执行的不一定是哪一个,不过如果while条件不符,还是会再wait罢了。
park / unpark
用法
// 暂停当前线程
LockSupport.park();
// 恢复某个线程的运行
LockSupport.unpark(暂停线程对象)
**先说结论:**无论unpark在park前还是后,都可以解除暂停状态。
先park在unpark可以成功运行:
Thread t1 = new Thread(() -> {
log.debug("start...");
sleep(1);
log.debug("park...");
LockSupport.park();
log.debug("resume...");
},"t1");
t1.start();
sleep(2);
log.debug("unpark...");
LockSupport.unpark(t1);

先unpark再park也可以成功运行:
Thread t1 = new Thread(() -> {
log.debug("start...");
try {
sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("park...");
LockSupport.park();
log.debug("resume...");
},"t1");
t1.start();
sleep(1);
log.debug("unpark...");
LockSupport.unpark(t1);
与wait/notify区别
特点 与 Object 的 wait & notify 相比
- wait,notify 和 notifyAll 必须配合 Object Monitor 一起使用(也就是先获取对象的锁),而 park,unpark 不必。
- park & unpark 是以线程为单位来【阻塞】和【唤醒(指定)】线程,而 notify 只能随机唤醒一个等待线程,notifyAll是唤醒所有等待线程,就不那么【精确】。
- park & unpark 可以先 unpark,而 wait & notify 不能先 notify。
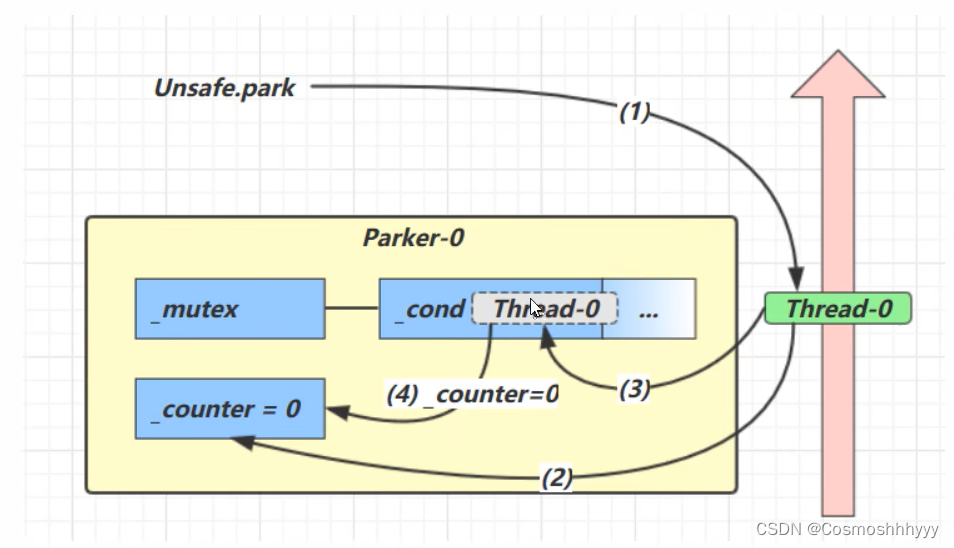
如果先unpark,在park之前,counter会先+1,把unpark存储,等park的时候再使用。当然只能存储一次。
线程活跃性
死锁
两个线程相互等待对方已拥有的锁,就会相互一直等待,不会停止。
t1拥有a锁,等待b锁。
t2拥有b锁,等待a锁。
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
Object A = new Object();
Object B = new Object();
Thread t1 = new Thread(() -> {
synchronized (A) {
log.debug("lock A");
try {
sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (B) {
log.debug("lock B");
log.debug("操作...");
}
}
}, "t1");
Thread t2 = new Thread(() -> {
synchronized (B) {
log.debug("lock B");
try {
sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (A) {
log.debug("lock A");
log.debug("操作...");
}
}
}, "t2");
t1.start();
t2.start();
}
}
活锁
相互改变对方的结束条件,两个线程永远无法结束。
count初始为10,
t1希望count减到0结束。
t2希望count加到20结束。
两个一起同速度执行,一定不能结束。
public class Test3{
static volatile int count = 10;
static final Object lock = new Object();
public static void main(String[] args) {
new Thread(() -> {
// 期望减到 0 退出循环
while (count > 0) {
sleep(0.2);
count--;
log.debug("count: {}", count);
}
}, "t1").start();
new Thread(() -> {
// 期望超过 20 退出循环
while (count < 20) {
sleep(0.2);
count++;
log.debug("count: {}", count);
}
}, "t2").start();
}
}
可以设置两个线程随机的睡眠时间解决。
解饿
线程一直无法获得cpu的调度,我么就称为线程饥饿。
可能原因为线程优先级太低。
ReentrantLock
翻译:可重入锁
特点
- 可中断
- 可设置超时时间(不会一直等待锁)
- 可设置为公平锁(防止线程饥饿)
- 支持多个条件变量
- 与 synchronized 一样可重入
基本语法
// 获取锁
reentrantLock.lock();
try {
// 临界区
} finally {
// 释放锁
reentrantLock.unlock();
}
可重入
同一个线程如果已经拥有了锁,可以再次获得这把锁。
@Slf4j(topic = "c.Test3")
public class st3 {
private static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
lock.lock(); // 加锁
try {
log.debug("enter m1");
m1();
}finally {
lock.unlock(); // 解锁
}
}
public static void m1 () {
lock.lock();
try {
log.debug("enter m2");
m2();
} finally {
lock.unlock();
}
}
public static void m2 () {
lock.lock();
try {
log.debug("m2获取了锁");
} finally {
lock.unlock();
}
}
}

可打断(避免死等、被动)
lockInterruptibly 可打断锁,在尝试获取锁进入阻塞队列中,被打断时,可以停止等待锁。
public static void main(String[] args) throws InterruptedException {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
try {
log.debug("t1线程尝试获取锁");
lock.lockInterruptibly(); // 尝试获取锁。若有竞争,进入阻塞队列,可被打断
} catch (InterruptedException e) {
e.printStackTrace();
log.debug("等待锁的时候被打断了,停止等待,返回");
return;
}
try {
log.debug("获得了锁");
} finally {
lock.unlock();
}
}, "t1");
lock.lock();
log.debug("主线程获得了锁");
t1.start();
sleep(1);
log.debug("打断 t1");
t1.interrupt();
lock.unlock();
}
锁超时(避免死等、主动)
无参数:获取锁,若没获取到,立即失败,返回false。
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
log.debug("启动...");
if (!lock.tryLock()) {
log.debug("t1获取锁立刻失败,返回");
return;
}
try {
log.debug("t1获得到了锁");
} finally {
lock.unlock();
}
}, "t1");
lock.lock();
log.debug("主线程获得了锁");
t1.start();
sleep(2);
lock.unlock();
}
}

可以主动设置等待时间。
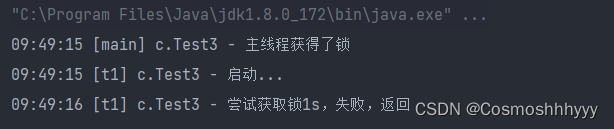
@Slf4j(topic = "c.Test3")
public class st3 {
public static void main(String[] args) throws InterruptedException {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
log.debug("启动...");
try {
if (!lock.tryLock(1, TimeUnit.SECONDS)) {
log.debug("尝试获取锁1s,失败,返回");
return;
}
} catch (InterruptedException e) { // 被打断,应该也return
e.printStackTrace();
}
try {
log.debug("t1获得了锁");
} finally {
lock.unlock();
}
}, "t1");
lock.lock();
log.debug("主线程获得了锁");
t1.start();
sleep(1);
lock.unlock();
}
}
主线程1ms后释放了锁,t1线程还在1s的等待中,可以获得锁,若时等待超过1s那就不再尝试获取锁了。

若主线程沉睡1s的情况:
sleep(1000);
公平锁
ReentrantLock默认也是不公平锁,但是可以修改。
公平: 先来先执行
不公平: 随机有机会
这里就给出如何修改
ReentrantLock lock = new ReentrantLock(true); // 公平
ReentrantLock lock = new ReentrantLock(false); // 不公平
一般是不设置的,会降低并发度,所以就不给出例子了。
多个条件变量
- ReentrantLock 的条件变量比 synchronized 强大之处在于,它是支持多个条件变量的。
- synchronized只能全部都唤醒,而ReentrantLock可以根据条件唤醒对应线程。
Condition waitCigaretteQueue = lock.newCondition(); // 条件
waitCigaretteQueue.await(); // 因为此原因进入等待
signal 唤醒 对应等待的线程
比如,在操作系统里,有一个很经典的问题,爸爸向盘子里放苹果,妈妈向盘子里放香蕉,儿子只吃苹果,女儿只吃香蕉,盘子可以放多个水果,但每种最多一个。
如果我么只用sync锁,那么就只能有一个条件,如果只有爸爸向盘子里放了苹果,那么他会唤醒儿子和女儿,但其实只唤醒儿子即可。
所以利用ReentrantLock多条件,因为沉睡的条件不同,我么就可以对应的唤醒我们想要的一些线程。
这里例子是用的烟和早餐,一样的。
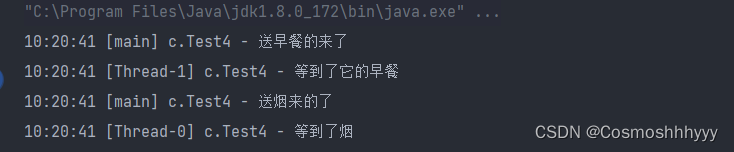
@Slf4j(topic = "c.Test4")
public class st4 {
static ReentrantLock lock = new ReentrantLock();
static Condition waitCigaretteQueue = lock.newCondition(); //因为等烟等烟,进入等待的阻塞线程队列
static Condition waitTokeoutQueue = lock.newCondition(); //因为等早餐进入阻塞队列
static boolean hasCigarette = false;
static boolean hasTokeout = false;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
lock.lock();
try {
while (!hasCigarette) {
try {
waitCigaretteQueue.await(); // 因为等烟,进入等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("等到了烟");
} finally {
lock.unlock(); // 解锁
}
}).start();
new Thread(() -> {
try {
lock.lock();
while (!hasTokeout) {
try {
waitTokeoutQueue.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("等到了它的早餐");
} finally {
lock.unlock();
}
}).start();
sleep(1);
sendBreakfast();
sleep(1);
sendCigarette();
}
private static void sendCigarette() {
lock.lock();
try {
log.debug("送烟来的了");
hasCigarette = true;
waitCigaretteQueue.signal();
} finally {
lock.unlock();
}
}
private static void sendBreakfast() {
lock.lock();
try {
log.debug("送早餐的来了");
hasTokeout = true;
waitTokeoutQueue.signal();
} finally {
lock.unlock();
}
}
}
java内存模型
JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、CPU 指令优化等。
JMM 体现在以下几个方面 :
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 cpu 缓存的影响
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响
可见性
按照如下代码,一般我们都会想,run改成false,那么线程t1也就运行结束了,但是并没有运行结束,而是无线运行下去了。
这就算因为可见性导致的。
@Slf4j(topic = "c.Test5")
public class st5 {
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
}
});
t.start();
sleep(1);
run = false; // 线程t不会如预想的停下来
}
}
在一开始t1线程是在主内存中获取 run 值。
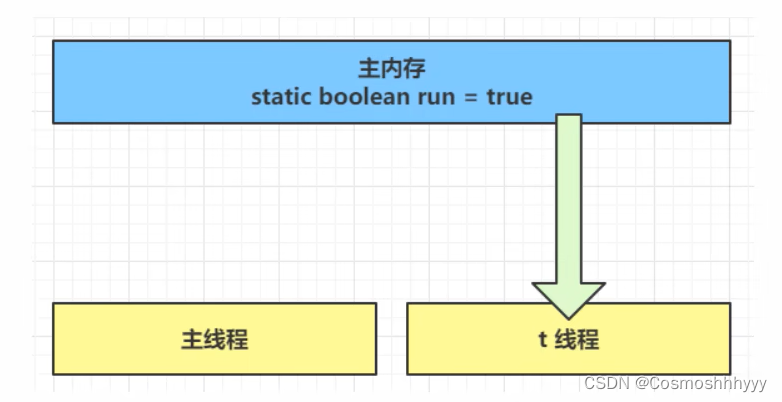
随着 while 次数一直获取次数增多,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率。

但是,会带来一个问题,就是主存和内存中的值不一致,当主存内容修改,t1 线程任然从内存中获取run值,就会读到旧的内容,从而一直停不下来。
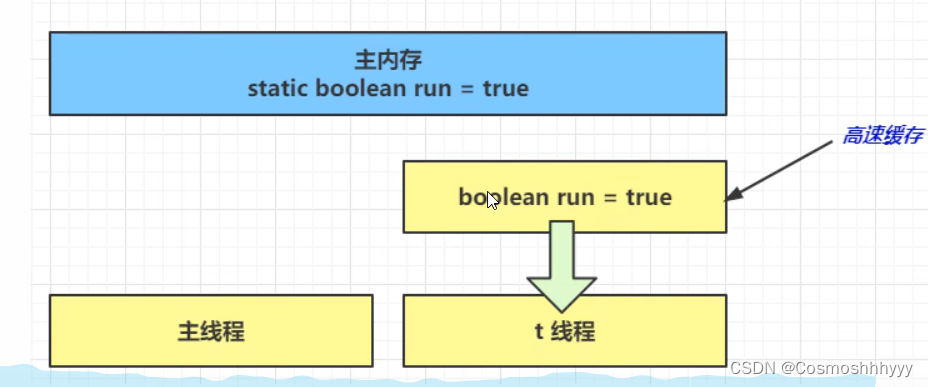
解决方法
加volatile, 它可以用来修饰成员变量和静态成员变量,可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的最新值,线程操作 volatile 变量都是直接操作主存。
volatile static boolean run = true;
当然我么之前用synchronized上锁,让共享变量在锁代码块中操作,也是可以保证可见性的,不然我么之前的的代码不就都不对了么。
不过synchronized毕竟比较重还要创建monitor,而volatile是更加轻量级的。
原子性
volatile只能保证读取到最新值,而不能解决原子性问题。
比如线程t1读取到了值x = 0,要进行++操作时,正好切换了,切换到了线程t2了,而t2也读取x = 0, 并对于x进行了–操作返回给内存进行更新,然后又切换回线程t2,t2该进行++操作,并且赋值x更新到内存。
原本一加一减应该变回0,但经过这种线程切换的情况,x最后为1,显然不符合我们的预期,因为破坏了读写的原子性。
所以在保证原子性时,还是利用synchronized和ReentrantLock编写代码时对共享变量读写保证其原子性。
有序性
指令重排
JVM 会在不影响正确性的前提下,可以调整语句的执行顺序。
比如i和j同时++,因为互不影响,谁先执行都一样,所以jvm可能的执行顺序就是i++,j++也可以是j++,i++。
流水线技术
流水线技术是一种并行计算的方式,它类似于生产流水线,将一个复杂的任务分解为一系列的子任务,并且这些子任务可以并行地执行,每个子任务的输出作为下一个子任务的输入,从而实现整体任务的并行处理。
在计算机科学中,流水线技术通常用于优化处理速度,特别是对于那些可以被分解为多个相互独立阶段的任务。通过流水线技术,可以将一个任务分解为多个阶段,每个阶段由专门的处理单元来执行,这样就可以同时处理多个阶段,从而提高整体处理速度。
流水线技术常见于处理器的设计中,例如现代CPU中的指令流水线。在指令流水线中,CPU将指令执行分解为多个阶段,比如取指阶段、解码阶段、执行阶段等等,每个阶段由专门的硬件单元来执行,这样就可以实现多条指令的并行执行,从而提高CPU的吞吐量。
简单来说啊,在不改变结果的情况下,把一个任务,拆成多个,重排序,一起执行。

// 可以重排
int a = 10; // 指令1
int b = 20; // 指令2
System.out.println( a + b );
// 不能重排
int a = 10; // 指令1
int b = a - 5; // 指令2
指令重排出现的问题
int num = 0;
boolean ready = false;
// 线程1 执行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
r.r1最后可能为0,但是概率非常非常非常小,我们自己测不出来的。
原因线程2执行方法指令重排,先执行了ready = true,这时切换线程1,执行了r.r1 = num + num,然后线程2才执行了num = 2。那么最后r.r1就等于0.
解决方法:
还是加上volatile即可,可以防止指令重排序。
volatile会保证 顺序性 和 可见性。
模式之Balking(犹豫)
犹豫模式,一个线程在执行某个操作之前会检查某个条件,如果条件不满足,则放弃执行,直接返回。这个模式的核心思想就是避免重复执行某个操作,当发现已经有其他线程或本线程已经执行了相同的操作时,就直接结束当前线程的执行。
Balking 模式通常适用于一些需要进行资源共享或状态同步的场景。当多个线程需要对共享资源进行访问或修改时,可以使用 Balking 模式来确保资源的正确使用,避免出现竞态条件或资源浪费。
举个简单的例子,假设有一个线程池,多个线程需要从线程池中获取任务执行。在获取任务之前,每个线程会检查线程池中是否还有可用的任务,如果有,则取出任务执行,如果没有,则放弃执行,直接返回。这样就可以避免多个线程同时尝试获取任务导致的竞态条件,同时也可以避免线程在没有可执行任务时进行无效的等待,提高了线程池的效率。
public class MonitorService {
// 用来表示是否已经有线程已经在执行启动了
private volatile boolean starting;
public void start() {
log.info("尝试启动监控线程...");
synchronized (this) {
if (starting) {
return;
}
starting = true;
}
// 真正启动监控线程...
}
}
这里volatile是可以不加的,synchronized已经保证了可见性,不过,通常建议还是添加 volatile 关键字来明确地表达你的意图,即使这样做可能会带来一些微小的性能开销。
synchronized锁代码块可以保证原子性、有序性、可见性。
double-checked locking(DCL) 问题
- 第一个if用于后续进入的线程,不用再获取锁来判断是否已经创建了对象。
- 第二个if,为的是第一个进入的线程创建对象,以及防止卡在第一个if之后,获锁之前的线程在第一个线程已经创建对象的情况下,在获取锁后,判断不用创建对象,防止多次创建。
单例模式:
public final class Singleton {
private Singleton() { }
private static Singleton INSTANCE = null;
public static Singleton getInstance() {
if(INSTANCE == null) {
// 首次访问同步,而之后的使用就不用 synchronized,所以在此行前加了判断
synchronized(Singleton.class) {
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
特点:
- 懒汉式实例化
- 首次使用加锁,之后不用加锁
但是,看似完美的代码,其实并不对,因为第一个if判断并不在synchronized中,所以可能会发生指令重排问题。
synchronized可以保证原子、有序、可见性,但是有序性需要变量完全synchronized被保护,这里第一个if并不在sync中,所以是可能发生下述情况的。
也就是说synchronized只能保证临界区内的指令不和临界区外的指令发生重排序。
比如先给INSTANCE赋值了,但是还没有调用构造方法,这时线程切换,他以为你创建好了对象,然后返回对象直接开始使用,是不是就出现问题了,因为我们对象还没构造呢。
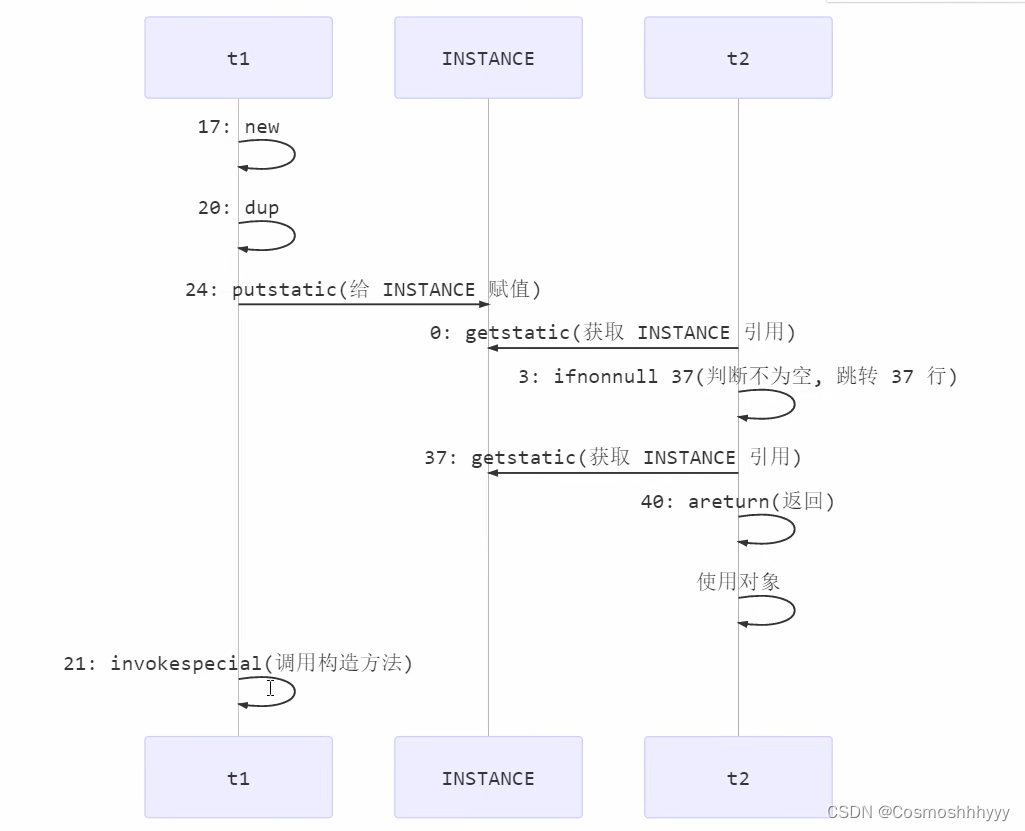
解决方法
给Singleton加volatile的原因。
public final class Singleton {
private Singleton() { }
private static volatile Singleton INSTANCE = null;
public static Singleton getInstance() {
if(INSTANCE == null) {
// 首次访问同步,而之后的使用就不用 synchronized,所以在此行前加了判断
synchronized(Singleton.class) {
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
这样就是一个正确的代码了。
volatile作用
volatile作用:
可见性:
- 写屏障(sfence)保证在该屏障之前对共享变量的改动,都同步到主存当中
- 读屏障(lfence)保证在该屏障之后对共享变量的读取,加载的是主存中最新数据
有序性:
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
只能保证读数据正确,不能保证原子性。
happens-before 规则
No.1
线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可性。
static int x;
static Object m = new Object();
new Thread(()->{
synchronized(m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized(m) {
System.out.println(x);
}
},"t2").start();
synchronized锁保证了可见性。
No.2
线程对 volatile 变量的写,对接下来其它线程对该变量的读可见。
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();
volatile保证读的正确性。
No.3
线程 start 前对变量的写,对该线程开始后对该变量的读可见。
static int x;
x = 10;
new Thread(()->{
System.out.println(x);
},"t2").start();
线程开始前写的,开始后肯定读到了正确。
No.4
线程结束前对变量的写,对其它线程得知它结束后的读可见。
static int x;
Thread t1 = new Thread(()->{
x = 10;
},"t1");
t1.start();
t1.join();
System.out.println(x);
No.5
线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见
static int x;
public static void main(String[] args) {
Thread t2 = new Thread(()->{
while(true) {
if(Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
},"t2");
t2.start();
new Thread(()->{
sleep(1);
x = 10;
t2.interrupt();
},"t1").start();
while(!t2.isInterrupted()) {
Thread.yield();
}
System.out.println(x);
}
t1线程赋完值后,进行打断t2,t2感知到打断标记为true后,输出,同时主线程再判断,然后输出。
No.6
对变量默认值(0,false,null)的写,对其它线程对该变量的读可见。
No.7
具有传递性,如果 x hb-> y 并且 y hb-> z 那么有 x hb-> z ,配合 volatile 的防指令重排,有下面的例子。
volatile static int x;
static int y;
new Thread(()->{
y = 10;
x = 20;
},"t1").start();
new Thread(()->{
// x=20 对 t2 可见, 同时 y=10 也对 t2 可见
System.out.println(x);
},"t2").start();
volatile会将写屏障之前的所有操作同步到主存,同步不会重排序,所以x赋值后,y也一定同步到主存了,虽然y没加volatile,但是对t2也是可见的。
CAS
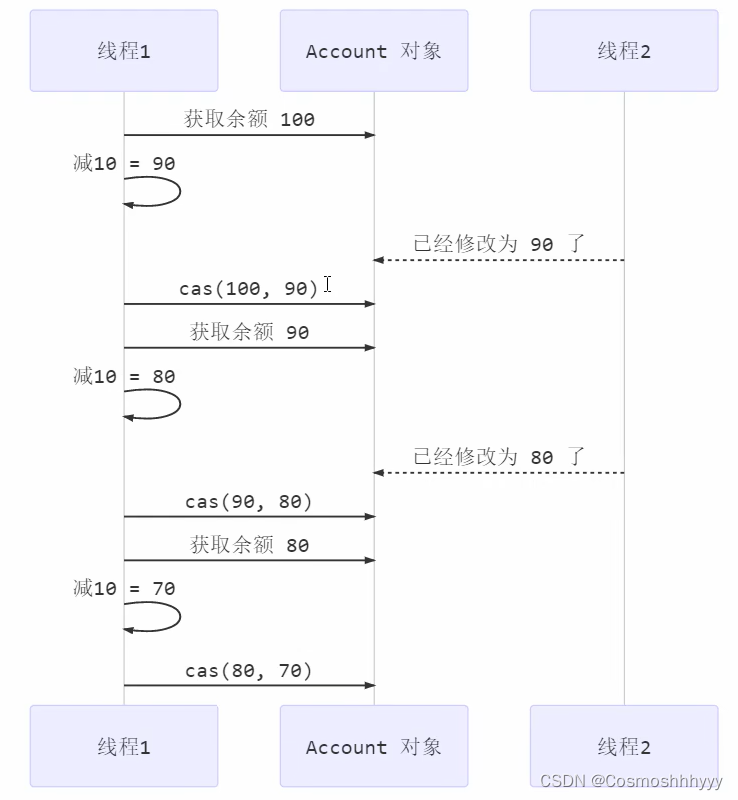
compareAndSet 比较和换行。
方法内部是原子的(指令级别)。
修改失败会返回false,用原值和最新值进行比较,如果原值被他人修改了返回false,若原值没有被人修改,进行交换,返回true。
当然这里会出现aba问题,加上版本号就可以很好的解决。
while循环直到交换成功。
public void withdraw(Integer amount) {
while (true) {
int prev = balance.get();
int next = prev - amount;
if (balance.compareAndSet(prev, next)) {
break;
}
}
}
- CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性。
- 在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
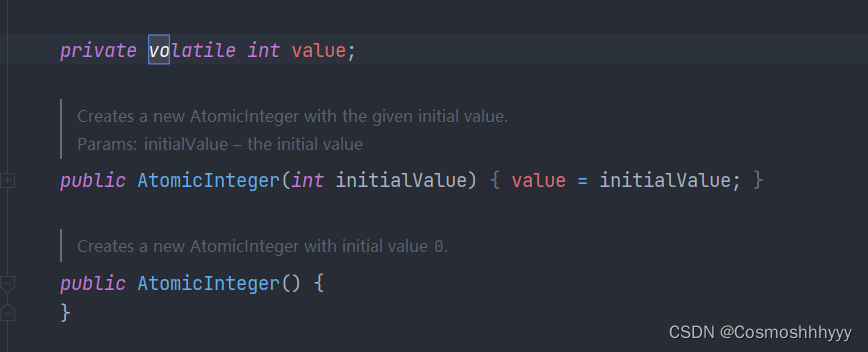
与volatile关系
cas需要volatile支持,因为我们比较时,需要利用最新值进行比较。
来看看AtomicInteger源码
为什么 cas 比 加锁 效率高
- 无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。
- 无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还是会导致上下文切换。
- 从阻塞机制变成了非阻塞机制,减少了线程之间等待的时间。
- 所以需要多核cpu才能发挥cas的作用。
cas的特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
- CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
- synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
CAS 体现的是无锁并发、无阻塞并发。
- 因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响。你想想,如果有一堆线程再不断的自旋重试,肯定会造成cpu的浪费。
原子类型
AtomicInteger 原子整数
public class test6 {
public static void main(String[] args) {
AtomicInteger i = new AtomicInteger();
System.out.println(i.getAndIncrement()); // i++ sout: 0
System.out.println(i.incrementAndGet()); // ++i sout: 2
System.out.println(i.decrementAndGet()); // --i sout: 1
System.out.println(i.getAndDecrement()); // i-- sout: 1
// i = 0
System.out.println(i.getAndAdd(5)); // sout:0 i += 5
System.out.println(i.addAndGet(-5)); // i -= 5 sout:0
// i = 0
System.out.println(i.getAndUpdate(p -> p - 2)); // sout:0 p -= 2
System.out.println(i.updateAndGet(p -> p + 2)); // p += 2 sout: 0
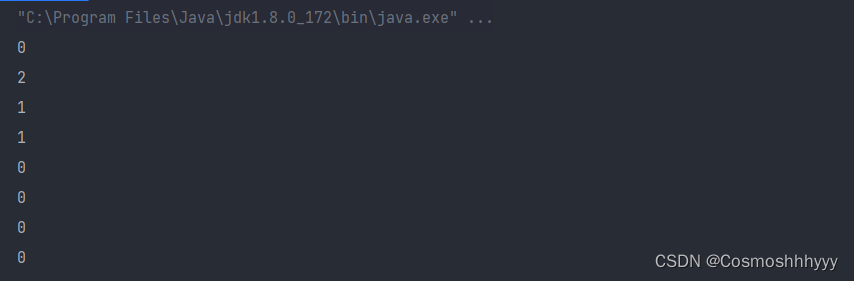
}
}
AtomicReferenc 原子引用
class DecimalAccountSafeCas{
AtomicReference<BigDecimal> ref;
public DecimalAccountSafeCas(BigDecimal balance) {
ref = new AtomicReference<>(balance);
}
public BigDecimal getBalance() {
return ref.get();
}
public void withdraw(BigDecimal amount) {
while (true) {
BigDecimal prev = ref.get();
BigDecimal next = prev.subtract(amount); // 减小
if (ref.compareAndSet(prev, next)) { // cas
break;
}
}
}
}
AtomicStampedReference 带版本号的原子引用
解决aba问题,aba问题之前介绍过了。
如果版本号与之前获取的相同,那么就进行交换,同时更新版本号。
可以知道更改次数。
class DecimalAccountSafeCas{
AtomicStampedReference<BigDecimal> ref;
public DecimalAccountSafeCas(BigDecimal balance) {
ref = new AtomicStampedReference<>(balance, 0); // 初始版本号0
}
public BigDecimal getBalance() {
return ref.getReference();
}
public void withdraw(BigDecimal amount) {
while (true) {
BigDecimal prev = ref.getReference();
int stamp = ref.getStamp();// 获取版本号
// 如果这之中有其他线程又修改了ref,那么版本号改变与之前不同。就会cas失败
BigDecimal next = prev.subtract(amount); // 减小
if (ref.compareAndSet(prev, next, stamp, stamp + 1)) { // cas。版本号相同才交换,并且更新版本号
break;
}
}
}
}
AtomicMarkableReference 仅记录是否修改的原子引用
我们一般不关心中间修改了多少次,我么只在乎是否修改过,那么就可以用这个类。
所以一个boolean值就可以记录。
class DecimalAccountSafeCas{
AtomicMarkableReference<BigDecimal> ref;
public DecimalAccountSafeCas(BigDecimal balance) {
ref = new AtomicMarkableReference<>(balance, true);
}
public BigDecimal getBalance() {
return ref.getReference();
}
public void withdraw(BigDecimal amount) {
while (true) {
BigDecimal prev = ref.getReference();
BigDecimal next = prev.subtract(amount); // 减小
// 如果这时有线程修改,把mark变为了false,那么就会cas就会失败
// 因为只有true,和false,我们就直接就对比是否是true就行了,不用在获取
if (ref.compareAndSet(prev, next, true, false)) { // cas。版本号相同才交换,并且更新版本号
break;
}
}
}
}
AtomicXXXArray 原子数组
我么一般都不是修改引用指向,而是引用里的内容,就比如数组。
下面是线程安全的数组。
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
这里我么先用普通数组,来看看是否有线程安全问题:
package com.leran;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.function.BiConsumer;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Supplier;
public class test7 {
public static void main(String[] args) {
demo(
() -> new int[10],
(array) -> array.length,
(array, idx) -> array[idx]++,
array -> System.out.println(Arrays.toString(array))
);
}
private static <T> void demo(
Supplier<T> arraySupplier, // 生产者,无中生有
Function<T, Integer> lengthFun, // 一个参数一个结果 BiFunction 多个参数,多个结果
BiConsumer<T, Integer> putConsumer, // 消费者多个参数,无结果
Consumer<T> printConsumer ) { // 一个参数,无结果
List<Thread> ts = new ArrayList<>();
T array = arraySupplier.get(); // 获取传入的数组
int length = lengthFun.apply(array); // 获取长array长度
for (int i = 0; i < length; i++) {
// 每个线程对数组作 10000 次操作
ts.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j%length);
}
}));
}
ts.forEach(t -> t.start()); // 启动所有线程
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); // 等所有线程执行完,输出
printConsumer.accept(array);
}
}

显然是不安全的,下面介绍安全的AtomicIntegerArray。
demo方法不变,改变传入的数组。
demo(
() -> new AtomicIntegerArray(10),
(array) -> array.length(),
(array, idx) -> array.getAndIncrement(idx),
array -> System.out.println(array)
);

其他用法相似。
AtomicXXXFieldUpdater 字段更新器
用于更新某一类中的属性。
- AtomicReferenceFieldUpdater // 域字段
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
必须配合volatile使用。
如:AtomicIntegerFieldUpdater
public class test8 {
public static void main(String[] args) {
AtomicIntegerFieldUpdater fieldUpdater = AtomicIntegerFieldUpdater.newUpdater(Student.class, "age");
Student student = new Student();
fieldUpdater.compareAndSet(student, 0, 5);
System.out.println(student.age); // 5
fieldUpdater.compareAndSet(student,5, 10);
System.out.println(student.age); // 10
fieldUpdater.compareAndSet(student, 5, 20); // 修改失败
System.out.println(student.age); // 10
}
}
class Student{
volatile int age;
@Override
public String toString() {
return "student{" +
"age=" + age +
'}';
}
}
其他用法相似。
LongAdder 累加器
java中专门用于累加的,所以性能肯定比我么AtomicLong好。
下面是对比。
public class test9 {
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
demo(() -> new AtomicLong(), adder -> adder.getAndIncrement());
}
for (int i = 0; i < 5; i++) {
demo(() -> new LongAdder(), adder -> adder.increment());
}
}
private static <T> void demo(Supplier<T> adderSupplier, Consumer<T> action) {
T adder = adderSupplier.get();
long start = System.nanoTime();
List<Thread> ts = new ArrayList<>();
for (int i = 0; i < 40; i++) {
ts.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
action.accept(adder);
}
}));
}
ts.forEach(t -> t.start());
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(adder + " cost:" + (end - start)/1000_000 + "ns");
}
}
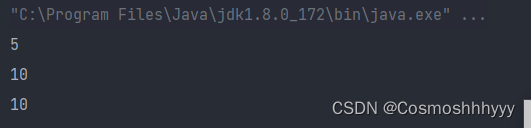
前五次是AtomicLong累加
后五次是LongAdder累加
20000000 cost:414ns
20000000 cost:390ns
20000000 cost:366ns
20000000 cost:377ns
20000000 cost:414ns
20000000 cost:33ns
20000000 cost:26ns
20000000 cost:26ns
20000000 cost:27ns
20000000 cost:37ns
Process finished with exit code 0
显然是快了10倍左右。
性能提升的原因,就是在有竞争时,设置多个累加单元Cell,最后将结果汇总。
这样在累加时操作的是不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
不可变类
SimpleDateFormat 不安全
public static void main(String[] args) {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 100; i++) {
new Thread(() -> {
try {
System.out.println(simpleDateFormat.parse("1951-04-21"));
} catch (ParseException e) {
e.printStackTrace();
}
}).start();
}
}
SimpleDateFormat是一个线程不安全的,多线程下大概率出现报错:

为什么不安全?
来看看这个方法:
@Override
public Date parse(String text, ParsePosition pos)
{
checkNegativeNumberExpression();
int start = pos.index;
int oldStart = start;
int textLength = text.length();
boolean[] ambiguousYear = {false};
CalendarBuilder calb = new CalendarBuilder();
for (int i = 0; i < compiledPattern.length; ) {
int tag = compiledPattern[i] >>> 8;
int count = compiledPattern[i++] & 0xff;
if (count == 255) {
count = compiledPattern[i++] << 16;
count |= compiledPattern[i++];
}
switch (tag) {
case TAG_QUOTE_ASCII_CHAR:
if (start >= textLength || text.charAt(start) != (char)count) {
pos.index = oldStart;
pos.errorIndex = start;
return null;
}
start++;
break;
case TAG_QUOTE_CHARS:
while (count-- > 0) {
if (start >= textLength || text.charAt(start) != compiledPattern[i++]) {
pos.index = oldStart;
pos.errorIndex = start;
return null;
}
start++;
}
break;
default:
// Peek the next pattern to determine if we need to
// obey the number of pattern letters for
// parsing. It's required when parsing contiguous
// digit text (e.g., "20010704") with a pattern which
// has no delimiters between fields, like "yyyyMMdd".
boolean obeyCount = false;
// In Arabic, a minus sign for a negative number is put after
// the number. Even in another locale, a minus sign can be
// put after a number using DateFormat.setNumberFormat().
// If both the minus sign and the field-delimiter are '-',
// subParse() needs to determine whether a '-' after a number
// in the given text is a delimiter or is a minus sign for the
// preceding number. We give subParse() a clue based on the
// information in compiledPattern.
boolean useFollowingMinusSignAsDelimiter = false;
if (i < compiledPattern.length) {
int nextTag = compiledPattern[i] >>> 8;
if (!(nextTag == TAG_QUOTE_ASCII_CHAR ||
nextTag == TAG_QUOTE_CHARS)) {
obeyCount = true;
}
if (hasFollowingMinusSign &&
(nextTag == TAG_QUOTE_ASCII_CHAR ||
nextTag == TAG_QUOTE_CHARS)) {
int c;
if (nextTag == TAG_QUOTE_ASCII_CHAR) {
c = compiledPattern[i] & 0xff;
} else {
c = compiledPattern[i+1];
}
if (c == minusSign) {
useFollowingMinusSignAsDelimiter = true;
}
}
}
start = subParse(text, start, tag, count, obeyCount,
ambiguousYear, pos,
useFollowingMinusSignAsDelimiter, calb);
if (start < 0) {
pos.index = oldStart;
return null;
}
}
}
// At this point the fields of Calendar have been set. Calendar
// will fill in default values for missing fields when the time
// is computed.
pos.index = start;
Date parsedDate;
try {
parsedDate = calb.establish(calendar).getTime();
// If the year value is ambiguous,
// then the two-digit year == the default start year
if (ambiguousYear[0]) {
if (parsedDate.before(defaultCenturyStart)) {
parsedDate = calb.addYear(100).establish(calendar).getTime();
}
}
}
// An IllegalArgumentException will be thrown by Calendar.getTime()
// if any fields are out of range, e.g., MONTH == 17.
catch (IllegalArgumentException e) {
pos.errorIndex = start;
pos.index = oldStart;
return null;
}
return parsedDate;
}
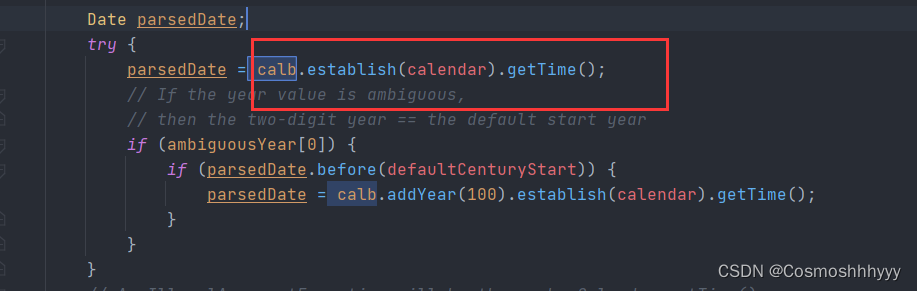
主要是这里调用了establish()
Calendar establish(Calendar cal) {
boolean weekDate = isSet(WEEK_YEAR)
&& field[WEEK_YEAR] > field[YEAR];
if (weekDate && !cal.isWeekDateSupported()) {
// Use YEAR instead
if (!isSet(YEAR)) {
set(YEAR, field[MAX_FIELD + WEEK_YEAR]);
}
weekDate = false;
}
cal.clear();
// Set the fields from the min stamp to the max stamp so that
// the field resolution works in the Calendar.
for (int stamp = MINIMUM_USER_STAMP; stamp < nextStamp; stamp++) {
for (int index = 0; index <= maxFieldIndex; index++) {
if (field[index] == stamp) {
cal.set(index, field[MAX_FIELD + index]);
break;
}
}
}
if (weekDate) {
int weekOfYear = isSet(WEEK_OF_YEAR) ? field[MAX_FIELD + WEEK_OF_YEAR] : 1;
int dayOfWeek = isSet(DAY_OF_WEEK) ?
field[MAX_FIELD + DAY_OF_WEEK] : cal.getFirstDayOfWeek();
if (!isValidDayOfWeek(dayOfWeek) && cal.isLenient()) {
if (dayOfWeek >= 8) {
dayOfWeek--;
weekOfYear += dayOfWeek / 7;
dayOfWeek = (dayOfWeek % 7) + 1;
} else {
while (dayOfWeek <= 0) {
dayOfWeek += 7;
weekOfYear--;
}
}
dayOfWeek = toCalendarDayOfWeek(dayOfWeek);
}
cal.setWeekDate(field[MAX_FIELD + WEEK_YEAR], weekOfYear, dayOfWeek);
}
return cal;
}
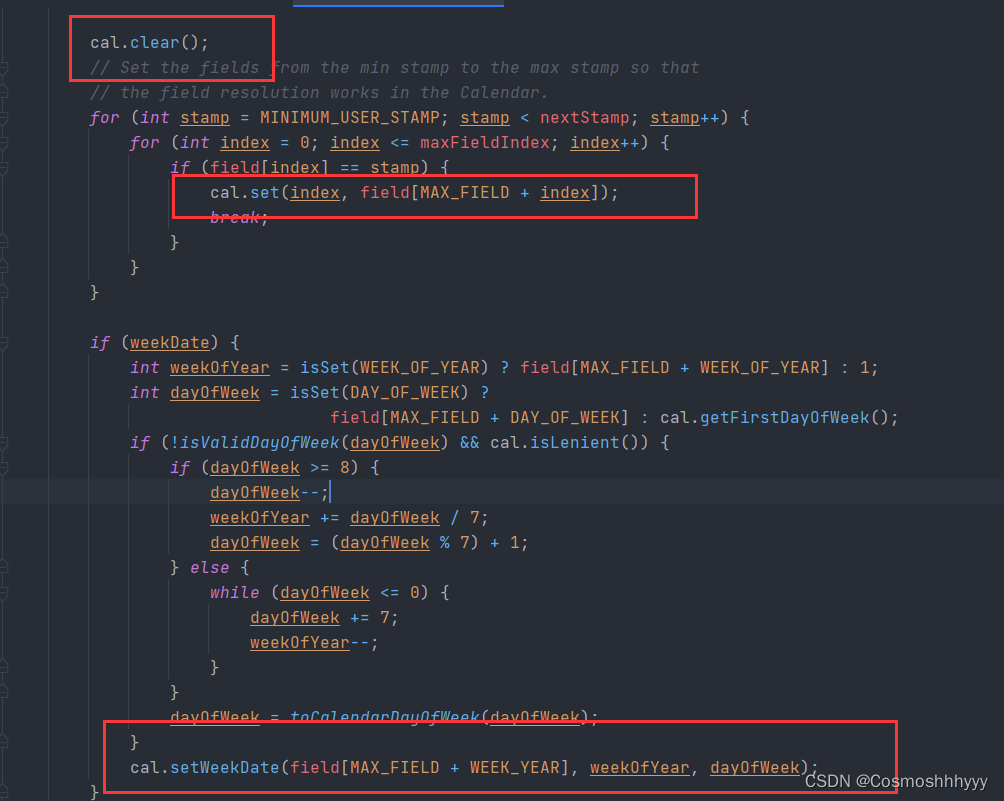
参数为calender,那么这个canlender出自哪里呢?
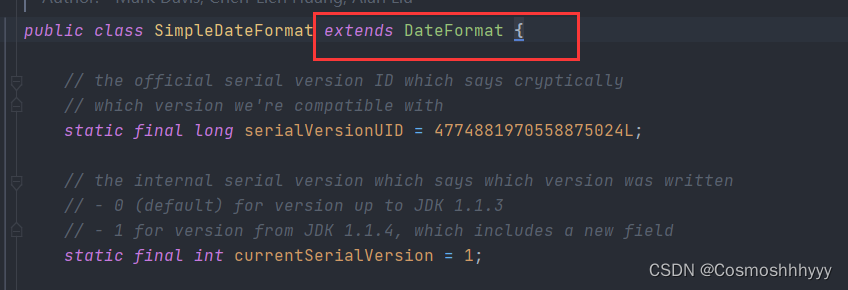
实际上是继承DateFormat里的。
establish中先进行了cal.clear(),又进行了cal.set()。 先清除cal对象中是值,再设置新的值。
这样多线程下,调用同一个cal,而cal又没有设置线程安全,比如线程t1刚set完,t2进行了clear,那t1的输出肯定是不对的。
下面介绍几种解决方法。
解决 DateTimeFormatter
方法一:
首先想到的肯定是加锁
public class test10 {
public static void main(String[] args) {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 100; i++) {
new Thread(() -> {
synchronized (simpleDateFormat) {
try {
System.out.println(simpleDateFormat.parse("1951-04-21"));
} catch (ParseException e) {
e.printStackTrace();
}
}
}).start();
}
}
}
这样可以解决,但是效率肯定是不高的。
方法二:
利用不可变类型DateTimeFormatter
源码介绍是一个不可变的、线程安全的类
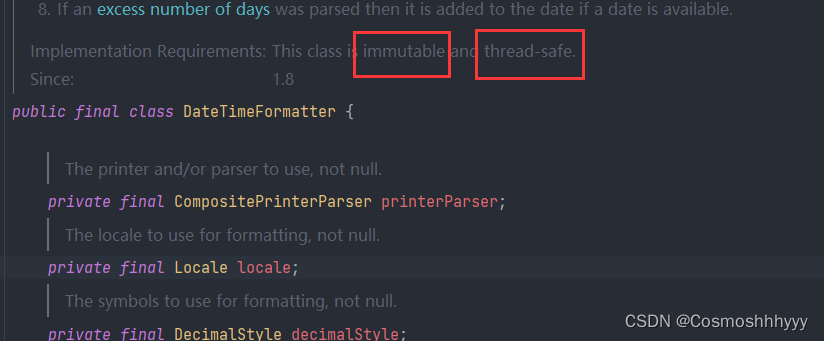
public class test10 {
public static void main(String[] args) {
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
for (int i = 0; i < 100; i++) {
new Thread(() -> {
TemporalAccessor parse = dateTimeFormatter.parse("1951-04-21");
System.out.println(parse);
}).start();
}
}
}
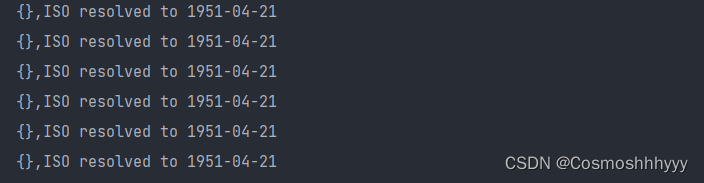
不可变类保证线程安全的实现
不可变类的类,属性都是final修饰的。
例如String:
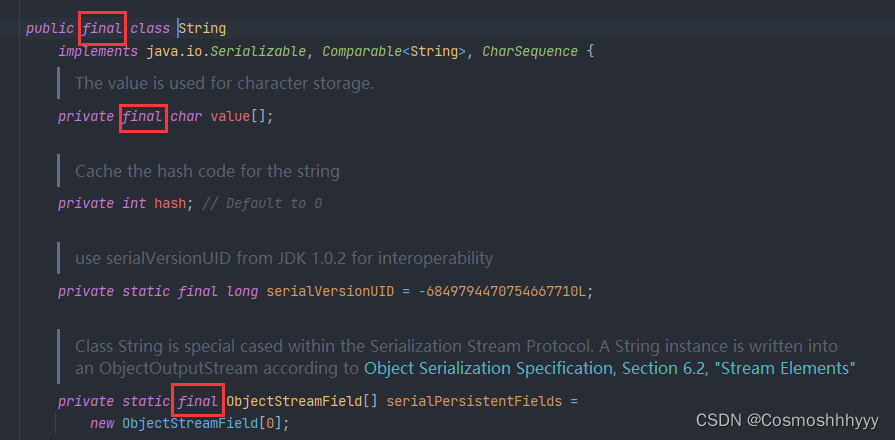
保证只读和防止修改。
同时其方法都是操作一个新对象,并不在原对象上操作,保证了安全。
手写数据库连接池
package com.数据库连接池;
import java.sql.*;
import java.util.Map;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.Executor;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicIntegerArray;
public class test {
public static void main(String[] args) {
Pool pool = new Pool(3);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
Connection conn = pool.borrow();
try {
Thread.sleep(new Random().nextInt(1000)); // 模拟使用随机的时间后,进行归还
} catch (InterruptedException e) {
e.printStackTrace();
}
pool.free(conn);
}).start();
}
}
}
class Pool {
// 连接池大小
private final int poolSize;
// 连接对象数组
private Connection[] connections;
// 连接状态,线程安全的
private AtomicIntegerArray states;
public Pool(int poolSize) {
this.poolSize = poolSize;
this.connections = new Connection[poolSize];
this.states = new AtomicIntegerArray(new int[poolSize]);
for (int i = 0; i < poolSize; i++) {
connections[i] = new MockConnection();
}
}
// 借连接
public Connection borrow() {
while (true) {
for (int i = 0; i < poolSize; i++) {
if (states.get(i) == 0) {
if (states.compareAndSet(i, 0, 1)) { // cas成功才return,不要直接set,防止多线程读写分离
System.out.println(Thread.currentThread().getName() + "借到了连接");
return connections[i];
}
}
}
// 没有空闲连接,进入等待
System.out.println(Thread.currentThread().getName() + "没有空闲连接,进入等待");
synchronized (this) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 归还连接
public void free(Connection connection) {
for (int i = 0; i < poolSize; i++) {
if (connections[i] == connection) {
states.set(i, 0); // 这里不用cas,归还线程一定是唯一拥有它的线程
System.out.println(Thread.currentThread().getName() + "释放了连接");
// 通知如果有再wait中的线程
synchronized (this) {
this.notifyAll();
}
break;
}
}
}
}
// 不用真的去连接,随便实现一下Connection用来测试即可
class MockConnection implements Connection{
// 这里省略了,太长了
}

手写线程池

public class MyThreadPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(2, 1000,TimeUnit.MICROSECONDS, 10, (queue, task) -> {
// 1.死等
queue.put(task);
// 2.带超时时间等待加入等待队列
// queue.offer(task, 500, TimeUnit.MICROSECONDS);
// 3.放弃任务
// 队列满了,没做人任何事情
// 4.抛出异常
// throw new RuntimeException("任务执行失败" + task);
// 5.让调用者自己执行
// task.run();
});
for (int i = 0; i < 15; i++) {
int j = i;
threadPool.execute(() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(j);
});
}
}
}
// 拒接策略
@FunctionalInterface
interface RejectPolicy<T> {
void reject(BlockQueue queue, T task) ;
}
class ThreadPool {
// 任务队列
private BlockQueue<Runnable> taskQueue;
// 线程集合
private HashSet<Worker> workers = new HashSet();
// 线程数
private int coreSize;
private long timeout;
private TimeUnit timeUnit;
private RejectPolicy<Runnable> rejectPolicy;
// 构造方法
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueSize, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockQueue<>(queueSize);
this.rejectPolicy = rejectPolicy;
}
public void execute(Runnable task) {
// 当任务数没有超过核心数时,直接交给woker对象执行
// 如果超过,放入任务队列中存起来
synchronized (workers) { // workers不安全,把他锁起来
if (workers.size() < coreSize) {
Worker worker = new Worker(task);
System.out.println("新增worker");
workers.add(worker); // 加入线程集合
worker.start();
} else {
// taskQueue.put(task); // 任务添加进入
// 1.死等
// 2.带超时时间等待
// 3.放弃任务
// 4.抛出异常
// 5.让调用者自己执行
taskQueue.tryPut(rejectPolicy, task);
}
}
}
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
// 当task任务不为空,执行
// 当任务为空,去任务队列中去取
// while (task != null || (task = taskQueue.take()) != null) 一直等待获取
while (task != null || (task = taskQueue.poll(timeout, timeUnit)) != null) {
try {
System.out.println("正在执行" + task);
task.run();
} catch (Exception e) {
} finally {
task = null;
}
}
synchronized (workers) {
System.out.println("worker被移除" + this);
workers.remove(this); // 移除当前集合对象
}
}
}
}
// 阻塞队列
class BlockQueue<T> {
// 任务队列
private Deque<T> queue = new ArrayDeque<>();
// 锁
private ReentrantLock lock = new ReentrantLock();
// 满了等待,生产者
private Condition fullWaitSet = lock.newCondition();
// 空的等待,消费者
private Condition emptyWaitSet = lock.newCondition();
// 容量
private int capacity;
public BlockQueue(int capacity) {
this.capacity = capacity;
}
// 阻塞队列中获取任务
public T take() {
lock.lock();
try {
while (queue.isEmpty()) {
try {
emptyWaitSet.await(); // 进入等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal(); // 唤醒
return t;
} finally {
lock.unlock();
}
}
// 阻塞队列中添加任务
public void put(T t) {
lock.lock();
try {
while (queue.size() == capacity) { // 如果满了,进入等待
try {
System.out.println("等待加入任务队列" + t);
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("加入任务队列" + t);
queue.addLast(t);
emptyWaitSet.signal(); // 唤醒
}finally {
lock.unlock();
}
}
public int size() {
lock.lock();
try {
return queue.size();
}finally {
lock.unlock(); // 就算return也会执行
}
}
// 带超时时间的获取,无需永久的等待了
public T poll (long timeout, TimeUnit unit) {
lock.lock();
try {
long nanos = unit.toNanos(timeout); // 时间转换为ns
while (queue.isEmpty()) {
try {
if (nanos <= 0) return null; // 超时了,直接返回吧
nanos = emptyWaitSet.awaitNanos(nanos);// 进入等待,超时不再等待,返回结果为剩余等待时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal(); // 唤醒
return t;
} finally {
lock.unlock();
}
}
// 带超时时间的添加, return 添加成功 or 失败
public boolean offer(T task, long timeout, TimeUnit timeUnit) {
lock.lock();
try {
long nanos = timeUnit.toNanos(timeout);
while (queue.size() == capacity) { // 如果满了,进入等待
try {
System.out.println("等待加入任务队列" + task);
if (nanos <= 0) return false;
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("加入任务队列" + task);
queue.addLast(task);
emptyWaitSet.signal(); // 唤醒
return true;
}finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
// 判断队列是否已满
if (queue.size() == capacity) { // 有空闲
rejectPolicy.reject(this, task); // 拒绝策略
} else { // 有空闲
queue.addLast(task);
emptyWaitSet.signal();
}
}finally {
lock.unlock();
}
}
}
ThreadPoolExecutor
线程池状态
线程池用高三位表示状态,第一位为符号位。

TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING
构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
- corePoolSize 核心线程数目
- maximumPoolSize 最大线程数目
- keepAliveTime 生存时间 - 针对救急线程
- unit 时间单位 - 针对救急线程
- workQueue 阻塞队列
- threadFactory 线程工厂
- handler 拒绝策略
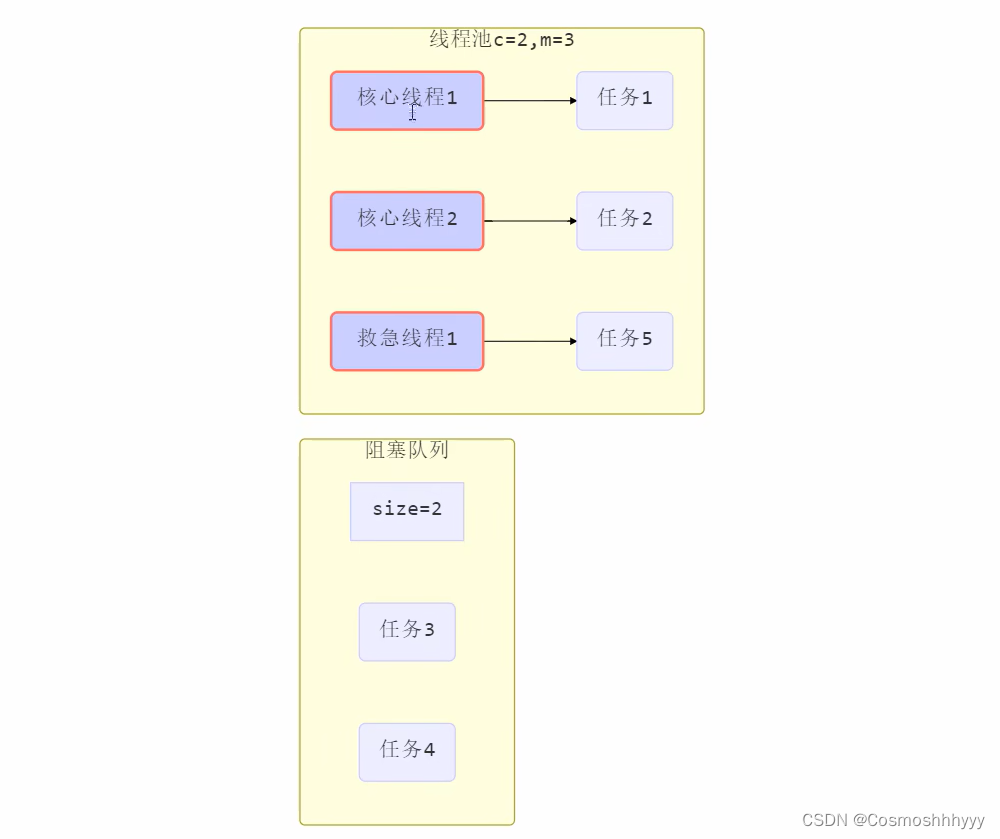
任务会先创建核心线程执行,若核心线程到达核心数,任务进入阻塞队列(任务队列),若阻塞队列也满了,则启用急救线程执行任务,若达到最大线程数,那么才会启用拒绝策略,急救线程在一段时间没有执行任务会自行关闭。
Executors 工厂方法
帮助我们快速构建想要的线程池,不用配置那么多参数。
newFixedThreadPool
固定线程的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点:
- 核心线程数 = 最大线程数(救急线程)。
- 无界队列,可以放入任意多任务。
- 阻塞队列是无界的,可以放任意数量的任务。
适用于任务量已知,相对耗时的任务。
newCachedThreadPool
带缓冲的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点:
- 核心线程数是 0,最大线程数是 Integer.MAX_VALUE。
- 创建的全部都是救急线程(60s 后可以回收)
- 救急线程可以无限创建。
- 队列采用了SynchronousQueue(同步队列),没有容量,有线程去取才能放入,所以叫同步的队列。
适合任务数比较密集,但每个任务执行时间较短的情况。
newSingleThreadExecutor
单线程的线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
特点:
线程数固定为 1,任务数多于 1 时,会放入无界队列排队。
任务执行完毕,这唯一的线程也不会被释放。
和自己创建一个线程来工作的区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作。
和Executors.newFixedThreadPool(1)的区别:
- Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改。FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法
- Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改。
对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
提交任务方法
// 执行任务
void execute(Runnable command);
// 用Future 获得任务执行结果,保护性暂停,主线程输出结果时,阻塞,直到返回结果
<T> Future<T> submit(Callable<T> task);
// 提交集合中所有任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
// 提交集合中所有任务,带超时时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
// 交集合中所有任务, 只要有一个任务完成,返回结果,其他的任务取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
// 交集合中所有任务, 只要有一个任务完成,返回结果,其他的任务取消, 带超时时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
关闭任务方法
void shutdown();
线程池状态变为 SHUTDOWN
- 不会接收新任务
- 但已提交任务会执行完
- 此方法不会阻塞调用线程的执行
List<Runnable> shutdownNow();
线程池状态变为 STOP
- 不会接收新任务
- 会将队列中的任务返回
- 并用 interrupt 的方式中断正在执行的任务
// 不在RUNNING状态的线程池,就返回 true
boolean isShutdown();
// 线程池状态是否是TERMINATED
boolean isTerminated();
// 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束,因此如果它想在线程池 TERMINATED 后做些事情,可以利用此方法等待
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
线程个数
. 创建多少线程池合适
- 过小会导致程序不能充分地利用系统资源、容易导致饥饿
- 过大会导致更多的线程上下文切换,占用更多内存
CPU 密集型运算
通常采用 cpu 核数 + 1 和cpu核心数 - 1 能够实现最优的 CPU 利用率,+1 是保证当线程由于页缺失故障(操作系统)或其它原因
导致暂停时,额外的这个线程就能顶上去,保证 CPU 时钟周期不被浪费。
核心数2n、3n,防止cpu核心空闲,及时的补上取利用cpu。
I/O 密集型运算
CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用 CPU 资源,但当你执行 I/O 操作时、远程
RPC 调用时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下:
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+等待时间) / CPU 计算时间
例如 4 核 CPU 计算时间是 50% ,其它等待时间是 50%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 50% = 8
例如 4 核 CPU 计算时间是 10% ,其它等待时间是 90%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 10% = 40
ScheduledThreadPoolExecutor
timer(不建议用)
timer也可以进行延迟运行,但是会有很多问题。
比如task1运行时间超过task2延迟时间。
@Slf4j(topic = "c.Main")
public class Main {
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.debug("task 1");
try {
sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.debug("task 2");
}
};
log.debug("start...");
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
}

当task1出异常,task2不会运行。
ScheduledThreadPoolExecutor
Executors就可以创建。
延迟执行:
@Slf4j(topic = "c.Main")
public class Main {
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
scheduledExecutorService.schedule(() -> {
log.debug("task1");
int i = 1 / 0; // 模拟异常
}, 1, TimeUnit.SECONDS);
scheduledExecutorService.schedule(() -> {
log.debug("task2");
}, 1, TimeUnit.SECONDS);
}
}

可以看出通过控制线程数可以解决timer的缺点。
同时出现异常也不会影响其他任务运行。
定时运行:
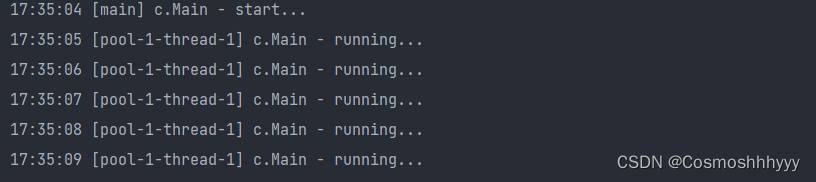
@Slf4j(topic = "c.Main")
public class Main {
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
log.debug("start...");
scheduledExecutorService.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 1, 1, TimeUnit.SECONDS); // 每隔1s反复执行
}
}
处理异常
try catch
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
try {
log.debug("task1");
int i = 1 / 0;
} catch (Exception e) {
log.error("error:", e);
}
});
通过返回值判断
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> f = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0; // 模拟异常
return true;
});
log.debug("result:{}", f.get());
若正常执行返回true,
若出现异常get会返回异常信息。

应用
每周四定时运行
public class Main {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 获得当前时间
LocalDateTime now = LocalDateTime.now();
// 获取本周四 18点时间
LocalDateTime startTime =
now.with(DayOfWeek.THURSDAY).withHour(18).withMinute(0).withSecond(0).withNano(0);
// 如果当前时间已经超过 本周四 那么找下周四
if(now.compareTo(startTime) >= 0) {
startTime = startTime.plusWeeks(1);
}
// 计算时间差,延时执行时间
long initialDelay = Duration.between(now, startTime).toMillis();
// 执行间隔 1周
long period = 1000 * 60 * 60 * 24 * 7;
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
executor.scheduleAtFixedRate(() -> {
System.out.println("running..");
}, initialDelay, period, TimeUnit.MILLISECONDS);
}
}
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











