







目录
一、前言
在之前我们已经对有关数据的缺失值的剔除与插补和异常值的发现做出相应的介绍,那么接下来就是要对可视化的基础能力加强,能欧对连续变量和分类变量的数据进行有效的可视化,方便数据分析与数据挖掘,到最后我们会根据其他类型数据的可视化加以补充,希望这个小系列能够对你带来帮助,让你能够对数据分析有所了解,对数据分析的方法有一定的基础掌握,为后序的机器学习模型提供一个好的开端。
二、介绍
有这么一个事实:人类更加善于在图中发现规律,在单纯的文本与数据本身,少量的规模或许轻而易举,但是只要规模大,那我们的分析过程就会十分漫长,得出趋势结论会有所遗漏,这时候对数据进行描述的图的存在意义非凡,不容忽视。
Ⅰ.连续变量间关系的可视化分析
①两个连续变量间关系的可视化
方法一:散点图
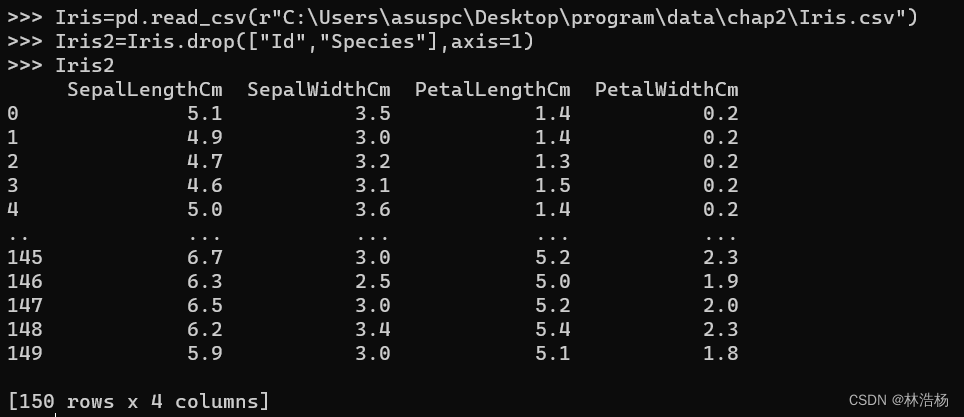
Iris=pd.read_csv(r"C:\Users\asuspc\Desktop\program\data\chap2\Iris.csv")
Iris2=Iris.drop(["Id","Species"],axis=1)那么在开始之前,我们先获取到要进行可视化的数据,方法之前讲过,这里我们就不再过多赘述,同样是把两个非连续变量进行一个drop处理。
那么对于两个连续变量之间的可视化方式,最直观的方法就是我们一直提及的散点图:
plt.figure(figsize=(10,6))
plt.scatter(x=Iris2.SepalLengthCm,y=Iris2.SepalWidthCm,color='blue')
plt.grid()
plt.xlabel('SepalLengthCm')
plt.ylabel('SepalWidthCm')
plt.title('Scatter')
plt.show()老规矩还是先设置图像窗口,然后再画图,把我们要刻画的两个连续变量分别写到x和y当中,接着为了让这张图让其他人好理解我们可以加上X轴Y轴的变量代表名称,还有标题的添加。
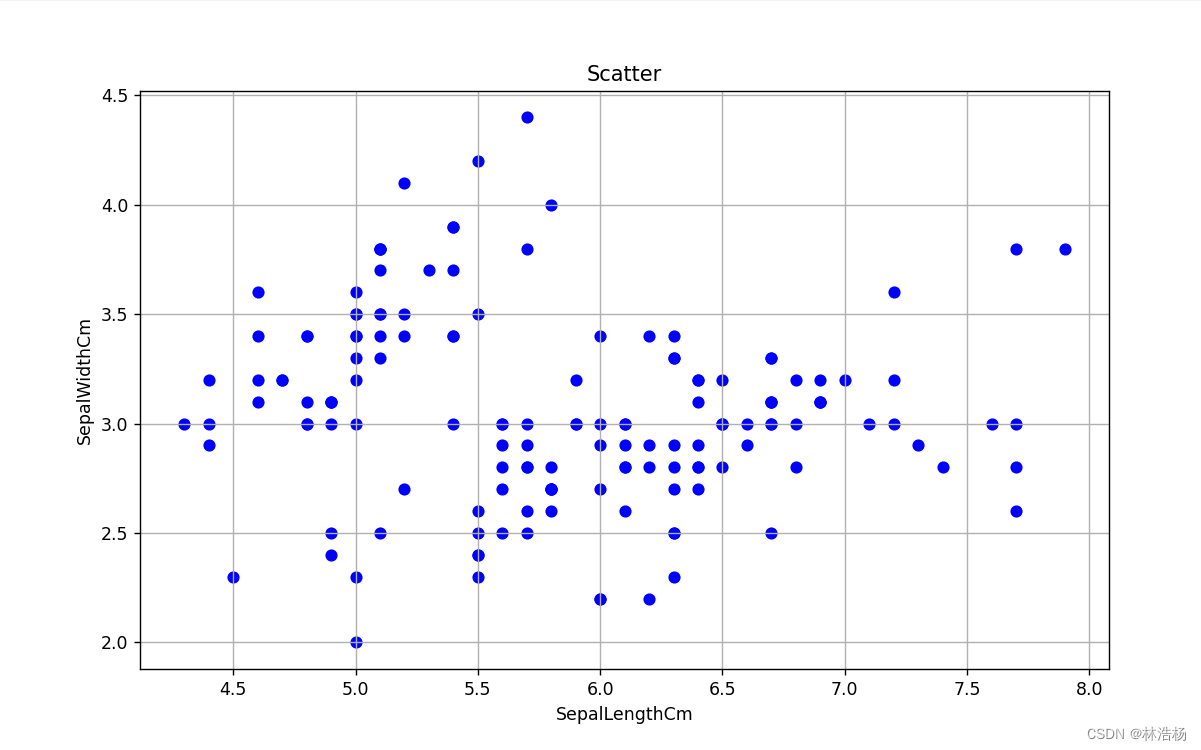
那么两个连续变量的散点图的可视化就刻画出来了,这样我们就能从中分析出两个变量之间的变化趋势。
方法二:2D密度曲线图
那如果想要分析这两个变量在空间中的分布情况呢?这个貌似有点意思。
那么这里要介绍的就是2D密度曲线图,它会将分布密集的区域用较深的颜色进行填充表示:
sns.jointplot(x=Iris2.SepalLengthCm,y=Iris2.Sep 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









