







一、HTTP协议简介
HTTP协议是超文本传输协议的简称,是应用层协议的一种,在web应用中主要用于应用程序和浏览器之间的交互。定义他们之间的通讯过程和规范。客户通过浏览器向服务器请求相关的资源,需要按照特定的格式,这个格式必须遵循HTTP协议的规范。
二、一个HTTP请求的内容
通过浏览器向服务器的请求就是一个HTTP请求,通常一个HTTP请求包括如下三个部分。
一个请求行
- 若干请求头
- 请求体
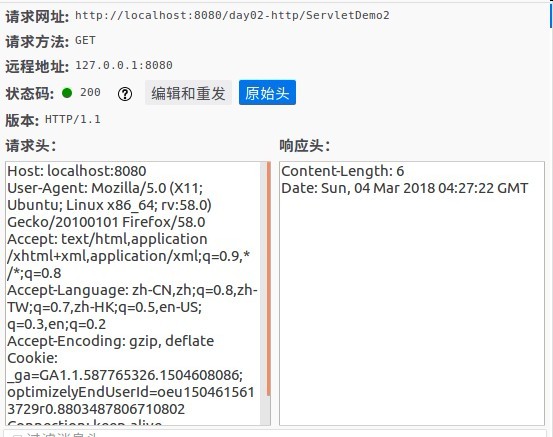
请求行的细节
请求方式:POST、GET、HEAD、OPTIONS、DELETE、TRACE、PUT常用的方式是GET、POST
在浏览器的行为中,其默认的提交方式都是GET提交,如果想要使用POST提交,只能是通过更改表单的提交方式,或者自行设置提交方式。
两种方式请求参数的区别
GET方式其请求的参数是是追加的方式附在网址的后面,如果有多个参数则以&分开,由于数据是附在浏览器网址上的,安全性不能保证,并且整个数据的长度是有限制的,最大是1K。比如:http://localhost:8080/day02-http/ServletDemo2?name=buer&logo=gou
POST方式在向服务器请求的过程中,请求参数是放在请求体中,所以安全性较高,并且可传输的数据是不限制的!
请求头的细节
此处列出一些常见的请求头
- Accept:用于告诉服务器,客户机支持的数据类型。
- Accept-Charset:用于告诉服务器,客户机支持的编码。
- Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式。
- Accept-Language:客户机的语言环境。
- Host:客户机通过这个头告诉服务器,想访问的主机名。
- If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间。
- Referer:客户机通过这个头告诉服务器,它是从哪个资源来访问服务器的(用于防盗链上)。
- User-Agent:客户机通过这个头告诉服务器,客户机的软件环境。
- Cookie:客户机通过这个头可以向服务器带些数据。
- Connection:客户机通过这个头告诉服务器,请求完了之后是保持连接(Keep-Alive)还是断开连接(close)。
- Date:当前请求时间值。
Accept text/html,application/xhtml+xm…plication/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Connection keep-alive
Cookie _ga=GA1.1.587765326.1504608086…4615613729r0.8803487806710802
Host localhost:8080
Upgrade-Insecure-Requests 1
User-Agent Mozilla/5.0 (X11; Ubuntu; Linu…) Gecko/20100101 Firefox/58.0三、HTTP响应的内容
HTTP响应代表了服务对我们请求的回答。一个响应通常包含如下几个内容:
- 一个状态行
- 一个响应头
- 实体内容
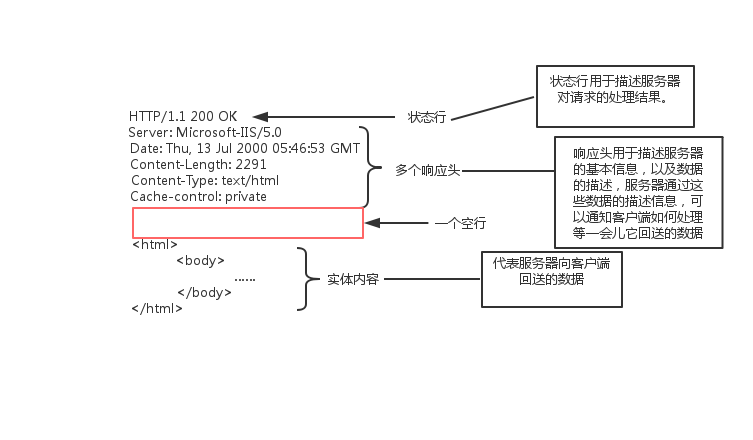
通过这个响应,我们可以知道请求是否成功,通过它的数据类型信息我们可以知道如何处理返回的数据。
响应细节--状态行
状态行的格式:
HTTP版本号 状态码 原因叙述<CRLF>。例:
HTTP/1.1 200 OK
状态码用于表示服务器对请求的处理结果,是一个三位的十进制数,分为5类。
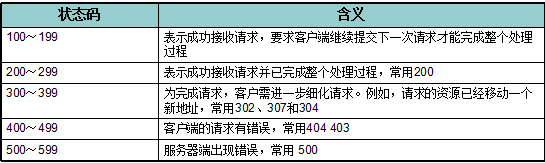
几个常见的状态码的说明
- 302 你找我,我无法帮你解决,一会给你一个location,你根据这个location指定的地址来找那个人。
- 307/304 你找我,但是之前已经询问我同样的事儿了,你去浏览器的缓存里面看看吧
- 404 你找我,但是我这没有你要的东西,是不是你要的东西错了,地址写错了?
- 403 你开始访问服务器某个资源,传入用户名和密码,结果用户名没有权限,服务器有这个资源,但拒绝给你这个资源
响应细节-常见的响应头
- location:这个头配合302状态码使用,用于告诉客户找谁。
- Server:服务器通过这个头,告诉浏览器服务器的类型。
- Content-Encoding:服务器通过这个头,告诉浏览器数据的压缩格式。
- Content-Length:服务器通过这个头,告诉浏览器回送数据的长度。
- Content-Language:服务器通过这个头,回送数据(即浏览器)的语言环境。
- Content-Type:服务器通过这个头,告诉浏览器回送数据的类型。
- Last-Modified:服务器通过这个头,告诉浏览器当前资源的缓存时间。
- Refresh:服务器通过这个头,告诉浏览器隔多长时间刷新一次。
- Content-Disposition:服务器通过这个头,告诉浏览器以下载方式打开数据。
- Transfer-Encoding:服务器通过这个头,告诉浏览器数据的传送格式。
- Set-Cookie:和Cookie相关的。以后会详讲。
- ETag:缓存相关的头。
用ETag可以做到实时更新,其他头只能控制到秒一级的更新,无法做到实时性很高的系统。
- Expires:服务器通过这个头,告诉浏览器把回送的资源缓存多长时间,-1或0,则不缓存。
- Cache-Control: no-cache
- Pragma: no-cache
服务器通过以上两个头,也是控制浏览器不要缓存数据。(实时性要求很高的数据不能缓存,如股票数据,对于一般的数据,都可缓存。)
如果控制市面上所有的浏览器都不要缓存数据,最好设置Expires、Cache-Control、Pragma这三个响应头。 - Connection:响应完之后,是保持连接,还是断开连接。
- Date:当前响应时间值。
代码练习--通过设置响应头来控制浏览器的行为
设置状态码302配合location一起使用,达到sendRedirect重定向的效果。
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println(request.getContextPath()+"123");
//302状态码配合location一起使用,告诉客户新的请求地址,地址栏会变化,并且和sendRedirect方法一样可以进行跨项目
response.setStatus(302);
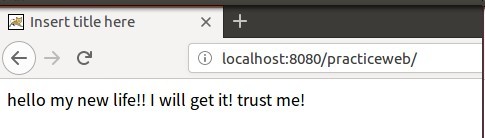
response.setHeader("location", "http://localhost:8080/practiceweb/");
}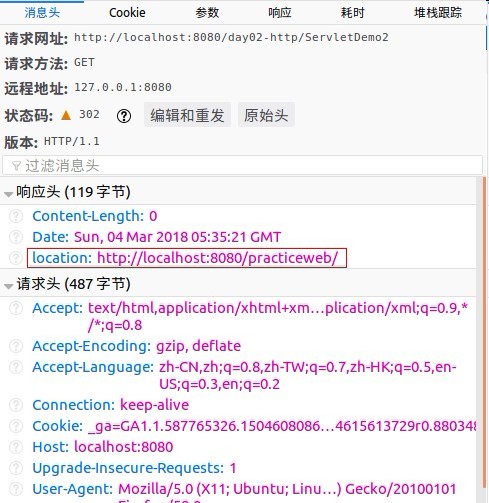
其状态码为302,表示是你要的资源我没有,我知道哪有,通过一个location告诉你去哪可以获取你要的资源。然后浏览器解析这个地址,跳转到location这个地址上面。效果如下:
代码练习-设置Content-Encoding,告诉浏览器的数据格式
压缩数据的好处:数据压缩之后会变下,请求同样的资源,从服务器下载资源,压缩之后的更快,页面展开的也快。有些门户网站,电信收费是按照流量收费的,所以会省很多钱。
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String str = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"+
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"+
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"+
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"+
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa";
System.out.println("原始数据的字节长度:"+str.getBytes().length);
ByteOutputStream bos = new ByteOutputStream();
GZIPOutputStream gs = new GZIPOutputStream(bos);
gs.write(str.getBytes("UTF-8"));
/*
*GZIPOutPutStream:包装流一般都会有一个缓冲,
*如果调用其write()方法在写数据时,如果数据量没有把包装流的缓冲写满,它是不会往底层流写的。需要用close强制刷新
*/
gs.close();
//得到压缩后的数据
System.out.println(bos.size());
//getBytes方法是获取缓冲区的数据,而toByteArray方法则是新分配一个Byte数组,大小是当前大小,流的有效输出。
//等于size方法返回值,也是count值
//byte[] gzip = bos.getBytes();
byte[] gzip = bos.toByteArray();
System.out.println("压缩后的字节长度:"+gzip.length);
/*
* 将压缩数据发送给浏览器
*/
//通知浏览器的压缩格式
response.setHeader("Content-Encoding", "gzip");
//告诉浏览器的压缩数据长度
response.setHeader("Content-Length", gzip.length+"");
response.getOutputStream().write(gzip);
}设置content-type响应头,控制浏览器以哪种方式处理数据
@WebServlet("/ServletDemo1")
public class ServletDemo1 extends HttpServlet {
// 通过Content-Type头字段,控制浏览器以哪种方式处理数据
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-Type", "image/jpeg");
// 读取位于项目根目录下的Krystal.jpg这张图片,返回一个输入流
InputStream in = this.getServletContext().getResourceAsStream("/Krystal.jpg");
int len = 0;
byte[] buffer = new byte[1024];
OutputStream out = response.getOutputStream();
while((len=in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}设置refresh响应头,让浏览器定时刷新
@WebServlet("/ServletDemo1")
public class ServletDemo1 extends HttpServlet {
// 定时刷新
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// response.setHeader("Refresh", "3"); // 浏览器每隔3秒钟请求一次
response.setHeader("Refresh", "3;url='http://www.sina.com'"); // 浏览器隔3秒钟请求一次后,并刷新到新浪上去
String data = "aaaaaaaaaaaaaaaaaaaaaaaa";
response.getOutputStream().write(data.getBytes());
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}设置content-disposition响应头,让浏览器下载文件
@WebServlet("/ServletDemo1")
public class ServletDemo1 extends HttpServlet {
// 下载文件
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-Disposition", "attachment;filename=Krystal.jpg");
InputStream in = this.getServletContext().getResourceAsStream("/Krystal(4).jpg");
int len = 0;
byte[] buffer = new byte[1024];
OutputStream out = response.getOutputStream();
while((len=in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}HTTP的一个实用头字段——Range
HTTP请求头字段
Range头指示服务器只传输一部分web资源。这个头可以用来实现断点续传功能。Range字段可以通过三种格式设置要传输的字节范围:
- Range:bytes=1000-2000
传输范围从1000到2000字节。 - Range:bytes=1000-
传输web资源中第1000个字节以后的所有内容。 - Range:bytes=1000
传输最后1000个字节。
例,web服务器有一个资源,比如是a.txt,内容为:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa- 1
有一个用户下载了一部分数据,并存储到C盘中的a.txt,内容为:
aaaaa- 1
此时该用户想接着下载完剩下的数据,该怎么做呢?此时他就不能通过浏览器去访问了,而应该自己写程序去访问指定的资源。
public class RangeDemo {
public static void main(String[] args) throws Exception {
URL url = new URL("http://localhost:8080/day04/a.txt");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestProperty("Range", "bytes=5-");
InputStream in = conn.getInputStream();
int len = 0;
byte[] buffer = new byte[1024];
FileOutputStream out = new FileOutputStream("c:\\a.txt", true);
while((len=in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
in.close();
out.close();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
运行以上程序,该用户就下载完剩下的数据了。
HTTP响应头字段
Accept-Ranges:这个字段说明web服务器是否支持Range,支持则返回Accept-Ranges: bytes;如果不支持,则返回Accept-Ranges: none。
Content-Range:指定了返回的web资源的字节范围。这个字段值的格式是——例,Content-Range: 1000-3000/5000。
注意:HTTP响应头字段不常用。















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









