







本文章将基于黑马程序员的 "Mysql数据库从入门到精通"教程 的视图部分进行归纳总结,如有侵权请联系删除!!
【MySQL存储引擎与架构探秘】你是否好奇MySQL如何高效管理海量数据?本文深度拆解InnoDB核心架构,揭秘表空间、段、区、页四级联动机制,剖析B+树索引与行存储的精妙设计。通过逻辑存储结构的全景解析,带您看懂数据从SQL语句到磁盘字节的蜕变之旅,为性能优化打下坚实基础!#数据库内核 #MySQL架构 #存储原理
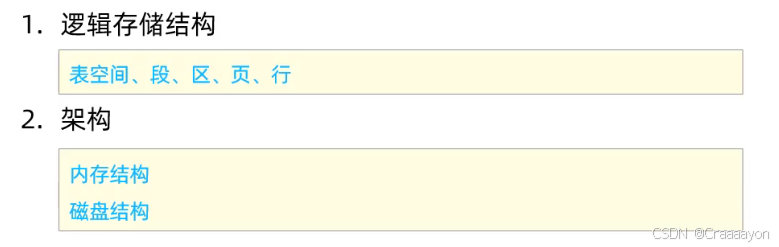
(一)逻辑存储结构

(1)五个方面存储结构的特点
- 表空间:对于InnoDB存储引擎来说,表内部的数据与索引实际上都是存放在表空间当中的,这是最外层的逻辑结构。
- 区:InnoDB存储引擎每次申请磁盘空间时都是以区为单位来申请的,且为了保证页的连续性每次都会申请4~5个区。
- 页:表结构当中所存储的记录以及索引都是在页这个逻辑结构当中进行存储的。
- 行:Trx_id指的是最后一次事务操作的id,与Roll_pointer一同作为表结构当中的隐藏字段,而Roll_pointer则类似一个指针,通过该指针可以去找到进行增删改操作时,执行操作之前的数据是什么样的。在后面讲解MCVV多版本并发控制时会详细地讲解这两个字段及它的作用。
(2)查看数据库实例的表空间文件
- 打开安装在Linux系统下的Mysql数据库的系统文件
在这个目录下存放的就是mysql的数据文件
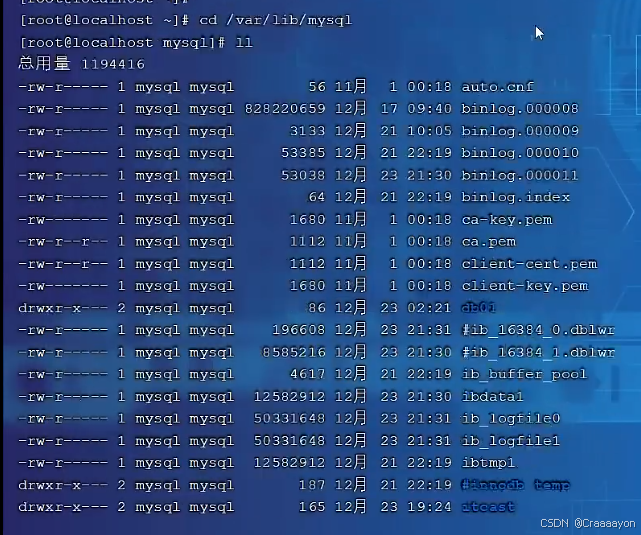
//进入mysql数据库的系统文件
cd /var/lib/mysql
//查看全部文件
ll
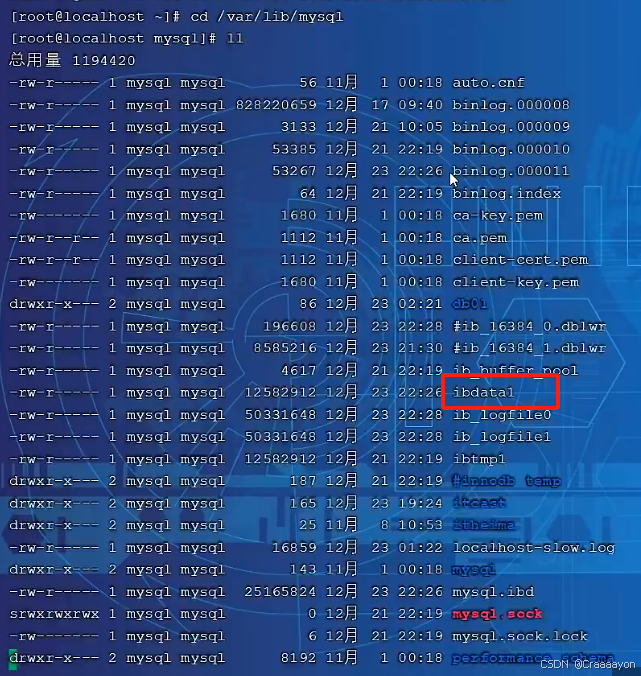
- 可以看到一个mysql.ibd,这就是mysql实例的表空间文件
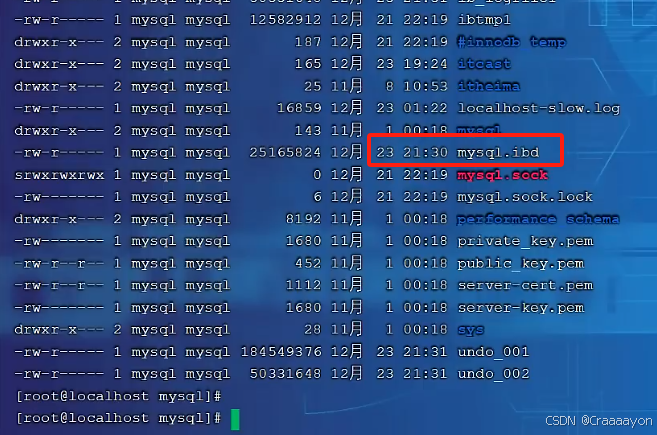
- 同样可以切换到其他数据库的目录下再查询其他表的表空间文件
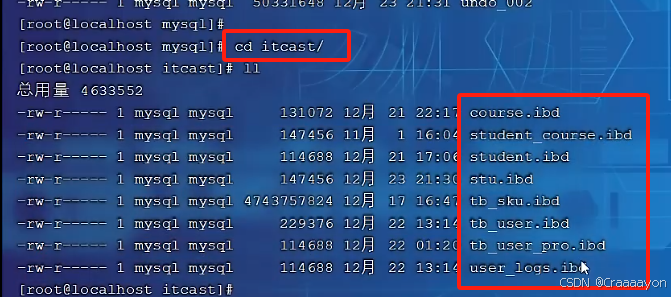
//切换到其他数据库
cd xxx/
//查看该数据库下的全部表空间文件
ll
(二)架构
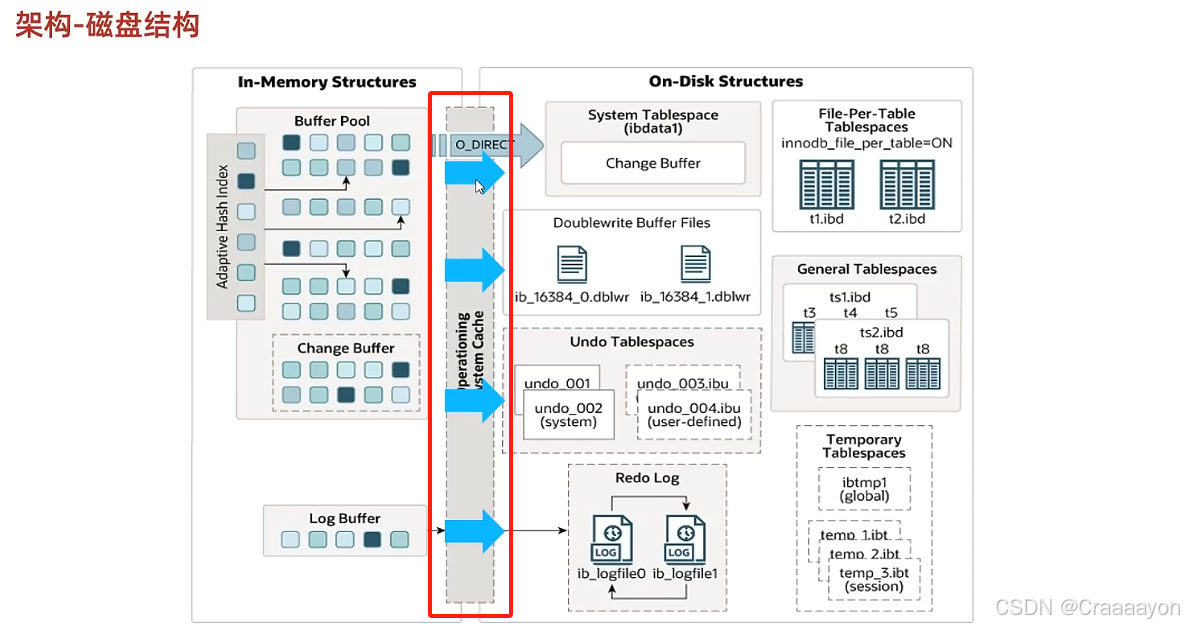
一、架构介绍
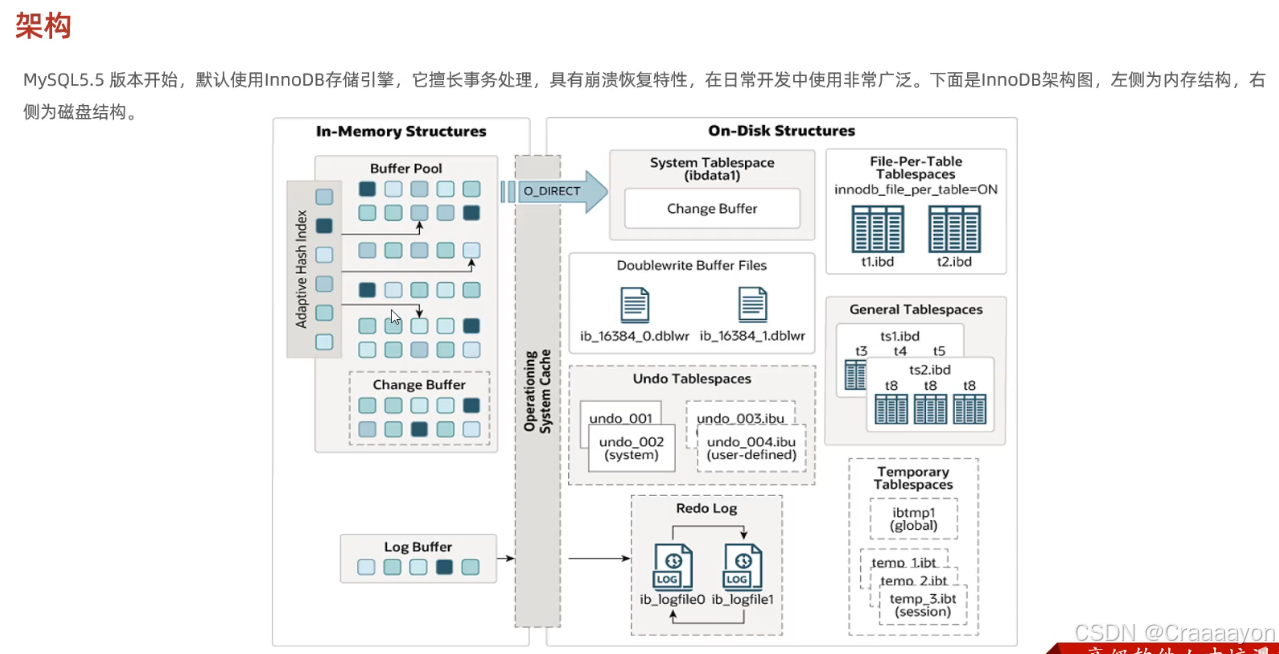
左侧的In-emory Structures指的是内存结构,右侧On-Disk Structures指的是磁盘结构。
- 内存结构
在内存结构中标注了四块区域:Buffer Pool缓冲池、Change Buffer更改缓冲区、Log Buffer日志缓冲区、以及Adaptive Hash Index自适应哈希索引。 - 磁盘结构
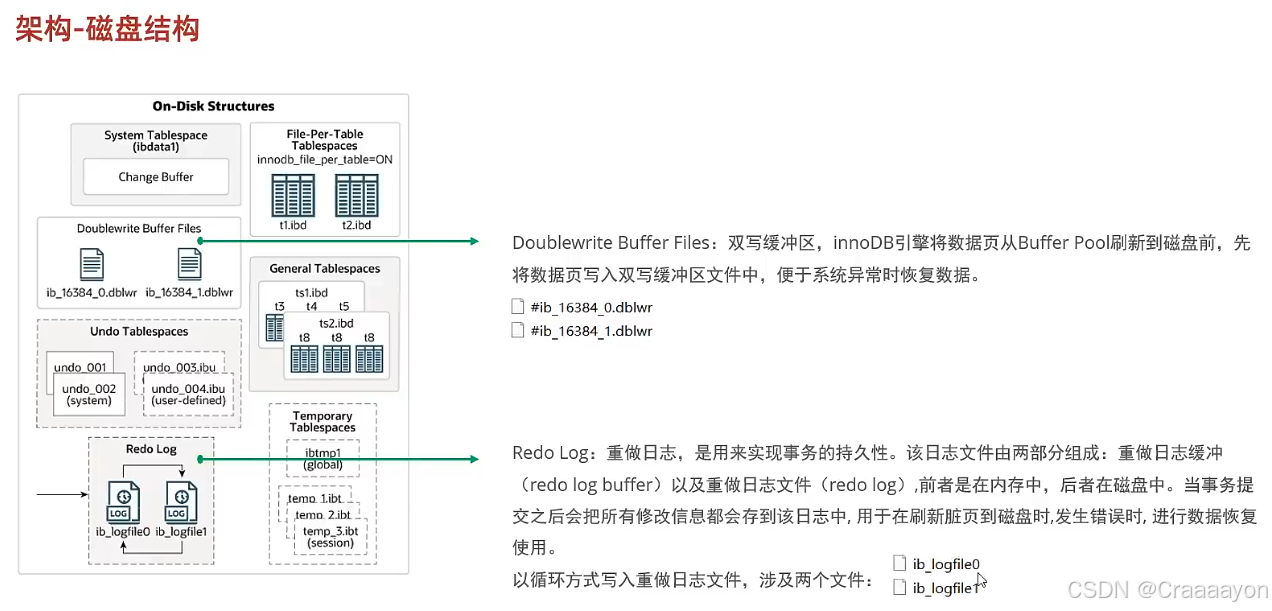
右侧磁盘结构中存在许多表空间,DoubleWrite Buffer Files指的是双写缓冲区。因为整个架构相当复杂,所以我们在讲解InnoDB架构时会分为两个方面:第一个先介绍内存结构,第二个方面再来介绍磁盘结构。
二、内存结构
(1)Buffer Pool缓冲池

- 缓冲区的作用
假如没有缓冲区,那么意味着当我们执行增删改查操作时,每一次数据库都需要去操作磁盘空间,那么就会存在大量的磁盘IO,而且在业务比较复杂的系统中,大量磁盘IO都是随机IO,所以这是非常耗费性能的。有了缓冲区之后就不用每次都去操作磁盘文件,可以先直接操作缓冲区,然后每隔一段时间或者触发某一段机制后,再将缓冲区当中的数据刷到磁盘当中即可。 - 缓冲区中的Page页
在缓冲区当中存在一个一个块,实际上就是一个一个Page页。而Page页又分为三种类型,并且是以不同的颜色来区分不同状态的页。
空闲Page指的是已经申请了空间但是还未进行使用。
(2)Change Buffer更改缓冲区
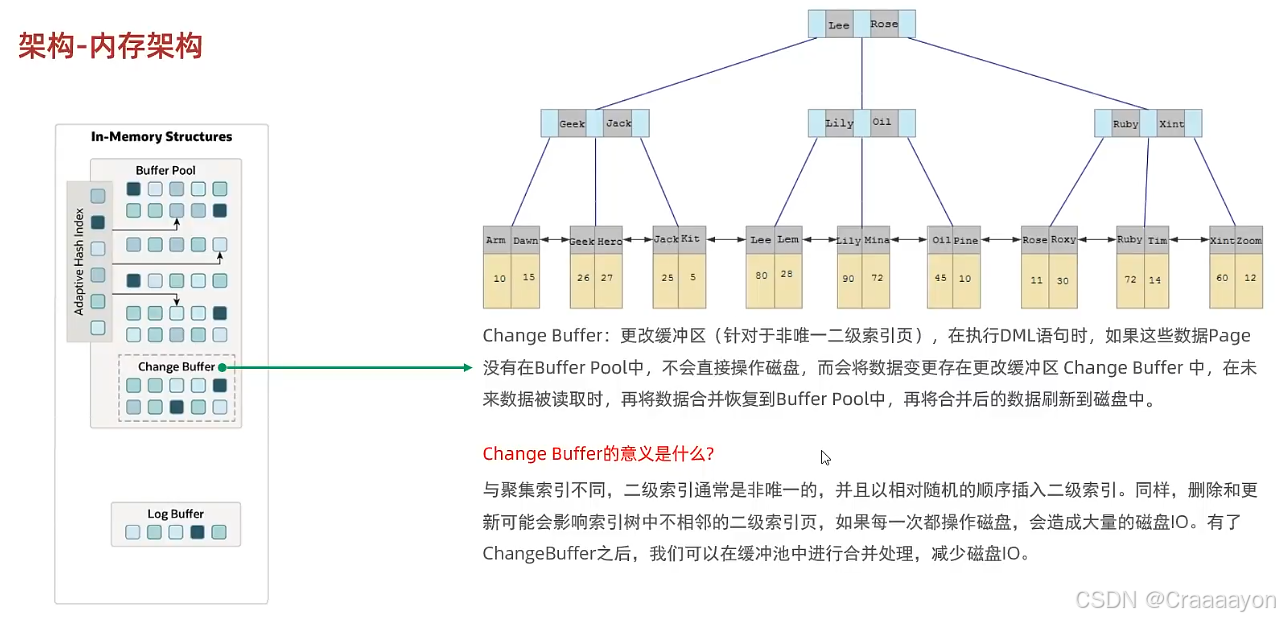
这个更改缓冲区实际上在5.几版本时是还不存在的,当时仅有插入缓冲区Insert Buffer。在8.0版本以后才引入了该Change Buffer更改缓冲区。
该更改缓冲区是针对于非唯一的二级索引页的,也就是对于唯一索引或主键索引是不会操作更改缓冲区的。而对于聚集索引与主键索引来说,我们通常都是按照主键顺序去顺序插入数据,也就会顺序地去进行磁盘IO。
①Change Buffer存在的意义:
拥有了Change Buffer后我们不用每一次都去操作磁盘IO,而是可以先去操作Change Buffer,然后再以一定频率把Change Buffer当中的数据同步到Buffer Poll,最后再刷新到磁盘当中,这样子就减少了磁盘IO,提高效率
(3)Adaptive Hash index自适应哈希索引

InnoDB引擎默认并不支持哈希索引,而是支持B+Tree索引,但是同时也在这一块提供了一种功能为自适应hash。前面提到过哈希索引最大的优势是快,因为它只需要匹配一次(前提是不存在哈希冲突);而对于B+Tree来说往往可能需要匹配两三次。虽然哈希索引的优势是查询速度快,但是弊端是不适合范围查询,只能进行等值匹配这类操作。所以在InnoDB引擎中就提供了自适应哈希,用于优化Buffer Pool当中的数据查询。
①查看自适应哈希索引的开关是否打开

//查看自适应哈希索引的开关
show variables like '%hash_index%';
或 show variables like 'innodb_adaptive_hash_index';
- 此处为参数名的前后都加上%,进行模糊匹配,就不需要把参数名称写全。
- 可以看到该开关是默认开启的。
(4)Log Buffer日志缓冲区

也就是说我们在记录日志时为了提高效率,可以先把日志记录在缓冲区当中,然后定期刷新到磁盘内。
①查看缓冲区大小及将日志刷新到缓冲区的时机
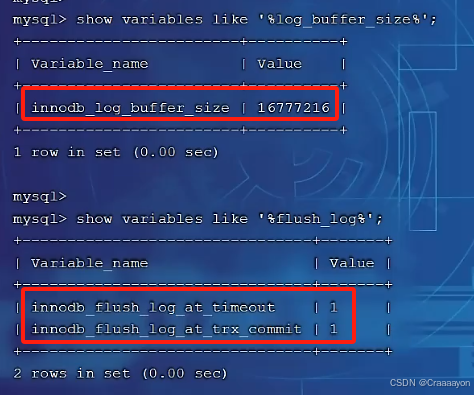
//查看缓冲区大小
show variables like '%log_buffer_size%';
或 show variables like 'innodb_log_buffer_size';
//查看将日志刷新到缓冲区的时机
show variables like '%flush_log%';
或 show variables like 'innodb_flush_log_at_timeout';
- 可以看到缓冲区默认大小为16K。
- 默认时机为1代表日志在每次事务提交时写入并刷新到磁盘,还会存在其他可选值。
* 对于mysql服务器来说,假如我们的mysql是部署在一台专门的服务器上的,那么这台服务器通常会分配80%的内存到它的缓冲区,以此来提高mysql的执行效率
三、磁盘结构
(1)System Tablespace系统表空间
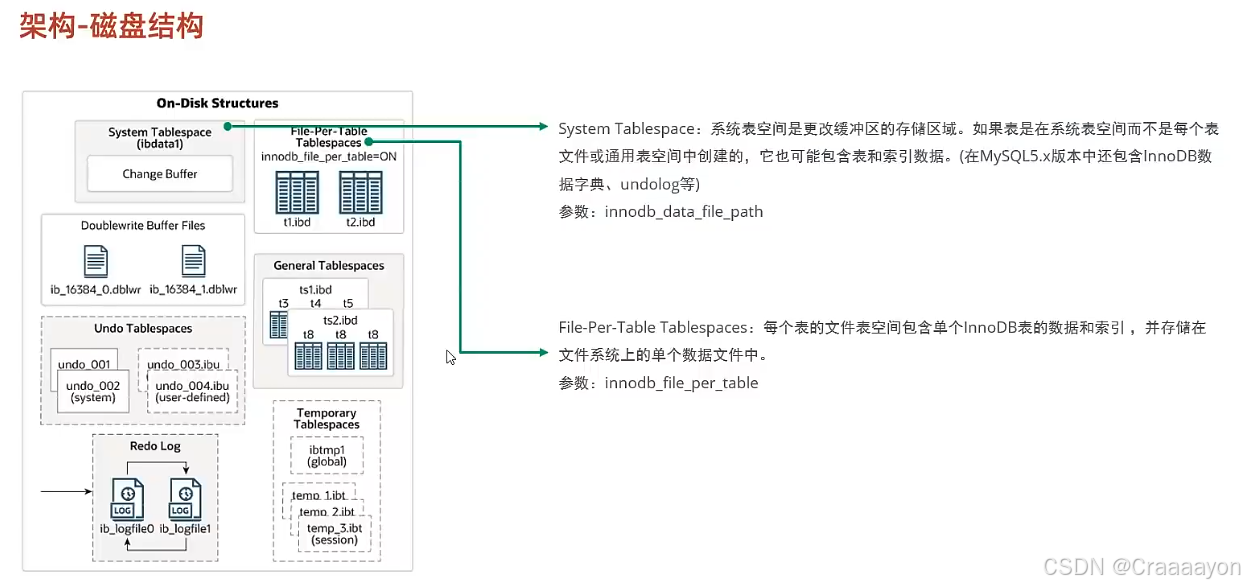
- 系统表空间就是Change Buffer更改缓冲区的存放区域,它是在8.0版本以后又重新规划的,在5.x版本中还会存放InnoDB的数据字典、Undo Log日志等信息。
- 如果在InnoDB引擎当中我们的每一张表的独立表空间都关闭的话,那么所有表的数据以及索引都会存储在系统表空间当中。
- innodb_data_file_path参数指的是表空间文件所处地址。
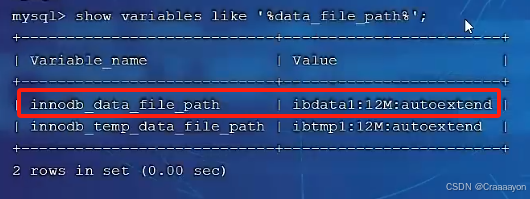
show variables like '%data_file_path%';
或 show variables like 'innodb_data_file_path';
这个ibdata1文件存放的就是系统表空间文件。
4. 进入mysql的系统文件夹,就能找到系统表空间文件
(2)File-Per-Table Tablespaces
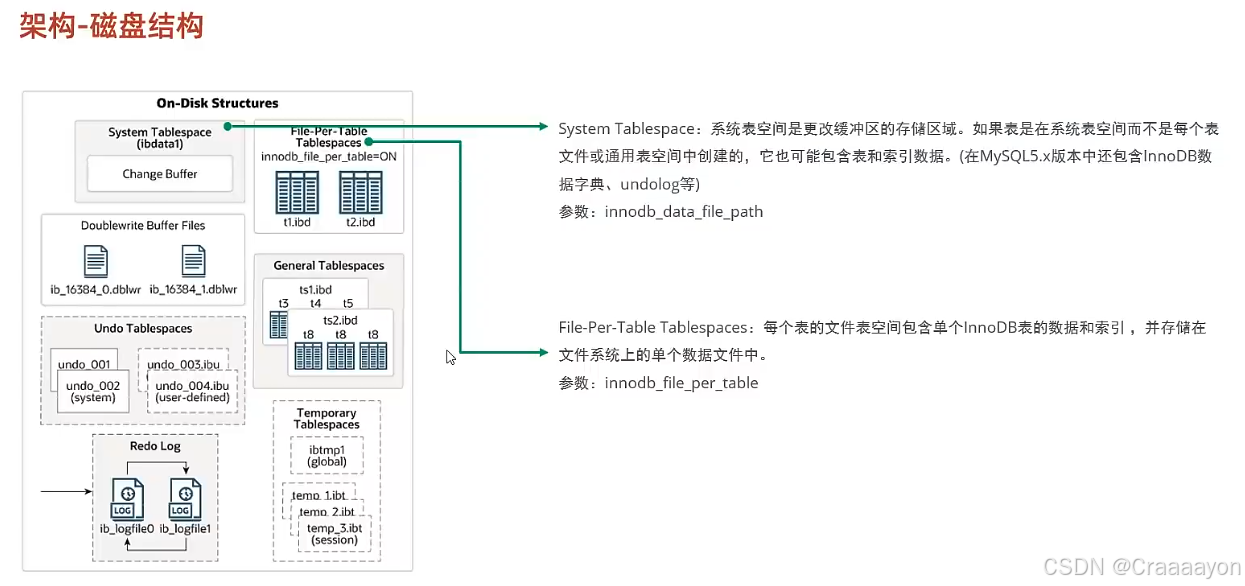
- File-Per-Table Tablespaces区域用于存储每张表独立的表空间,对于InnoDB引擎来说当前都是默认开启该开关的,也就意味着我们建立的每一张表,都会有一个独立的表空间,并不会在System Tablespace当中存放。
- Iinnodb_file_per_table参数
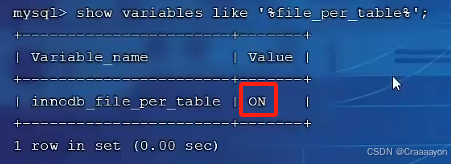
show variables like '%file_per_table%';
或 show variables like 'innodb_file_per_table';
因为开启了该开关,所以在我们使用的数据库中就会有很多的表空间文件。
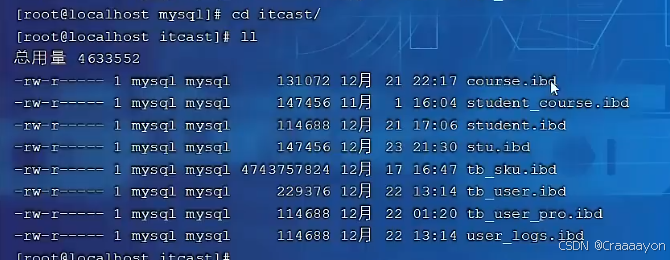
在这个表空间文件当中存放的就是这张表的表结构、数据、索引。
(3)GeneralTablespaces通用表空间
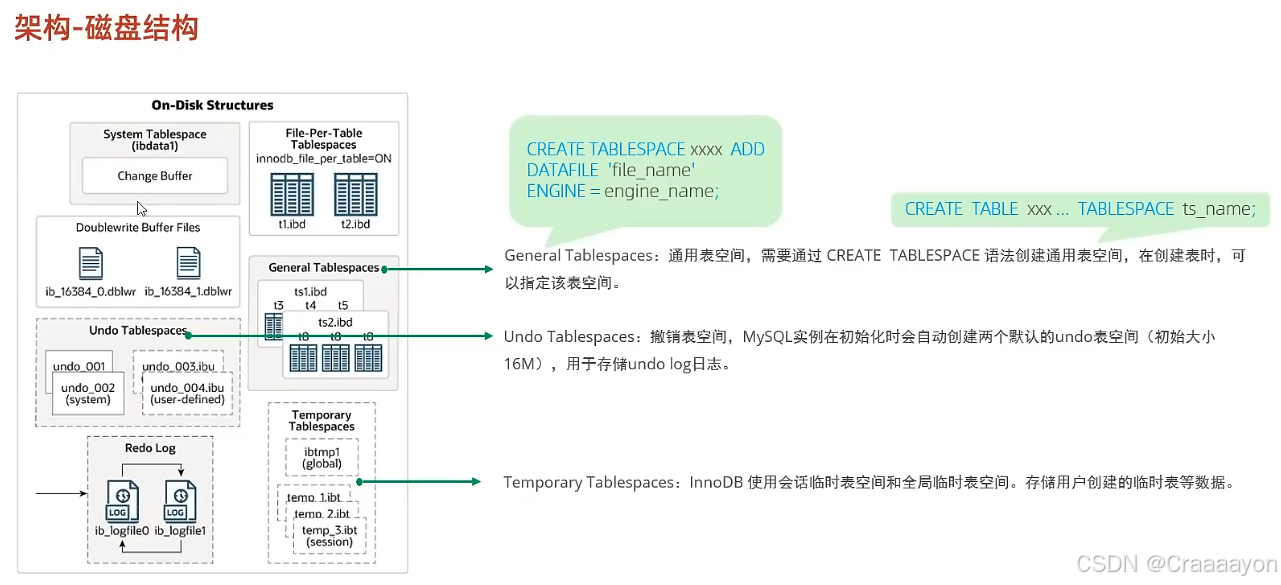
- 创建通用表空间语句
ADD DATAFILE用于指定我们表空间关联的表空间文件。
后续在创建表时就可以去指定该表的数据存放在那个表空间里面,也就是使用TABLESPACE参数,并指定表空间的名字即可。
也就是说通用表空间需要我们自己去创建,并且需要去指定关联的表空间是谁。 - 示例
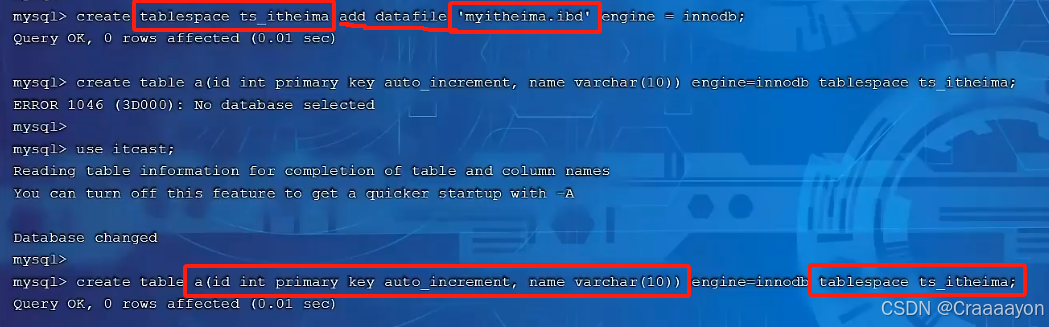
//创建通用表空间
create tablespaces xxx add datafile 'xxx.ibd' engine = innodb;
//创建表并指定表空间
create table x() engine = innodb tablespace xxx;
回到mysql系统文件夹,就能找到我们所创建出来的通用表空间里面存放的就是这张 a 表。

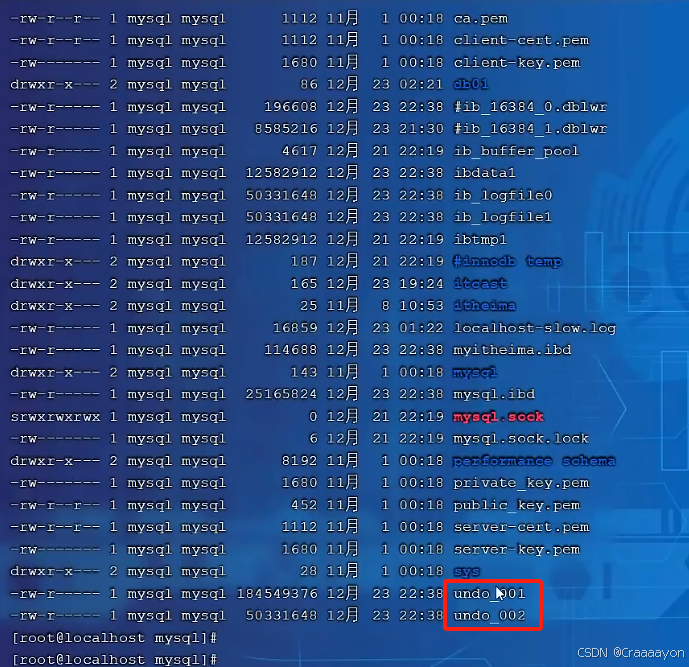
(4)Undo Tablespaces撤销表空间
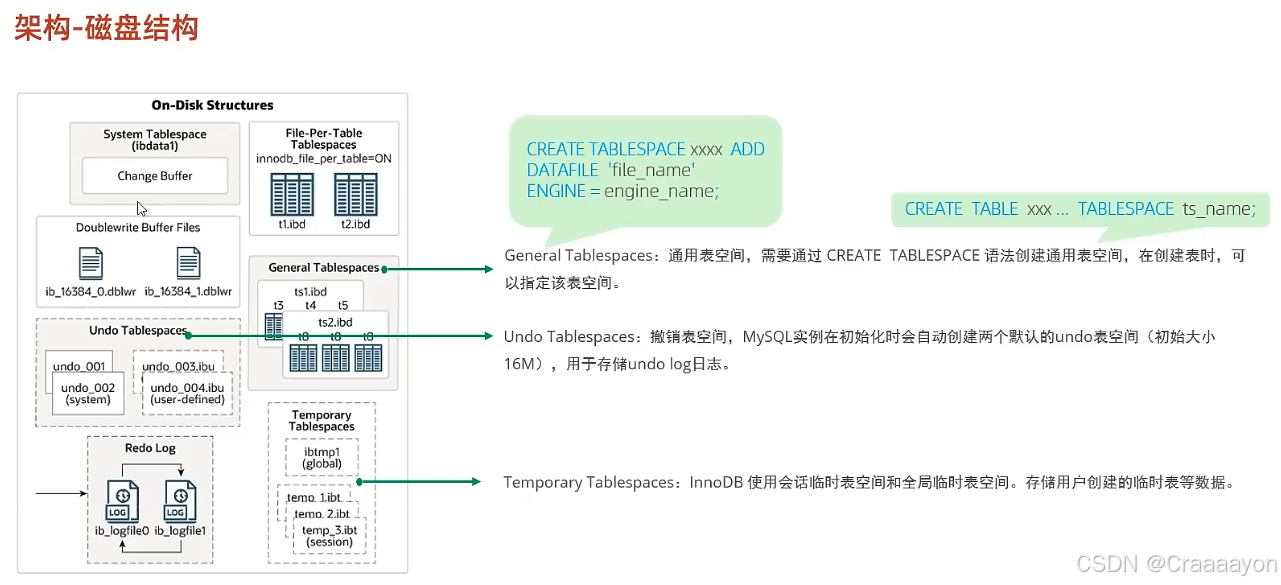
两个默认的undo表空间分别为undo_001与undo_002。
在系统文件中就能找到这两个默认的undo表空间:
(5)Temporary Tablespaces临时表空间
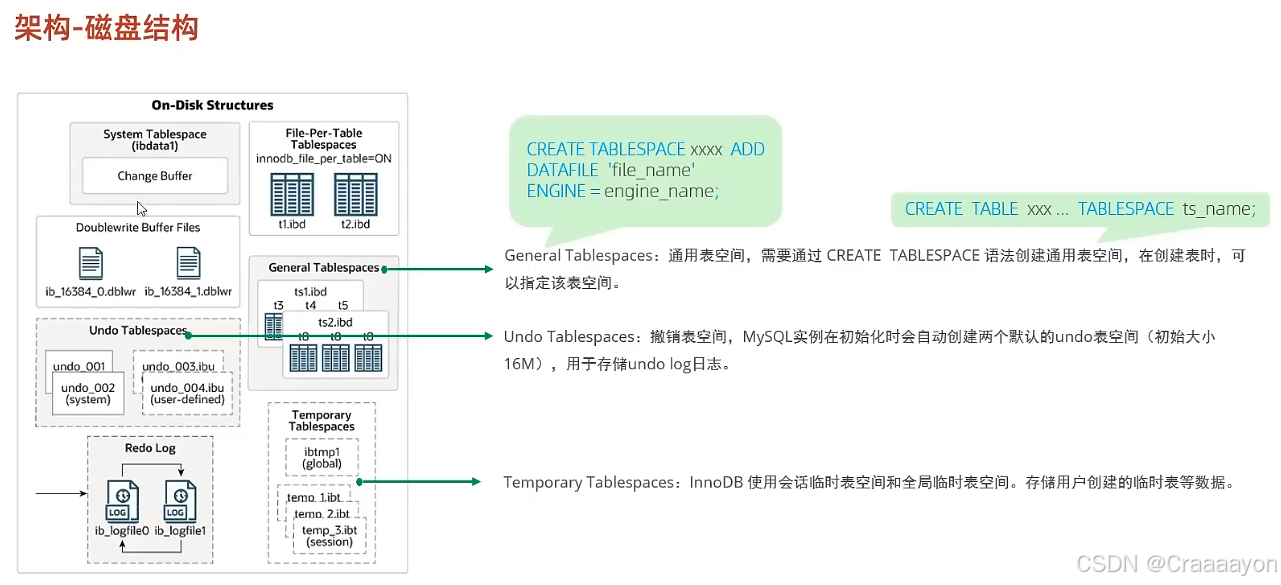
(6)Doublewrite Buffer Files双写缓冲区
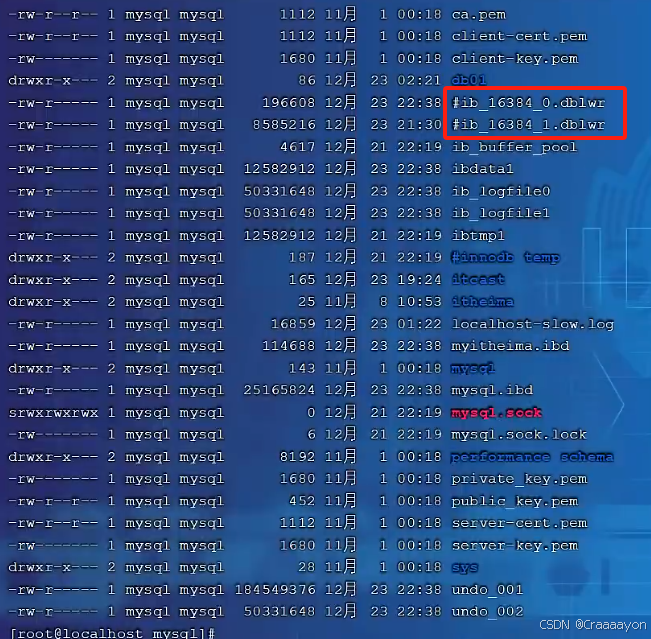
在系统文件中就能找到这两个默认的双写缓冲区文件:
(7)Redo Log重做日志
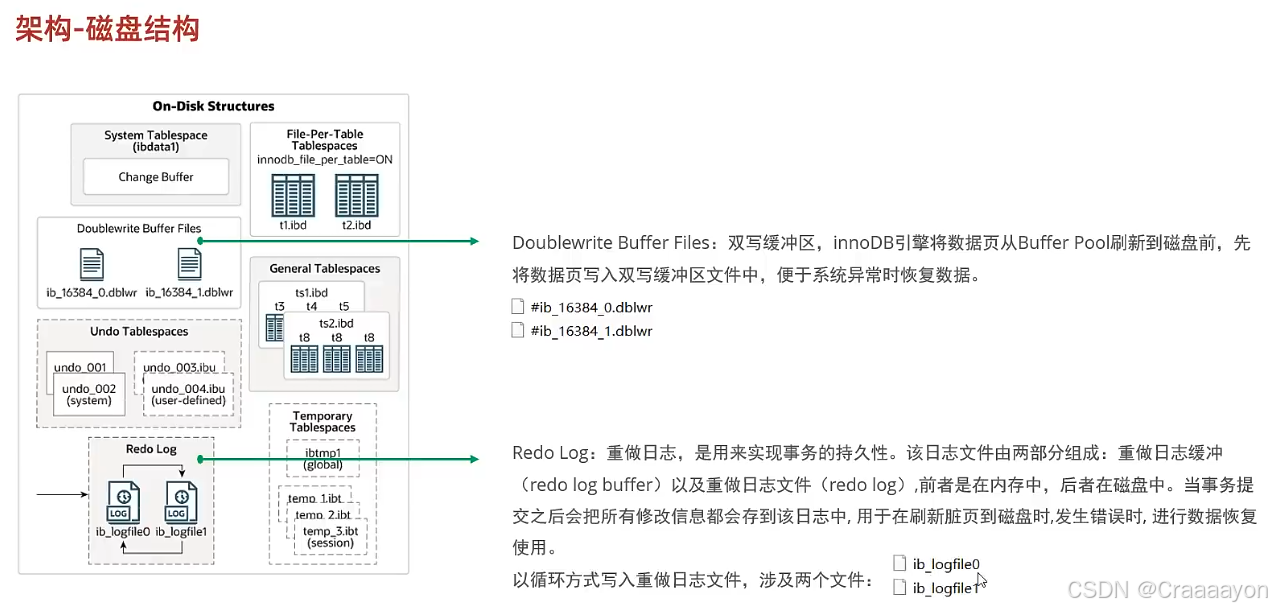
Redo Log是循环写的,不会永久保存,会每隔一段时间去清理之前没有用的Redo Log。而当事务提交后它存在的意义就不大了,因为它的主要作用是保证异常时进行数据恢复,从而保证事务的持久性。
在系统文件中就能找到这两个默认的重做日志文件:
四、后台线程
(1)后台线程的作用
- 内存结构当中的数据是使用一组后台线程来将数据刷新到磁盘当中的。
- 将InnoDB存储引擎的缓冲池当中的数据在合适的时机刷新到磁盘文件当中。
(2)后台线程的四种主要种类

②IO Thread
- AIO指的是异步非阻塞IO。
- 可以以下指令来查看InnoDB引擎的状态,在这个状态当中就能看到对应IO Thread的相关信息

show engine innodb status;
从这里开始往下包含了很多InnoDB的状态信息
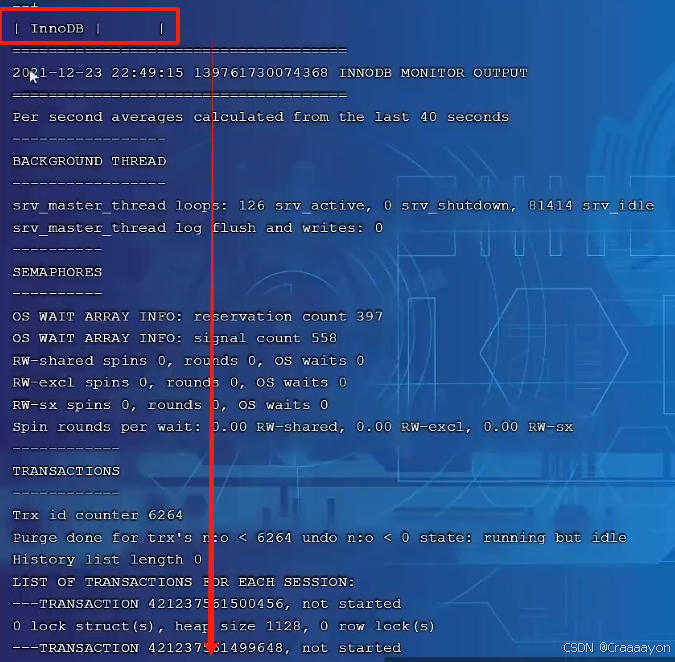
而我们需要关注的是这一块的IO信息
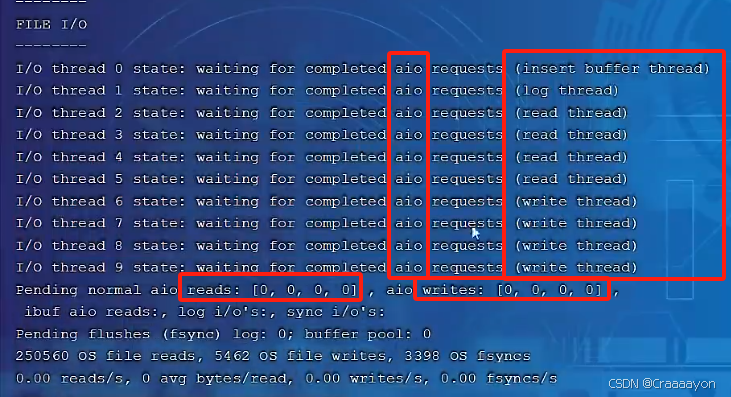
可以看到有1个insert buffer thread线程,1个log thread线程,4个read thread线程与4个write thread线程。采用的也全部都是AIO异步IO。
此时还可以看到所有read与write线程都在等待接收请求的状态。
五、架构总结

对于InnoDB引擎的整个体系结构的运行逻辑就是:当我们业务在操作时,会直接去操作In-Memory Structures中的缓冲区,若缓冲区当中没有数据就会将磁盘当中的数据加载回来,然后再存储在缓冲区当中,我们在增删改查时也是去操作这一块的缓冲区。缓冲区当中的数据也会以一定频率或时机,通过这组后台线程刷新到磁盘当中,并在磁盘当中进行永久化的保留下来。此处的永久化保留主要指的是表当中的数据、索引等相关信息。对于Redo Log与Undo Log并不是把所有的东西都保留下来,而是需要去回收及释放对应的磁盘空间(后续还会进行详细讲解)。


















 4352
4352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











