









总结最近面试的 SRE、DevOps 真题,从经验方案、云原生、稳定性、可观测性、DevOps、K8s基础知识 几方面提问,然后我通过 ChatGPT 回答,不得不说,ChatGPT 回答的真好,内容较长,建议先收藏,回头需要面试时,再品一品~
经验方案
-
微服务应用迁移到 Kubernetes ,流量如何接入切换?

-
微服务架构迁移 Kubernetes, 主要做了哪些工作, 中间有遇到什么难点?


-
为什么要迁移 Kubernetes ?


-
如果让你迁移百度的现有应用到K8S上面, 需要做哪些工作?


-
如果让你改进你们公司现有的监控系统,你会从哪些方向改进优化?


-
聊聊了成本优化的问题


-
Kubernetes 运维中经常遇到的问题是什么,讲讲实际案例?


-
聊了聊现有公司的业务, Kubernetes 的架构,云架构

-
给客户的一批机器过保了,作为运维应该怎么处理?


稳定性
- 系统架构高可用,应该怎么实现?


- 容量规划怎么做的?(基于AWS 的auto scaling group机制的讨论)

- 让你做多活架构设计的话, 几个机房合适?

- 如何实现服务稳定性的保障?


- 让你针对百度或者抖音等APP做性能测试报告,你会怎么出 ?


- 对SRE的理解 , SRE最重要的需要什么能力 ?

- SRE 的关注点?

- SLA SLO SLI 该怎么做?


- On-Call 的流程? incident management 流程的讨论


- K8S 架构, 多少节点 ? 怎么管理的?

- 论到多集群,Centralized cluster 怎么和其他 cluster交互 ?

- 上云 网络架构的讨论 (VPC Peering)

可观测性
-
监控这块怎么做的 ?

-
混沌工程 如何做的故障注入 ?

-
怎么推动该混沌工程的落地实施?

-
从传统监控迁移到Prometheus&thanos架构? 有什么优势?

-
你们公司的系统监控metric的量级在多少 ? 都监控了哪些指标 ?
-
ES 日志量多少 ? ES 架构 ?
-
搭建的可观测性平台, 怎么对业务做到可观测性的提高?


-
做SLO 的指标标准是怎么来的, 比如某个SLI 达到多少是异常 , 大于500ms是异常,这个是怎么评估的 ?


-
传统监控和 可观测性有什么区别? 为什么要做可观测性?

-
Prometheus 指标类型

-
直方图 ,summary 有什么区别 ?(回答不太好,本质是 summary在客户端计算, histogram在服务端计算)

-
rate 和 irate 有什么区别?
(举个例子:最后两个采集点没有数据的话,rate 和 irate 分别的值怎么算的)

-
Prometheus 写过exporter? 具体细节?
-
Prometheus怎么自动发现mertic的 ?

-
Prometheus性能调优?


-
tracing 怎么做的 ?(从opentelemetry&zipkin 到tempo再到cilium网络插件)


-
ebpf的probe有哪些?

-
tracepoint了解吗,怎么用 ?
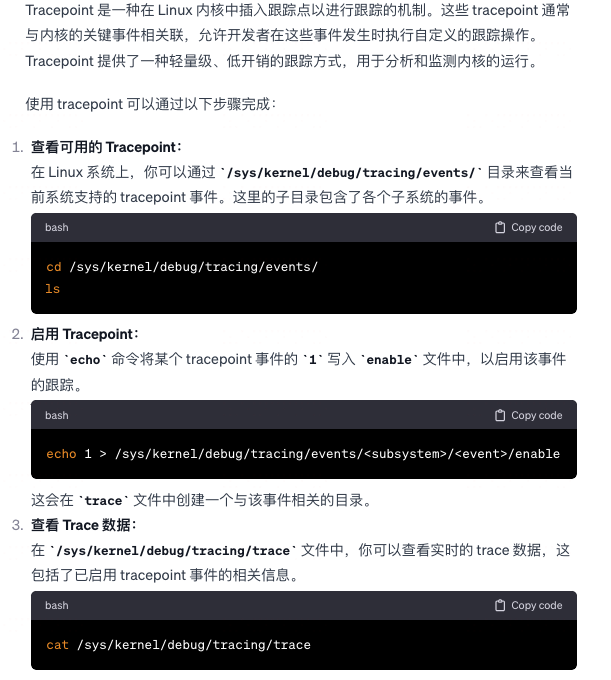

-
ebpf是怎么监控性能的?

DevOps
-
自动化做了哪些工作? 有涉及到 故障自愈 ,智能运维的级别吗 ?

-
terraform Dynamic block 怎么用


-
Count 语法、 for_each 语法 ?

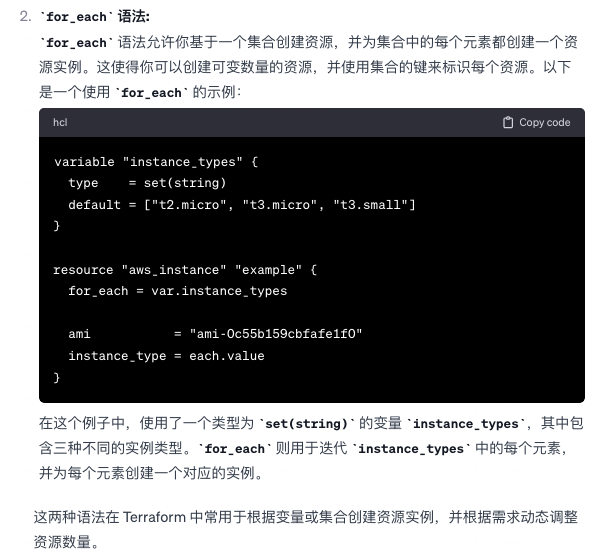
-
terraform 文件结构 (best pratices)
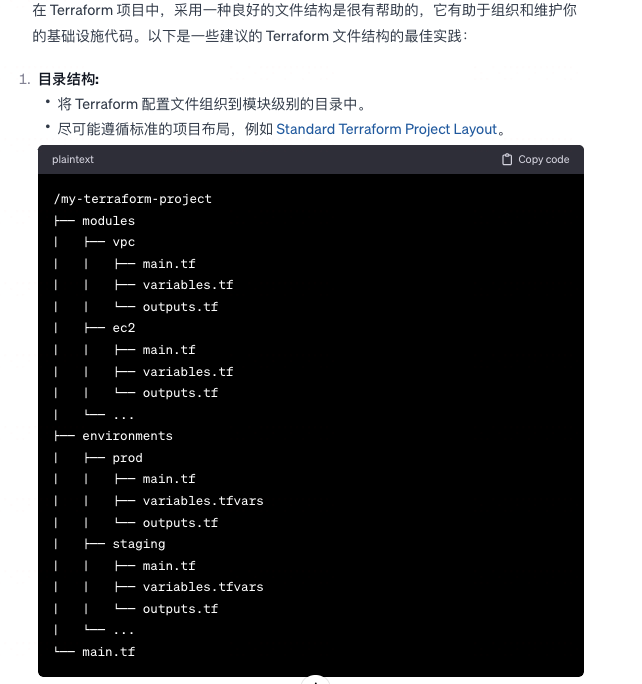

-
Ansible 配置中, 怎么做并发执行同时跑更多任务?
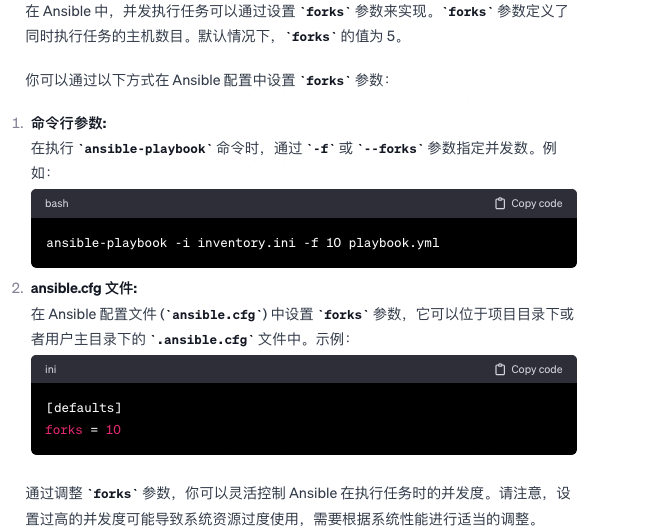
-
你们是怎么做CICD的 , 构建CICD 过程中遇到哪些问题 ?

-
可以再具体深入点, 怎么触发CD机制的?

-
运维自动化你做过哪些,你觉得最有成就的 ?

-
发布版本的策略都有哪些?

-
蓝绿发布解释下 ?

-
详细描述一下之前工作中代码提交的这个过程?


-
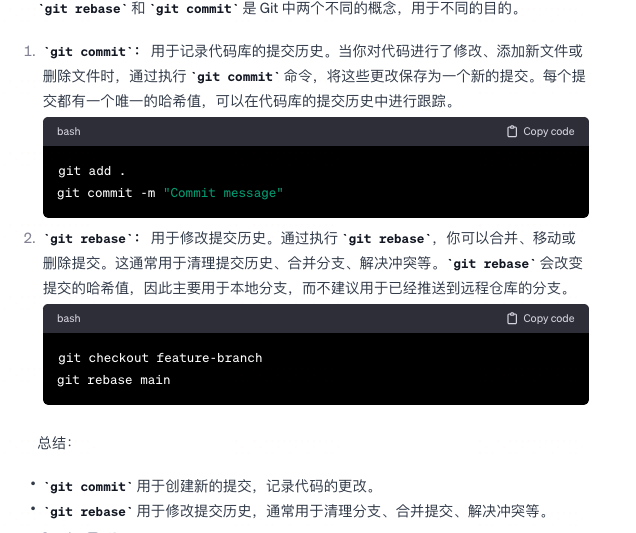
git rebase和commit有什么区别
-
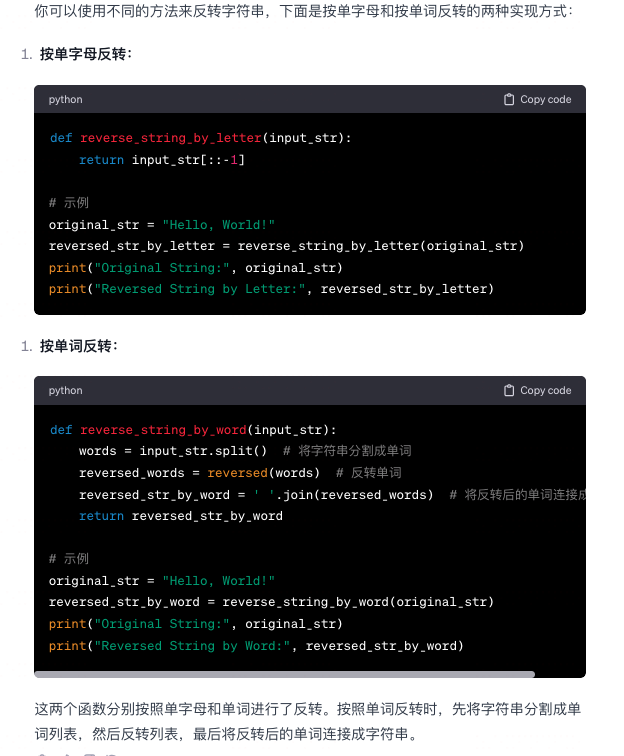
实现下字符串反转(分别按单字母以及word来反转)
-
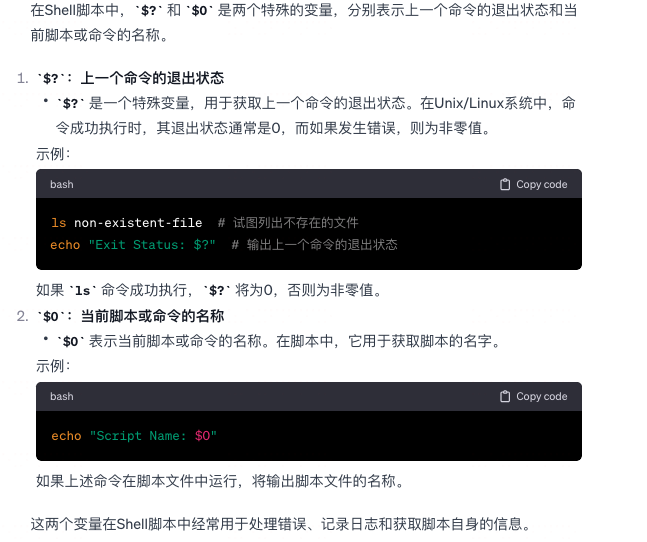
Shell $? $0 代表什么 ?
-
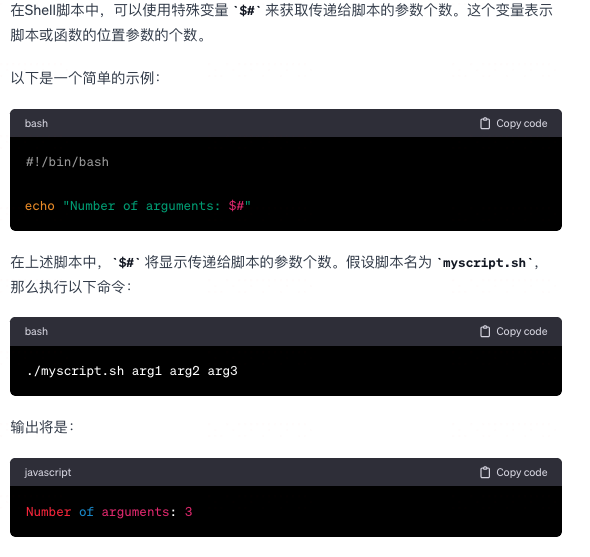
Shell 怎么查看 参数个数 ?
-
给定个字符串,怎么通过变量做字符串截取?
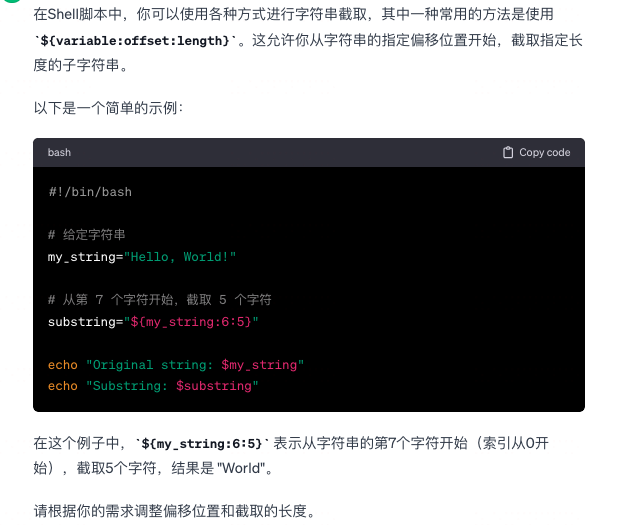
-
shell中 怎么进行 数值计算?
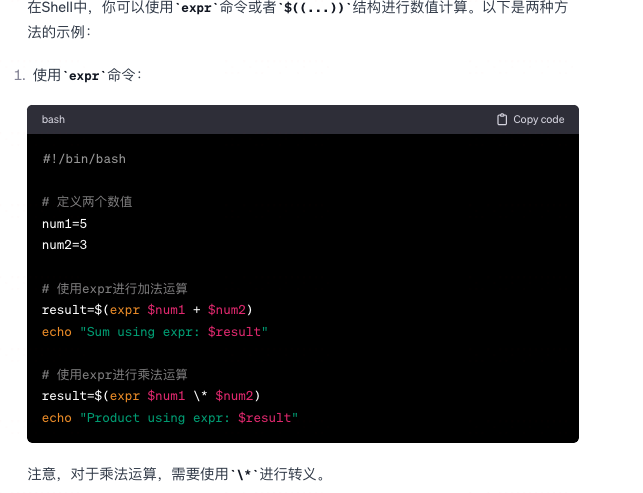
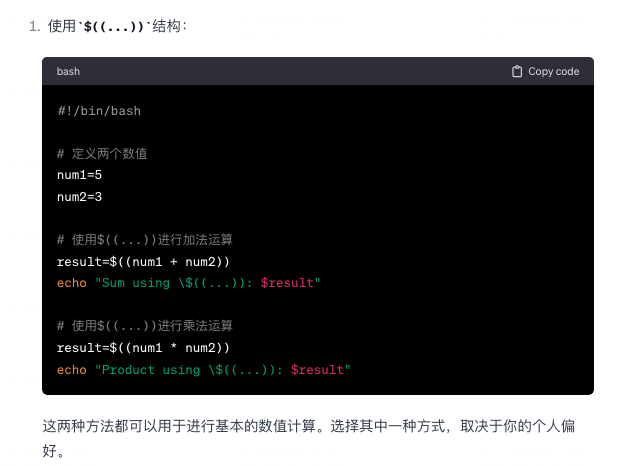
-
Python的多进程和多线程
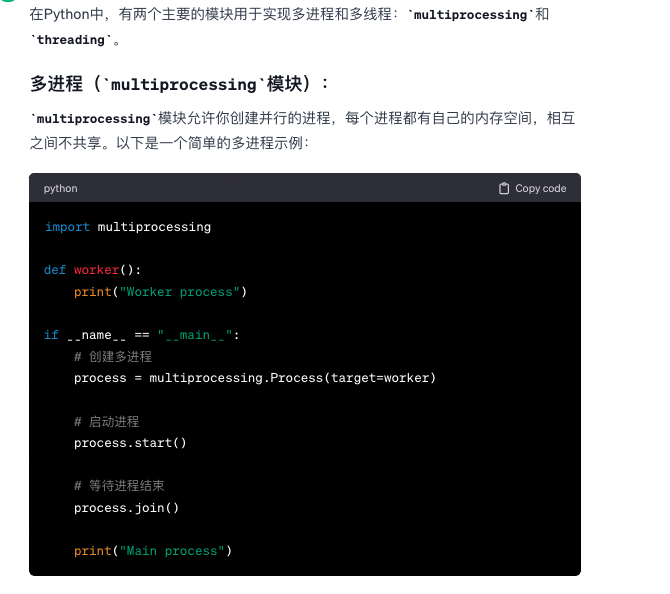
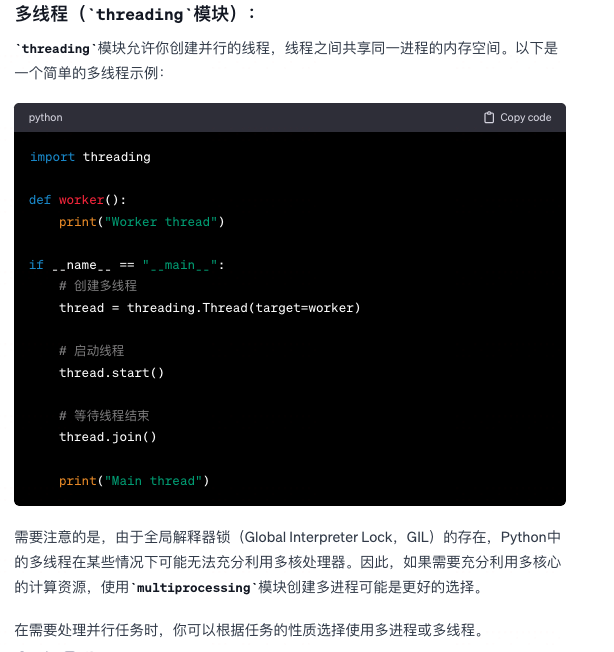
-
GIL解释器

K8s 基础知识
-
怎么查看 Node 上跑了哪些 Pod ?(Describe 更简单)
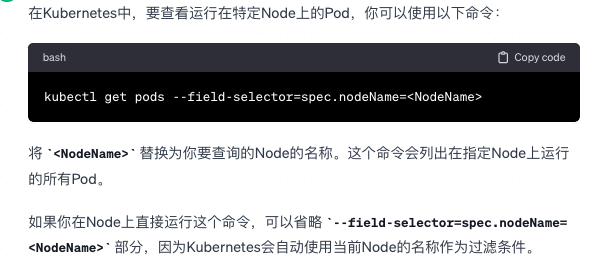
-
Pod 怎么跑到指定节点上 ?
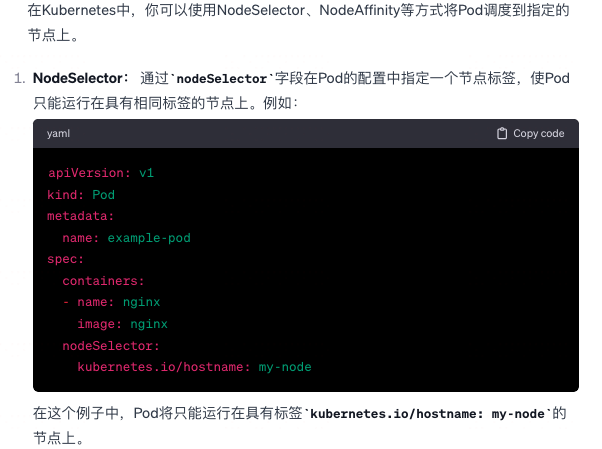
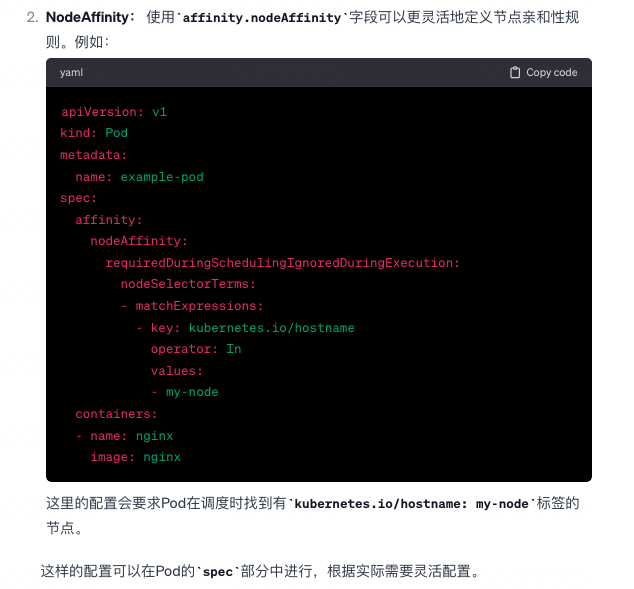
-
怎么限制某个特定 Pod 的的网络带宽?
gpt 回答不准,calico 实现方式是通过如下注解annotations: kubernetes.io/ingress-bandwidth: 10M kubernetes.io/egress-bandwidth: 10M -
Pod 健康检查机制? liveness 和 readiness的区别 ?

-
Pod 服务挂了,怎么排错?思路?
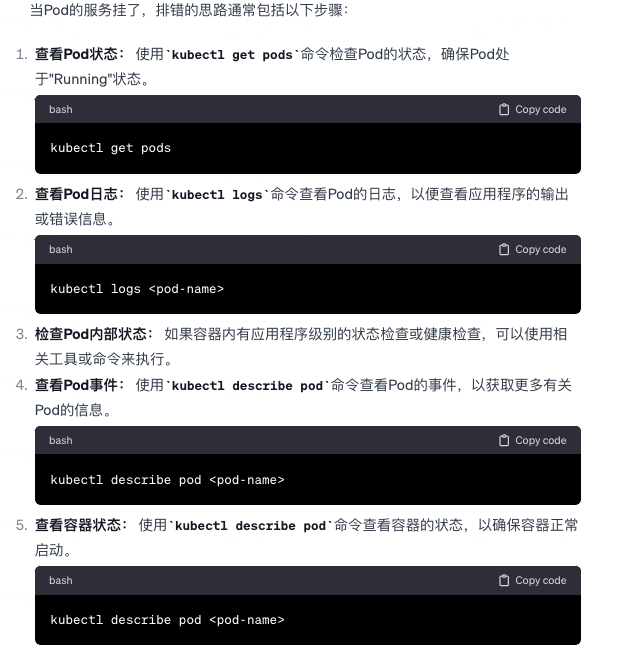

-
怎么做到在多个容器的 Pod 里面,只重启某个容器 ?
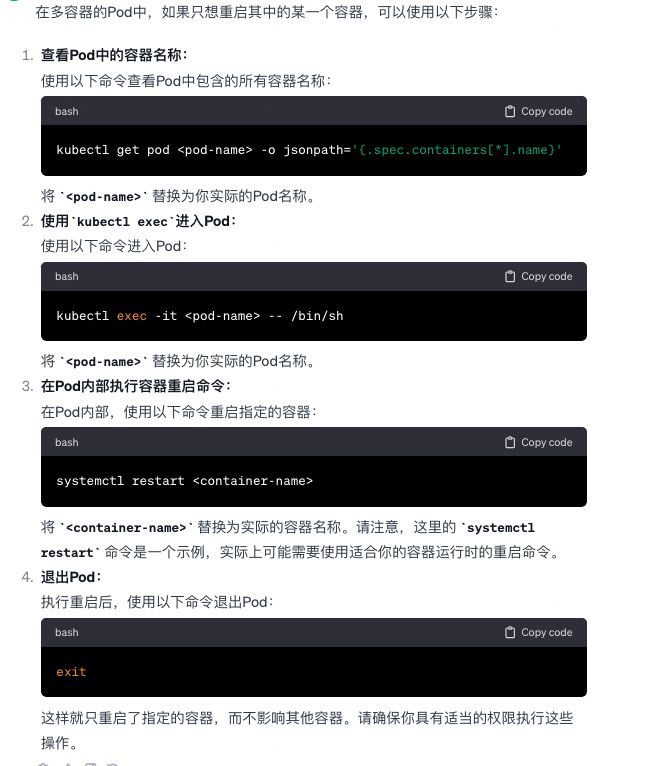
-
Deployment 创建 Pod 的过程, 涉及到的K8S组件有哪些?


-
Deployment 升级策略

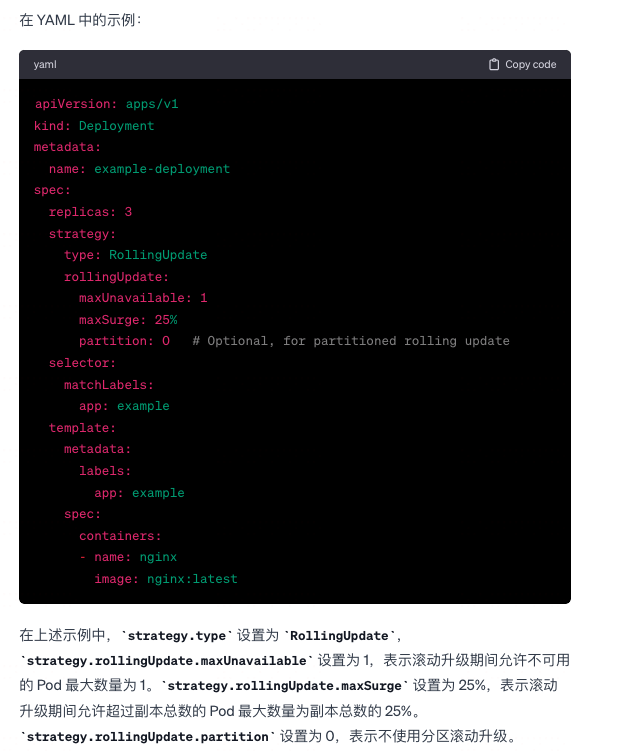
-
Deployment滚动更新过程

-
怎么控制滚动更新过程

-
Kubernetes Replication Controller:负责执行控制什么

-
Deployment 更新过程 ,replicaset 正在更新过程中,新的replicaset提交, 会有什么效果?

-
Service 有哪几种类型 ? (还有 headless)

-
Service 中 iptables 原理 (kube-proxy)

-
Ingress是什么?

-
服务流量不通了,需要做故障排查,都会查哪些地方?排查思路
gpt 回答的不好,看我总结这个吧还是
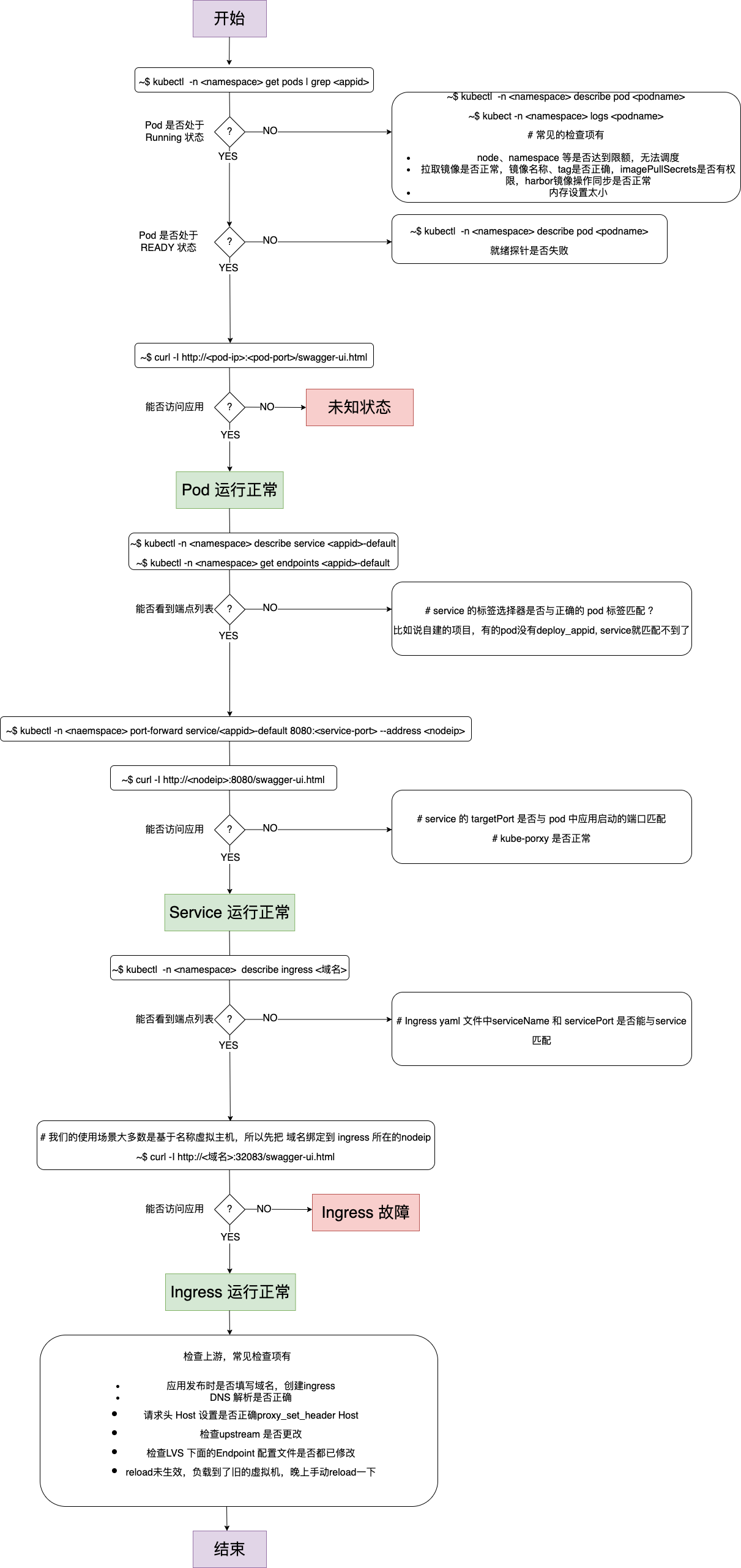
-
Calico的网络模式 有哪些 ?IPIP, BGP 都怎么实现的 ? 两种模式有什么区别 ?(回答的也不好)

-
kube schedule的调度机制?

-
kube schedule 坏了的话,还有其他什么方式去跑起来 Pod?
回答的不好, 个人感觉方法是 静态Pod -
Pod 经过scheduler,这一步之后Pod的会多出什么属性?
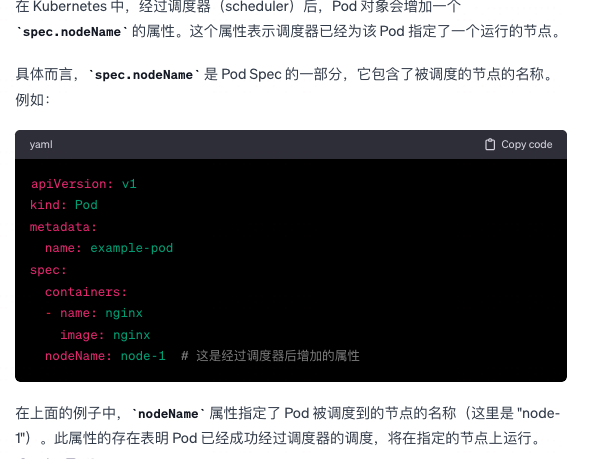
-
kubectl apply 创建一个pod的过程,具体说说
回答不好,看这个吧
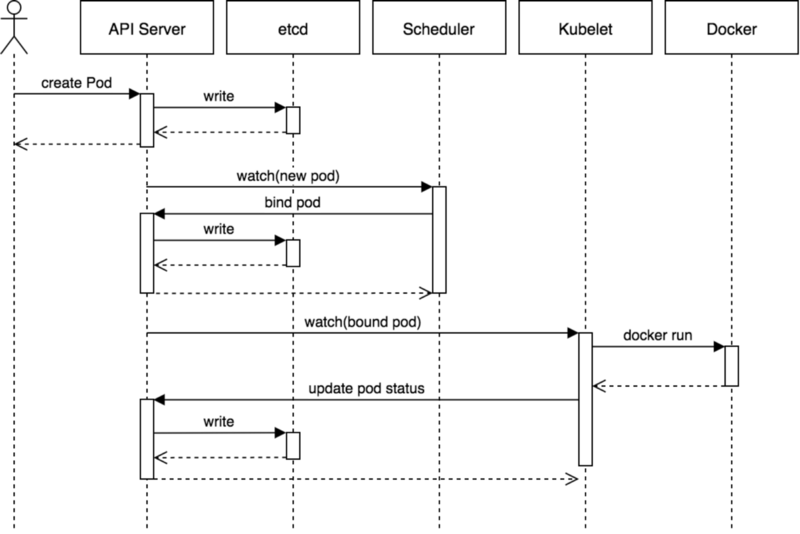
-
K8S QoS

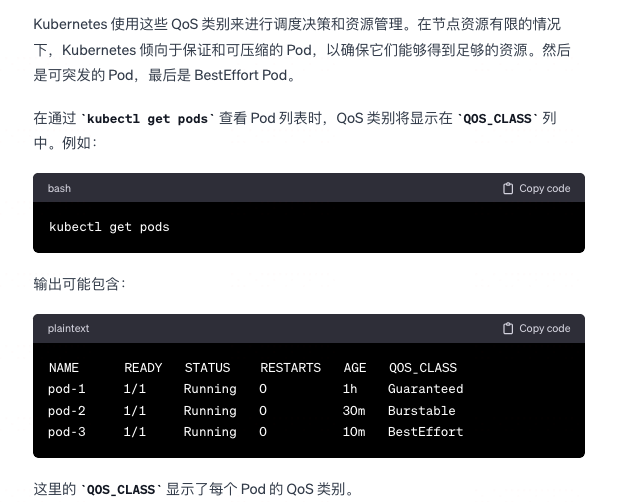
-
K8S怎么做升级的,升级需要考虑什么?


-
Dockerfile ADD和 COPY 有什么区别 ?

-
Docker 底层技术实现

-
Docker 网络模式


-
K8S node not ready 不可用,该怎么排查原因?
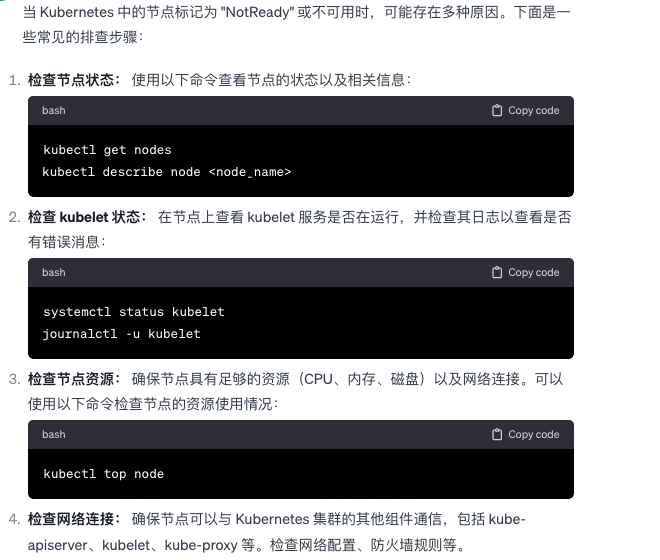
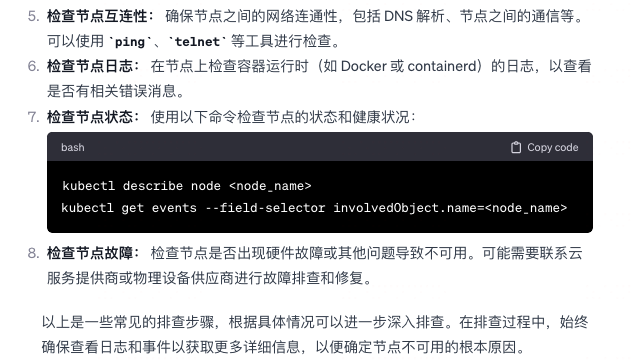
-
docker run跑了一个容器,但发现这个容器啊没有运行成功,那可以通过什么方法去排查?

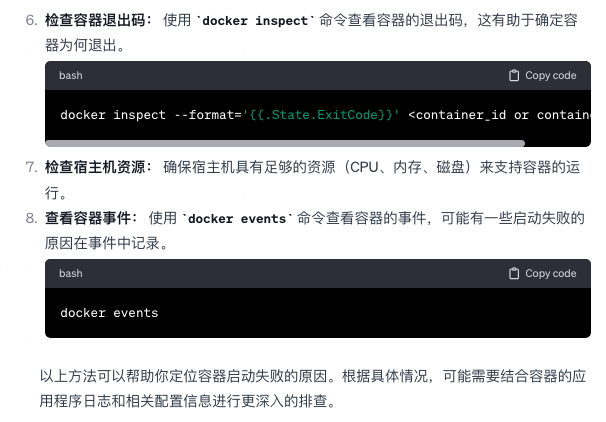
-
docker 常见错误码有哪些 ? 退出码 137是什么 ?

-
cmd 和 entrypoint 有什么区别?

-
Docker 怎么实现资源隔离 ?

-
容器想去访问主机上面的一些资源,要怎么打破这个隔离呢?

-
Dockerfile 的最佳实践,怎么写比较优雅?

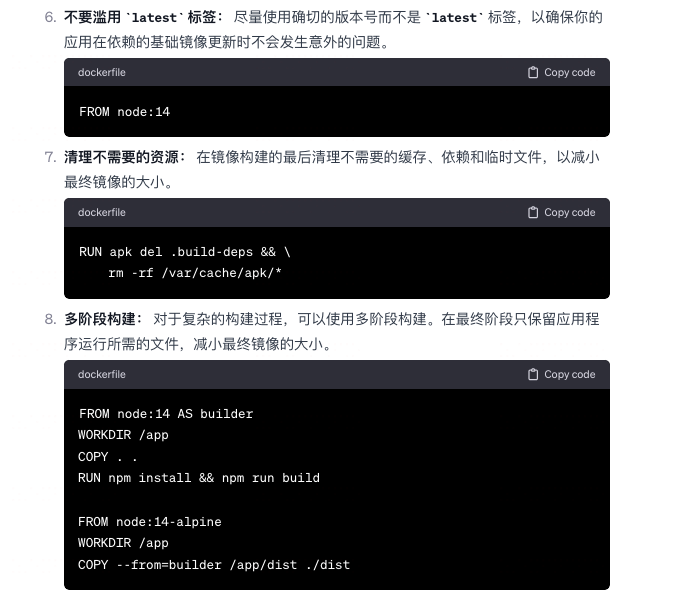
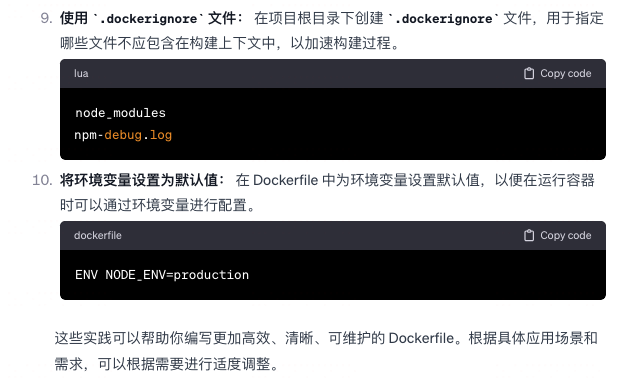
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/wiki 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
















 5138
5138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









