







处理数据样本的代码可能会变得杂乱无章且难以维护。
理想情况下,我们希望数据集代码与模型训练代码分离,以获得更好的可读性和模块化。
PyTorch 提供了两个数据原语:torch.utils.data.DataLoader和torch.utils.data.Dataset,允许您使用预加载的数据集和您自己的数据。
Dataset用于存储样本及其相应的标签,而DataLoader则在Dataset周围封装了一个可迭代器,以方便访问样本。
PyTorch域库提供了许多样本预加载数据集(如FashionMNIST),这些数据集是torch.utils.data.Dataset的子类,并实现特定数据的特定功能。模型原型设计和基准测试的示例包括:
- Image Datasets
- Text Datasets
- Audio Datasets
1. 加载数据集
以下是如何从 TorchVision 加载Fashion-MNIST 数据集的示例。Fashion-MNIST 是一个 Zalando 文章图像数据集,由 60,000 个训练示例和 10,000 个测试示例组成。每个示例包括一张 28×28 灰度图像和 10 个类别中的一个相关标签。
我们使用以下参数加载 FashionMNIST 数据集:
- root 是存储训练/测试数据的路径
- train 指定训练或测试数据集
- download=True 如果根目录下没有数据,则从互联网上下载
- transform 和 target_transform 指定特征和标签变换
2. 迭代和可视化数据集
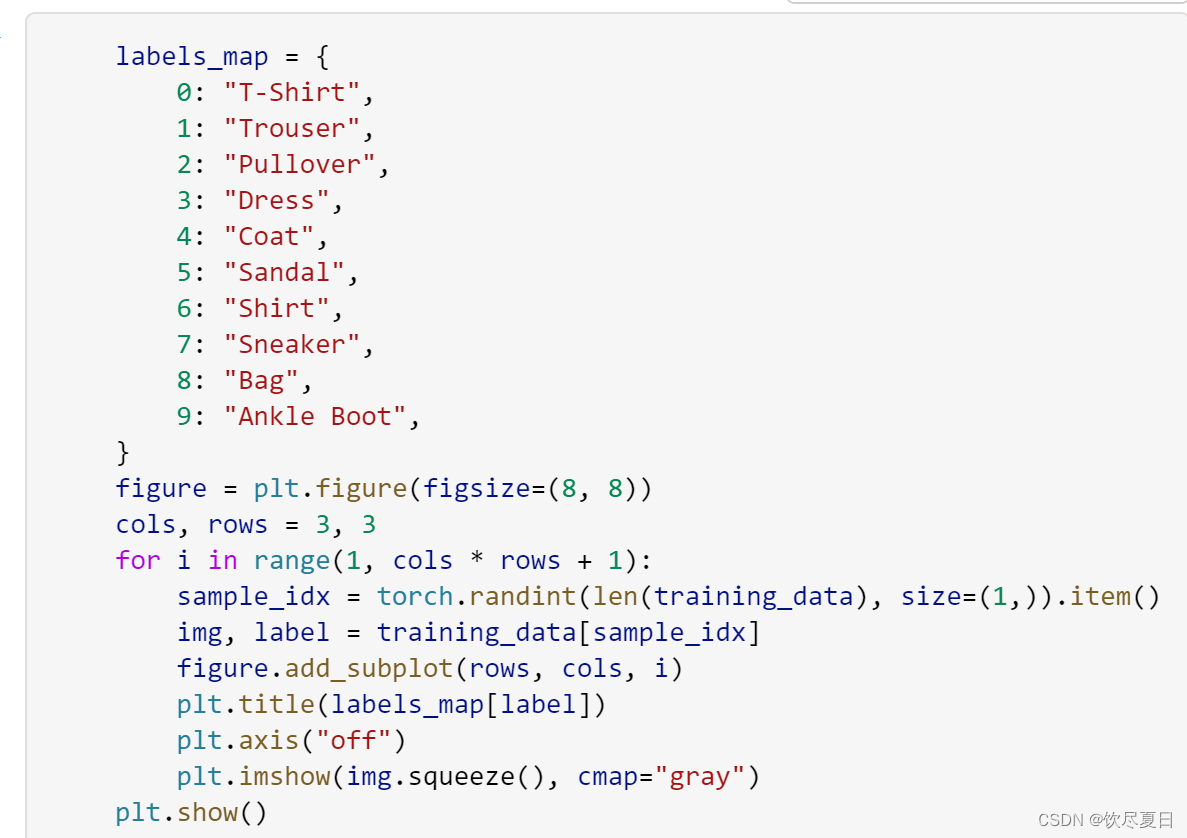
我们可以像列表一样手动为数据集编制索引:
training_data[index]。我们使用matplotlib来可视化训练数据中的一些样本。

3. 为使用DataLoaders进行培训准备数据
数据集检索数据集的特征,并一次标记一个样本。在训练模型时,我们通常希望在“迷你批次”中传递样本,在每个时期重新排列数据以减少模型过拟合,并使用Python的多处理来加快数据检索。
在机器学习中,您需要指定数据集中的特征和标签。特征是输入的,标签是输出的。我们训练特征,然后训练模型来预测标签。
- 特征是图像中的图案像素
- 标签是我们的10类:T恤、凉鞋、连衣裙等
DataLoader是一个可迭代的,它在一个更简单的API中为我们抽象了这种复杂性。要使用Dataloader,我们需要设置以下参数:
- data ——将用于训练模型的训练数据,以及用于评估模型的测试数据
- batch size 每个批次中要处理的记录数
- shuffle 按索引打乱数据的随机抽样

4. 遍历DataLoader
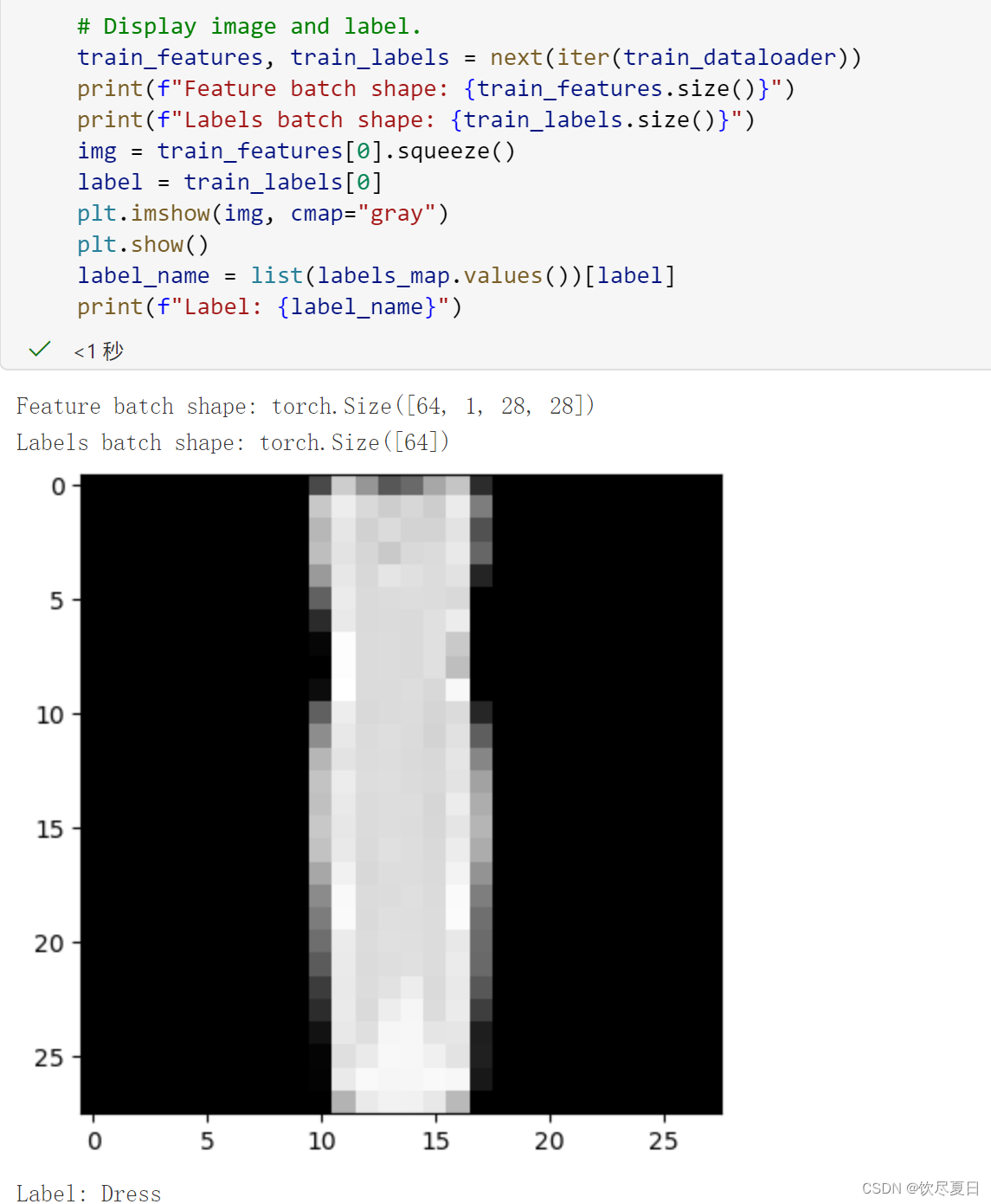
我们已经将该数据集加载到
Dataloader中,现在可以根据需要对数据集进行迭代。下面的每个迭代都返回一批train_features和train_labels(分别包含batch_size=64个特征和标签)。因为我们指定了shuffle=True,所以在迭代所有批次之后,数据会被打乱,以便对数据加载顺序进行更细粒度的控制。
5. 规范化
规范化是一种常见的数据预处理技术,用于缩放或变换数据,以确保每个特征都有相同的学习贡献。例如,灰度图像中的每个像素都具有0到255之间的值,这是特征。如果一个像素值是17,而另一个像素是197。像素重要性的分布将不均匀,因为像素体积越大,学习就会偏离。规范化可以更改数据的范围,而不会扭曲其在我们的功能中的区别。
进行此预处理是为了避免:
- 预测精度的降低
- 模型的学习难度
- 特征数据范围的不利分布
6. Transforms
数据并不总是以训练机器学习算法所需的最终处理形式出现。我们使用转换来处理数据,并使其适合于训练。
所有TorchVision数据集都有两个参数(transform用于修改特性,target_transform用于修改标签),它们接受包含转换逻辑的可调用文件。torchvision.transforms模块提供了几种常用的开箱即用转换。
FashionMNIST功能采用PIL图像格式,标签为整数。对于训练,我们需要将特征作为归一化张量,并将标签作为一个热编码张量。为了进行这些转换,我们将使用ToTensor和Lambda。
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
7. ToTensor
ToTensor将PIL图像或NumPy ndarray转换为FloatTensor,并将图像的像素强度值缩放到范围[0.,1.]
8. Lambda transforms
Lambda转换应用任何用户定义的Lambda函数。在这里,我们定义了一个函数,将整数转换为一个热编码张量。它首先创建一个大小为10(我们数据集中标签的数量)的零张量,并调用scatter,它在标签y给定的索引上分配一个值=1。您也可以使用torch.nn.functional.one_hot作为另一个选项来执行此操作。

9. 为文件创建自定义数据集
自定义 Dataset 类必须实现三个函数:__init__、__len__ 和 __getitem__ 三个函数。看看这个实现;FashionMNIST 图像存储在 img_dir 目录中,它们的标签分别存储在 CSV 文件 annotations_file 中。
getitem 函数根据给定的索引 idx 从数据集中加载并返回一个样本。根据索引,函数会识别图像在磁盘上的位置,使用 read_image 将其转换为张量图像,从 self.img_labels 中的 csv 数据中获取相应的标签,调用转换函数(如果适用),然后以元组形式返回张量图像和相应的标签。
















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









