







前言:MapRedeuce这一章节是非常重要的,涉及了很多实例,这篇文章对MapReduce进行概述,了解它的架构和工作机制,为编程做好基础。
概述
1、分布式并行编程
MapReduce是最先由谷歌提出的分布式并行编程模型,相对于传统并行计算框架来讲,它采用非共享式存储,容错性好,以普通的PC机作为硬件,大大节约成本,编程简单,适用于批处理、非实时、数据密集型数据。
2、MapReduce模型
(1)MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽 象到了两个函数:Map和Reduce
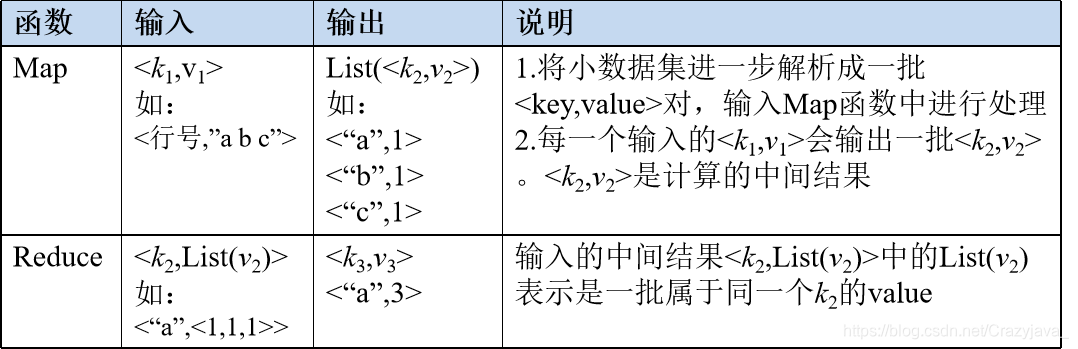
(2)MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的 大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理。
(3)MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker
MapReduce的体系结构
主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task。
1、Client:程序通过Client提交到JT端,可以通过Cilent提供的接口查看作业运行状态。
2、JobTracker: 监控资源、调度作业,监控所有的TT和Job的健康,一旦发现失败,就会将任务转移到其他节点。
3、TaskTracker: 想JT汇报资源使用情况和作业运行情况,接受JT的命令并执行。
4、Task: Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。
MapReduce工作流程
1、概述
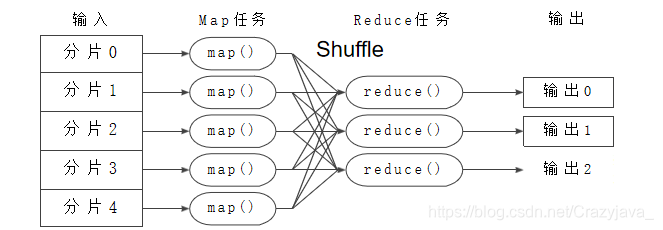
由图可知,不同的Map、Reduce任务之间不会通信,所有的数据交换都要通过MapReduce框架实现。
2、各个执行阶段
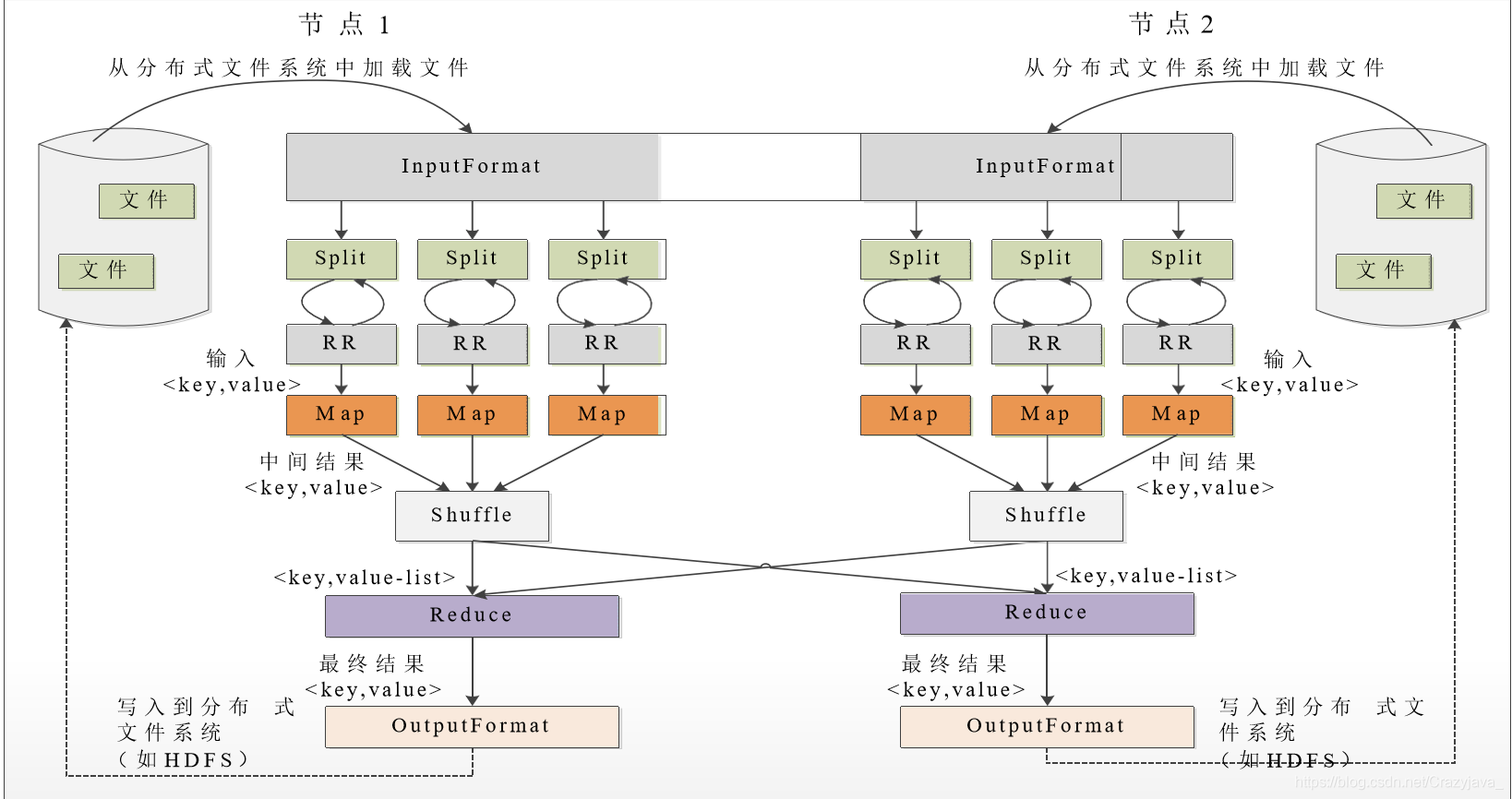
图中的split(分片): HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其 处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据 起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
Map任务数量: 一个split创建一个Map,由split数量决定。
Reduce任务数量: 最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目。通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
Shuffle过程详解
1、Shuffle过程简介
所谓 Shuffle,是指对 Map 输出结果进行分区、排序、合并等处理并交给 Reduce 的过程。因此,Shuffle 过程分为 Map 端的操作和 Reduce 端的操作,主要执行以下操作
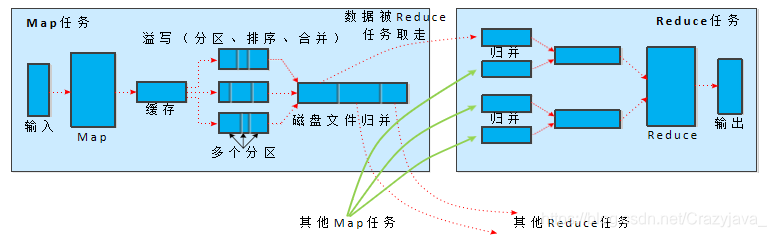
2. Map 端的 Shuffle 过程
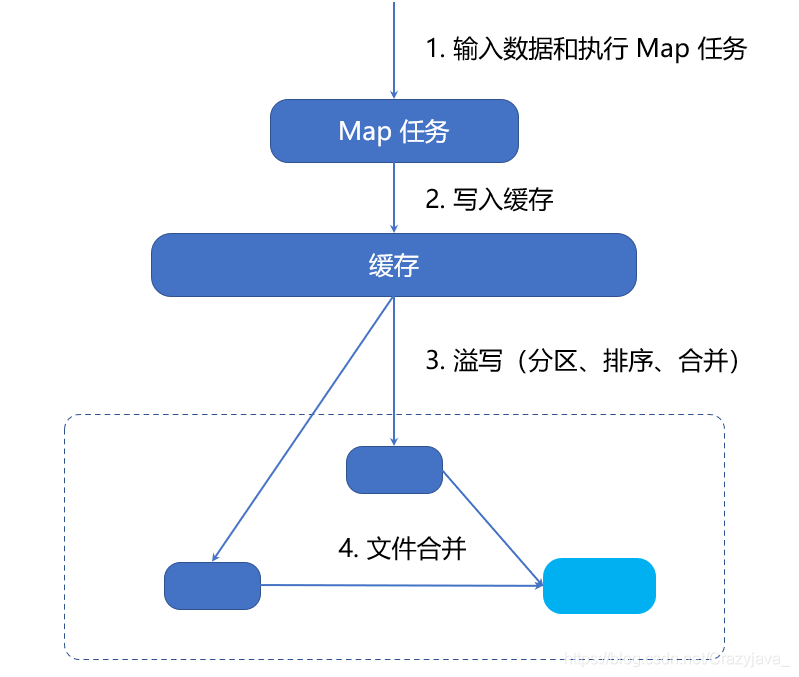
(1)输入数据和执行 Map 任务
Map 任务的输入数据一般保存在分布式文件系统的文件块中,这些文件块的格式是任意的,可以是文档,也可以是二进制格式的。Map 任务接受 <key,value> 作为输入后,按一定的映射规则转换成一批<key,value> 进行输出。
(2)写入缓存
每个Map任务分配一个缓存,MapReduce默认100MB缓存
(3)溢写(分区、排序、合并)
设置溢写比例0.8;分区默认采用哈希函数;排序是默认的操作;排序后可以合并;合并不能改变最终结果
(4)文件归并
在Map任务全部结束之前进行归并,归并得到一个大的文件,放在本地磁盘。文件归并时,如果溢写文件数量大于预定值(默 认是3)则可以再次启动Combiner,少于3不需要;JobTracker会一直监测Map任务的执行,并通知 Reduce任务来领取数据
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
3、Reduce 端的 Shuffle 过程
(1)领取数据
Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据。
(2)归并数据
Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘;多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的;当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
(3)把数据输入给 Reduce 任务
磁盘中经过多轮归并后得到的若干个大文件,不会继续归并成一个新的大文件,而是直接输入给
Reduce 任务,这样可以减少磁盘读写开销。由此,整个 Shuffle 过程顺利结束。接下来Reduce 任务会执行 Reduce 函数中定义的各种映射,输出最终结果,并保存到分布式文件系统中。















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











