







最近换了工作环境,以前的IDEA配置都没了,记得上次配置自己的IDEA还是在两年前?然后构建Maven项目时遇到了一些小插曲,记录下解决方案(PS:新手教程向)
1. idea中maven默认配置的坑
首先打开File->Settings
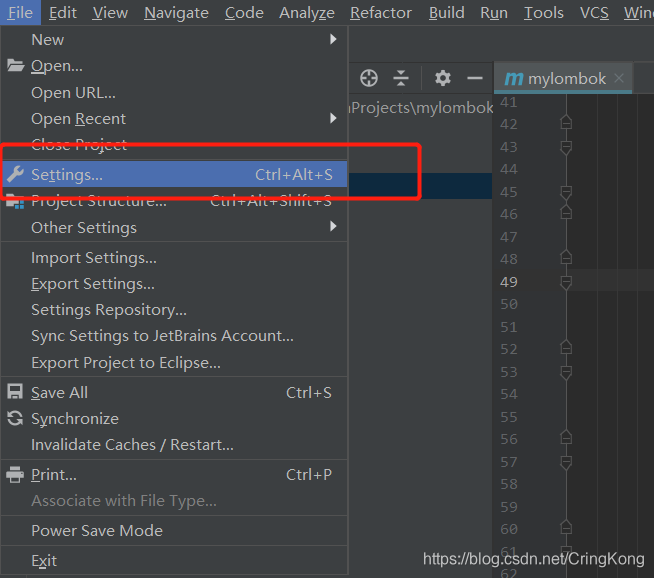
这里可以直接搜索maven,就可以进入idea的Maven配置选项。
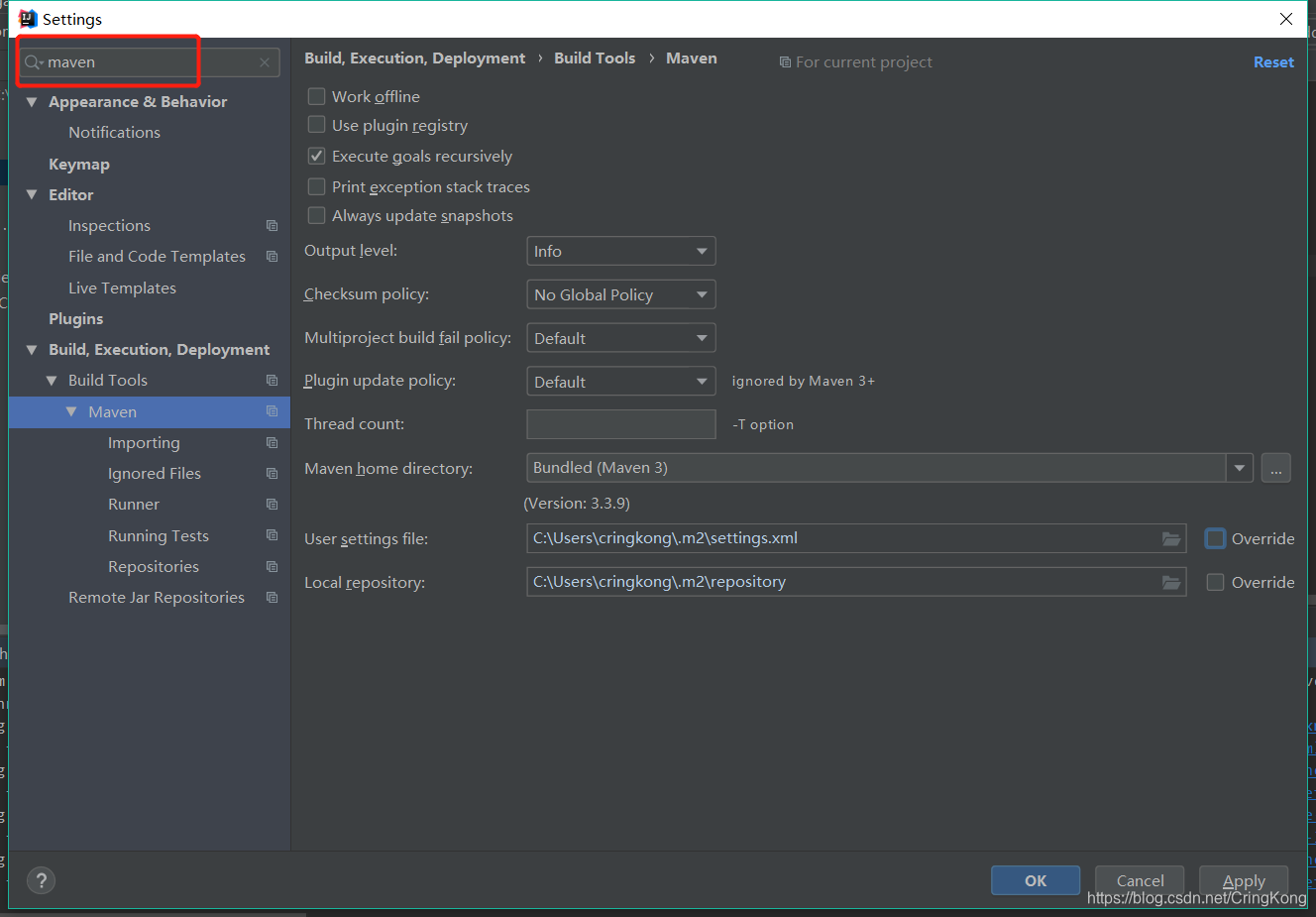
我这里是idea默认的maven配置,可以看到默认的Maven目录是idea内置的maven插件目录,同时Maven的配置文件在操作系统的User目录下。
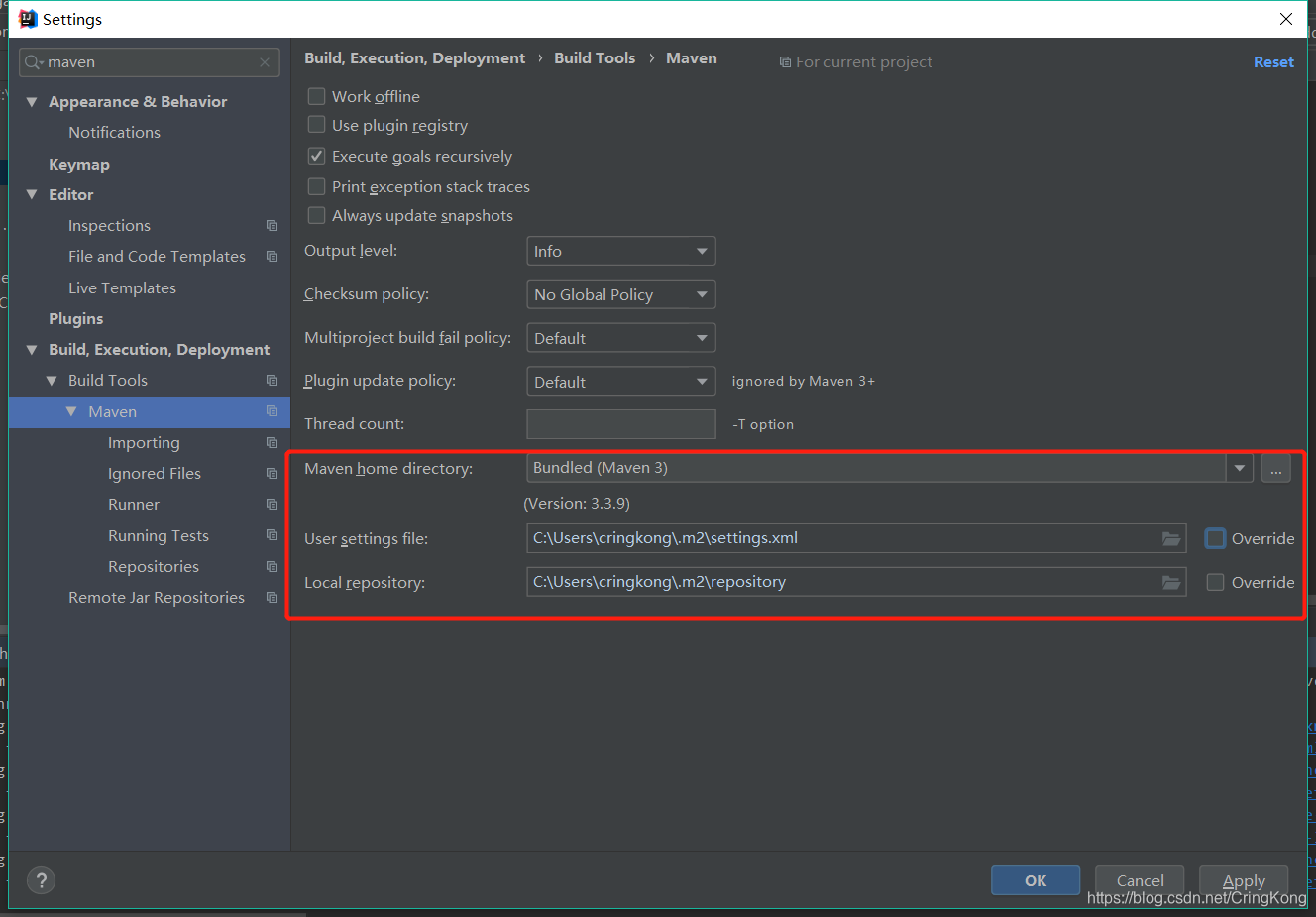
理论上来讲idea的默认配置这样是没什么问题的,但是因为国内网络环境,idea默认的maven远程仓在国外,这样会导致一些依赖资源下载过慢,或者下载失败。
根据网络上的教程,我们需要更改配置文件,配置国内镜像仓库。

打开目录,坑爹的事情发生了,这压根就没有settings.xml文件啊?这时如果我们去创建一个maven工程,就会出现问题。
maven会自动构建目录,引入pom.xml中的的依赖,但是默认配置是不行的。就会像下图一样卡死。或者构建特别慢,因为国内网络问题。

2. 解决方法一:引入配置文件
把Maven的配置文件settings.xml丢到那个目录下就行。
这个配置文件可以在idea的安装目录的插件目录下找到:
JetBrains\IntelliJ IDEA 2019.1\plugins\maven\lib\maven3\conf

这里我们需要修改一下,配置国内镜像仓库。
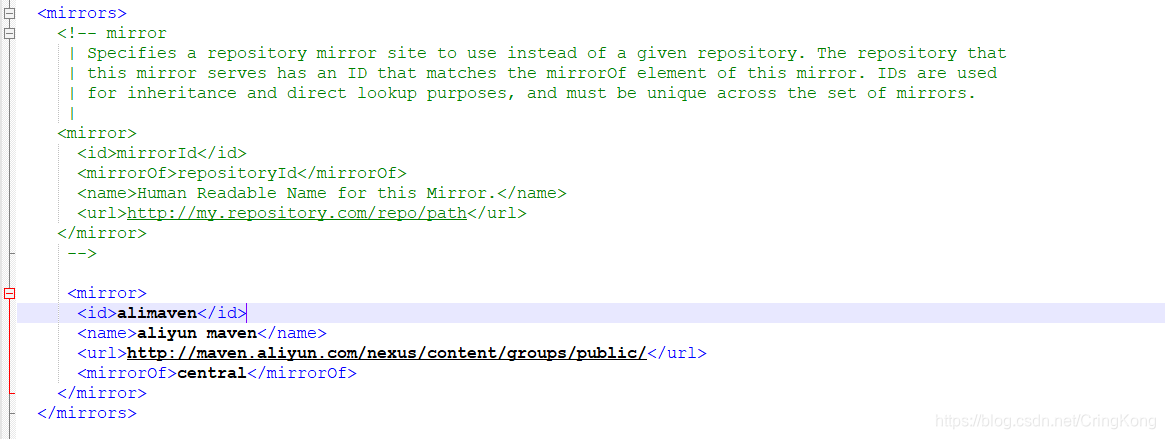
在<mirros>标签中加上阿里国内镜像仓库地址:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
然后把他放到idea配置的对应目录下:

3.解决方式二:使用自己的Maven
首先去Maven官网下载:http://us.mirrors.quenda.co/apache/maven/maven-3/3.6.1/binaries/apache-maven-3.6.1-bin.zip
解压到任意目录后,maven的目录结构是这样的:
然后去idea中配置:
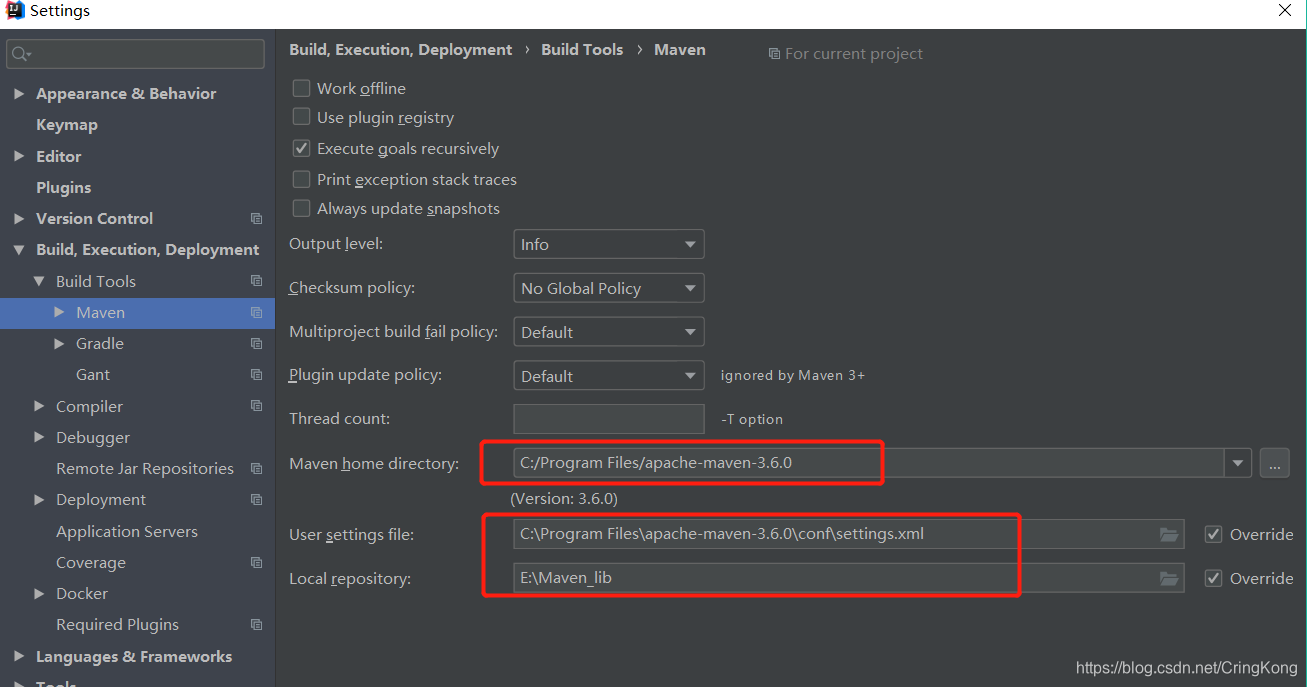
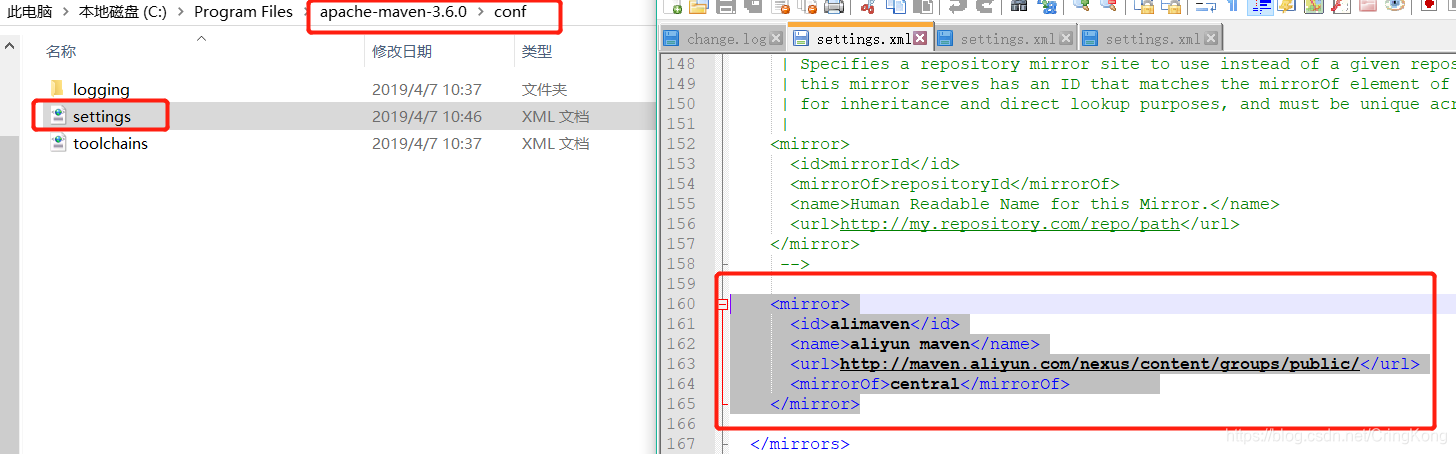
这里Maven本地仓我选择了自己的目录,配置文件选用了maven自身的配置文件,当然别忘了配置国内镜像仓:
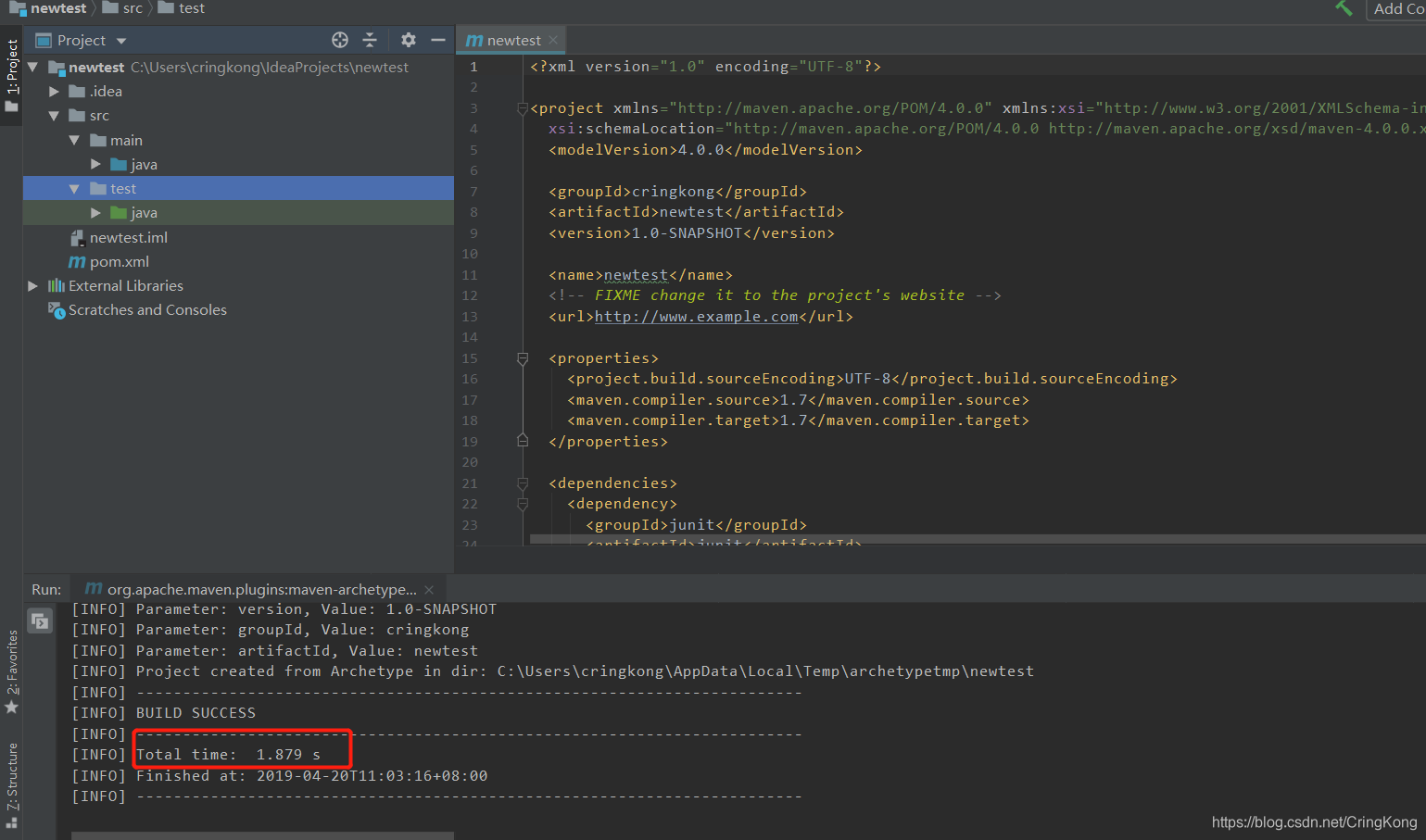
4.构建Maven项目:
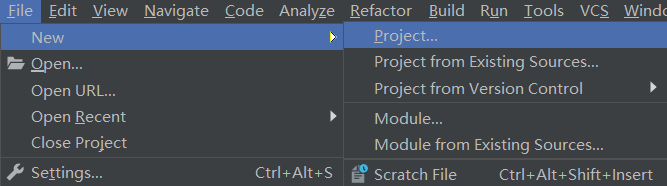
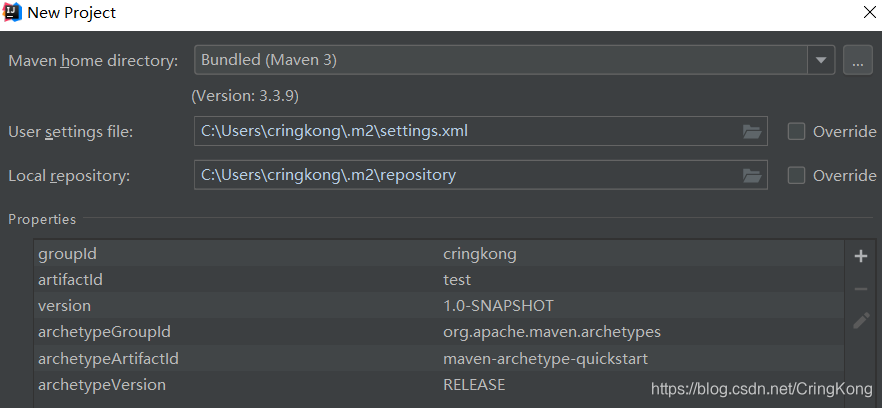
File->New->Project,然后选择maven项目:
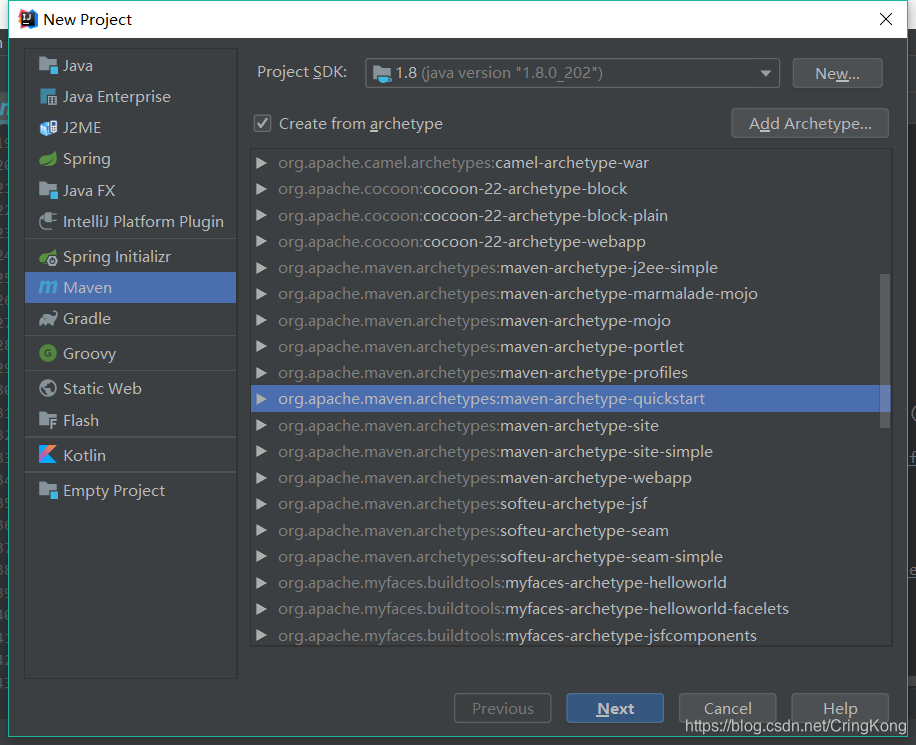
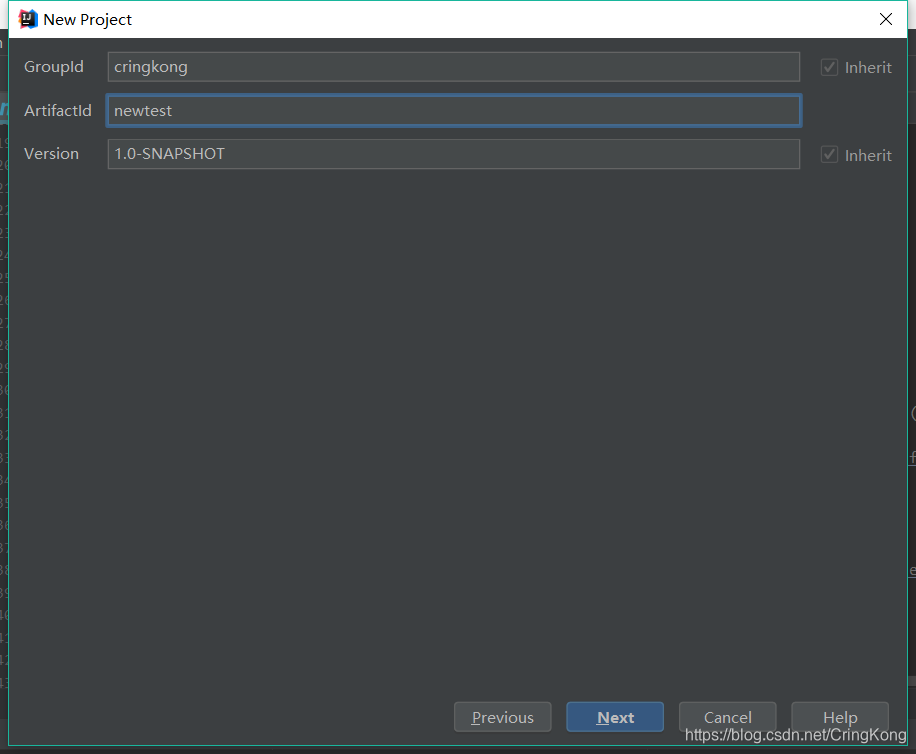
选择我们自己的maven配置:
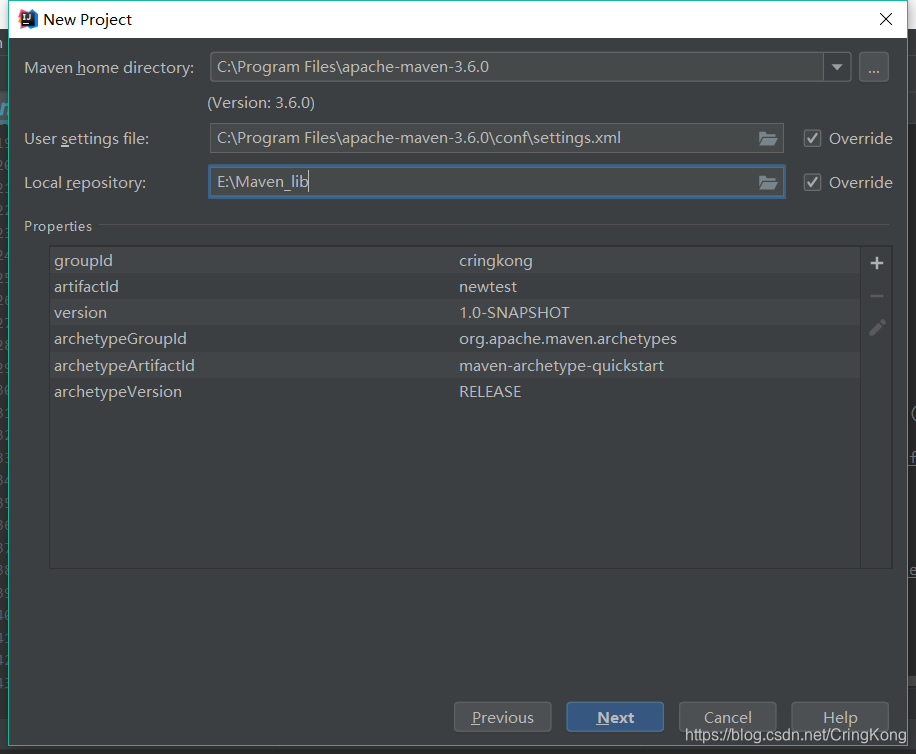
因为配置了国内仓的原因,瞬间构建完成

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









