






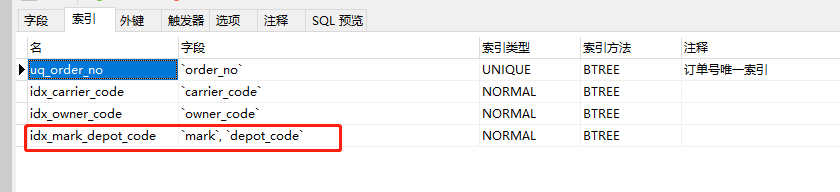
1、建立索引
详解
一般来说,应该在这些列上创建索引,例如:
mysql主键不需要建立索引,主键具备索引的功能
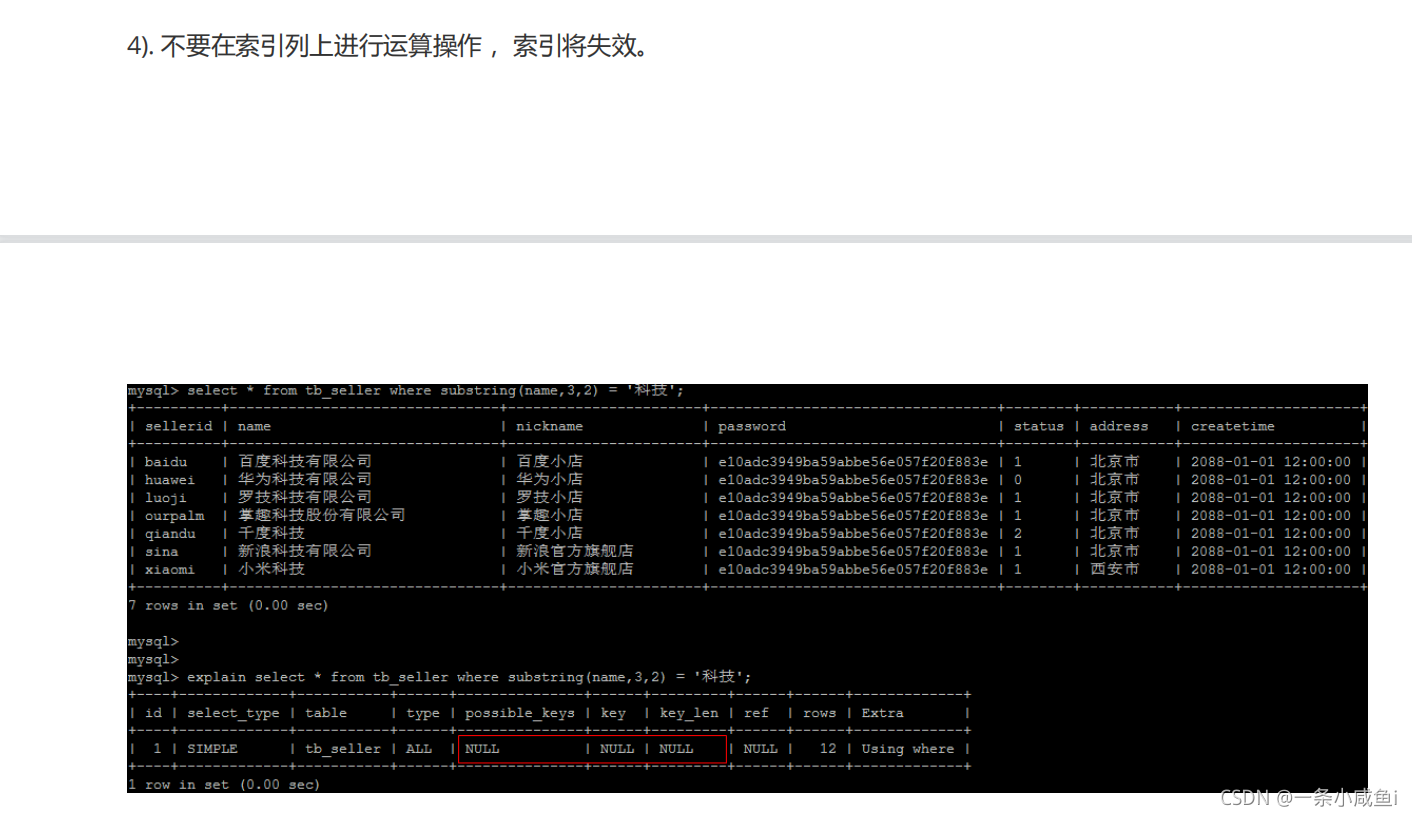
第一、在经常需要搜索的列上,可以加快搜索的速度;
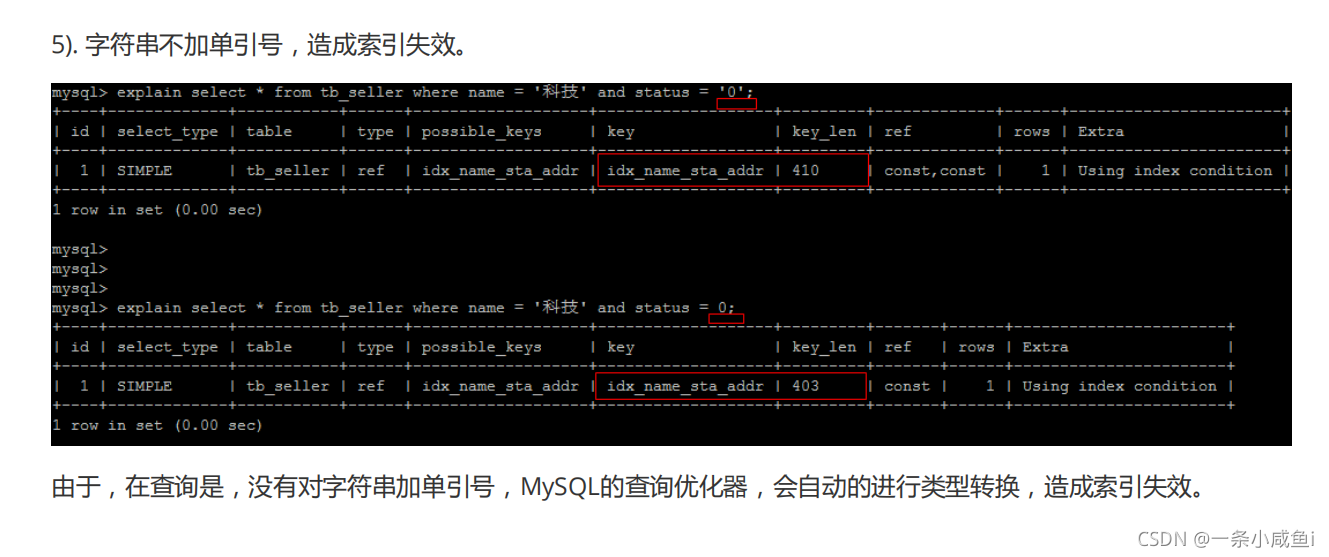
第二、在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
第三、在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
第四、在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
第五、在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
第六、在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
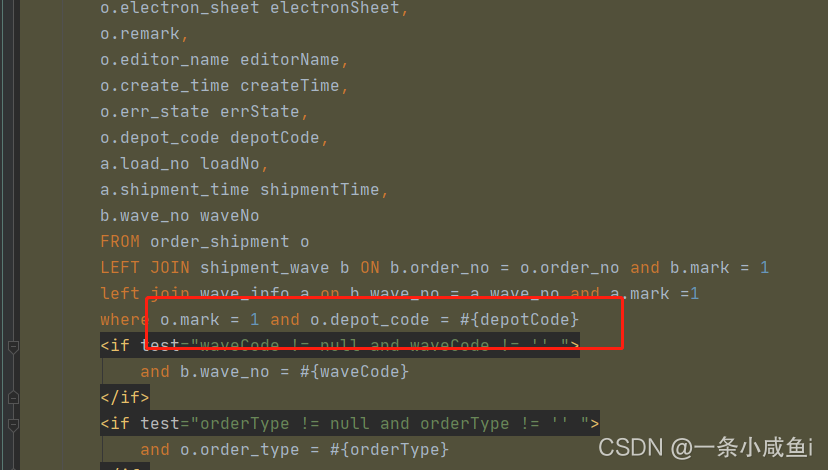
建立索引,一般按照select的where条件来建立,比如: select的条件是where f1 and f2,那么如果我们在字段f1或字段f2上建立索引是没有用的,只有在字段f1和f2上同时建立索引才有用等。
2、优化sql
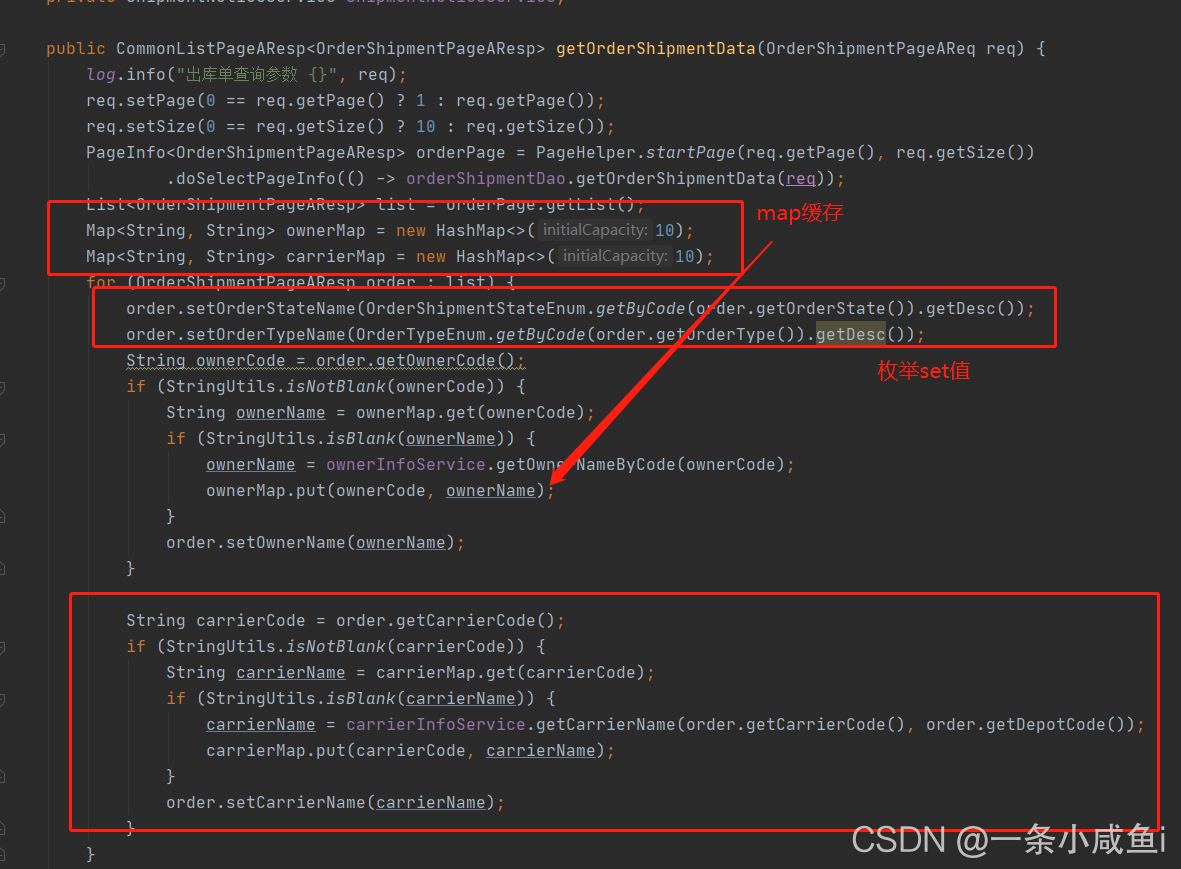
1、移除查询字段中要查询的字典表中的数据,将其在service层用枚举set进去。
2、减少连表操作入货主承运商这种数据少的可以在service层set进去。
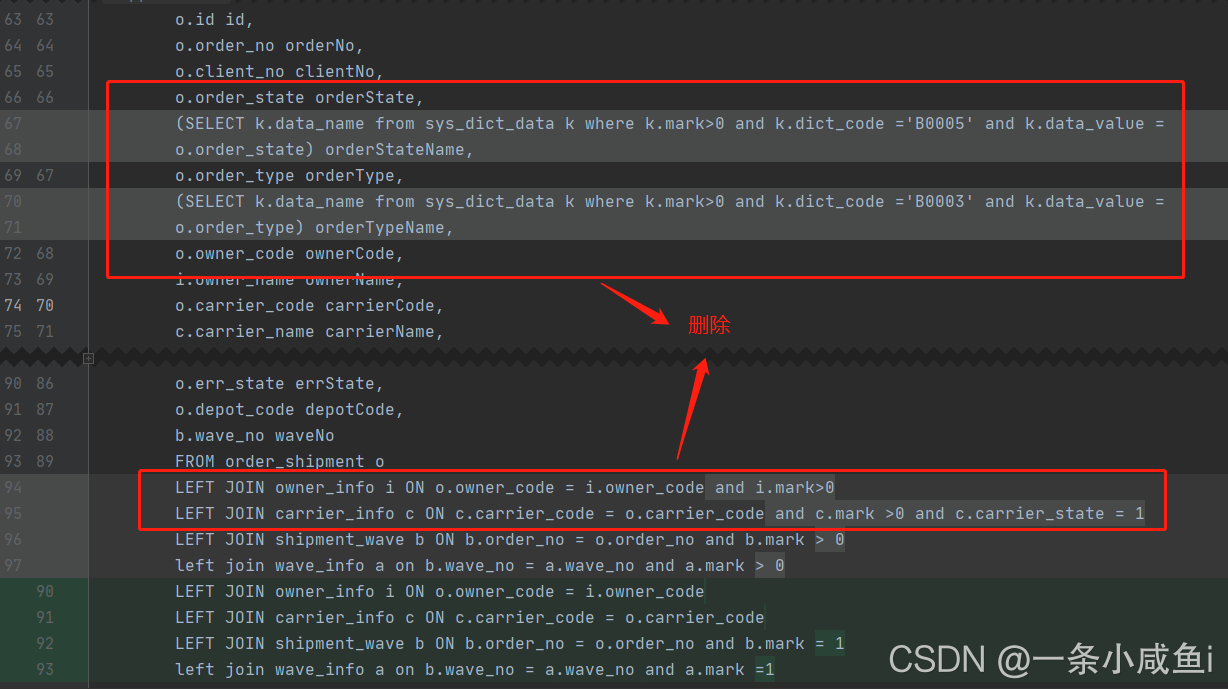
3、java的操作要比sql快的多,连表查询效率很低
代码尽量减少数据库操作次数,数据库操作是会有网络IO和磁盘IO的
比如:不要用for循环新增多条数据 可以批量插入。
4、explain学习
详解
explain(执行计划)包含的信息十分的丰富,着重关注以下几个字段信息。
①id,select子句或表执行顺序,id相同,从上到下执行,id不同,id值越大,执行优先级越高。
②type,type主要取值及其表示sql的好坏程度(由好到差排序):system>const>eq_ref>ref>range>index>ALL。保证range,最好到ref。
③key,实际被使用的索引列。
④ref,关联的字段,常量等值查询,显示为const,如果为连接查询,显示关联的字段。
⑤Extra,额外信息,使用优先级Using index>Using filesort(九死一生)>Using temporary(十死无生)。
着重关注上述五个字段信息,对日常生产过程中调优十分有用。
5、单列索引和复合索引的应用场景 todo
详解
复合索引 :要满足最左前缀法则,如下图所示:建立复合索引name+status+addres后,查询语句中where条件中包含下面三种都会执行索引,第三种哪怕顺序不同也会执行,如果where条件为name+address只会走name单列索引。

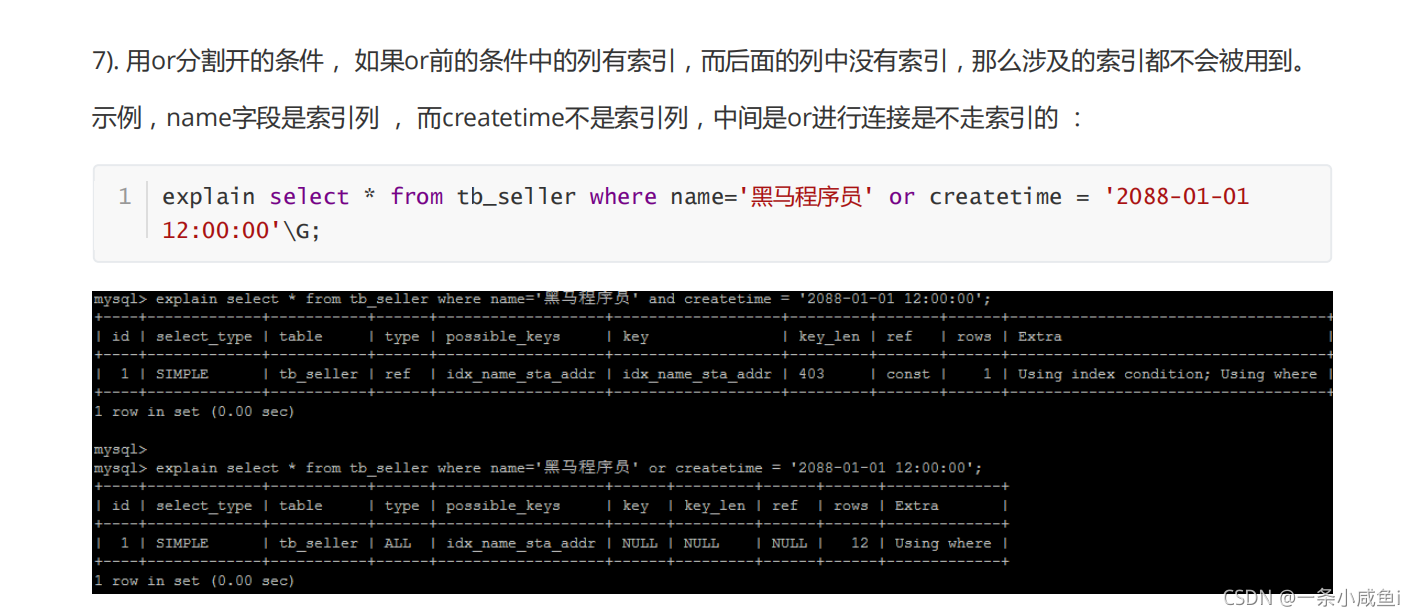
6、索引失效的几种情况
主键自带索引
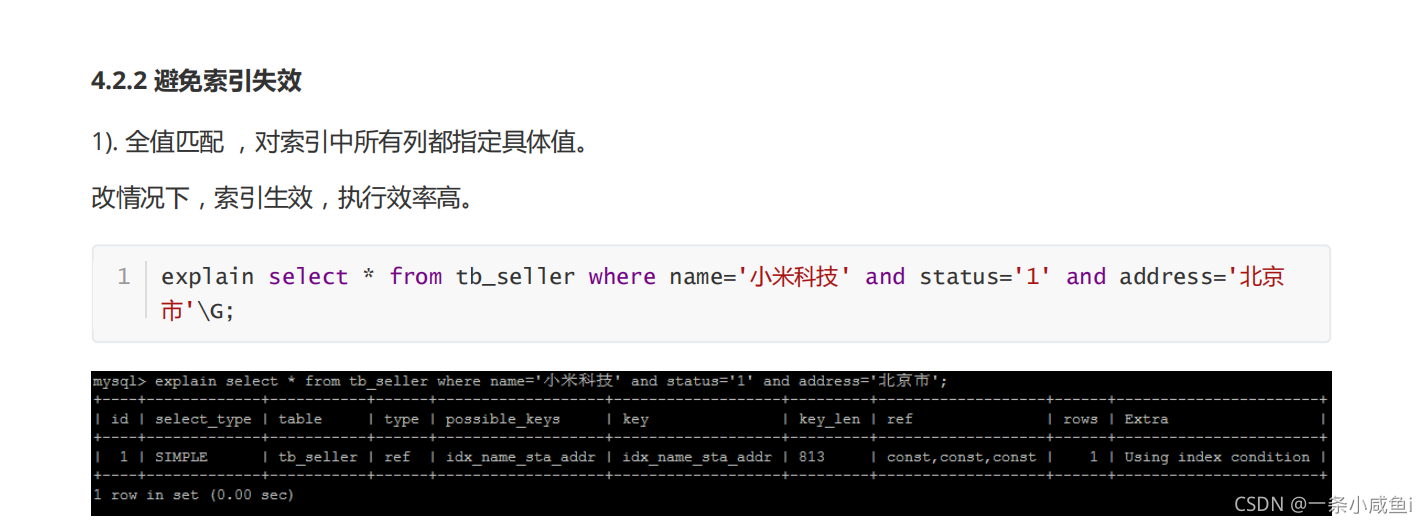

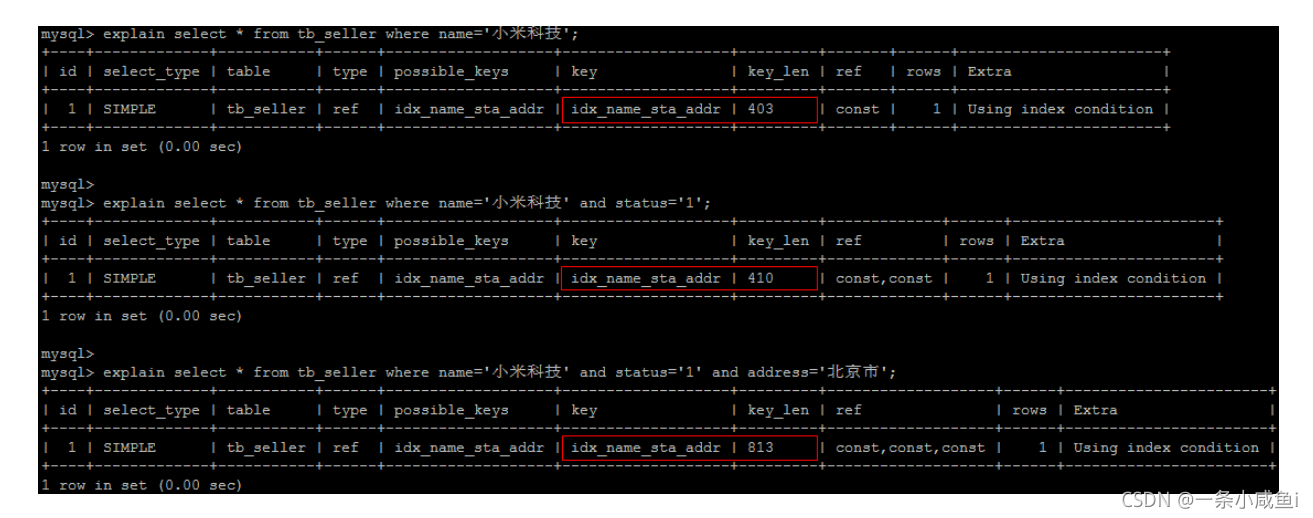
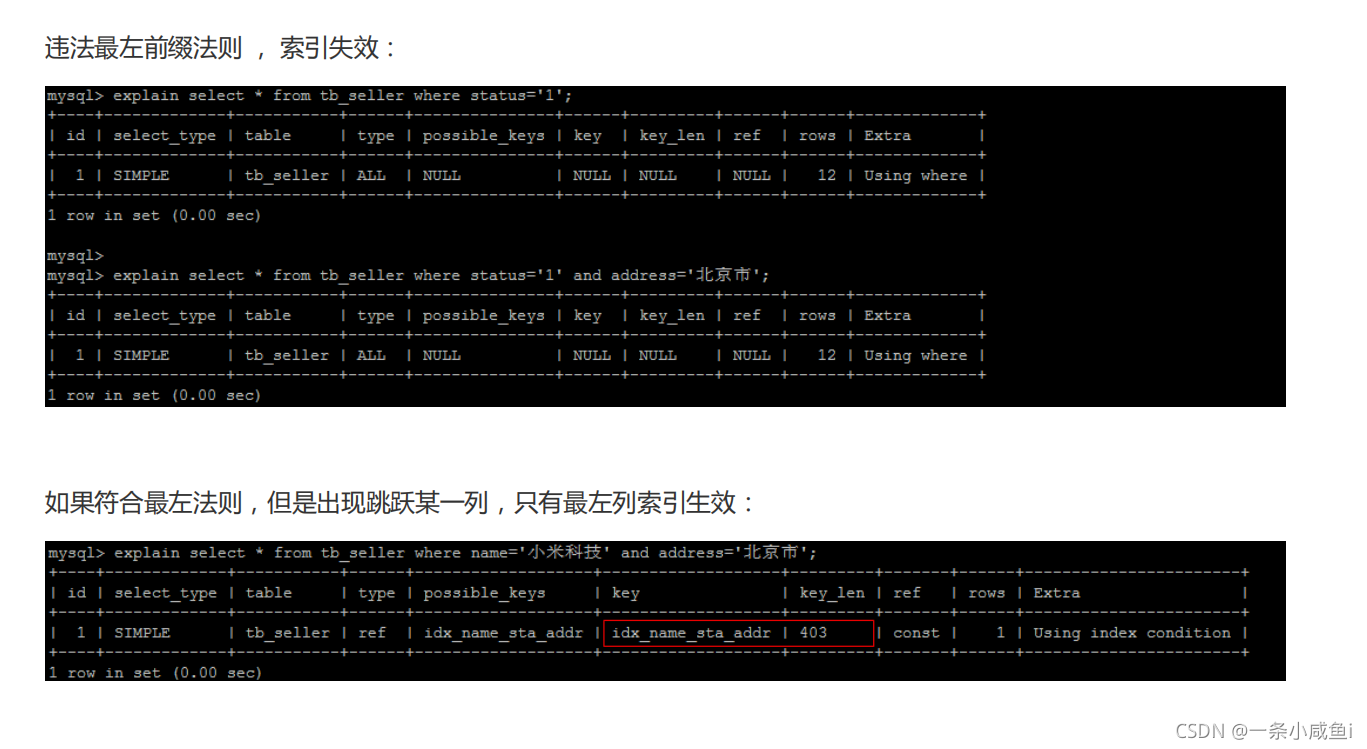
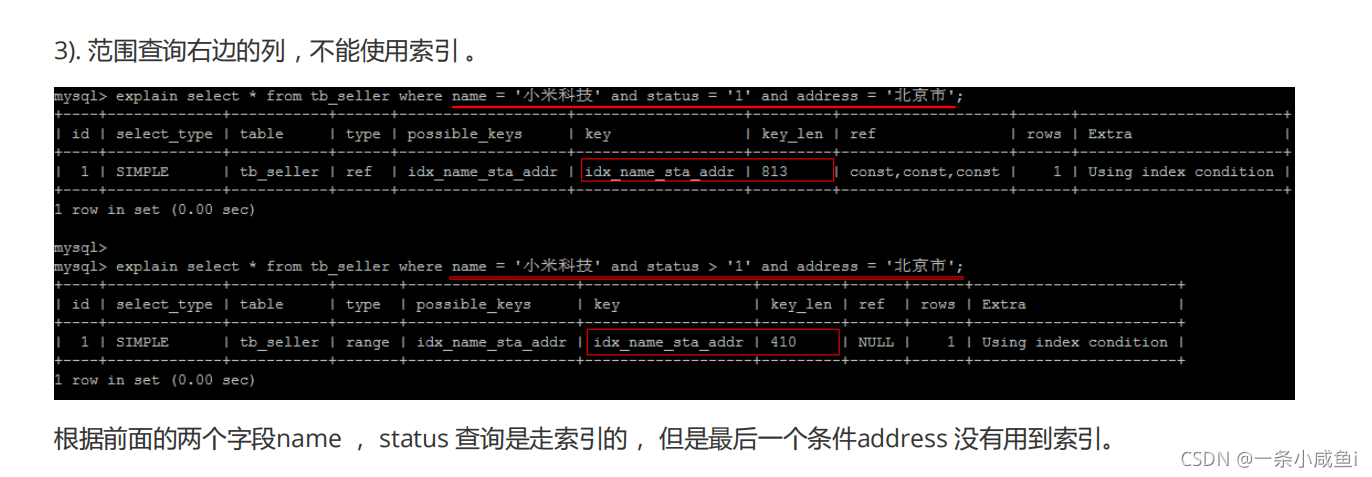

使用覆盖索引解决,覆盖索引指的是将Select * 中的替换了对应的索引字段。如果中包含没有索引的字段则索引失效
7、横向分表和纵向分表
1. 纵向分表
纵向分表是指将一个有20列的表根据列拆分成两个表一个表10列一个表11列,这样单个表的容量就会减少很多,可以提高查询的性能,并在一定程度上减少锁行,锁表带来的性能损耗。
纵向分表的原则是什么呢,应该怎样拆分呢?答案是根据业务逻辑的需要来拆分,对于一张表如果业务上分两次访问某一张表其中一部分数据,那么就可以根据每次访问列的不同来做拆分; 另外还可以根据列更新的频率来拆分,例如某些列每天要更新3次,有些列从创建开始基本上很少更新。
举例:
假定场景,我有一张用户表,这张表包含列:
ID, UserName, Password, RealName, Gender, Email, IsEmailValid, Birthday, Country, City, Address, Mobile, Phone, ZipCode, Hometown, OfficePhone, Company, Position, Industry, LatestLoginTime, LatestLoginIP, LoginTimes,OnlineMinutes
假定现在我们的登录出现了性能问题,用户登录经常出现数据库超时的现象。我们打算用拆表的方法解决这个问题。先看下涉及到登录的字段有:UserName,Password,LatestLoginTime,LatestLoginIP,LoginTimes;那么我们就可以以此为依据将原表拆分为:UserLogin和UserBase 两个表,后者包含除了登录信息的其他列信息;两张表都要包含主键ID。
2. 横向分区
横向分区是将表从行的角度拆分,例如将创建时间在05年之前的数据放在一个分区上,将05年到08年之间的数据放到另一个分区上,以此类推。横向分区所根据的列必须在聚集索引上,通常会根据时间,主键id等进行划分。
横向分区将数据划分为不同的区,在根据分区列条件进行查询时可以缩小查询的范围,从而提高查询的性能;另外如果数据库服务器有多个cpu,则可以通过并行操作获得更好的性能。
到底要根据那个列进行横向的分区和查询有关系,我们在建表的时候需要分析,会根据那个列进行查询。
举例:
- 订单是一个实效性很强的实体,我们很少查询几年前的订单数据,我们就可以在订单的创建时间列上创建分区函数来做分区。
- 比如帖子通常情况下只有在首页推荐的最新的帖子被访问次数很多,而几年前的帖子被访问的几率较小,这时候我们可以根据帖子的主键id来做分区,id小于300w的在一个分区上,id在300到600w之间的在一个分区上。














 3148
3148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









