







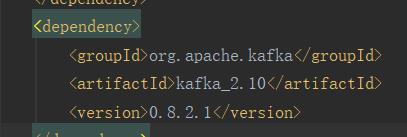
Note:spark1.6版本,kafka版本要是0.8.21
咳咳,pom文件自己去配
代码示例:
def main(args:Array[String]):Uint={
val conf=new SparkConf().setAppName("test) //在集群中运行可以不指定master
val sc=new SparkContext(conf)
// 定义topic
val topic=Set("callcentor") //callcentor为topic的名称
//定义bootstraps
val bootstraps="localhost:9092" //我是在集群单机版测试的,localhost 可以改成对应的地址
//定义kafka参数
val kafkaparams=Map[String,String](
"bootstrap.servers"->bootstraps,
"groupid"->"test",//消费者组的名字
"auto.offset.reset"->"smallest" //从最小的offset可以取
"key.deserializer"->"org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer"->"org.apache.kafka.com
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









