







目录
前言
进程是Linux里面很重要的一个概念,,进程就是指运行中的的程序,是程序动态运行过程的描述(这里的描述包含标识符、内存指针、上下文数据、程序计数器等),也可以称之为pcb(进程控制块)。
虚拟地址和真实地址不一样,但他们之间又有对应关系。
进程详解
进程要区别于程序,程序是死的,写完的程序只要没有被运行就不会占用内存,他们只是被存放到了电脑的磁盘里,当程序需要运行时,电脑会把程序加载到cpu里,此时这个正在运行的程序就叫进程,也就是说进程就是正在运行的程序,他是会占用内存空间的。
进程可以用pcb来描述,而pcb在linux下是task_struct,这是一种数据结构,可以看做是结构体,里面包含了进程的相关信息。电脑要想对一个进程进行操作控制,就得找到这个进程的描述(pcb)。
task_struct内容
task_struct包含着与进程相关的信息,如下:
1、标识符(唯一描述程序、决定程序的归属)
2、状态(有5种基本状态)
3、优先级
4、程序计数器(程序中即将被执行的下一条指令的地址)
5、内存指针
6、上下文数据(程序执行时,寄存器中的数据)
7、I/O状态信息
8、记账信息
9、其他信息
进程状态
运行态(R):正在执行或拿到时间片就可以执行的状态。
可中断休眠态(S):因某种条件不满足而暂时不能运行的状态。一旦某种条件成立,则被唤醒
不可中断休眠态(D):和上一个一样不可运行,但即使各个条件都成立也无法被唤醒
停止态(T):什么都不做的状态。
僵死态(Z):进程已经退出了,但是资源并没有完全释放,正在等待处理的一种状态。
创建子进程
在linux里创建子进程我们可以用fork,该函数头文件#include <unistd.h>,有一个返回值,这个返回值在不同的进程中是不一样的。
在父进程中fork的返回值是子进程的pid(每个进程都有唯一一个pid)
在子进程中的返回值是0
创建失败时返回值都是-1
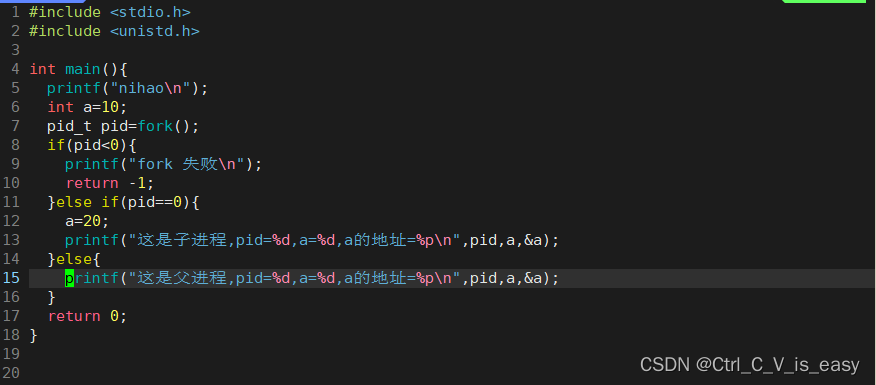
例如:
#include <stdio.h>
#include <unistd.h>
int main(){
printf("nihao\n");
int a=10;
pid_t pid=fork();
if(pid<0){
printf("fork 失败\n");
return -1;
}
else if(pid==0){
a=20;
printf("这是子进程,pid=%d,a=%d\n",pid,a);
}
else{
printf("这是父进程,pid=%d,a=%d\n",pid,a);
}
return 0;
}
程序执行的结果如上,可以看到,父进程和子进程里pid的返回值不一样,还有一件事,那就是a这个变量,同一个变量在不同的进程中的值不同,
如果我们打印一下a的地址

可以发现a的地址居然是一样的,按理来说同一个地址上的变量不可能出现两个不同的值,难道这是量子力学?还能搞出叠加态?
其实这是因为打印出来的a变量的地址不是真实地址,而是个虚拟地址,设置虚拟地址的好处就是防止像野指针这样的变量访问不该访问的内存地址,以及防止内存碎片,提高内存使用率。
内存地址
进程中访问的变量地址是虚拟地址,虚拟地址可以提高内存利用率,实现离散式存储,实现内存访问控制。
比如一个内存总大小为16M,现在里面已经占用了13M,如果再想加载一个7M的进程进去,是无法实现的,因为内存不足。

如果我们退出一个4M的进程呢,现在剩余内存为7M,结果也是不行的,因为虽然内存剩余7M,但这7M内存不连续,所以无法再加载一个7M的进程。这就是内存碎片化的问题,那么这个问题该如何解决呢?

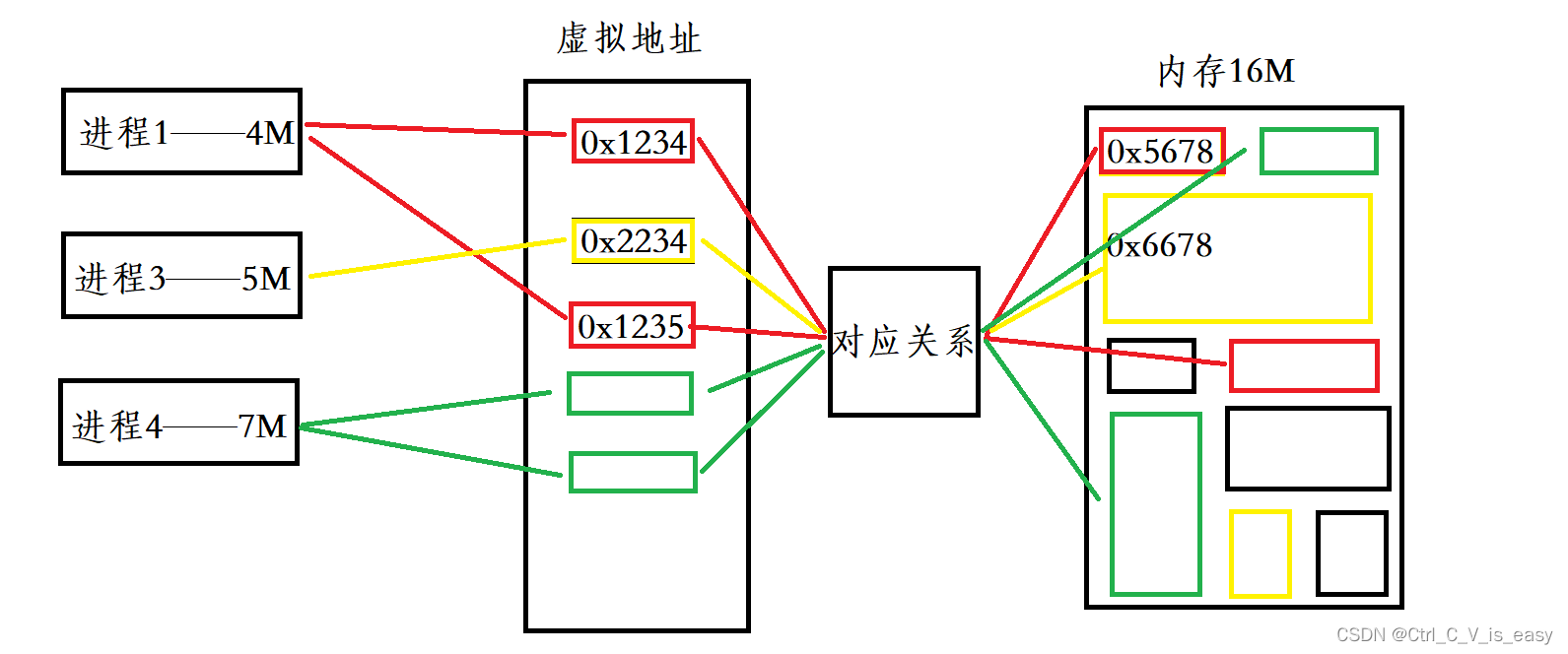
实际上,如果一个进程大小为4M,那么把它加载进cpu其实是用不到4M大小的,只需要把需要运行的变量,函数等加载上去就行了,其实际内存占用是不到4M的。所以有一个思路就是上面提到的虚拟地址。虚拟地址和实际地址之间是有一个联系的,他们有一个对应关系表。
例如:进程1里面的两个地址为0x1234、0x2234的变量,他们通过对应关系对应到真实地址里面,由图可知在虚拟地址里连续的两个变量,在真实地址里不一定连续,这就是离散式存储,可以提高内存利用率。
如果我们定义一个野指针,野指针的虚拟地址通过对应关系对应到内存里去发现该真实地址不属于这个进程应该访问的空间时就会直接报错退出,所以这样的野指针就无法访问它不该访问的内存了,这样的结构更加安全。














 3869
3869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









