







序列化与反序列化
什么是序列化,反序列化
- 序列化 --通过某种方式把数据结构或对象写入的磁盘文件中或通过网络传到其它结点的过程,也就是将对象的状态信息转换为可以存储或传输的形式的过程
- 反序列化 --把磁盘中对象或者把网络结点中传输的数据恢复为Python的数据对象的过程,是将有序的二进制序列转换成某种对象(字典,列表)的过程
什么是Json
- Json(JavaScript Object Notation)是前后端交互的枢纽,相当于编程界的普通话
- Json在现代编程中广泛应用,它是一种轻量级的数据交换格式,采用完全独立于编程语言的文本格式来存储和表示数据,简洁和清晰的层次结构使得Json成为理想的数据交换语言,易于人类阅读和编写,同时也易于机器解析和生成,并有效的提升网络传输效率
标准库:json
Python 提供了内置的Json库,允许在Python中解析和序列化Json数据
Json类型和格式转换
Json 和 Python内置的数据类型对应
| Python | Json |
|---|---|
| dict | object{} |
| list,tuple | array([]) |
| int,long,float | number |
| True | true |
| False | false |
| None | null |
Json模块
Python 3 可以使用 Json 模块来对JSON数据进行编码解码
主要提供了四个方法
- 序列化
-- json.dump() # 对python对象进行序列化,且可以进行文件操作,可以将序列化的结果编码存储到文件中。
-- json.dumps() # 对Python对象进行序列化,无法进行文件操作,可以将Pythin对象编码存储到变量中。
- 反序列化
-- json.load() # 对json对象进行反序列化,且可以进行文件操作,可以将json文件中的数据解码出来存储到Python对象中。
-- json.loads() # 对json对象进行反序列化,不可以进行文件操作,可以将json格式的数据解码出来保存到Python对象中。
dump函数\dumps函数
dump函数
dump 参数:
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, iudnet=None, separators=None, default=None, sort_keys=False, **kw)
dumps函数
dumps函数不需要传输文件描述符
dumps 参数:
json.dump(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, iudnet=None, separators=None, default=None, sort_keys=False, **kw)
参数说明
| 参数 | 说明 |
|---|---|
| obj | 表示要序列化的对象 |
| fp | 文件描述符,将序列化的字符串保存在文件中 |
| ensure_ascii | 默认值为True,能将所传出的非ASCII字符转义输入,如果ensure_ascii为False,则这些字符将按原字符输出,包括中文 |
| check_circular | 默认值为True,循环类型检查,如果check_cirular为False,则将跳过对容器类型的循环引用检查,循环引用将导致OverflowError |
| allow_nan | 默认值为True,确定是否为允许值 |
| indent | 默认值为Noen,设置缩进格式,当设置indent时,会以美观的方式来打印Json |
| separators | 默认为None,去除分隔符后面的空格 |
| sort_keys | 默认为False,如果sort_keys为True,则字典的输出按键值顺序来 |
示例
样例数据
# python对象
dict_data = {"province": "浙江省", "city": "杭州市", "area": "西湖区", "posd_code": 310000}
dumps默认形式打印
json_data = json.dumps(dict_data) # 将Python对象转换成Json对象
print(json_data)
# 输出结果: 中文转义成了二进制数据
# {"province": "\u6d59\u6c5f\u7701", "city": "\u676d\u5dde\u5e02", "area": "\u897f\u6e56\u533a", "post_code": 310000}
dumps转义后保持原字符格式不变
json_data = json.dumps(dict_data, ensure_ascii=False)
print(json_data)
# 输出结果:ecsure_ascii 参数改为False,就不会进行ASCII编码转义了
{"province": "浙江省", "city": "杭州市", "area": "西湖区", "post_code": 310000}
dumps根据键值排序
json_data = json.dumps(dict_data, ensure_ascii=False, sort_keys=True)
print(json_data)
# 输出结果: sort_keys = True 表示打开键值排序
{"area": "西湖区", "city": "杭州市", "post_code": 310000, "province": "浙江省"}
以比较美观的形式打印Json数据
json_data = json.dumps(dict_data, ensure_ascii=False, indent=1)
print(json_data)
# 输出结果
{
"province": "浙江省",
"city": "杭州市",
"area": "西湖区",
"post_code": 310000
}
load函数\loads函数
load函数
json.load(fp, *, cls=None, check_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
loads函数
json.loads(s, *, ecnoding=None, cls=None, check_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
参数说明
| 参数 | 说明 |
|---|---|
| fp | 文件描述符,将fp(.read() 支持包含JSON文档的文本文件或二进制文件)反序列化为Python对象 |
| s | 将s(包含JSON文档的str,bytes或bytearray实例)反序列化为Python对象 |
| encoding | 指定一个编码的格式 |
| object_hook | 默认值为None,object_hook是一个可选函数,此功能可用于实现自定义解码器,指定一个函数,该函数负责把反序列化的基本类型对象转换成自定义类型的对象 |
| parse_float | 默认值为None ,如果指定了parse_flaot,用来对JSON float字符串进行解码,这可用于为JSON浮点数使用另一种数据类型或解析器 |
| parse_int | 默认值为None ,如果指定了parse_int,用来对JSON int字符串进行解码,这可用于为JSON浮点数使用另一种数据类型或解析器 |
示例
loads函数将json数据转换为Python对象
# json数据
json_data = '{"province": "浙江省", "city": "杭州市", "area": "西湖区", "post_code": 310000}'
# 转换成python对象
py_data = json.loads(json_data)
print(py_data,type(py_data))
# 输出结果:
{'province': '浙江省', 'city': '杭州市', 'area': '西湖区', 'post_code': 310000}
<class 'dict'> # 数据类型为dict
其他操作
读写文件
# json文件位置
file = 'test.json'
jsonFile = os.path.join(os.getcwd(), file)
if not os.path.exists(jsonFile):
open(jsonFile, "w").close()
# 写json文件
with open(jsonFile,"w") as fp:
city_data = {"province": "浙江省", "city": "杭州市", "area": "西湖区", "post_code": 310000, "time":time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())}
# 写入
print(f"写入Json内容:{city_data}")
json.dump(city_data, fp, ensure_ascii=False, indent=1)
print(f"数据写入{file}成功!")
# 读取json文件内容
with open(jsonFile,"r") as fp:
result = json.load(fp)
print(f"读取{file}文件内容:{result}")
# 输出内容:
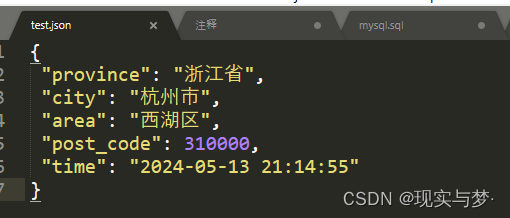
写入Json内容:{'province': '浙江省', 'city': '杭州市', 'area': '西湖区', 'post_code': 310000, 'time': '2024-05-13 21:14:55'}
数据写入test.json成功!
读取test.json文件内容:{'province': '浙江省', 'city': '杭州市', 'area': '西湖区', 'post_code': 310000, 'time': '2024-05-13 21:14:55'}
类对象转JSON
class Citys:
def __init__(self, province: str, city: str, phone: int):
self.province = province
self.city = city
self.__phone = phone
@property
def tojson(self):
return {
'province': self.province,
'city': self.city,
'phone': self.__phone
}
cts = Citys("浙江省", "杭州市", 310000)
print("类转json------------第一种方式")
json_data = json.dumps(cts.__dict__, indent=1, ensure_ascii=False)
print(json_data)
print("类转json------------第二种方式")
json_data = json.dumps(cts.tojson, indent=1, ensure_ascii=False)
print(json_data)
# 输出结果:
类转json------------第一种方式
{
"province": "浙江省",
"city": "杭州市",
"_Citys__phone": 310000
}
类转json------------第二种方式
{
"province": "浙江省",
"city": "杭州市",
"phone": 310000
}
Json转类对象
class_data = json.loads(json_data)
c = Citys(class_data["province"],class_data["city"], class_data["phone"])
print("c.type:", type(c))
print(c.tojson.items())
# 输出结果:
c.type: <class '__main__.Citys'>
dict_items([('province', '浙江省'), ('city', '杭州市'), ('phone', 310000)])
特殊类型的处理
# JSON库提供了对于处理特殊类型(如自定义对象,日志等)的方法
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 通过自定义编码器,可以将自定义对象转换为JSON
def custom_encoder(obj):
if isinstance(obj, Person):
return {"name": obj.name, "age":obj.age}
raise TypeError('Object of type Persoon is not JSON serializable')
persion = Person('张三', 20)
json_data = json.dumps(persion, default=custom_encoder, ensure_ascii=False)
print(json_data)
# 输出结果:
{"name": "张三", "age": 20}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











