







https://www.microsoft.com/en-us/research/blog/fara-7b-an-efficient-agentic-model-for-computer-use/
In 2024, Microsoft introduced small language models (SLMs) to customers, starting with the release of Phi(opens in new tab) models on Microsoft Foundry(opens in new tab), as well as deploying Phi Silica(opens in new tab) on Copilot+ PCs powered by Windows 11. Today, we are pleased to announce Fara-7B, our first agentic SLM designed specifically for computer use.
Unlike traditional chat models that generate text-based responses, Computer Use Agent (CUA) models like Fara-7B leverage computer interfaces, such as a mouse and keyboard, to complete tasks on behalf of users. With only 7 billion parameters, Fara-7B achieves state-of-the-art performance within its size class and is competitive with larger, more resource-intensive agentic systems that depend on prompting multiple large models. Fara-7B’s small size now makes it possible to run CUA models directly on devices. This results in reduced latency and improved privacy, as user data remains local.
Fara-7B is an experimental release, designed to invite hands-on exploration and feedback from the community. Users can build and test agentic experiences beyond pure research—automating everyday web tasks like filling out forms, searching for information, booking travel, or managing accounts. We recommend running Fara-7B in a sandboxed environment, monitoring its execution, and avoiding sensitive data or high-risk domains. Responsible use is essential as the model continues to evolve.
Fara-7B operates by visually perceiving a webpage and takes actions like scrolling, typing, and clicking on directly predicted coordinates. It does not rely on separate models to parse the screen, nor on any additional information like accessibility trees, and thus uses the same modalities as humans to interact with the computer. To train Fara-7B, we developed a novel synthetic data generation pipeline for multi-step web tasks, building on our prior work (AgentInstruct). This data generation pipeline draws from real web pages and tasks sourced from human users.
2024年,微软开始向客户推出小型语言模型(SLM),首先在Microsoft Foundry平台发布了Phi系列模型,并在搭载Windows 11的Copilot+ PC上部署了Phi Silica。今天我们正式发布Fara-7B——这是首款专为计算机操作设计的智能体SLM。
与传统生成文本回复的聊天模型不同,Fara-7B这类计算机操作智能体(CUA)模型能通过鼠标键盘等界面工具代用户完成任务。仅70亿参数的Fara-7B在其体量级别中实现了顶尖性能,甚至可以媲美依赖多个大模型协同工作的资源密集型智能体系统。其小巧体型首次实现了设备端直接运行CUA模型,既能降低延迟,又因数据本地处理而增强隐私保护。
本次发布的Fara-7B为实验版本,旨在邀请社区参与实践探索与反馈。用户可突破纯研究范畴,构建测试各类智能体应用场景——例如自动填写表单、信息检索、旅行预订或账户管理等日常网页任务。建议在沙盒环境中运行Fara-7B,监控其执行过程,避免处理敏感数据或高风险领域。随着模型持续进化,负责任的使用至关重要。
Fara-7B通过视觉感知网页内容,直接在预测坐标上执行滚动、键入和点击等操作。它不依赖额外模型解析屏幕元素,也无需辅助功能树等附加信息,完全模拟人类与计算机的交互方式。为训练该模型,我们在AgentInstruct研究基础上开发了创新的合成数据生成流程,其素材均源自真实网页及人类用户的实际任务场景。
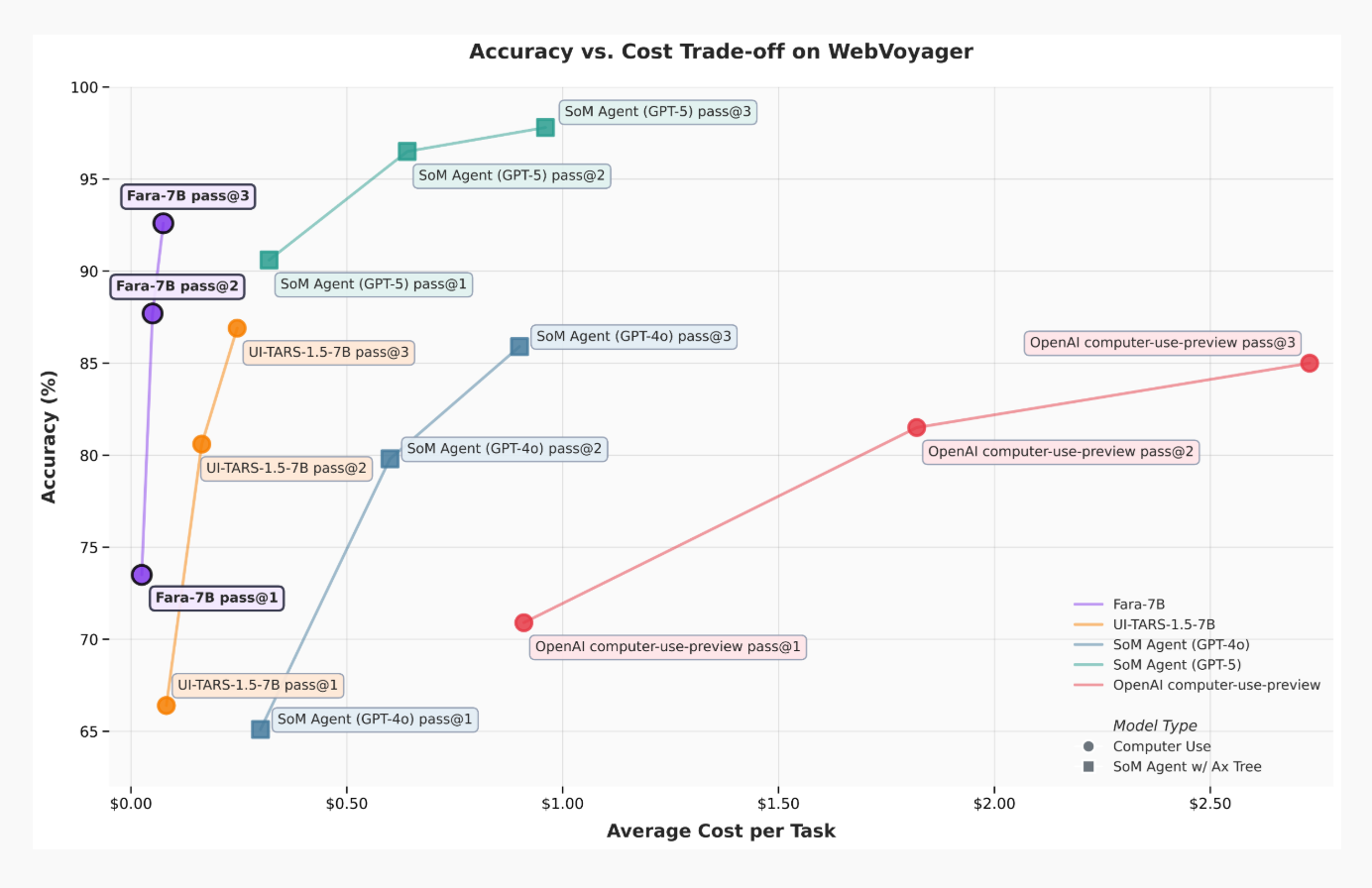
Fara-7B exhibits strong performance compared to existing models across a diverse set of benchmarks. This includes both existing benchmarks as well as new evaluations we are releasing which cover useful task segments that are underrepresented in common benchmarks, such as finding job postings and comparing prices across retailers. While Fara-7B demonstrates strong benchmark results, even against much larger models, it shares many of their limitations, including challenges with accuracy on more complex tasks, mistakes in following instructions, and susceptibility to hallucinations. These are active areas of research, and we’re committed to ongoing improvements as we learn from real-world use.
Fara-7B is now available on Microsoft Foundry(opens in new tab) and Hugging Face(opens in new tab) under an MIT license and is integrated with Magentic-UI, a research prototype from Microsoft Research AI Frontiers(opens in new tab). We are also sharing a quantized and silicon-optimized version of Fara-7B, is available to install and run on Copilot+ PCs powered by Windows 11, for turnkey experimentation. The community can simply download the pre-optimized model and run it in their environment.
By making Fara-7B open-weight, we aim to lower the barrier to experimenting with and improving CUA technology for automating routine web tasks, such as searching for information, shopping, and booking reservations.
与现有模型相比,Fara-7B在多样化基准测试中展现出强劲性能。这既包括现有基准测试,也涵盖我们最新发布的评估方案——这些方案聚焦于常见基准中代表性不足的实用任务领域,例如职位招聘信息检索和跨零售商比价。虽然Fara-7B即便面对体量更大的模型仍能交出亮眼成绩单,但它同样存在此类模型的固有局限,包括复杂任务准确率不足、指令执行偏差以及易产生幻觉等问题。这些正是我们重点攻关的研究方向,我们将基于实际应用反馈持续优化模型。
Fara-7B现已通过MIT许可证在Microsoft Foundry(新标签页打开)和Hugging Face(新标签页打开)平台发布,并与微软研究院AI Frontiers(新标签页打开)的研究原型Magentic-UI完成集成。我们还同步提供了量化版及硅片优化版Fara-7B,可一键安装运行于Windows 11驱动的Copilot+ PC设备,便于开箱即用的实验探索。开发者社区可直接下载预优化模型并在本地环境中部署运行。
通过开源Fara-7B的权重参数,我们致力于降低CUA(常规网络任务自动化)技术的应用门槛,推动信息检索、在线购物、预约预订等场景的技术改良。
Developing Fara-7B
CUA multi-agent synthetic data generation
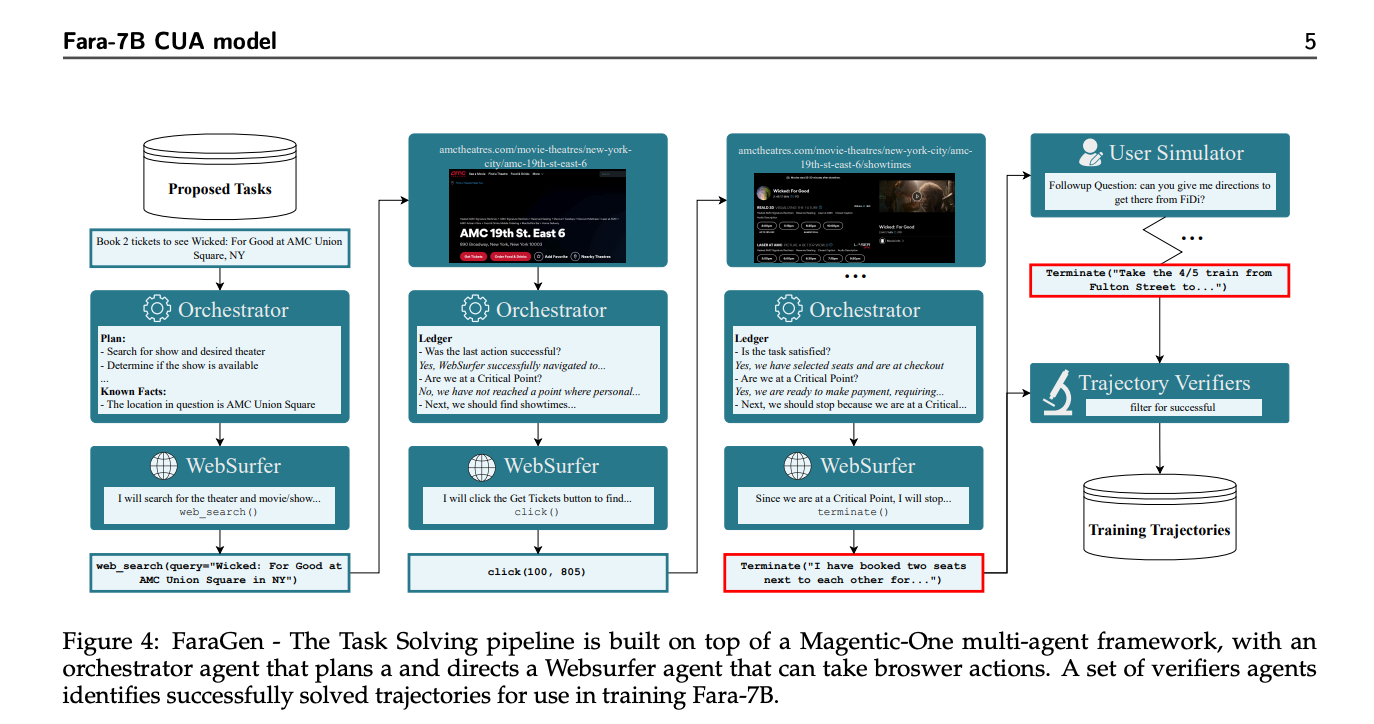
A key bottleneck for building CUA models is a lack of large-scale, high-quality computer interaction data. Collecting such data with human annotators is prohibitively expensive as a single CUA task can involve dozens of steps, each of which needs to be annotated. Our data generation pipeline (Figure 2) avoids manual annotation and instead relies on scalable synthetic data sourced from publicly available websites and custom task prompts. We build this pipeline on top of the Magentic-One framework, and it involves three main stages:
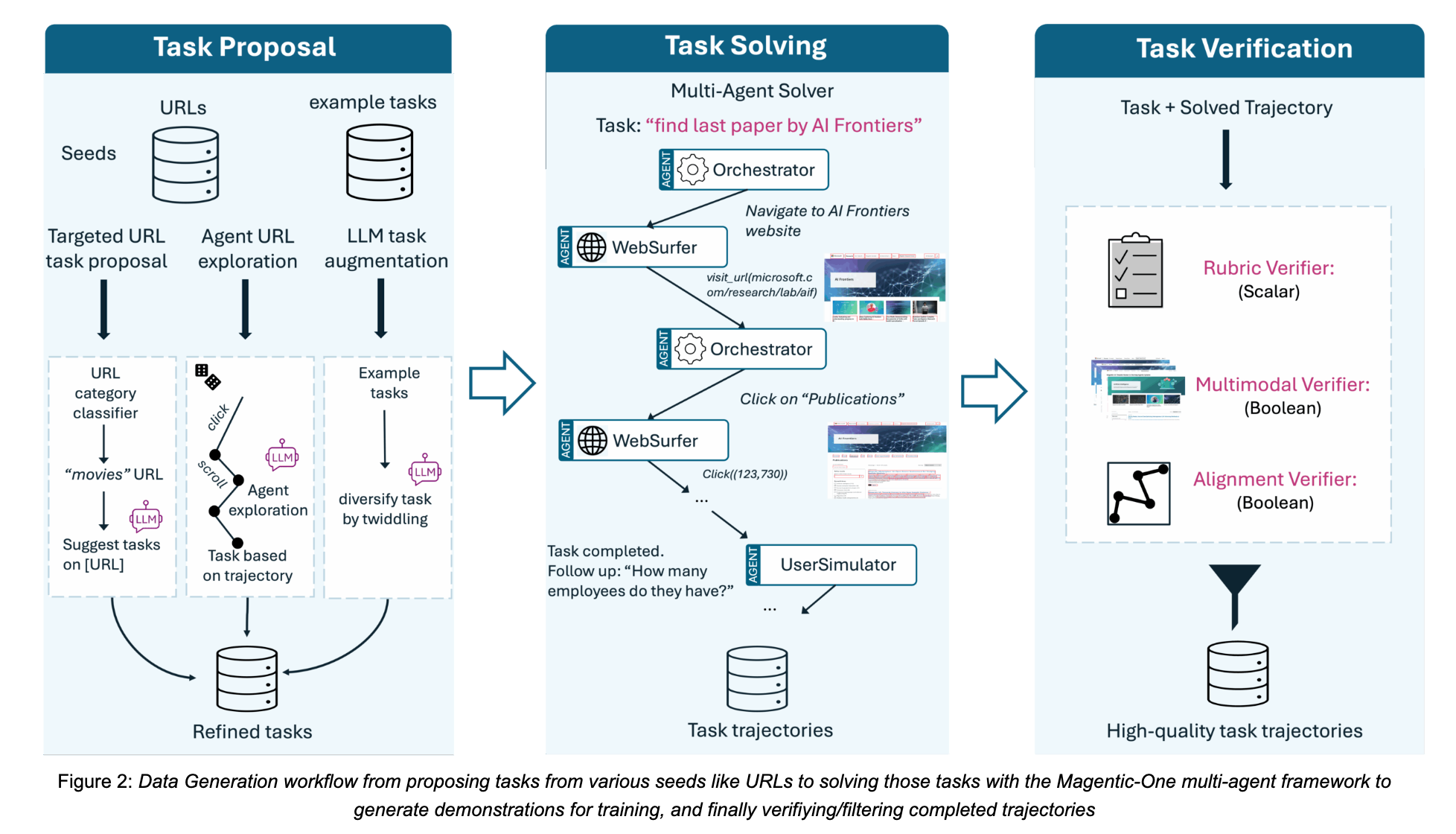
Task Proposal. We generate a broad set of synthetic tasks that mirror common user activities on the web. To ensure coverage and diversity, tasks are “seeded” by a web index of public URLs classified into various categories e.g., shopping, travel, restaurants, etc. This enables task generation targeting a particular skill, like “book 2 tickets to see the Downton Abbey Grand Finale at AMC Union Square, NYC.” from a URL like this(opens in new tab) classified as “movies”. As another strategy, we devised a way to generate tasks from randomly sampled URLs. Each task starts with a general prompt and is iteratively refined as an LLM agent explores the website and gathers more information about it. We are releasing a held-out subset of these tasks as a benchmark (“WebTailBench”), described in the Evaluation section below.
Task Solving. Once synthetic tasks are generated, a multi-agent system built on Magentic-One attempts to complete them to generate demonstrations for supervised finetuning. The multi-agent system uses an Orchestrator agent to create a plan and direct a WebSurfer agent to take browser actions and reports results. The Orchestrator monitors progress, updating plans as needed, and can end tasks or engage a UserSimulator agent if user input is required, allowing for multi-turn completion. Each task and corresponding sequence of observations, actions, and agent thoughts forms a “trajectory”.
Trajectory Verification. Before using any tasks for training, three verifier agents evaluate if a task was “successful”: The Alignment Verifier checks if the trajectory of actions match the task’s intent; the Rubric Verifier defines completion criteria and scores the trajectory against them; and the Multimodal Verifier reviews screenshots and responses to confirm visual evidence supports successful completion. Trajectories failing these standards are removed.
We ultimately train this version of Fara-7B on a dataset of 145,000 trajectories consisting of 1 million steps covering diverse websites, task types, and difficulty levels. Additionally, we include training data for several auxiliary tasks, including grounding for accurate UI element localization, captioning, and visual question answering.
Training Fara-7B
Using one compute use model is easier than a multi-agent system, particularly when it comes to deployment. Therefore, we distill the complexities of our multi-agent solving system into a single model that can execute tasks. Fara-7B is a proof-of-concept that small models can effectively learn from complex, multi-agent systems with lots of bells and whistles.
As shown in Figure 3, Fara-7B is trained to execute user tasks by perceiving only browser window screenshots (without relying on accessibility trees), and predicting single-step actions. For each step, the context used to make its prediction contains all user messages, the complete action history, and the latest three screenshots.
In its prediction, Fara-7B outputs a reasoning message (“thinking” about the next action) followed by a tool call. The available tools include standard Playwright(opens in new tab) mouse and keyboard actions, such as click(x,y) and type(), and browser-specific macro-actions like web_search() and visit_url().
Fara-7B uses Qwen2.5-VL-7B(opens in new tab) as its base model due to its strong performance on grounding tasks and its ability to support long contexts (up to 128k tokens). We linearize the solving pipeline’s trajectories into a sequence of “observe-think-act” steps that are suitable for training with supervised finetuning loss. We did not use reinforcement learning to achieve the results we report below.
论文
https://arxiv.org/abs/2511.19663
https://arxiv.org/pdf/2511.19663
开源
Fara-7B: An Efficient Agentic Model for Computer Use
https://huggingface.co/microsoft/Fara-7B
# 1. Clone repository
git clone https://github.com/microsoft/fara.git
cd fara# 2. Setup environment
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
playwright install
https://github.com/microsoft/fara
微软介绍
https://www.microsoft.com/en-us/research/blog/fara-7b-an-efficient-agentic-model-for-computer-use/
微软 Azure
https://labs.ai.azure.com/projects/fara-7b/

















 20
20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









