







1.数组
1.1数据结构
就是计算机存储和组织数据的一种方式,存储方式不同,带来的操作性能不同,所以合理选择数据结构会有效提高程序的运行效率和存储效率。
1.2数组概述及特性
连续存储,每个数据都有不同的下标
下标从0开始计算
数组长度确定后不可改变
有length属性保存了数组长度
数组是引用类型 :占用两块空间,栈内存一块
数组特性:查询修改效率极高,添加删除效率低
1.3数组声明
数组声明方式有三种,两种静态声明,一种动态声明,如果创建数组前明确数组内的值,则用静态声明,如果没有数组内的值,则用动态声明
静态声明:
1. 数据类型[] 变量名 = new 数据类型[]{值1,值2,值3。。。};
int[] array = new int[] {1,1,4,5,1,4};
2.数据类型[] 变量名 = {值1,值2,值3。。。 };
int[] array = {1,1,4,5,1,4};
动态声明:
数据类型[] 变量名 = new 数据类型[n];
int[] array = new int[6];
动态数组内的值默认值为0例如, 注:这里与二维数组略有不同
array[0] = 0;
1.4数组存储方式
数组同接口,类都是是引用类型 ,引用类型存储在堆内存中
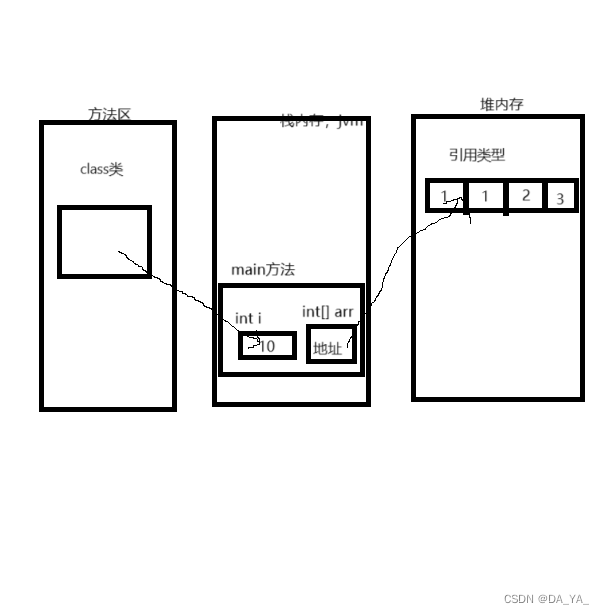
1.5 数据使用
动态创建数组时,会保存对应类型的默认值
整数0,小数0.0,布尔型false,字符型\u0000 ,引用类型 null
int[] arr2 = new int[5];
//查询 数组[下标] 从下标0开始
//修改数组方法: 数组[下标] = 值;
//数组长度 : 数组.length
//数组最后一个元素: 数组名[数据名.length-1]
// 数组遍历通常使用for循环:for(int i=0;i<数组名.length;i++){}
1.6数组常见异常
1.空指针异常
当数组创建时会在堆内存中开辟一个数组空间,创建的数组对象是一个指针,指向堆内存中数组空间,比如创建的数组是arr,int[] arr = new int[3],这时会在堆内存中开辟长度为3的数组空间,由于是动态创建的int类型数组,里面的三个值是0; arr记录的数据是堆内存数组的地址。
arr = null;
这是内存清空,不再有指针指向堆内存中的地址,java会将堆内存中的数组当作“垃圾”释放掉,
在输出arr时会报空指针异常错误。
2.下标越界
arr = new int[]{1,5,6};
sout(arr[5]);
创建的数组长度等于三,存储了三个值,分别是1,5,6,最后一个值的下标是2,即arr[2]=6;
当输出arr[3]的时候超过了数组的长度,会报越界错误。
1.7数组传递
创建整型int变量时,语句:int i = 1;
创建双字符double变量时,语句:double d = 1.0d;
创建数组变量时,语句: int[] arr = new int[]{1,2,3};
所以数组字面量类型是: new int[]{1,2,3};
数组输出时应该是 Syste.out.print(new int[]{1,2,3});
输出结果为存储数组的地址。
1.8传值和传址
传值:
psvm{
int a=0; a1(a);
}
psv a1(int n){
n++; sout(n);
}
当传入方法中的数据类型是基本数据类型时,在执行方法时会在栈内存中开辟一个main方法空间,里面存储着一个基本数据类型,例如int a = 0; 还存储着一个方法void a1(int n){ n++; print(n);} 在执行main方法时会在栈内存中额外开辟一个空间,先在栈中存储方法a1,然后在a1中的创建一个int类型的数据a = 0; 这个a 与 main方法中的a存在在两个不同的空间中,相互独立,其中一个改变另一个不会有影响。输出出来的结果为1,但是main中的a依然是0;
传址:
psvm{
int[] a = new int[]{1,2,3};
a1(a);
}
psv a1(int[] n){
fori{ a[i] =0; System.out.print( a[i] ); }
}
当传入方法的数据类型是引用类型时。这里将上面的基本数据类型中的int换成引用数据类型中的int数组,数据记录的是地址。内存运行同上,不同的是传入a1方法中的数据不是值,而是数组的地址(因为数组记录的是地址,其值存储在堆内存中),方法中根据传入的地址找到堆内存中存储数组的值的空间,直接修改这里的数据,所以main方法中的数组因为是同一个地址,输出的值也会发生变化。这便是传址。
1.9数组复制
数组复制的API:arraycopy(src,begin1,dest,begin2,num);
src:源数组
begin1:源数组起始位置
dest:目标数组
begin2:目标数组起始位置
num:复制个数
2.二维数组
2.1数组声明
//二维数组也有三种声明方式,同一为数组有两种静态声明,一种动态声明
静态声明1:数据类型[][] 变量名 = new 数据类型[][]{值1,值2,.....}
静态声明2:数据类型[][] 变量名 = {值1,值2,....}
注:这里的值的数据类型是引用类型的数组,在一维数组中,拿int[]数组举例,里面存储的都是int数据类型,在二维数组中,int[][]数组存储的都是一维数组int[].
2.2数组存储
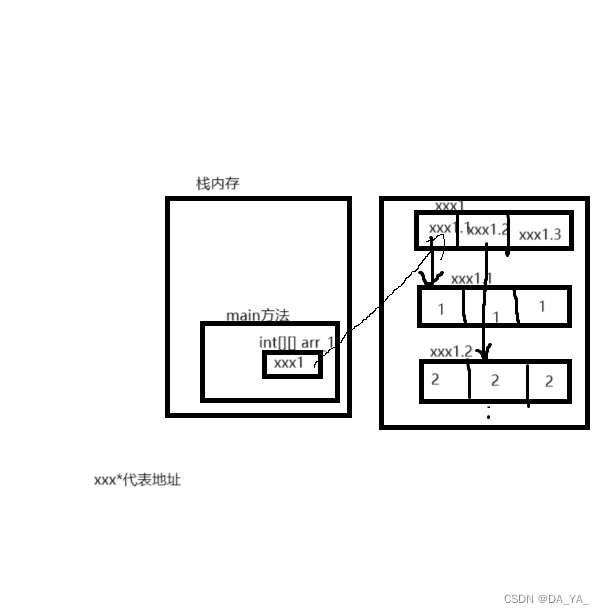
2.3数组使用
查询: 数组[下标]
修改: 数组[下标] = 值;
//二维数组遍历
一维数组使用for循环,二维数组使用两层for循环嵌套
3.排序
排序就是指让保存的元素按照一定的规则进行排序存储
比如 成绩 降序排序,排序后,前三个值就是前三名
3.1交换变量的值
交换方式:
int x=10; int y=11; int z=x; x=y; y=z;
或者 int x = 10; int y =10; x = x^y; y = x^y; x = x^y;
或者 x = x+y ; y = x-y; x = x-y;
3.2冒泡排序
升序原理: 1.使用for循环对相邻两个元素进行比较,如果第一个值大于第二个值则交换位置,
2.对所有元素,进行重复操作,比较完一轮之后,最后一个一定是最大的元素
3重复第一第二步操作,直到没有一对元素可以比较时终止
经过一轮后,最大的数必定会在最后一个位置出现,下次循环就可以不与他比较(优化点)
冒泡使用嵌套循环实现
3.3选择排序
升序原理:1.每次都假设当前元素是最小的,依次和后面所有元素进行比较
2.如果有比当前元素小的,就记录下标,最小值改变
3.比较一轮之后,当前最小值记录的下标就是最小值的位置,放到最前面,
4.重复上轮操作,直到没有一对元素可以比较
4查找元素
4.1顺序查找
顺序查找:从左向右依次查找
缺点:不稳定,数据越靠前,查找次数越少,数据越靠后,查找次数越多,查找次数一次到n次,数据越多越不稳定
二分法查找:必须在已排序的基础上,依次对半查询,效率极高
因为有序,所以一般用于固定的数据查找,但是在有序的条件下,进行添加会比较麻烦,因为要考虑排序情况
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









