







数据、代码等相关资料来源于b站日月光华老师视频,此博客作为学习记录。
本节是对【1】中模型的分解,更具体说明每行代码进行了什么运算。首先导入包、读入数据和预处理的部分不发生改变,如下:
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
# 读入数据
data = pd.read_csv(r'E:\Code\pytorch\第2章\Income1.csv')
# 数据预处理
X = torch.from_numpy(data.Education.values.reshape(-1, 1)).type(torch.FloatTensor)
Y = torch.from_numpy(data.Income.values.reshape(-1, 1)).type(torch.FloatTensor)
初始化线性模型的参数:
# 对于x,需要初始化一个w和b,建立线性模型
# 除之前【1】中的模型外,此处为分解的写法
w = torch.randn(1, requires_grad=True) # 单变量线性回归,所以形状是1
b = torch.zeros(1,requires_grad=True) # 偏置设为0,1维
# 规定学习率
learning_rate = 0.0001
训练5000次:
# 训练5000次
for epoch in range(5000):
for x,y in zip(X, Y):
y_pred = torch.matmul(w,x) + b # 矩阵乘法对w和x相乘,加上b
loss = (y-y_pred).pow(2).mean() # 均方误差的分解写法,差的平方求均值
# 以下相当于opt.zero_grad()
if not w.grad is None: # 为让w和b的梯度不累计,需要置零
w.grad.data.zero_() # zero_表示直接改变w的值,而不是生成新的
if not b.grad is None:
b.grad.data.zero_()
loss.backward()
# 优化变量的,不需要跟踪梯度.相当于opt.step()
with torch.no_grad():
# 沿梯度下降方向计算,就是现有值减梯度值
# 为预防异常值引起模型剧烈震荡,用学习率约束,而不是全部减掉
w.data -= w.grad.data*learning_rate
b.data -= b.grad.data * learning_rate
把更新后的w和b打印出来:

在【1】中,通过一下语句查看权重和偏置大小:
print(model.linear.weight)
print(model.linear.bias)
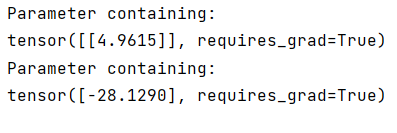
可见是十分相似的。
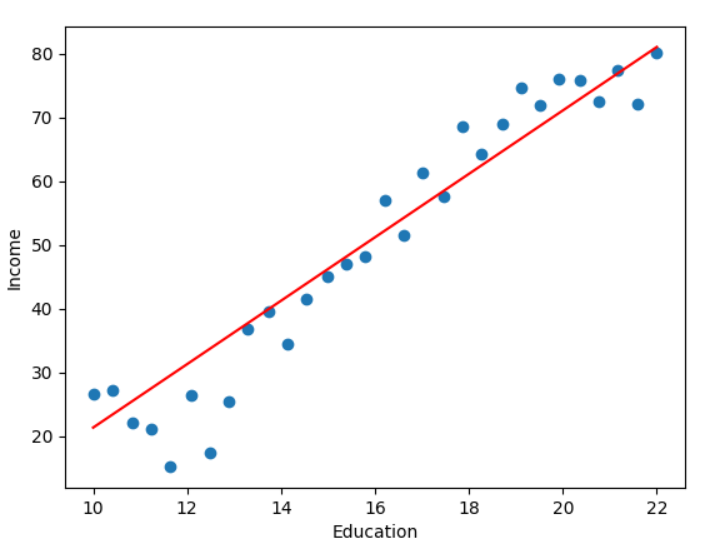
# 绘制散点图和回归曲线
plt.scatter(data.Education, data.Income)
plt.xlabel('Education')
plt.ylabel('Income')
plt.plot(X.numpy(), (X*w + b).data.numpy(), c='r')
plt.show()















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











