







数据、代码等相关资料来源于b站日月光华老师视频,此博客作为学习记录。
- 回归:以曲线拟合数据点,表示从输入变量到输出变量之间映射,回归的目的是预测数组型的目标值。
- 线性回归:根据已知的数据集,通过梯度下降的方法来训练线性回归模型的参数w,从而用线性回归模型来预测数据的未知的类别。
- 逻辑回归:回归的目标是发现特征与特定结果的可能性之间的联系。给出的是一个“是”或“否”的回答。
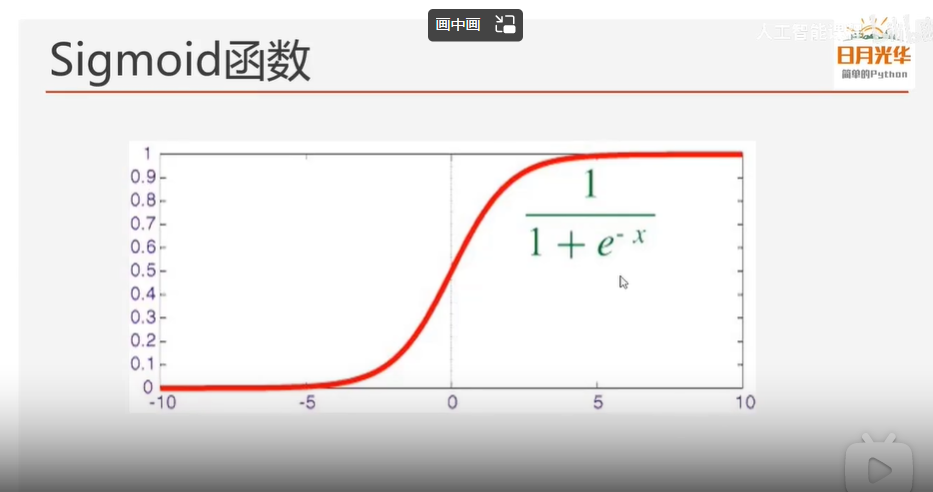
sigmoid函数:把任意x映射到0~1之间的概率值。
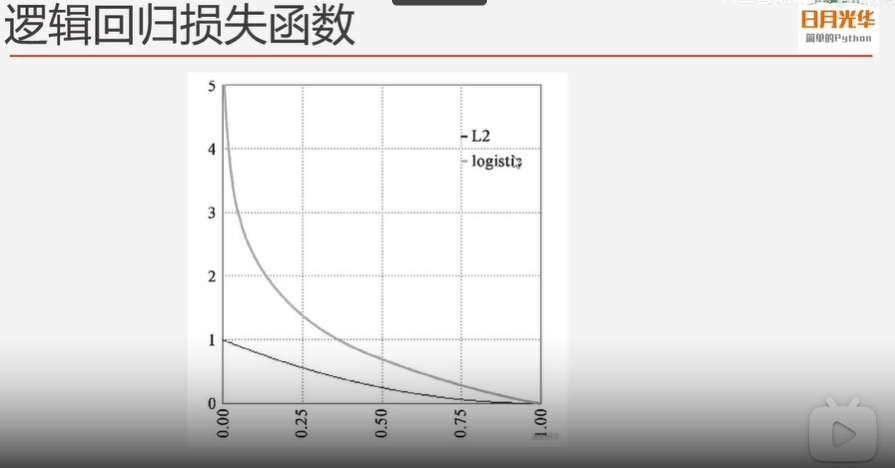
逻辑回归损失函数
平方差所惩罚的是与损失为同一数量级的情形,对于分类问题,我们最好的使用交叉熵损失函数会更有效,交叉熵会输出一个更大的“损失”。
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。
假设概率分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉嫡,则:
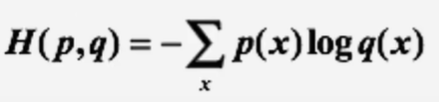
在pytorch中的二元交叉熵损失使用nn.BCEloss()来调用。
实例:
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
data = pd.read_csv(r'E:\Code\pytorch\第4章\credit-a.csv', header=None)
# header = None意为没有表头,防止把第一行当成表头
# 前15列是特征,第16列是结果
X = data.iloc[:,:-1] # 逗号前:表示所有的行,逗号后意思是除最后一列以前的列
Y = data.iloc[:,-1].replace(-1, 0) # 取最后一列作为Y,把里面的-1替换为0
# 数据预处理,转成tensor并且转换成浮点型
X = torch.from_numpy(X.values).type(torch.float32)
# 转成维度为1的数据
Y = torch.from_numpy(Y.values.reshape(-1, 1)).type(torch.float32)
逻辑回归在线性回归的基础上还要再加sigmoid函数,把结果映射成0~1之间的概率值,从而实现二分类。
多个层顺序连接的时候可以使用nn.sequential()方法
# 创建模型
model = nn.Sequential(
nn.Linear(15,1), # 输入的形状是15,输出是1
nn.Sigmoid()
)
打印出来看看:

接下来初始化损失函数、进行训练:
# 初始化损失函数
loss_fn = nn.BCELoss()
opt = torch.optim.Adam(model.parameters(),lr=0.0001)
# 小批量训练方法:单张训练异常值引起震荡,太多显存吃力
batches = 16 # 设定一个batch大小
num_of_batch = 653//16 # 共653个数据,整除需要训练多少次
epoches = 1000 # 所有数据训练一遍叫一个epoch
# 进行训练
for epoch in range(epoches): # 每个epoch
for i in range(batches): # 每个batch
start = i*batches # 第几个batch都乘以固定的16作为起点
end = start + batches # 起头+16就是结尾
x = X[start:end]
y = Y[start:end]
y_pred = model(x)
loss = loss_fn(y_pred,y) # 计算loss
opt.zero_grad() # 梯度置零
loss.backward() # 反向传播
opt.step() # 迭代优化
通过print(model.state_dict())可以查看model的参数:

计算准确率
accurate = ((model(X).data.numpy() > 0.5).astype('int') == Y.numpy()).mean()
print(accurate)
















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











