






近期国内引进了一些动漫电影,然而博主还没有去看~( ̄▽ ̄)~*,外面阳性太多,遂先看看网上的风评如何,兴趣使然,此处就用scrapy来收集下某站上该电影的短评
初始化scrapy项目
初始化项目
# 先安装下依赖包
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1$
pip3 install bs4 scrapy
# 使用scrapy创建一个采集项目douban
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1$ scrapt startproject douban
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1$ ll
total 20
drwxrwxr-x 5 xadocker xadocker 4096 12月 14 15:44 ./
drwxrwxr-x 4 xadocker xadocker 4096 12月 14 15:41 ../
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 17:43 douban/
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 19:08 .idea/
drwxrwxr-x 6 xadocker xadocker 4096 12月 14 15:41 venv/
# 创建一个spider movie_comment
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1$ scrap genspider movie_comment movie.xxx.com
调整settings.py
# 调整settings.py中以下两个参数即可
USER_AGENT = 'User-Agent=Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
至此基本配置算是完成了,接下来就开始编写spider了
电影短评spider编写
上面初始项目时创建了一个名为movie_comment的spider
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1$ ll douban/douban/spiders/
total 20
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 19:39 ./
drwxrwxr-x 5 xadocker xadocker 4096 12月 14 19:40 ../
-rw-rw-r-- 1 xadocker xadocker 161 12月 14 15:43 __init__.py
-rw-rw-r-- 1 xadocker xadocker 1558 12月 14 19:39 movie_comment.py
drwxrwxr-x 2 xadocker xadocker 4096 12月 14 19:39 __pycache__/
使用bs4来解析页面,同时使用css解析器来过滤数据
通过观察页面分析,可以通过css选择器获取具有class=’comment-item’的集合
comment_set = soup.select('.comment-item')
print(type(comment_set))
for user in comment_set:
print(user)
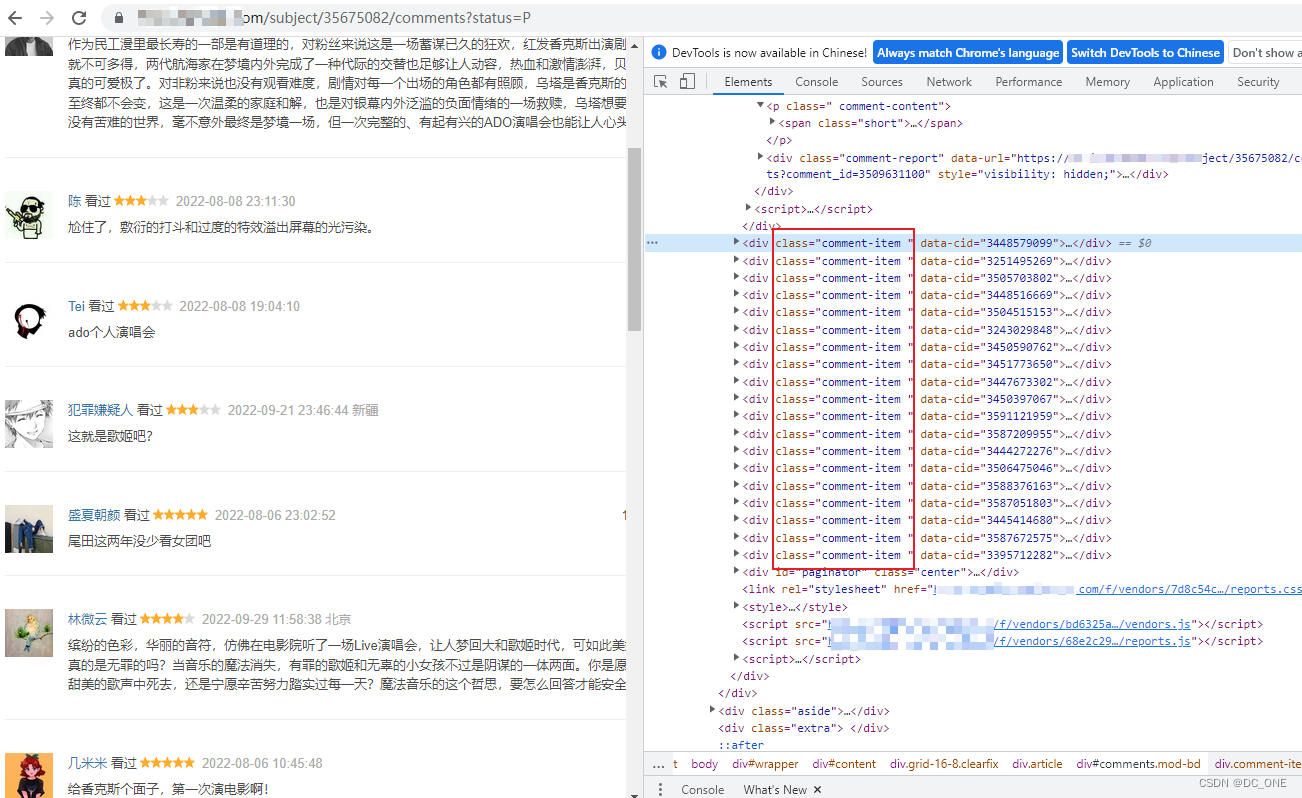
展开其中一个列表,我们先简单的获取第一页的短评中的几个字段:
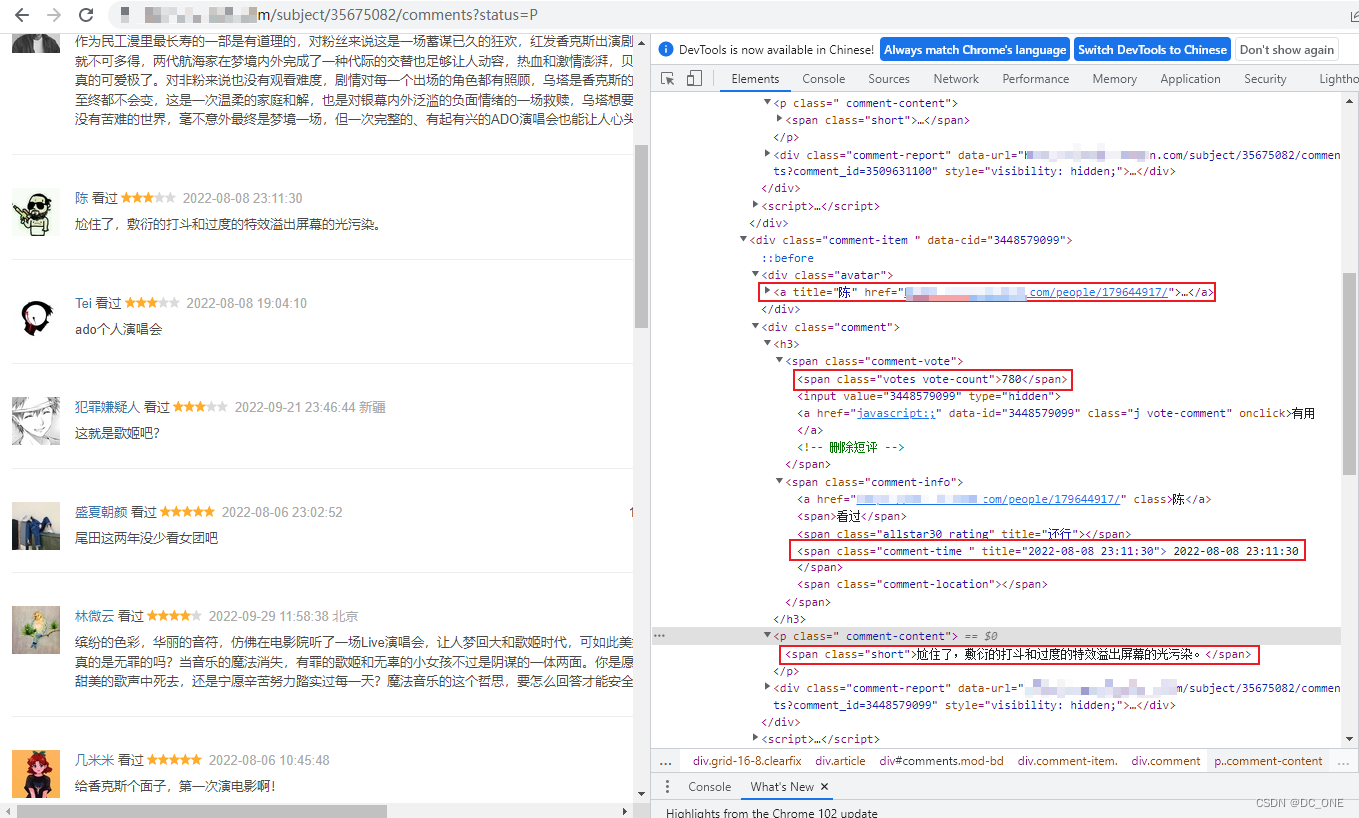
- 用户名称:user.select(‘div.avatar > a’)[0][‘title’].strip()
- 短评时间:user.select(‘div.comment > h3 > span.comment-info > span.comment-time’)[0].string.strip()
- 短评内容:user.select(‘div.comment > p > span.short’)[0].string.strip()
- 短评票数:user.select(‘div.comment > h3 > span.comment-vote > span’)[0].string.strip()
所以我们初始的spider如下movie_comment.py
import scrapy
from bs4 import BeautifulSoup
class MovieCommentSpider(scrapy.Spider):
name = 'movie_comment'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.xxxx.com/subject/35675082/comments?limit=20&status=P&sort=new_score']
def parse(self, response):
item = {}
r = response.text
# print(r)
soup = BeautifulSoup(r,'lxml')
comment_set = soup.select('.comment-item')
# print(type(comment_set))
for user in comment_set:
item['comment_date'] = user.select('div.comment > h3 > span.comment-info > span.comment-time')[0].string.strip()
item['comment_user'] = user.select('div.avatar > a')[0]['title'].strip()
item['comment_vote'] = user.select('div.comment > h3 > span.comment-vote > span')[0].string.strip()
item['comment_content'] = user.select('div.comment > p > span.short')[0].string.strip()
# print(comment_date,comment_user,comment_vote,comment_content)
print(item,'\n')
运行spider开始采集
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ scrapy crawl movie_comment
2022-12-14 21:43:08 [scrapy.utils.log] INFO: Scrapy 2.7.1 started (bot: douban)
2022-12-14 21:43:08 [scrapy.utils.log] INFO: Versions: lxml 4.9.2.0, libxml2 2.9.14, cssselect 1.2.0, parsel 1.7.0, w3lib 2.1.1, Twisted 22.10.0, Python 3.8.0 (default, Dec 9 2021, 17:53:27) - [GCC 8.4.0], pyOpenSSL 22.1.0 (OpenSSL 3.0.7 1 Nov 2022), cryptography 38.0.4, Platform Linux-5.4.0-132-generic-x86_64-with-glibc2.27
2022-12-14 21:43:08 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'douban',
'NEWSPIDER_MODULE': 'douban.spiders',
'REQUEST_FINGERPRINTER_IMPLEMENTATION': '2.7',
'SPIDER_MODULES': ['douban.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioSelectorReactor',
'USER_AGENT': 'User-Agent=Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; '
'rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0'}
2022-12-14 21:43:08 [asyncio] DEBUG: Using selector: EpollSelector
2022-12-14 21:43:08 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2022-12-14 21:43:08 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.unix_events._UnixSelectorEventLoop
2022-12-14 21:43:08 [scrapy.extensions.telnet] INFO: Telnet Password: 1d1e99a9f0b3f857
2022-12-14 21:43:08 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2022-12-14 21:43:08 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2022-12-14 21:43:08 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2022-12-14 21:43:08 [scrapy.middleware] INFO: Enabled item pipelines:
['douban.pipelines.DoubanPipeline']
2022-12-14 21:43:08 [scrapy.core.engine] INFO: Spider opened
2022-12-14 21:43:08 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2022-12-14 21:43:08 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2022-12-14 21:43:09 [filelock] DEBUG: Attempting to acquire lock 140420844892016 on /home/xadocker/.cache/python-tldextract/3.8.0.final__venv__0354b0__tldextract-3.4.0/publicsuffix.org-tlds/de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-12-14 21:43:09 [filelock] DEBUG: Lock 140420844892016 acquired on /home/xadocker/.cache/python-tldextract/3.8.0.final__venv__0354b0__tldextract-3.4.0/publicsuffix.org-tlds/de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-12-14 21:43:09 [filelock] DEBUG: Attempting to release lock 140420844892016 on /home/xadocker/.cache/python-tldextract/3.8.0.final__venv__0354b0__tldextract-3.4.0/publicsuffix.org-tlds/de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-12-14 21:43:09 [filelock] DEBUG: Lock 140420844892016 released on /home/xadocker/.cache/python-tldextract/3.8.0.final__venv__0354b0__tldextract-3.4.0/publicsuffix.org-tlds/de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-12-14 21:43:09 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.xxx.com/subject/35675082/comments?limit=20&status=P&sort=new_score> (referer: None)
{'comment_date': '2022-08-08 23:11:30', 'comment_user': '陈', 'comment_vote': '775', 'comment_content': '尬住了,敷衍的打斗和过度的特效溢出屏幕的光污染。'}
{'comment_date': '2022-08-08 19:04:10', 'comment_user': 'Tei', 'comment_vote': '506', 'comment_content': 'ado个人演唱会'}
{'comment_date': '2022-09-25 19:19:57', 'comment_user': '次等水货', 'comment_vote': '272', 'comment_content': '作为民工漫里最长寿的一部是有道理的,对粉丝来说这是一场蓄谋已久的狂欢,红发动容,热血和激情澎湃,贝波打call真的可爱极了。对非粉来说也没有观看难度,剧情对每一个出场的角色都有照顾,乌塔是香克斯的女儿自始至终都不会变,这是一次温柔的家庭和解,也是对银幕内外泛滥的负面情绪的一场救赎,乌塔想要创造一个没有苦难的世界,毫不意外最终是梦境一场,但一次完整的、有起有兴的ADO演唱会也能让人心头一软。'}
{'comment_date': '2022-08-08 16:20:33', 'comment_user': '辣手修猫', 'comment_vote': '306', 'comment_content': '这是开了一场个人演唱会啊,我觉得这个很适合小朋友看,大人的话闭上眼睛听听音乐还是可以的,剧情几乎是为零。'}
{'comment_date': '2022-09-29 11:58:38', 'comment_user': '林微云', 'comment_vote': '233', 'comment_content': '缤纷的色彩,华丽的音符,仿佛在电影院听了一场Live演唱会,让人梦回大和歌姬时代过是阴谋的一体两面。你是愿意沉迷在甜美的歌声中死去,还是宁愿辛苦努力踏实过每一天?魔法音乐的这个哲思,要怎么回答才能安全地活下去'}
{'comment_date': '2022-09-21 23:46:44', 'comment_user': '犯罪嫌疑人', 'comment_vote': '463', 'comment_content': '这就是歌姬吧?'}
{'comment_date': '2022-09-22 20:32:11', 'comment_user': '桃桃林林', 'comment_vote': '169', 'comment_content': '等于看了一场演唱会,ADO的歌还是不错的。'}
{'comment_date': '2022-08-08 13:31:24', 'comment_user': '动物世界', 'comment_vote': '417', 'comment_content': '这也太粉丝向幼龄化了,海贼现在就疯狂过滤收集高浓缩粉丝吗?'}
{'comment_date': '2022-12-01 23:06:37', 'comment_user': 'Rocktemple', 'comment_vote': '116', 'comment_content': '又是被自我感动的东亚爹气死的一天'}
{'comment_date': '2022-12-02 21:27:24', 'comment_user': '问宝侠', 'comment_vote': '37', 'comment_content': '好漫长又随意的一部剧场版,槽点真的有比隔壁柯南少吗……加各种强行的设定也一定要促个三星吧。\n\n对池田秀一的声音都要有阴影了,又是这种被过度神话的装逼人物。另外,中文字幕强行翻译成航海王就很真的很能让人意识到,到底为什么这些不偷不杀不作恶的人要自称“海贼”。每次看乌塔和路飞就“为什么要当海贼”鸡同鸭讲地吵起来时,都很想打断他们,“其实他只是想当巡游世界的夺宝奇兵啦”。'}
{'comment_date': '2022-08-06 23:02:52', 'comment_user': '盛夏朝颜', 'comment_vote': '997', 'comment_content': '尾田这两年没少看女团吧'}
{'comment_date': '2022-08-09 16:47:33', 'comment_user': '血浆爱好者', 'comment_vote': '209', 'comment_content': '好烂的歌舞片。'}
{'comment_date': '2022-12-02 11:47:08', 'comment_user': 'dddd', 'comment_vote': '151', 'comment_content': '买red电影票送uta演唱会门票'}
{'comment_date': '2022-12-01 21:04:48', 'comment_user': 'Anything Goes!', 'comment_vote': '145', 'comment_content': '久违的在影院看电影,感谢海贼让我渡过近期最有意义的两个小时!\n乌塔那么出色,难怪路飞刚出海的时候,就嚷嚷着要找音乐家当伙伴😊'}
{'comment_date': '2022-08-06 10:45:48', 'comment_user': '几米米', 'comment_vote': '584', 'comment_content': '给香克斯个面子,第一次演电影啊!'}
{'comment_date': '2022-08-07 14:43:29', 'comment_user': '柠檬茶', 'comment_vote': '120', 'comment_content': '打斗还可以,剧情也就那么回事。'}
{'comment_date': '2022-12-01 23:01:10', 'comment_user': '星空', 'comment_vote': '39', 'comment_content': '还可以打磨的更好看,乌塔前面不用知道真相,后面知道想改变却被魔王吞噬,改成这样好能基本回归正常生活。'}
{'comment_date': '2022-12-01 21:30:02', 'comment_user': '一條魚佔滿了河', 'comment_vote': '33', 'comment_content': '★★☆ 一切自作主張的為你好,都是幼稚與傲慢的表現,以自由之名剝奪自由,不到記不得了,《海賊王:紅髮歌姬》的作畫算是最讓我驚艷的部分,但是在劇情上則太多意料之中,對於歌舞場面,在受到過《犬王》的全面震撼之後,就顯得平平無奇許多,對於熱血場面,劇情一直在用力頂,卻始終沒能讓我有熱血沸騰感,直到路飛和香克斯跨時空合力才算戳到了一下,遠沒有上一部劇場版後半段全程熱血衝腦的爽感。'}
{'comment_date': '2022-11-28 16:38:37', 'comment_user': '鬼腳七', 'comment_vote': '42', 'comment_content': '要不是最后想起来还要拍点战斗段落,我差点以为我又看了一遍龙与雀斑公主'}
{'comment_date': '2022-08-06 11:46:41', 'comment_user': '麻圆姬', 'comment_vote': '298', 'comment_content': '香克斯的面子必须要给'}
2022-12-14 21:43:09 [scrapy.core.engine] INFO: Closing spider (finished)
2022-12-14 21:43:09 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 344,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 13538,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 0.802649,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2022, 12, 14, 13, 43, 9, 384361),
'httpcompression/response_bytes': 68737,
'httpcompression/response_count': 1,
'log_count/DEBUG': 8,
'log_count/INFO': 10,
'memusage/max': 67321856,
'memusage/startup': 67321856,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2022, 12, 14, 13, 43, 8, 581712)}
2022-12-14 21:43:09 [scrapy.core.engine] INFO: Spider closed (finished)
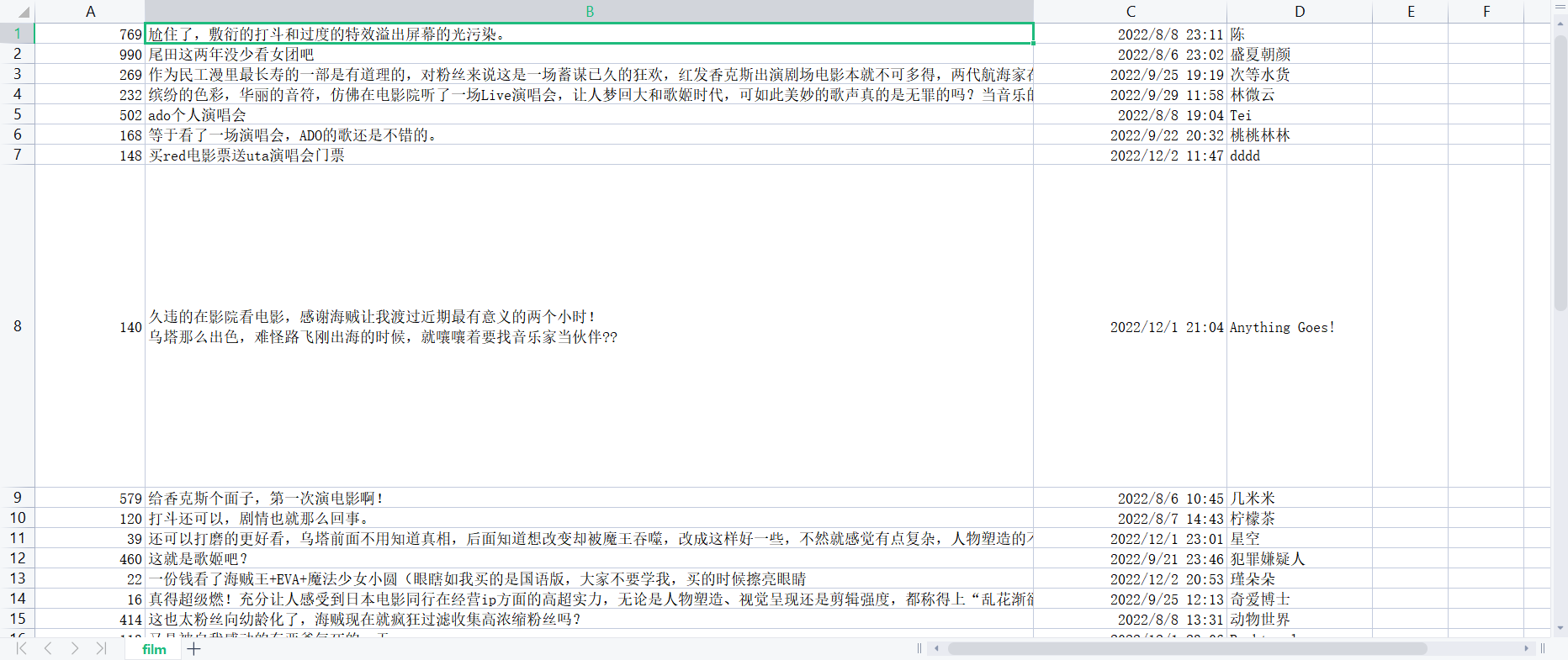
试试使用pipeline将数据保存到csv中
此时我们需要建立我们的item数据模型,编写items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
comment_date = scrapy.Field()
comment_user = scrapy.Field()
comment_vote = scrapy.Field()
comment_content = scrapy.Field()
调整我们之前的spider.py:
- 引入上面定义的item
- parse方法中返回解析后的item
import scrapy
from douban.items import DoubanItem
from bs4 import BeautifulSoup
class MovieCommentSpider(scrapy.Spider):
name = 'movie_comment'
allowed_domains = ['movie.xxx.com']
start_urls = ['https://movie.xxx.com/subject/35675082/comments?limit=20&status=P&sort=new_score']
def parse(self, response):
item = DoubanItem()
# item = {}
r = response.text
soup = BeautifulSoup(r,'lxml')
comment_set = soup.select('.comment-item')
for user in comment_set:
item['comment_date'] = user.select('div.comment > h3 > span.comment-info > span.comment-time')[0].string.strip()
item['comment_user'] = user.select('div.avatar > a')[0]['title'].strip()
item['comment_vote'] = user.select('div.comment > h3 > span.comment-vote > span')[0].string.strip()
item['comment_content'] = user.select('div.comment > p > span.short')[0].string.strip()
print(item,'\n')
yield item
再pipelines.py中接收item,并将item保存到csv中,编写pipelines.py
from itemadapter import ItemAdapter
import csv
class DoubanPipeline:
def process_item(self, item, spider):
data = []
result = []
with open("film.csv", "a", encoding="gb18030", newline="") as csvfile:
writer = csv.writer(csvfile)
for key in item:
data.append(item[key])
result.append(data)
writer.writerows(result)
此时pipelines.py编写完后还需要再settings.py中开启管道,不然不会启用
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 找到以下配置,将其注释取消掉
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
开启后再次运行spider,会再douban项目下生成一个film.csv文件
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ ll
total 60
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 17:43 ./
drwxrwxr-x 5 xadocker xadocker 4096 12月 14 15:44 ../
drwxrwxr-x 5 xadocker xadocker 4096 12月 14 21:59 douban/
-rw-rw-r-- 1 xadocker xadocker 41058 12月 14 17:43 film.csv
-rw-rw-r-- 1 xadocker xadocker 255 12月 14 15:44 scrapy.cfg
为spider提供自动解析下一页内容
上面我们只是简单的演示了下解析一页的短评,此处我们看下页面中css,查看下一页的特征,从页面可以看到它会存在一个class=’next’,所以我们的下一页可以用该class获取
next_page = soup.select('#paginator > a.next')[0]['href'].strip()
调整我们的spider movie_comment.py,由于未登录情况下只允许获取前10页,后面的请求都会403,所以我们需要设置页数限制
import scrapy
import time
from douban.items import DoubanItem
from bs4 import BeautifulSoup
class MovieCommentSpider(scrapy.Spider):
name = 'movie_comment'
allowed_domains = ['movie.xxx.com']
base_url = 'https://movie.xxx.com/subject/35675082/comments'
count = 0
start_urls = ['https://movie.xxx.com/subject/35675082/comments?limit=20&status=P&sort=new_score']
def parse(self, response):
self.count += 1
item = DoubanItem()
r = response.text
soup = BeautifulSoup(r,'lxml')
comment_set = soup.select('.comment-item')
for user in comment_set:
item['comment_date'] = user.select('div.comment > h3 > span.comment-info > span.comment-time')[0].string.strip()
item['comment_user'] = user.select('div.avatar > a')[0]['title'].strip()
item['comment_vote'] = user.select('div.comment > h3 > span.comment-vote > span')[0].string.strip()
item['comment_content'] = user.select('div.comment > p > span.short')[0].string.strip()
print(item,'\n')
yield item
# 解析下一页地址并拼接完整地址
next_page = soup.select('#paginator > a.next')[0]['href'].strip()
next_url = self.base_url + next_page
print(next_url)
# 加个延时,避免请求过快
time.sleep(1)
# 设置页数限制,未登录情况下只允许获取前10页,后面的请求都会403
if self.count<10:
yield scrapy.Request(url=next_url,callback=self.parse)
将数据采集到elasticsearch中
上面我们是将数据保存到csv中,此处则是将数据保存到elasticsearch中,同时对短评进行分词
安装elasticsearch-dsl
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ pip3 install elasticsearch-dsl配置 es module
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ mkdir douban/modules
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ touch douban/modules/es_models.py
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ ll douban/
total 36
drwxrwxr-x 5 xadocker xadocker 4096 12月 14 21:59 ./
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 17:43 ../
-rw-rw-r-- 1 xadocker xadocker 0 12月 14 15:43 __init__.py
-rw-rw-r-- 1 xadocker xadocker 392 12月 14 21:59 items.py
-rw-rw-r-- 1 xadocker xadocker 3648 12月 14 15:44 middlewares.py
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 20:48 models/
-rw-rw-r-- 1 xadocker xadocker 1017 12月 14 19:40 pipelines.py
drwxrwxr-x 2 xadocker xadocker 4096 12月 14 19:40 __pycache__/
-rw-rw-r-- 1 xadocker xadocker 3367 12月 14 17:00 settings.py
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 22:11 spiders/
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ ll douban/models/
total 16
drwxrwxr-x 3 xadocker xadocker 4096 12月 14 20:48 ./
drwxrwxr-x 5 xadocker xadocker 4096 12月 14 21:59 ../
-rw-rw-r-- 1 xadocker xadocker 2408 12月 14 20:48 es_models.py
-rw-rw-r-- 1 xadocker xadocker 0 12月 14 18:02 __init__.py
drwxrwxr-x 2 xadocker xadocker 4096 12月 14 20:49 __pycache__/
在models目录中配置es_models.py
from datetime import datetime
from elasticsearch_dsl import Document, Date, Nested, Boolean, InnerDoc, Completion, Keyword, Text, Integer, query
from elasticsearch_dsl import Search
from elasticsearch_dsl.connections import connections
# 设置索引名称
index_name = "scrapy_douban_movie_comments"
# 配置es连接
client = connections.create_connection(hosts=["es-01.xadocker.cn"], http_auth=('elastic','elastic'))
# 创建document search实例
douban_search = Search(using=client, index=index_name)
# 继承了es的Document
class DoubanCommentsType(Document):
# 对comments使用ik分词,采用最多分词模式
comments = Text(analyzer="ik_max_word")
user = Keyword()
vote = Integer()
date = Date()
createtime = Date()
updatetime = Date()
class Index:
name = index_name
settings = {
"number_of_shards": 3,
"number_of_replicas": 2
}
# 判断某个用户user是否存comments,返回True或False
def exist_some_comments(self):
print(f"exist_some_comments: {self.user}")
s = douban_search.query("match", user=self.user)
# 执行count查询,返回数字
count = s.count()
# 三元表达式,大于0返回True
return True if count > 0 else False
# 获取相同用户user的数据
def get_some_comments(self):
s = douban_search.query("match", user=self.user)
# 执行搜索并返回Response包装所有数据的实例
res = s.execute()
total = res.hits.total
print('total hits', total.relation, total.value)
# 这里的hits下的hits是es返回的josn格式。可以在kibana中执行xxxxindex_name/_search命令查看
hits = res.hits.hits
return hits;
# 自定义保存方法
def mysave(self):
if self.exist_some_comments() == True:
print('更新comments,vote会有变化')
hits = self.get_some_comments()
self.meta.id = hits[0]["_id"]
print(hits[0])
self.createtime = hits[0]['_source']['createtime']
self.updatetime = datetime.now()
self.save()
else:
print('新增')
# 如果user未曾提交短评,则创建它,否则将覆盖它。
self.createtime = datetime.now()
self.save();
# 使用init方法创建索引并配置映射
if __name__ == '__main__':
DoubanCommentsType.init()
运行es_models.py来创建索引
# 运行未报错即可
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ python3 es_models.py
调整pipeline管道,将之前item保存到csv的方法改为到es中,pipelines.py内容
from itemadapter import ItemAdapter
# import csv
# 引入自定义的es models
from .models import es_models
class DoubanPipeline:
# def process_item(self, item, spider):
# data = []
# result = []
# with open("film.csv", "a", encoding="gb18030", newline="") as csvfile:
# writer = csv.writer(csvfile)
# for key in item:
# data.append(item[key])
# result.append(data)
# writer.writerows(result)
def process_item(self, item, spider):
comments = es_models.DoubanCommentsType()
comments.user = item['comment_user']
comments.date = item['comment_date']
comments.vote = item['comment_vote']
comments.comments = item['comment_content']
comments.mysave()
return item
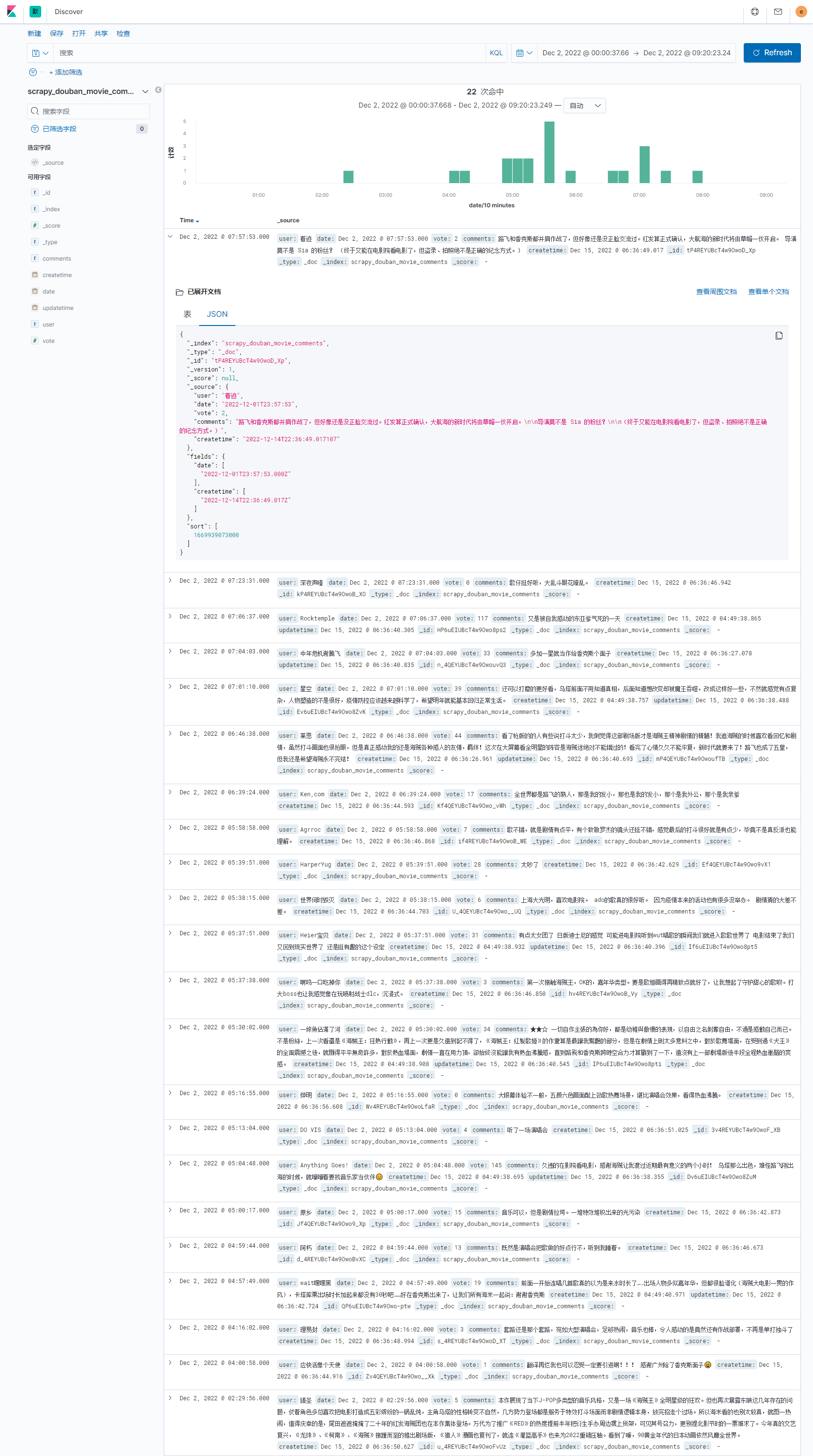
再次运行spider,登录kibana查看数据
(venv) xadocker@xadocker-virtual-machine:~/PycharmProjects/untitled1/douban$ scrapy crawl movie_comment
........
........
2022-12-14 22:36:56 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.xxx.com/subject/35675082/comments?start=180&limit=20&sort=new_score&status=P&percent_type=>
{'comment_content': '一半角色都不认得,但是被感动得一塌糊涂,每首歌都好抓耳,特别黑化时候唱的那些我可太喜欢了!\n'
'名冢佳织的演出没想到这么好,有些时候声线还让我想到林原惠美。',
'comment_date': '2022-12-04 15:40:42',
'comment_user': '龙骨',
'comment_vote': '0'}
{'comment_content': '低配版《盗梦空间》,红发歌姬想要借助美好的虚拟世界带领人们逃避现世的苦厄,可人生还是要像路飞和他们的伙伴一样直面风雨才是正道啊!',
'comment_date': '2022-12-02 14:43:44',
'comment_user': '馥雅',
'comment_vote': '0'}
exist_some_comments: 馥雅
2022-12-14 22:36:56 [urllib3.connectionpool] DEBUG: http://es-01.xadocker.cn:9200 "POST /scrapy_douban_movie_comments/_count HTTP/1.1" 200 71
2022-12-14 22:36:56 [elasticsearch] INFO: POST http://es-01.xadocker.cn:9200/scrapy_douban_movie_comments/_count [status:200 request:0.005s]
2022-12-14 22:36:56 [elasticsearch] DEBUG: > {"query":{"match":{"user":"馥雅"}}}
2022-12-14 22:36:56 [elasticsearch] DEBUG: < {"count":0,"_shards":{"total":3,"successful":3,"skipped":0,"failed":0}}
新增
2022-12-14 22:36:56 [urllib3.connectionpool] DEBUG: http://es-01.xadocker.cn:9200 "POST /scrapy_douban_movie_comments/_doc HTTP/1.1" 201 196
2022-12-14 22:36:56 [elasticsearch] INFO: POST http://es-01.xadocker.cn:9200/scrapy_douban_movie_comments/_doc [status:201 request:0.008s]
2022-12-14 22:36:56 [elasticsearch] DEBUG: > {"user":"馥雅","date":"2022-12-02T14:43:44","vote":0,"comments":"低配版《盗梦空间》,红发歌姬想要借助美好的虚拟世界带领人们逃避现世的苦厄,可":"2022-12-14T22:36:56.835468"}
2022-12-14 22:36:56 [elasticsearch] DEBUG: < {"_index":"scrapy_douban_movie_comments","_type":"_doc","_id":"bP4REYUBcT4w9OwoLvZz","_version":1,"result":"created","_shards":{"total":3,"successful":3,"failed":0},"_seq_no":83,"_primary_term":1}
2022-12-14 22:36:56 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.xxx.com/subject/35675082/comments?start=180&limit=20&sort=new_score&status=P&percent_type=>
{'comment_content': '低配版《盗梦空间》,红发歌姬想要借助美好的虚拟世界带领人们逃避现世的苦厄,可人生还是要像路飞和他们的伙伴一样直面风雨才是正道啊!',
'comment_date': '2022-12-02 14:43:44',
'comment_user': '馥雅',
'comment_vote': '0'}
https://movie.douban.com/subject/35675082/comments?start=200&limit=20&sort=new_score&status=P&percent_type=
2022-12-14 22:36:57 [scrapy.core.engine] INFO: Closing spider (finished)
2022-12-14 22:36:57 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 4911,
'downloader/request_count': 10,
'downloader/request_method_count/GET': 10,
'downloader/response_bytes': 143741,
'downloader/response_count': 10,
'downloader/response_status_count/200': 10,
'elapsed_time_seconds': 20.47767,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2022, 12, 14, 14, 36, 57, 857134),
'httpcompression/response_bytes': 701332,
'httpcompression/response_count': 10,
'item_scraped_count': 200,
'log_count/DEBUG': 1571,
'log_count/INFO': 461,
'memusage/max': 67399680,
'memusage/startup': 67399680,
'request_depth_max': 9,
'response_received_count': 10,
'scheduler/dequeued': 10,
'scheduler/dequeued/memory': 10,
'scheduler/enqueued': 10,
'scheduler/enqueued/memory': 10,
'start_time': datetime.datetime(2022, 12, 14, 14, 36, 37, 379464)}
2022-12-14 22:36:57 [scrapy.core.engine] INFO: Spider closed (finished)















 3735
3735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









