











目录
一、总体框架:SPD(Spot-the-Difference)
1. SmoothBlend缺陷生成算法:一种更自然的伪缺陷合成方法
论文标题
SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation
核心问题
本论文聚焦于工业质检场景中的视觉异常检测与分割任务,试图解决当前方法中,异常样本稀缺、自监督预训练方法【1】泛化能力【2】不足、以及对缺陷区域关注不集中的问题。现有方法往往依赖于监督式的ImageNet预训练模型【3】,难以适应工业中多对象、小缺陷、低样本等实际条件,限制了模型的迁移能力和检测精度。
创新方法
论文提出了一种自监督学习框架——SPot-the-Difference(SPD),该方法通过在对比学习基础上引入“找不同”任务,引导模型聚焦于图像中的局部差异区域,从而提升缺陷检测与分割的敏感性。
关键技术点如下:
-
SmoothBlend数据增强:合成局部缺陷图像,引导模型识别局部微小变化。
-
预训练正则化机制:SPD可用于增强主流自监督方法(如SimSiam、MoCo、SimCLR)的表示能力。
-
通用性与兼容性:SPD可以与任何对比式自监督方法结合,不依赖预训练分类标签,不依赖预训练模型。
-
VisA数据集:构建了目前较大的工业缺陷数据集,包含12类物体的10821张图像,提供像素级与图像级标签,便于评估检测与分割性能。
论文讲解
论文分为以下几个主要部分:
-
引言:指出工业异常检测的四大挑战(样本稀缺、缺陷微小、精度敏感、跨域适配)并引出自监督学习的潜力与局限。
-
相关工作:回顾自监督学习、工业缺陷检测方法的发展,指出现有方法如CutPaste【4】无法泛化至跨对象的实际场景。
-
方法:
-
提出SPD框架,通过“找不同”任务训练模型识别局部差异;
-
设计SmoothBlend算法以合成微小局部缺陷;
-
利用与现有对比学习结构兼容的正则化目标引导模型学习更具判别性的表示。
-
-
数据集与实验:
-
发布VisA数据集,并与MVTec-AD等主流数据集对比;
-
实验中验证SPD可在1-class、2-class、low/high-shot条件下均显著优于基线,特别是在AU-PR指标上超过SimSiam约6%。
-
-
可视化与分析:采用GradCAM进行注意力热图可视化,验证SPD确实引导模型关注局部异常区域。
局限分析
从多个维度对方法进行批判性分析如下:
-
计算成本:虽然SPD引入额外的“找不同”合成过程与正则化目标,但并未显著增加训练时长;然而,训练初期可能需要调优以适配目标任务。
-
泛化能力:SPD在VisA和MVTec-AD均表现良好,但仍依赖于缺陷的“局部可视差异”假设,对某些复杂的高层语义异常(如伪装、遮挡)可能不够敏感。
-
数据需求:虽然SPD适用于low-shot场景,但在极低样本(如仅1张)下仍可能受限,且合成缺陷的质量对最终性能有显著影响。
最后提出两个问题
• Why型:
为什么SPD比传统的对比学习(如SimCLR)更适合工业异常检测?
→ 因为SPD通过模拟真实缺陷图像中的“局部差异”,引导模型聚焦于细粒度区域,提高了对微小缺陷的敏感性,符合工业检测的实际需求,而传统对比学习多注重整体结构或语义差异,易忽略局部缺陷。
• How型:
如何将SPD方法扩展到其他领域,如医学影像中的异常识别?
→ 可以通过设计医学场景下的“局部变化”合成方式(如伪造肿瘤、纹理错位等),将SPD理念迁移到MRI或CT图像中,训练模型识别微小病变区域,从而提升医疗图像中的异常检测能力。
SPD(Spot-the-Difference)框架详解
一、总体框架:SPD(Spot-the-Difference)
▶ 目标:
构建一个自监督预训练机制,使模型能够从大量无缺陷图像中学习到对局部异常的敏感性,从而提升在工业缺陷检测任务中的表现。
SPD 的核心灵感来自人类的“找不同”任务:对比两张图,找到微小的差异。
二、核心组成模块
1. SmoothBlend缺陷生成算法:一种更自然的伪缺陷合成方法
核心目标:
模拟微小、局部、自然过渡的缺陷,从而提升自监督预训练中伪缺陷的真实性和多样性,解决 CutPaste 方法中伪缺陷过于“粗糙、不真实”的问题。
1️⃣ SmoothBlend 的设计思想
传统的 CutPaste 方法直接剪切图像块并粘贴到图中其他位置,虽然制造了“结构不一致”,但粘贴区域与周围区域之间存在明显的边界,过于突兀,不符合工业中真实缺陷的特征。
🔍 SmoothBlend 设计重点:
-
模拟真实缺陷中的细微结构破坏或材质扰动;
-
平滑过渡缺陷区域与背景之间的边缘;
-
引入不确定性(位置、形状、边缘模糊程度),提升数据多样性。
2️⃣ 算法流程解析(类伪代码讲解)
以下为 SmoothBlend 缺陷生成的主要流程:
def smooth_blend(image):
# Step 1: 选择原图中的一块随机小区域(源 patch)
patch = random_crop(image, size=(w, h)) # 通常较小,比如 32x32
# Step 2: 随机选择一个目标位置用于粘贴(目标区域)
x_offset, y_offset = random_position(image, patch_size=(w, h))
# Step 3: 生成一个平滑混合掩码 mask(通常是高斯核)
mask = generate_gaussian_mask(w, h)
# Step 4: 融合 patch 到原图上,使用 alpha-blend 公式
for i in range(h):
for j in range(w):
alpha = mask[i, j] # 从中心向外逐渐减少
image[y_offset+i, x_offset+j] = (
alpha * patch[i, j] + (1 - alpha) * image[y_offset+i, x_offset+j]
)
return image # 得到带有微小扰动的图像
3️⃣ 高斯掩码(Gaussian Mask)详解
用于实现“边缘平滑”效果,其特点是:
-
中心值接近 1(保留 patch 内容);
-
边缘值接近 0(保留原图内容);
-
从中心向边缘渐变过渡,实现“混合”。
生成方式:
def generate_gaussian_mask(w, h):
x = np.linspace(-1, 1, w)
y = np.linspace(-1, 1, h)
xv, yv = np.meshgrid(x, y)
sigma = 0.5 # 控制模糊程度
mask = np.exp(-(xv**2 + yv**2) / (2 * sigma**2))
return mask
可视上看,融合区域中心清晰,边缘渐变模糊,提升伪缺陷的“自然感”。
4️⃣ 整体效果分析
| 特征 | SmoothBlend | CutPaste(对比) |
|---|---|---|
| 缺陷边缘 | 平滑、模糊过渡 | 锯齿、突兀 |
| 缺陷形态 | 可控、类真实 | 结构化强、人为感强 |
| 多样性 | 高(位置、边缘、形状) | 低(固定粘贴) |
| 生成质量 | 更接近真实缺陷 | 偏人工合成感 |
5️⃣ 应用意义与创新性
-
SmoothBlend 使自监督伪缺陷更加语义逼真;
-
提高模型对细粒度局部扰动的感知能力;
-
避免模型因训练数据“太假”而过拟合非真实缺陷特征;
-
是 SPD 成功迁移到复杂工业检测任务的关键技术支撑。
📘 小结
SmoothBlend 本质上是一个 “高斯融合 + 区域扰动 + 自监督生成” 的模块,完美兼顾了:
-
无需人工标注;
-
多样性高;
-
缺陷真实感强;
-
可嵌入现有对比学习框架中。
2. 图像对构建(Difference Pair)
构造方式:
-
原图 x 和其 SmoothBlend 改造图
构成一个图像对;
-
图像对中的两幅图输入同一个编码器
;
-
学习它们之间的局部差异。
这构成“找不同”的基础任务,让网络专注于“局部不同”。
3. 自监督对比学习目标
论文设计了一个与主流对比学习(如SimCLR, MoCo)兼容的损失函数,但区别在于:
普通对比学习:
-
同一个图像的不同增强版本作为正样本对;
-
不同图像为负样本对;
-
学习全局语义表示。
SPD自监督目标:
-
正样本对:原图和缺陷图之间的编码差异(同一对象不同局部);
-
负样本对:不同图像对之间的差异;
-
学习“判别性地编码图像的微小局部变化”。
引入正则项来约束特征空间中图像对之间的距离(利用对比损失 + 正则化),鼓励网络更关注微差异。
三、在实际任务中的应用
SPD 预训练后的模型被迁移到下游任务:
-
异常检测(使用One-Class分类器或重建误差);
-
像素级分割(使用编码器特征图与异常图比对);
通过实验表明,在多个工业数据集(如 MVTec AD)上,SPD在不使用缺陷样本的前提下达到了或超过了有监督方法的表现。
小结:创新点归纳
| 创新模块 | 描述 | 是否依赖预训练模型 |
|---|---|---|
| SmoothBlend | 更自然的伪缺陷合成方法,模拟微小局部异常 | ❌ 不依赖外部预训练 |
| Spot-the-Difference任务 | 构建原图与缺陷图对,训练网络关注局部差异 | ❌ |
| 对比学习正则目标 | 结合 contrastive learning 引导模型学习判别性特征 | ✅ 可与SimCLR等结构兼容 |
代码复现
我们根据文中的内容,来实现一个复现代码。
代码
# 导入必要的库
import cv2 # OpenCV库,用于图像处理
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库,用于显示图像
def generate_gaussian_mask(w, h, sigma=0.5):
"""
生成二维高斯掩码,用于图像融合时的平滑过渡
:param w: 掩码的宽度(对应目标区域的宽度)
:param h: 掩码的高度(对应目标区域的高度)
:param sigma: 高斯分布的标准差,控制衰减速度,默认0.5
:return: 高斯掩码矩阵,形状为(h, w, 1),方便与RGB图像相乘
"""
# 生成从-1到1的均匀分布坐标点(归一化坐标,便于计算高斯分布)
x = np.linspace(-1, 1, w) # 宽度方向生成w个点
y = np.linspace(-1, 1, h) # 高度方向生成h个点
xv, yv = np.meshgrid(x, y) # 生成网格坐标矩阵
# 计算高斯分布:exp(-(x² + y²)/(2σ²)),值域在0到1之间
mask = np.exp(-(xv ** 2 + yv ** 2) / (2 * sigma ** 2))
# 增加一个维度,使掩码形状变为(h, w, 1),便于与RGB图像进行广播相乘
return mask[..., np.newaxis]
def smooth_blend(image, patch_size=(32, 32)):
"""
对输入图像进行随机裁剪和平滑融合操作
:param image: 输入图像,形状为(h, w, 3)的RGB图像
:param patch_size: 裁剪和融合的补丁大小,格式为(高度, 宽度)
:return: 融合后的图像,并标记融合位置的矩形框
"""
h, w, _ = image.shape # 获取图像的高度、宽度和通道数
ph, pw = patch_size # 获取补丁的高度和宽度
# Step 1: 随机裁剪一个补丁
# 生成随机起始坐标,确保补丁在图像范围内
x1 = np.random.randint(0, w - pw) # 宽度方向随机起始x坐标
y1 = np.random.randint(0, h - ph) # 高度方向随机起始y坐标
patch = image[y1:y1 + ph, x1:x1 + pw].copy() # 拷贝补丁区域,避免修改原图
# Step 2: 随机选择目标融合位置
x2 = np.random.randint(0, w - pw) # 目标区域的x起始坐标
y2 = np.random.randint(0, h - ph) # 目标区域的y起始坐标
# Step 3: 生成高斯掩码
mask = generate_gaussian_mask(pw, ph, sigma=0.5) # 生成与补丁尺寸相同的掩码
# Step 4: 平滑融合
blended = image.copy() # 拷贝原图,避免直接修改
roi = blended[y2:y2 + ph, x2:x2 + pw] # 提取目标区域的ROI(Region of Interest)
# 使用高斯掩码进行加权融合:mask * patch + (1 - mask) * roi
# 将计算结果转换为uint8类型(OpenCV图像要求)
blended[y2:y2 + ph, x2:x2 + pw] = (mask * patch + (1 - mask) * roi).astype(np.uint8)
# 在融合位置绘制蓝色矩形框标记(RGB颜色(255,0,0)为红色,但原图已转为RGB格式)
# 注意:由于测试代码中将图像转换为RGB,此处用红色显示。若原图为BGR需调整颜色顺序
cv2.rectangle(blended, (x2, y2), (x2 + pw, y2 + ph), (255, 0, 0), 2)
return blended
# 测试代码
if __name__ == "__main__":
# 读取测试图像,使用OpenCV读取的默认格式为BGR
image = cv2.imread("test.jpg")
# 将图像转换为RGB格式,便于matplotlib正确显示颜色
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 执行平滑融合操作
blended_image = smooth_blend(image)
# 使用matplotlib并排显示原图与融合结果
plt.figure(figsize=(10, 5)) # 设置画布大小
# 显示原图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")
plt.axis("off") # 关闭坐标轴
# 显示融合结果
plt.subplot(1, 2, 2)
plt.imshow(blended_image)
plt.title("SmoothBlend Result with Rectangle Marker")
plt.axis("off")
plt.show() # 显示图像原图
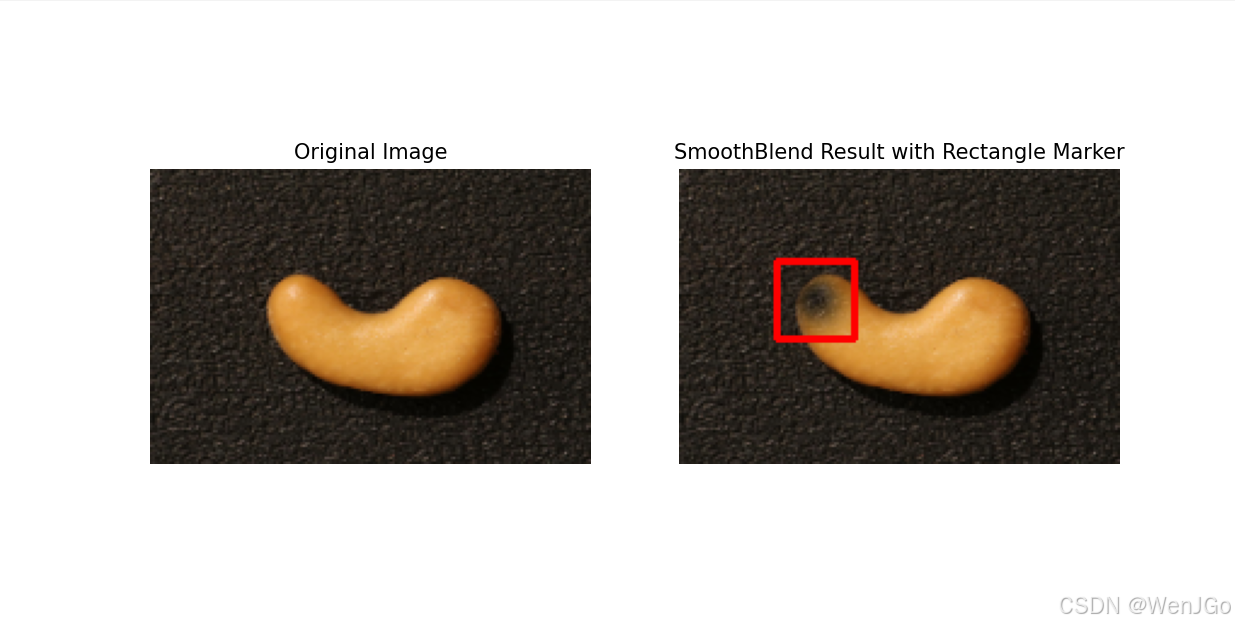
效果
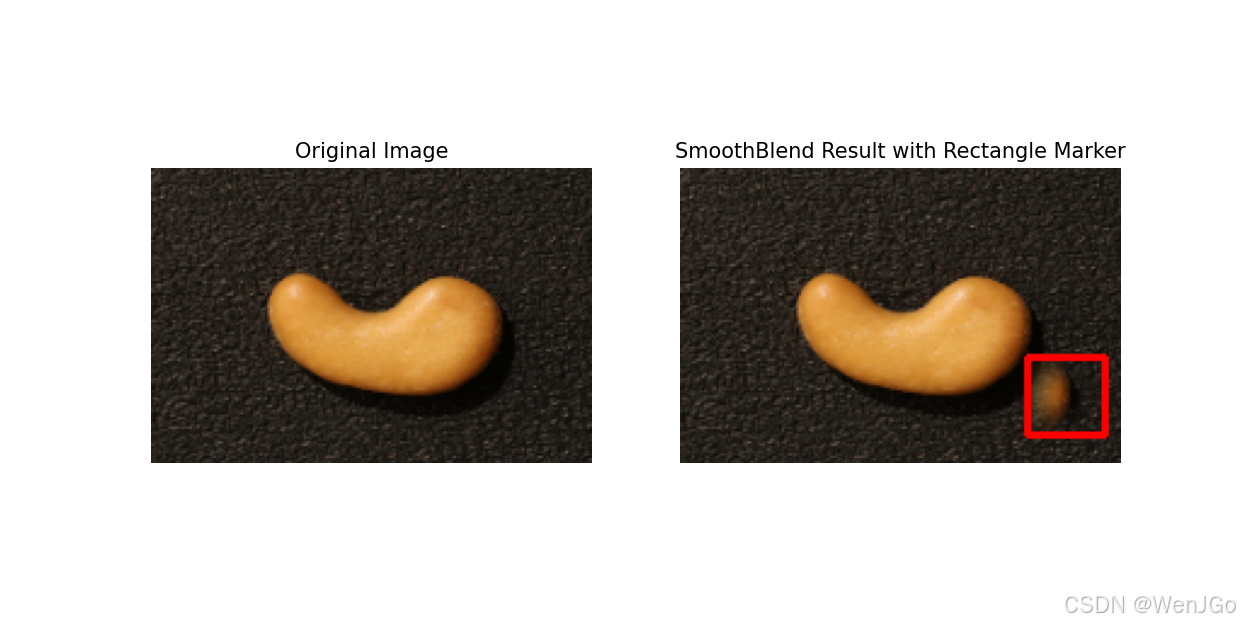
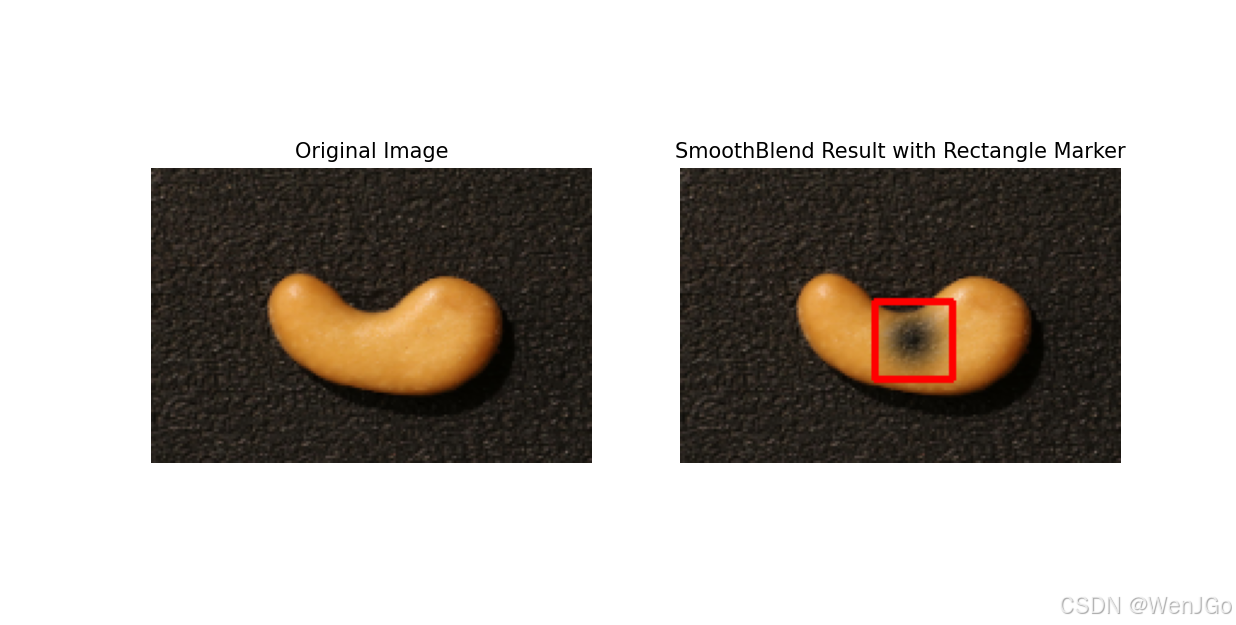 也有达不到预期效果的。
也有达不到预期效果的。
名词解释
【1】什么是自监督预训练方法?
自监督预训练方法是一种机器学习技术,主要用于提高模型在处理特定任务时的性能。这种方法的核心思想是利用大量未标注的数据进行预训练,通过设计一些所谓的“ pretext task ”(预文本任务)来让模型学习到数据中的一些内在结构或特征表示。这些预文本任务不需要人工标注,因为它们通常基于输入数据本身就能定义出一个目标,比如预测图像中被遮挡的部分、旋转图像的角度、或者是句子中词的顺序等。
在自监督学习中,模型通过解决这些 pretext task 来学习一种通用的特征表示。之后,这种学到的特征表示可以被用于各种下游任务(如分类、检测等),并通过少量标注数据进行微调来适应具体的应用场景。这样做的好处是可以减少对大规模标注数据的依赖,同时还能提升模型的表现。
自监督学习在自然语言处理领域取得了显著的成功,例如BERT、RoBERTa等模型就是采用了自监督预训练加有监督微调的方式。近年来,这一思路也被广泛应用于计算机视觉等领域,并取得了一系列进展。随着研究的深入,自监督学习被视为推动人工智能进一步发展的重要方向之一。
【2】模型的泛化能力是什么意思
模型的泛化能力指的是机器学习模型在处理未见过的数据(即训练过程中没有用到的数据)时,能够准确地进行预测或分类的能力。换句话说,它是衡量一个模型在面对新数据时表现如何的关键指标。良好的泛化能力意味着模型不仅能够在训练数据上表现良好,而且还能对未知数据做出准确的预测。
如果一个模型只是记住了训练数据中的特定模式和答案(这种情况称为过拟合),而不能很好地应用这些知识去处理新的数据,那么它的泛化能力就是比较差的。相反,一个好的模型应该能够从训练数据中学习到一般的规律,并将这种理解应用于更广泛的情况,从而在新数据上也表现出色。
为了提高模型的泛化能力,常用的方法包括但不限于:
- 使用更多的训练数据,以帮助模型学习更加普遍的规律。
- 应用正则化技术,如L1/L2正则化、Dropout等,以防止模型过度拟合训练数据。
- 采用交叉验证的方法评估模型性能,确保模型在不同的数据子集上都能有稳定的表现。
- 在模型训练过程中使用早停法(early stopping),当验证集上的性能不再提升时提前结束训练,以避免过拟合。
它跟鲁棒性的区别
-
泛化能力:如前所述,指的是模型在面对未见过的数据时准确预测的能力。一个具有良好泛化能力的模型能够在训练数据之外的数据集上保持较高的性能,即它能够从训练样本中学到一般性的规律,并将这些规律成功应用到新的、未知的数据中。泛化能力主要是关于模型能否有效地处理与训练数据分布相似的新数据。
-
鲁棒性:则更多地涉及到模型对于输入数据中的扰动或变化的敏感程度。具体来说,鲁棒性衡量的是当输入数据包含噪声、丢失信息或遭受对抗攻击等情况下,模型能否维持稳定且可靠的性能。一个具有高鲁棒性的模型能够在面对数据的小幅度变化或不完全精确的情况下,依然给出正确的预测结果。鲁棒性强调的是模型对异常值和干扰因素的抵抗能力。
也就是说,泛化能力关注的是模型在不同但相关的数据上的表现,而鲁棒性更注重模型在面对数据扰动或不完美情况下的稳定性。
【3】ImageNet预训练模型 是什么
ImageNet预训练模型是指在大型图像数据集 ImageNet 上预先训练好的神经网络模型,常用于图像分类、目标检测、图像分割等视觉任务的基础模型。
ImageNet 是一个大规模的图像数据集,包含了 2万多个类别,约1400万张标注图像。其中,每个图像都带有人工标注的类别标签,覆盖从“猫”、“狗”到“飞机”、“键盘”等丰富的物体类型。
什么是预训练模型?
在深度学习中,训练一个神经网络从头开始(即从随机参数初始化)往往需要大量的数据和计算资源。为了节省时间和提升模型效果,研究者通常先在大数据集(如ImageNet)上训练出一个通用的模型,这就是预训练模型。
什么是 ImageNet 预训练模型?
ImageNet 预训练模型即是在 ImageNet 数据集上训练好的网络(如 ResNet、VGG、EfficientNet、ViT 等)。这些模型在 ImageNet 上学习到了丰富的图像表示能力,比如边缘、纹理、物体形状等。
然后,这些预训练的参数可以作为“通用视觉知识”迁移到其他任务中。例如:
-
在工业缺陷检测中,可以使用 ImageNet 预训练模型作为编码器,再微调(fine-tune)以适应特定缺陷检测任务;
-
在医学图像分析中,也可以迁移使用这些模型进行CT/MRI分析;
-
在目标检测中,像YOLO和Faster R-CNN等模型的骨干网络常用ImageNet预训练参数初始化。
优点
-
降低训练成本(避免从零开始训练);
-
加快收敛速度;
-
在数据量小的任务中能有效提升精度(通过迁移学习)。
局限性
-
领域不一致:ImageNet上的自然图像与工业、医学等领域的图像差异较大,迁移效果有限;
-
关注宏观语义:预训练模型更擅长整体分类,不擅长关注局部细微异常;
-
对异常检测任务不敏感:因为ImageNet中的图像大多是“正常物体”,缺乏缺陷或异常的表达。
【4】CutPaste方法
CutPaste 是一种用于工业缺陷检测的 自监督学习方法,最早由Li et al. 在2021年提出,旨在解决工业场景中缺陷样本极少的问题。它通过合成图像中的“伪缺陷”来训练模型,进而在测试阶段检测真实缺陷。
核心思想
CutPaste 的核心思路是利用无缺陷图像,通过“剪切(Cut)一块区域再粘贴(Paste)到原图其他位置”来制造一个人工的伪缺陷图像,训练模型学习“正常”和“异常”的分布差异。
这是一种 不依赖任何标注数据 的自监督方法。
具体做法
-
输入:原始无缺陷图像。
-
操作:
-
随机从图像中裁剪一块小区域;
-
将该区域粘贴回图像的其他位置;
-
得到一个“异常图像”,因为它包含了一个明显的不自然区域。
-
-
训练目标:
-
使用二分类模型(如ResNet)区分“原图”(正常)与“粘贴图”(异常);
-
训练完成后,在测试阶段识别真实缺陷图像。
-
优点
-
无需标注:完全自监督,只需正常图像;
-
简单有效:适用于图像级或像素级的异常检测;
-
适合工业视觉:在如MVTec AD数据集上表现出色。
局限性
论文中指出 CutPaste 存在以下问题:
-
缺乏语义多样性:合成缺陷种类单一,主要是纹理和边缘变化;
-
对真实缺陷适配差:合成伪缺陷与实际复杂缺陷有差异;
-
泛化能力差:在跨对象检测(如从“电路板”迁移到“瓶子”)时,效果明显下降。
这正是本文提出 SPD 方法的出发点——通过更拟真的缺陷合成策略和关注局部差异的机制,提升泛化与鲁棒性。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











