










本文提出了一个新颖的大型多模态模型系统 Myriad,专为工业异常检测任务设计,通过引入预训练工业异常检测模型生成的异常图(anomaly map)作为视觉专家引导信号,利用视觉提示生成器(VPG)和文本提示生成器(TPG)分别增强视觉编码器和语言模型,从而实现对图像中异常区域的更精准关注与语义理解,有效提升了多模态模型在工业检测中的泛化能力和任务适应性。
目录
1. VE-Guided Visual Feature Extractor(视觉专家引导的视觉特征提取器)
2. Instruction-Based Multimodal Interaction(基于指令的多模态交互)
3. Multimodal Large Language Model(多模态大语言模型)
② VE-Guided Vision Encoder(视觉专家引导的视觉编码器)
③ VPG(Visual Prompt Generator)
④ TPG(Textual Prompt Generator)
论文标题
Myriad:应用视觉专家进行工业异常检测的大型多模态模型
Myriad: A Large Multimodal Model Applying Vision Experts for Industrial Anomaly Detection
核心问题:
传统的工业异常检测(Industrial Anomaly Detection, IAD)方法通常需要为每一个应用场景单独训练模型(嫌麻烦了说是),难以适应现代制造中多样化和快速变化的需求。这种方法的泛化能力弱、可扩展性差,限制了其在工业实际中的部署效率和灵活性。
创新方法:
论文提出了一种名为 Myriad 的大规模多模态模型,通过引入已有的视觉专家(例如AnomalyGPT【1】、 ImageBind【2】、PatchCore【3】、MiniGPT-4)引导大模型关注图像中异常区域,从而实现高效的工业异常检测。该方法包括以下关键技术点:
-
视觉专家引导机制:利用已有 IAD 方法生成的异常图作为提示,辅助多模态模型关注关键区域。
-
VE-guided 视觉特征提取器:结合视觉专家输出与原始图像,通过 adapter 模块调节视觉特征以适应异常检测任务。
-
语言模型驱动的输出生成:将人类指令、图像特征及异常图融合输入语言模型,输出检测结果和描述信息。
该方法依赖预训练大语言模型(LLaMA【4】, Vicuna【5】)和图像模型,并在其基础上构建多模态系统。
论文讲解:
文章从工业异常检测的重要性和现有方法的局限出发,逐步引出LMMs(Large Multimodal Models)在IAD中的潜力。论文整体结构如下:
-
引言部分明确指出传统IAD方法对部署环境的适应性差,而LMMs凭借理解和指令跟随能力,具备良好的泛化前景。
-
核心挑战在于当前LMM虽然具备关于异常检测的文本知识,但难以直接从图像中激活这些知识,即“模态鸿沟【6】”问题。
-
方法部分提出Myriad系统架构。其创新在于引入已有IAD模型作为“视觉专家”,生成异常图用于提示LMM聚焦图像中的异常区域。该过程通过:
-
VE-guided Vision Encoder提取多模态输入;
-
adapter模块调节视觉特征以适配语言模型;
-
多模态融合后由语言模型进行推理和输出。
-
-
实验部分在MVTec-AD、VisA、PCB Bank等数据集上对比SOTA方法,验证其在单类和小样本设定下的优越性能。
-
灵活性讨论强调该框架无需结构改动即可适应zero-shot、few-shot等多种训练/推理模式,表现出较强的通用性和扩展性。
局限分析:
-
计算成本:由于依赖大规模语言模型与视觉编码器,同时还需引入视觉专家,整体模型计算和推理成本较高,不适合对实时性要求极高的工业场景。
-
数据依赖性:虽然支持few-shot甚至zero-shot场景,但预训练模型本身仍需要大量训练数据支撑,且对视觉专家性能有所依赖。
-
模态耦合复杂性:融合视觉专家输出和图像特征,再传入语言模型的过程需要精密设计,系统耦合度较高,不利于轻量化部署。
-
泛化能力仍有限于训练分布:虽然较传统模型更强,但若视觉专家对某类异常识别能力不足,则仍可能影响整体性能。
问题与解答:
• Why型:为什么该方法比传统方案更优?
Myriad通过引入视觉专家提供的异常图,解决了LMM对图像中异常区域缺乏关注的问题,显著提升了模型在复杂场景下的感知与推理能力。同时,它兼具大模型的语言理解与指令跟随能力,能适应更多任务形式和输入变化,相比传统“一模型一任务”的方式更具通用性和灵活性。
• How型:如何将该方法扩展到其他场景?
该方法可迁移到如医学图像异常检测、交通设施损坏识别等领域。只需更换相应领域的视觉专家模型(如医学图像分割器或道路检测模型),并利用相应预训练语言模型(如医学大模型)配合指令模板,即可快速适配不同任务场景,保持框架不变。
Myriad 系统架构详解(依据论文 Section 3)
Myriad 旨在让大语言模型(LLM)能够理解异常图像并完成检测与定位任务。它的架构由以下三个核心组件组成:
1. VE-Guided Visual Feature Extractor(视觉专家引导的视觉特征提取器)
该模块用于从图像中提取有意义的视觉特征,同时将视觉专家(VE)生成的异常图整合进去。详细结构如下:
-
输入包括:
-
原始图像
x -
对应的异常图
m,由视觉专家生成
-
-
结构步骤:
-
原始图像
x和异常图m被拼接(concatenate)成一个四通道图像[x; m]。 -
拼接后的图像被输入到 预训练的视觉编码器(如 SAM Image Encoder)中。
-
输出的视觉特征为
F ∈ ℝ^{H×W×D}。
-
-
接着,将
F输入到一个称为 Adapter 模块 的小型网络中(一个两层 MLP),得到最终的视觉特征F':-
F' = Adapter(F)
-
-
最终的视觉 token 会被格式化为一组 patch token,并输入至多模态融合模块中。
2. Instruction-Based Multimodal Interaction(基于指令的多模态交互)
此模块的任务是整合语言指令、图像内容和异常图,从而激活语言模型的推理能力。其结构包含以下要素:
-
输入组成:
-
自然语言形式的用户指令(prompt)
-
异常图
m -
图像 patch token
F'
-
-
处理流程:
-
使用 Q-Former 作为多模态交互中枢。它接收 Adapter 输出的视觉 token,并将其映射为若干个视觉 token(如 32 个)。
-
这些视觉 token 再通过一层 Linear Projection 映射为与语言模型输入兼容的嵌入向量。
-
与用户指令的文本 token 一起拼接,形成完整的多模态输入序列。
-
3. Multimodal Large Language Model(多模态大语言模型)
这是整个系统的语言推理核心,用于处理融合后的多模态输入并生成异常检测的自然语言输出。
-
模型类型:使用了 Vicuna-7B 或者 LLaMA-2-7B 等开源 LLM。
-
输入:包括文本指令 + 映射后的视觉 token。
-
输出:异常检测结果,例如:
-
是否存在异常;
-
异常部位(文字描述);
-
整体检测结论。
-
图示结构(对应论文 Figure 2)
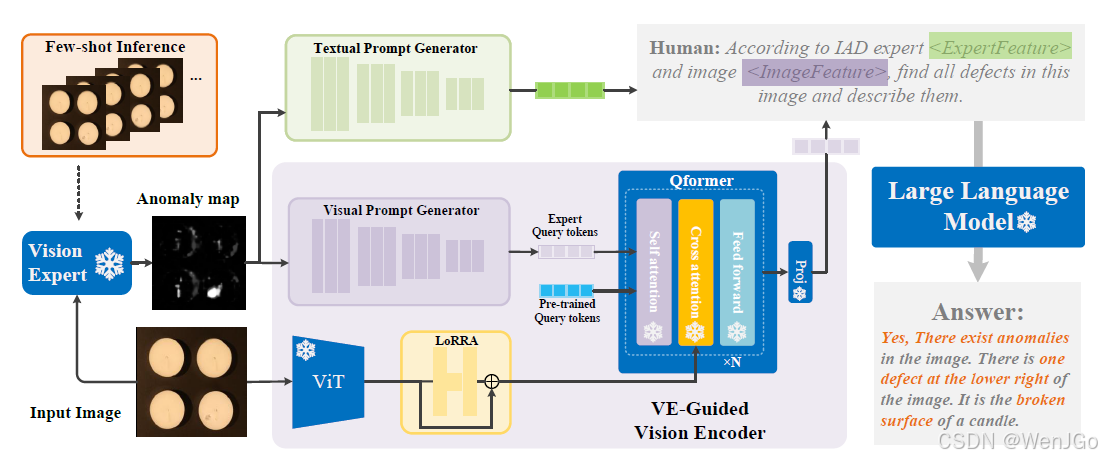
输入:工业图像
-
输入为工业场景下的一张图像,通常用于异常检测。
① 视觉专家(Vision Expert, VE)
-
功能:对输入图像进行分析,估计一个异常图(Anomaly Map)M。
-
意图:为系统提供 先验知识(prior knowledge),标示图像中的潜在异常区域。
② VE-Guided Vision Encoder(视觉专家引导的视觉编码器)
-
输入:原始图像 + 异常图(M)
-
功能:
-
将原始图像和异常图进行拼接([x ; M]),输入编码器。
-
输出更符合 IAD(工业异常检测)语义的视觉特征(更专注于异常区域)。
-
-
模块构成:
-
采用 EVA-CLIP 的 ViT 主干(用于图像编码)
-
后接 Q-Former(用于多模态 token 对齐)
-
特别引入 Expert Prompts(由 VPG 生成,作为“指导提示”)
-
③ VPG(Visual Prompt Generator)
-
功能:根据异常图 M 生成 视觉提示(expert prompts)
-
用途:输入给视觉编码器,用于强调视觉特征中的异常区域。
④ TPG(Textual Prompt Generator)
-
功能:将异常图 M 编码成 语言模型可理解的 VE tokens
-
目的:提升大型语言模型(LLM)利用视觉异常信息的能力。
-
输出:VE tokens,最终送入 LLM 作为额外上下文。
⑤ 大型语言模型(LLM,如 Vicuna)
-
输入:Q-Former 处理后的视觉 tokens + TPG 提供的 VE tokens
-
功能:根据提示、视觉信息和异常区域理解,输出异常检测相关文本结果(如是否异常、异常原因、位置等)
模块之间的依赖关系总结:
| 模块 | 输入 | 处理过程 | 输出 |
|---|---|---|---|
| VE-Guided Visual Encoder | 原始图像 + 异常图 | Vision Encoder + Adapter | 视觉 token |
| Q-Former | 视觉 token | 多模态 token 转换 | LLM-compatible embeddings |
| LLM | token + 用户指令 | 自然语言生成 | 检测结果描述 |
名词解释
【1】AnomalyGPT
AnomalyGPT 是一种基于大型视觉-语言模型(LVLMs)的工业异常检测方法。它旨在解决传统工业异常检测(IAD)方法的局限性,即需要手动设置阈值来区分正常和异常样本。AnomalyGPT 利用了预训练的图像编码器和大型语言模型(LLM),通过模拟异常数据进行微调,从而将IAD知识整合到模型中。该模型不仅能够指示异常的存在和位置,而且无需手动调整阈值,支持交互式查询,并且能够在提供很少正常样本的情况下快速适应新对象。AnomalyGPT 在 MVTec-AD 数据集上取得了显著的成绩,显示了其在无监督学习环境下的强大性能。
【2】ImageBind
ImageBind 是由 Meta AI 提出的一个多模态学习模型,它能够在不需要显式配对数据的情况下,将图像、文本、音频、深度信息、温度信息、惯性数据(IMU)六种不同模态的数据绑定在一个共享的表示空间中。这个模型利用了大规模网络数据(如图像和文本匹配数据)以及自然存在的配对数据(如视频和音频)。ImageBind 的目标是创建一个统一的嵌入空间,使得不同模态的信息可以在其中相互关联和转换。这为跨模态检索、语义组合以及生成任务提供了可能性,例如通过声音生成图像或通过文本描述生成相应的音频内容。
【3】PatchCore
PatchCore 是一种基于图像块(patch-based)的无监督异常检测模型,特别适用于工业场景中的外观缺陷检测。它通过使用预训练的深度神经网络提取多尺度特征,并利用内存库(memory bank)存储正常样本的特征分布,以实现对细微缺陷的高精度检测。PatchCore 的核心优势在于其仅需正常样本即可训练,减少了标注成本;同时,它具有高像素级检测能力,能够捕捉到非常微小的缺陷。此外,PatchCore 还引入了一系列优化策略,如特征金字塔融合、内存库优化策略和高效的推理优化,使其在复杂工业应用场景中表现出色。
总结
- AnomalyGPT 专注于工业异常检测领域,利用了最新的视觉-语言模型技术,解决了传统方法需要手动设置阈值的问题,并且可以处理少量正常样本的情况。
- ImageBind 是一个多模态模型,旨在将多种不同类型的数据(包括但不限于图像、文本、音频等)映射到一个共同的空间中,以便于跨模态理解和应用。
- PatchCore 是一种专门针对工业缺陷检测设计的无监督模型,通过高效地利用正常样本的特征,在像素级别上实现了精确的异常检测。
【4】LLaMA
LLaMA(Large Language Model Meta AI)是由Meta AI(原Facebook AI研究实验室)开发的一个系列的预训练大型语言模型。LLaMA模型以其卓越的性能和开源特性,在人工智能社区中引起了广泛关注,并被广泛应用于各种自然语言处理任务中。
LLaMA的关键特点:
-
开源性:LLaMA是一个开源项目。
-
多规模版本:LLaMA提供了多种规模的版本,包括70亿参数、130亿参数、700亿参数等不同大小的模型。
-
训练数据:LLaMA使用了公开的数据集进行训练,整个训练数据集在token化之后大约包含1.4T的token,并且随着版本迭代,训练数据规模不断增加。
-
技术架构:LLaMA模型采用了Transformer架构,并引入了如前置层归一化(Pre-normalization)、RMSNorm归一化函数、SwiGLU激活函数以及旋转位置嵌入(RoPE)等。
-
性能表现:LLaMA在多个基准测试上表现出色,例如具有130亿参数的LLaMA模型在大多数基准上可以胜过GPT-3(参数量达1750亿。
【5】模态鸿沟
模态鸿沟(Modality Gap)是指在跨模态任务中,不同模态的数据表示之间的差异或不一致性。也就是在多模态学习和应用的背景下,模态鸿沟指的是不同信息来源(如文本、图像、语音等)之间存在的语义差距或特征空间上的不一致。这种差距可能会导致模型难以有效地整合来自不同模态的信息,从而影响最终的任务性能。
在Referring Image Segmentation (RIS) 中,即根据描述性语言来分割图像中的特定对象时,同样面临着像素和词水平上的语言-图像模态鸿沟问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











