










目录
效果展示
 |  |
 |  |
 |  |
 | 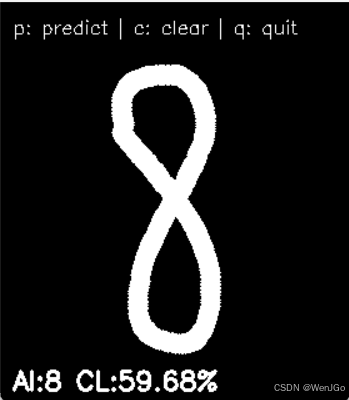 |
 |  |
使用到的Python库讲解
这行代码里用到的三个库其实都挺有意思的。cv2 是 Python 里搞图像处理的扛把子,比如你摄像头拍张图或者视频里截个帧,它都能帮你读进来处理。平时常见的修图功能像模糊滤镜、边缘检测,甚至是人脸识别这种高级操作,它都自带现成的方法直接调。很多做视觉项目的程序员都喜欢用它,因为底层优化得好,处理速度很快。
numpy 这个库你可能经常见到,它最核心的就是处理多维数组。比如你把一张图片读进来之后,其实就是一个三维数组(高度、宽度、颜色通道),这时候用 numpy 的切片操作截取局部图像特别方便。它还能做矩阵运算,像加减乘除这些数学操作可以直接对整个数组批量处理,比用 for 循环快几十倍。很多机器学习框架底层其实都在偷偷用 numpy 做计算加速。
最后这个 load_model 是 TensorFlow 里保存训练成果的关键工具。比方说你用 Keras 搭了个神经网络训练了一晚上,第二天想直接用的话,用这行代码就能把整个模型结构和参数都加载回来。它支持两种保存格式——HDF5 和 TensorFlow 自带的 SavedModel,前者适合轻量化存储,后者会把优化器状态之类的细节也存下来方便接着训练。有时候项目需要部署模型的时候,这个函数能省不少事。
模型训练
我们现在是要实现一个典型的手写数字识别模型(后面训练出来的效果,我只能说有效果,但不是那么好,但是如果你要把这个作为一个你学习人工智能的小Demo的话,还是很有意义的。),咱们分步骤来看每个部分的作用。首先加载MNIST数据集这个经典的手写数字库,里面包含了6万张训练图和1万张测试图,每张都是28x28像素的黑白图片。
数据预处理阶段把图片从二维数组转成四维张量(加了个颜色通道维度),同时把0-255的像素值缩放到0-1之间,这样训练时数值更稳定。
模型结构设计得挺有意思,先用32个3x3的卷积核提取图像特征,这层能捕捉数字的笔画走向这些局部特征。紧跟着的池化层像筛子一样,把特征图尺寸减半,既保留了主要信息又减少了计算量。 展平后的全连接层像翻译官,把前面提取的抽象特征转成最终0-9十个数字的概率,softmax激活函数让十个输出值加起来刚好是100%。
训练配置选用了Adam优化器,这种自适应学习率的算法比传统梯度下降更智能。交叉熵损失函数特别适合多分类任务,配合one-hot编码的标签,能准确衡量预测和实际的差距。训练时每轮都用测试集做验证,方便实时观察模型有没有过拟合。
最后保存的H5文件是个大礼包,不仅存了网络结构、参数权重,连优化器状态都保存了。这样下次要接着训练或者部署到其他平台,直接加载就能用,不用重新搭积木。整个过程跑完大概五分钟,看着准确率从95%飙到99%多,还是挺有成就感的吧?
模型训练整体代码
这里如果你已经下载好对应的包了,但是他的下面的子包还是爆红,跑一下这段测试代码,看能不能正确输出,如果正确输出,就没有问题,爆红是IDE的问题,雨你无瓜。
包完整测试代码
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
print("Keras 已正常工作!")
训练模型代码
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.utils import to_categorical
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 构建模型
model = Sequential([
Conv2D(32, kernel_size=(3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D(pool_size=(2,2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5)
# 保存模型
model.save("mnist_model.h5")
print("模型已保存为 mnist_model.h5")
训练结果
| Epoch | Training Loss | Training Accuracy | Validation Loss | Validation Accuracy | Duration | Steps per Second |
|---|---|---|---|---|---|---|
| 1/5 | 0.1422 | 95.81% | 0.0645 | 97.85% | 14s | 142.86 steps/s |
| 2/5 | 0.0506 | 98.44% | 0.0481 | 98.41% | 14s | 142.86 steps/s |
| 3/5 | 0.0315 | 99.04% | 0.0507 | 98.39% | 15s | 133.33 steps/s |
| 4/5 | 0.0212 | 99.32% | 0.0444 | 98.56% | 15s | 133.33 steps/s |
| 5/5 | 0.0129 | 99.59% | 0.0435 | 98.70% | 16s | 125.00 steps/s |
说明:
- 最终模型保存为
mnist_model.h5 - 验证准确率在 Epoch 3 出现轻微下降(98.39% → 98.41%),但整体保持上升趋势
- 训练时间逐步增加(14s → 16s),可能与模型复杂度或资源占用有关,但是我觉得是这里过拟合了。
- 最终验证准确率达到 98.70%,训练准确率 99.59%,存在轻微过拟合现象,我这里由于只是在讲解这个效果,你们可以不用训练五个回合,我感觉三个就足够了。
(表格数据保留原始精度,百分比数值基于日志显示的4位小数转换计算,格式为两位小数百分比)
AI推理
这里就来到了一个挺有意思的地方了,我们之前训练模型的最终目的是实现一个交互式手写数字识别应用,咱们分模块来看它的实现逻辑。
首先通过加载训练好的MNIST模型,这个模型文件路径需要注意不能有中文,否则可能会读取失败。画布设计成了320x280像素,顶部预留了40像素的黑底提示栏,这样既能保持绘图区域接近MNIST的28x28比例,又能显示操作指引。
鼠标事件处理部分用到了OpenCV的回调机制,按下左键开始绘制,移动时在非提示区域画白色实心圆,松开按键结束绘制。这里画圆的半径设为8像素,既保证了笔画连贯性,又不会让数字太细影响识别。绘制时特意避开y<=40的区域,防止提示文字被涂改,这种细节处理挺实用的。
主循环里的显示逻辑每帧都会复制画布,并在顶部叠加操作提示。预测功能触发时,程序会截取绘图区域并缩放到28x28像素,这个预处理步骤和MNIST数据集格式完全匹配。输入的归一化处理(除以255)也和模型训练时的数据标准化方式保持一致,这对保证识别准确率很重要。
预测结果显示部分用了百分比置信度,这种设计能让用户直观感受模型判断的把握程度。比如显示"AI:7 CL:98.76%"既给出了识别结果,也体现了模型对该结果的信心指数。清空画布和退出功能通过键盘事件实现,这种交互方式符合用户习惯,操作起来比较顺手。
整个程序把图像采集、模型推理、人机交互这几个模块结合了起来,虽然界面简单但功能完整。实际使用中可能会发现,快速连笔画数字时识别率更高,因为模型训练时用的也是规范书写样本,例如9这个数字,你写成两笔它根本识别不出来QAQ。如果遇到识别错误,可以尝试把数字画得居中些,笔画不要超出画布边缘,这样预处理效果更好。但是有些时候就是书写规范性的问题,因为数据集也不算太大。
整体代码
import cv2
import numpy as np
from tensorflow.keras.models import load_model
# 加载训练好的模型(确保路径没有中文)
model = load_model("D:\\IDE\\PyCharmIDE\\projectPosition\\HandCatch\\all\\BOKE_MODEL\\mnist_model.h5")
# 创建空白画布(上面 40px 用来显示文字)
canvas = np.zeros((320, 280), dtype=np.uint8)
drawing = False
prediction_text = "" # 用于存放预测信息
def draw(event, x, y, flags, param):
global drawing
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
elif event == cv2.EVENT_MOUSEMOVE and drawing:
if y > 40: # 避免在提示区画
cv2.circle(canvas, (x, y), 8, 255, -1)
elif event == cv2.EVENT_LBUTTONUP:
drawing = False
cv2.namedWindow("Draw a digit (0-9)")
cv2.setMouseCallback("Draw a digit (0-9)", draw)
font = cv2.FONT_HERSHEY_SIMPLEX
while True:
# 创建一个复制画布用于显示文字
display = canvas.copy()
# 绘制顶部提示文字
cv2.rectangle(display, (0, 0), (280, 40), 0, -1) # 黑色背景
cv2.putText(display, "p: predict | c: clear | q: quit", (10, 25), font, 0.5, 255, 1)
# 如果有预测结果,显示在画布中
if prediction_text:
cv2.putText(display, prediction_text, (10, 310), font, 0.7, 255, 2)
# 显示画布
cv2.imshow("Draw a digit (0-9)", display)
key = cv2.waitKey(1)
if key == ord('q'): # 退出
break
elif key == ord('c'): # 清空画布和预测
canvas[:] = 0
prediction_text = ""
elif key == ord('p'): # 预测
# 仅提取下方画图区域(排除提示文字)
img = canvas[40:, :]
img = cv2.resize(img, (28, 28))
img = img.astype("float32") / 255.0
img = img.reshape(1, 28, 28, 1)
prediction = model.predict(img, verbose=0)
digit = np.argmax(prediction)
confidence = prediction[0][digit]
prediction_text = f"AI:{digit} CL:{confidence*100:.2f}%"
cv2.destroyAllWindows()
总结
如果您觉得这篇文章对您有所帮助
欢迎点赞、转发、收藏,这将对我有非常大的帮助
感谢您的阅读,我们下篇文章再见~ 👋




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











