






已知数据越多,得到的结果可能越精确。为了简单我们介绍多一点符号,我们会写x下标j或者有时我会简单地说,x sub j,表示特征列表。用n来表示特征的总数,用x上标i来表示第i个训练示例。有时我们将其称为包含第i个训练示例的所有特征的向量。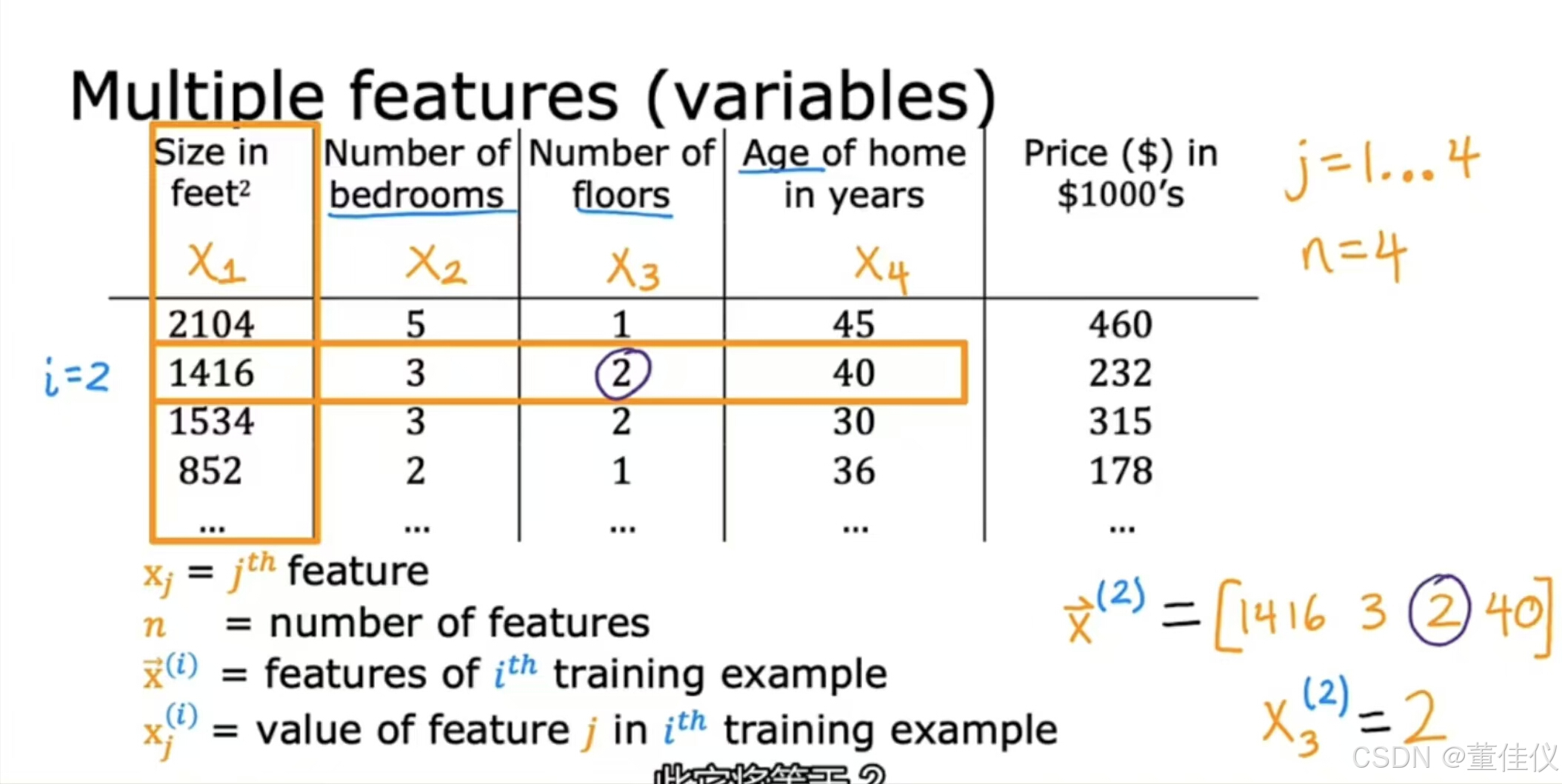
有时为了强调这个x^2不是数字而是一个数学列表,他是一个向量,我们将在其上边画一个箭头,只是为了直观的显示这是一个向量,如上所示。但你不必在符号中绘制此箭头。你可以将箭头视为可选的能指。它们有时只是用来强调这是一个向量而不是数字。
模型
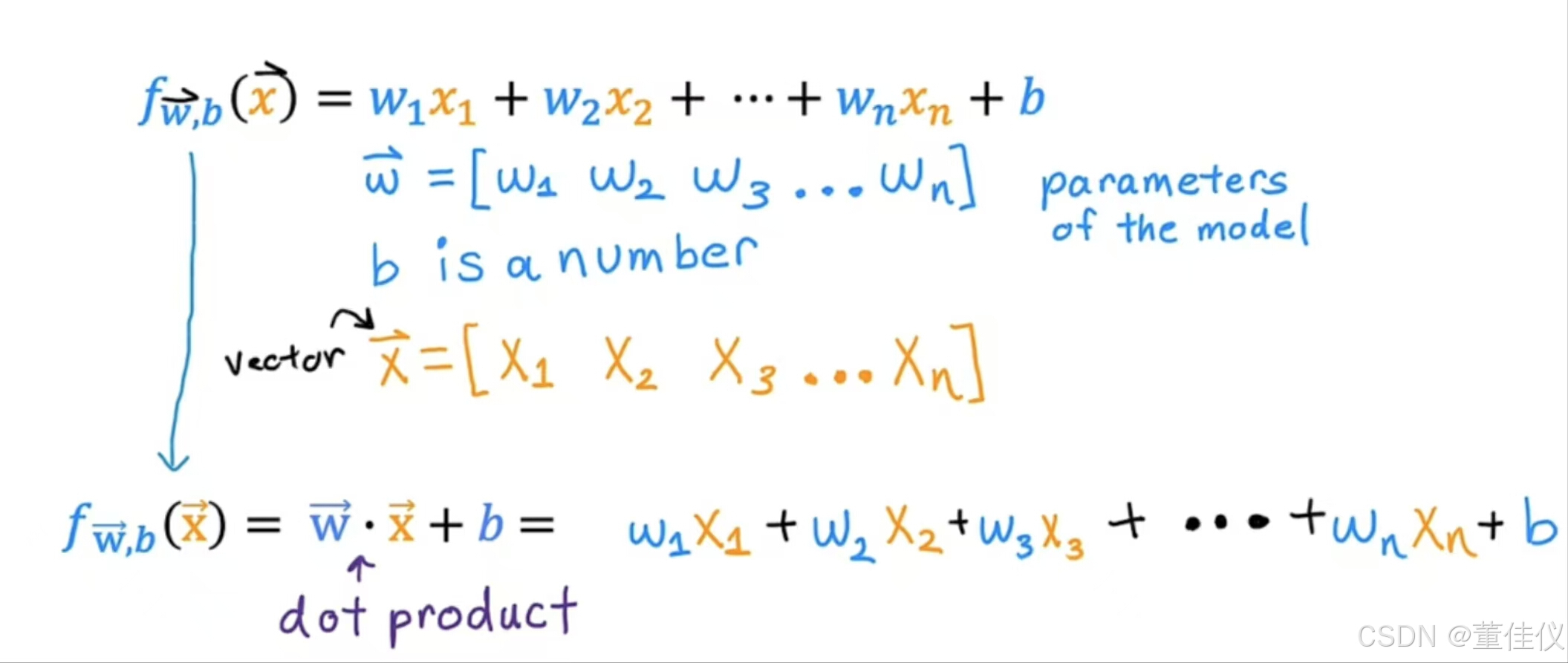
f of x等于,向量w dot并且这个点指的是向量x的线性代数的点积,加上数字b。点积就是w和x的两个向量的点积,通过检查相应的数字对来计算, 这种具有多个输入特征的线性回归模型的名称是多元线性回归。这与只有一个特征的单变量回归形成对比。这个模型称为多元线性回归。
矢量化
矢量化会使您的代码更短,也使它运行更有效。学习如何编写矢量化代码将使你还利用现代数值线性代数库,甚至可能还有代表图像处理单元的GPU硬件。
注意在线性代数中,索引或计数从1开始,所以第一个值下标w1和x1.在python代码中,你可以定义这些变量w,b和x使用这样的数组。在这里我实际上使用的是数值线性代数库在python中称为Numpy,这是迄今为止python和机器学习中使用最广泛的数值线性代数库。因为在python中,数组的索引同时数组中的计数从0开始,您将访问的第一个值w使用w方括号0.第二个值使用w方括号1。同样要访问x的各个特征,你将使用x0,x1和x2.包括python在内的许多编程语言从0而不是1开始计数。 现在,让我们看一个没有矢量化
现在,让我们看一个没有矢量化
来计算模型预测的实现。在代码中,它看起来像这样。你将每个参数w乘以他的相关特征。现在,你可以像这样编写代码,但是如果n不是3而是100或a。另一种方法,不使用矢量化但使用for循环。在数学中,你可以使用求和运算符将w_j的所以乘积相加并且j的x_j等于1到n。然后将引用你在末尾添加b的总和。求和从j等于1到并包括n。对于n等于3,因此j从1,2变为3.在代码中,你可以在0之后进行初始化。然后对于从0到n范围内的j,这实际上使j从0到n减1.然后,从0,1到2,您可以将w_j乘以x_j的积加到f。最后,在for循环之外,添加b。请注意,在python中,范围0到n意味着j从0到n-1.这是用python写的范围n。
如何使用矢量化来做到这一点。可以用一行代码来实现他
矢量化实际有两个好处:1.它使代码更短,现在只有一行代码。2。他的代码运行速度比前两个实现中的任何一个都快得多。
了解矢量化如何运行
比如说你有问题16个特征和16个参数,w1到w16除了参数b。你计算这16个权重和代码的16个导数,也许您将w和d的值存储在两个np.array中,而d存储导数的值。对于此示例,我将忽略b。现在,你要计算这16个参数中的每一个的更新。w_j更新为w_j减去学习率,比如0.1,乘以d_j,对于j从1到16.没有矢量化的编码,你会做这样的事。将w1更新为w1减去学习率0.1乘以d1,接下来类似的更新w2,以此类推到w16,更新为w16减去0.1乘以d16。编码没有矢量化,你可以使用这样的for循环
相反,通过因式分解,你可以想象计算机的像这样的并行处理硬件。它取向量w中的所有16个值并并行减去,向量d中所有16个值的0.1倍,并分配所有16个计算在同一时间,一步回到w。在代码中,你可以按如下方法实现,将w赋值为w减去0.1乘以d。在幕后,计算机采用这些NumPy数组w和d,并使用并行处理硬件高效的执行了所有16次计算。使用矢量化实现,你应该获得更高效的实现线性回归。
用于多元线性回归的梯度下降法
使用向量表示法,我们可以将模型写为f_w,x的b等于向量w.product与向量x加上b。请记住,这里这个点表示.product。 我们的成本函数可以定义为
我们的成本函数可以定义为
w_1到w_n,b的J.但不仅仅是将J视为这些和不同参数w_j以及b的函数,我们将把J写成参数向量w和数字b的函数。 
我们将把J写成参数向量 w和数字b的函数。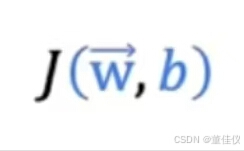 这是梯度下降的样子:
这是梯度下降的样子:
我们将重复更新每个参数w_j为w_j减去Alpha乘以成本J的导数,其中J具有参数w_1到w_n和b。再一次,我们只是把它写成向量w和数字b的J。
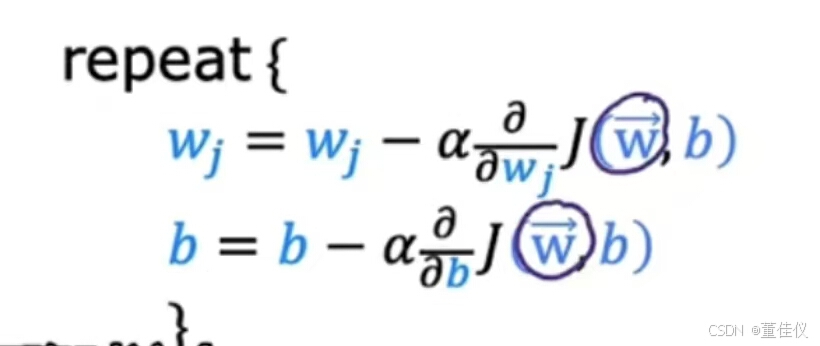
我们将看到梯度下降在具有多个特征时变得有点不同与仅一项功能相比。这是我们使用一个特征进行梯度下降时的情况。我们有一个w的更新规则和一个单独的b更新规则。希望,这些对你来说很熟悉。这项是成本函数J关于参数w的导数。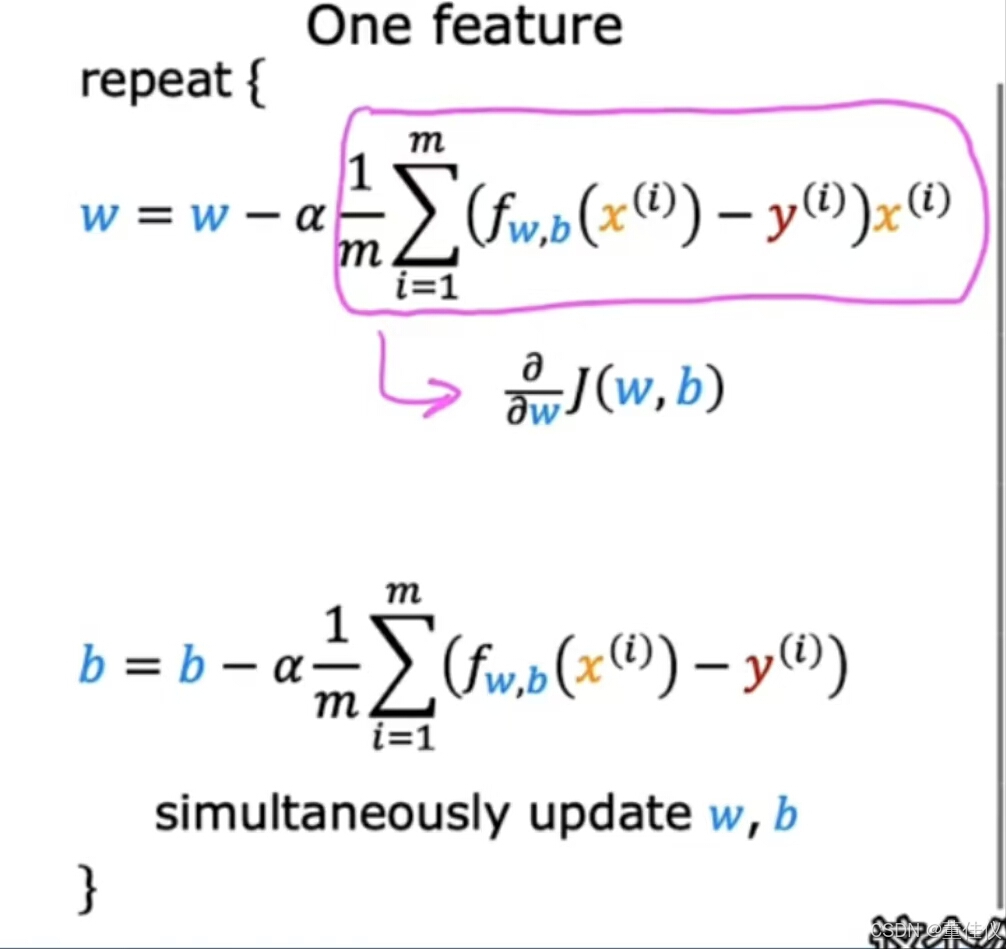 相似的我们有参数b的更新规则,使用单变量回归,我们只有一个特征。我们称该特征为xi,不带任何下标。现在,这里有一个新的符号表示我们有n个特征,其中n是两个或更多。我们得到这个梯度下降的更新规则。将w_1更新为w_1减去alpha乘以这个表达式
相似的我们有参数b的更新规则,使用单变量回归,我们只有一个特征。我们称该特征为xi,不带任何下标。现在,这里有一个新的符号表示我们有n个特征,其中n是两个或更多。我们得到这个梯度下降的更新规则。将w_1更新为w_1减去alpha乘以这个表达式 
,这个公式实际上是成本J关于w_1的导数的导数公式J相当于右边的w_1看起来非常相似左边的一个特征的情况。误差项仍然采用x减去目标y的预测f。一个最大的区别是w和x现在是向量,就像左边的w现在变成了右边的w_1,左边的xi现在变成了xi_1这里右边,这仅适用于J等于1.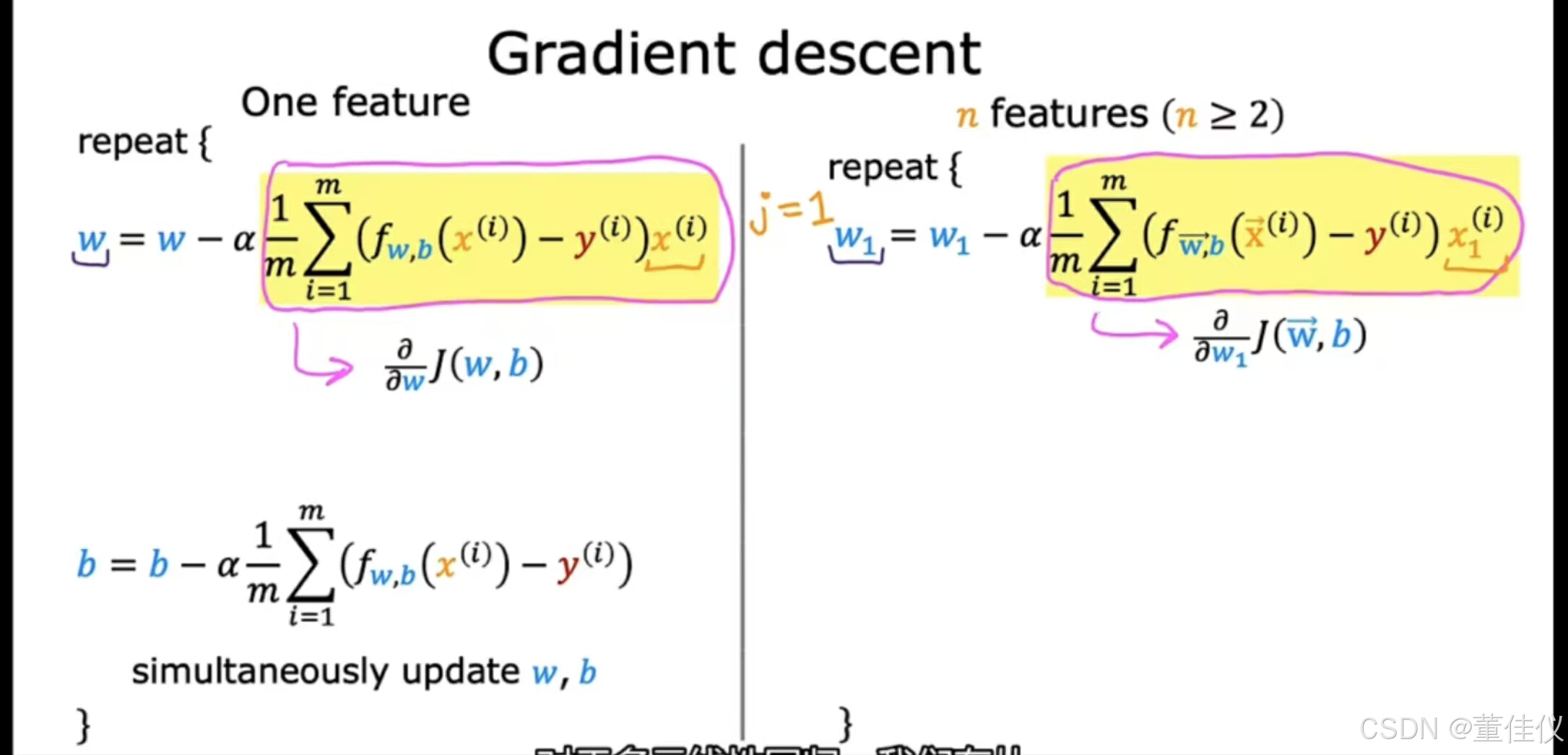 对于多元线性回归,我们有从1到n的J。所以我们将更新参数w_1,w_2,一直到w_n,然后和以前一样,我们将更新b。如果你实现了这个,你将会得到多元回归的梯度下降。这就是多元回归的梯度下降。
对于多元线性回归,我们有从1到n的J。所以我们将更新参数w_1,w_2,一直到w_n,然后和以前一样,我们将更新b。如果你实现了这个,你将会得到多元回归的梯度下降。这就是多元回归的梯度下降。
用另一种查找方式做一个快速的旁注或快速旁注w和b用于线性回归。这种方法称为正规方程。事实证明,梯度下降是最小化成本函数J以找到w和b的好方法,还有另一种算法只适用于线性回归,几乎没有你在本专业中看到的用于求解w和b的其他算法而这种其他方法不需要迭代梯度下降算法。称为正规方程法,事实证明可以使用一个高级线性代数库,无需迭代即可在一个目标中求解w和b。正规方程法的一些缺点是:首先与梯度下降不同,这个没有推广到其他学习算法,如果特征数量和这么大,正规方程方法也很慢。几乎没有机器学习从业者应该实现正规方程方法他们自己,但如果你使用的是成熟的机器学习库和调用线性回归,有可能在后端,它将用来解决w和b。
特征缩放
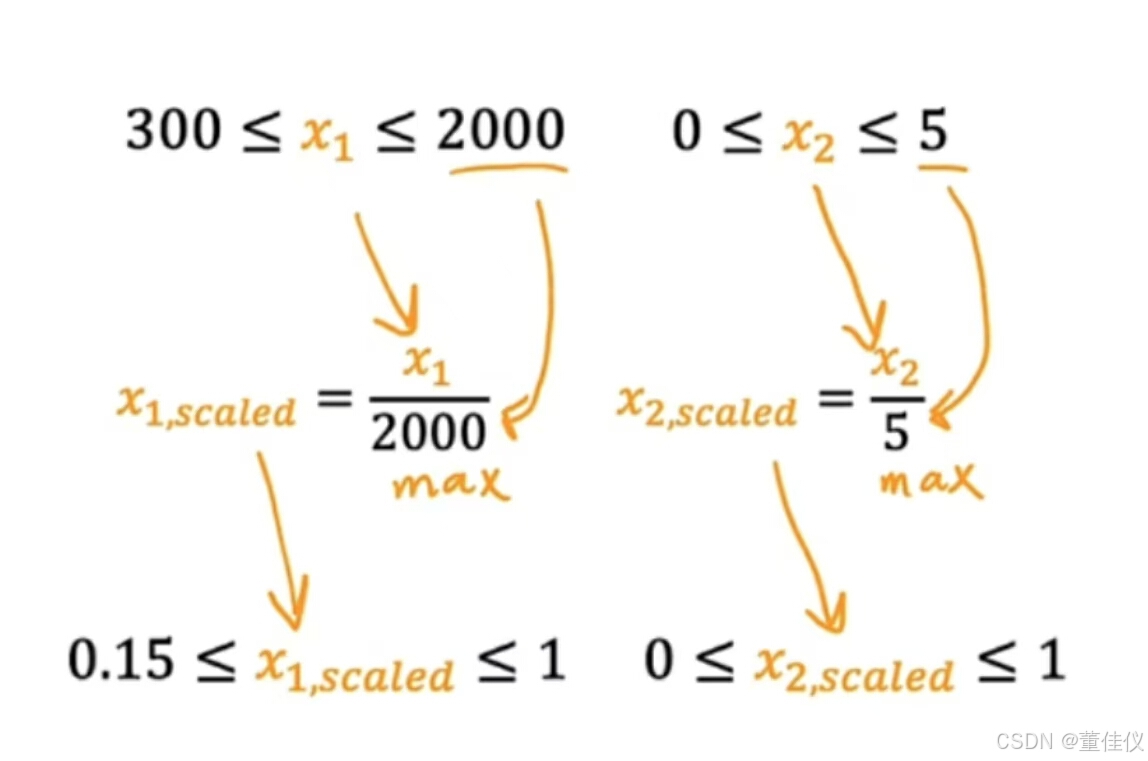
两边同时除以最大范围,除了除以最大值以外,你还可以执行所谓的均值归一化。这看起来是,你从原始特征开始,然后你重新缩放他们,使两者其中以零为中心。以前它们只有大于零的值,现在他们既有负值又有正值这通常可能在负一和正一之间
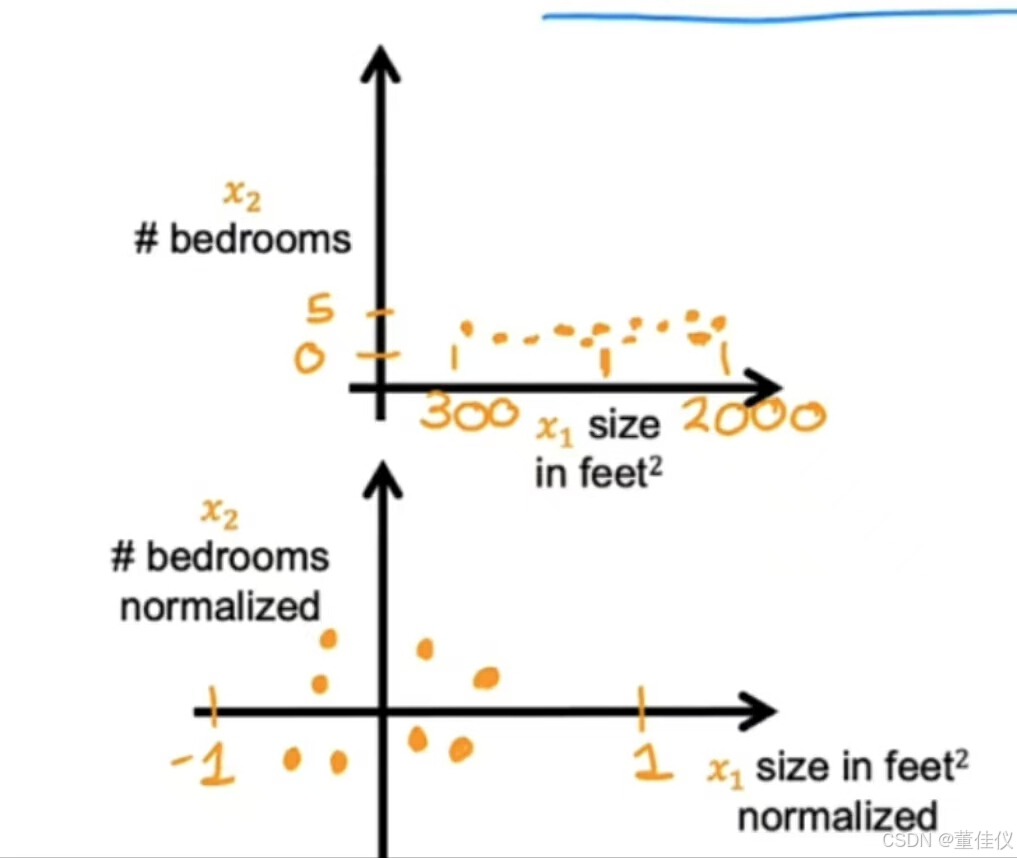
要计算x_1的均值归一化,首先求均值,也称为训练集上x_1的均值,我们称其为均值Mu_1,这是希腊字母Mu。假如你发现特征1的平均值,Mu_1是600平方英尺。让我们取每个x_1,减去平均Mu_1,然后让我们除以差值2000减去300,其中2000是最大值,300是最小值,如果你这样做,你会得到标准的x_1范围为负0.18—0.82。同样,要平均归一化x_2,你可以计算特征2的平均值。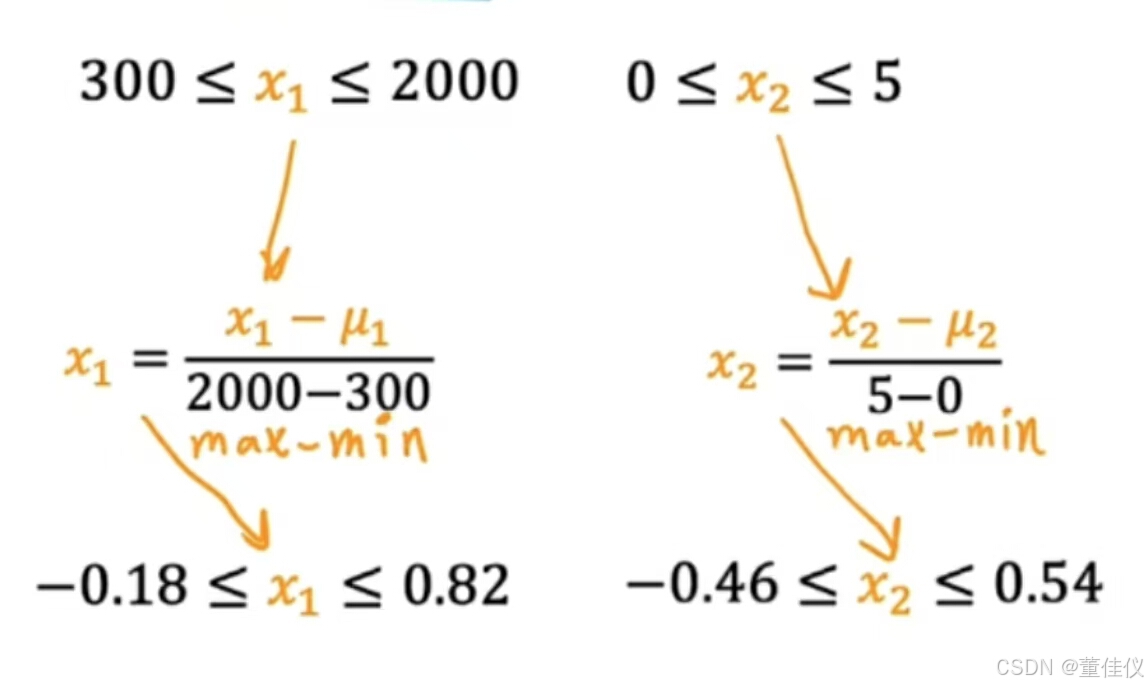
最后一个常见的重新缩放方法调用Z-score标准化。为了实现 Z-score归一化,需要计算每一个特征的标准差。如果不知道标准差是多少,不用担心一会会学习。或者你听说过正态分布或钟形曲线,有时也被称为高斯分布,这就是标准差对于正态分布的样子。如果你知道什么是标准差然后实现Z-score归一化,你首先计算平均Mu以及标准差,这通常由每个特征的小写希腊字母Sigma表示。。例,也许特征1的标准差为450,平均值为600,然后对Z-score归一化x_1,取每个x_1,减去Mu_1,然后除以标准差,我将其表示为Sigma1。你可能会发现Z分数已标准化x_1现在的范围为-0.67-3.1。同样如果计算第二个特征的标准差为1.4且均值为2.3,然后你可以计算x_2,减去Mu_2,然后除以Sigma2,在这种情况下,由x_2归一化的Z分数现在可能范围为-1.6-1.9。如果你将训练数据绘制在图上的归一化x_1和x_2上,他可能看起来像这样
根据经验,在执行特征缩放时,你可能希望将功能范围从任何地方每个特征x大约为负一到大约加一。但是这些值,负一和正一可能有点松散。如果范围从负三到正三或负0.3到正0.3.所有这些都完全没问题。如果你有一个特征x_1最终介于0到3之间,这不是问题。如果你愿意,你可以重新缩放它,但如果你不重新缩放它,它也应该可以正常工作。或者,如果你有不同的特征x_2,其值介于负数之间2再加上0.5,其次,没关系,重新缩放它没有害处,但是,如果你也不管他,那也没事。但是如果另一个特征,比如这里的x_3,范围从负100到正100,那么这具有非常不同的值范围,例从负一到正一你可能最好重新放缩这个特性x_3所以他的范围从接近负一到正一。同样,如果你有一个特征x_4具有非常小的值,比如在-0.00001和正0.00001之间,那么这些值是如此之小这意味着你可能想重新缩放它。最后如果你的特征x_5例医院病人受体温范围从98.6-105华氏度在这种情况下这些值在100左右,实际上相当大与其他比例特征相比,这实际上会导致梯度下降运行更慢。在这种情况下,特征重新缩放可能会有所帮助。几乎没有任何伤害进行特征重新缩放。
这就是特征缩放。有了这个技巧,你通常可以得到梯度下降运行得更快。
判断梯度下降是否收敛
这里是梯度下降规则,关键选择之一是学习率alpha的选择。
确保梯度下降运行良好,回想一下梯度下降的工作是找到参数w和b希望最小化成本函数J。经常做的是绘制成本函数J,它是在训练集上计算出来的,我在梯度下降的每次迭代中绘制J的值。请记住,每次迭代意味着在参数w和b的每次同时更新之后。在这个图中,横轴是迭代次数到目前为止你已经运行的梯度下降。你可能会得到这样的曲线注意横轴是迭代次数梯度下降,而不是像w和b这样的参数。 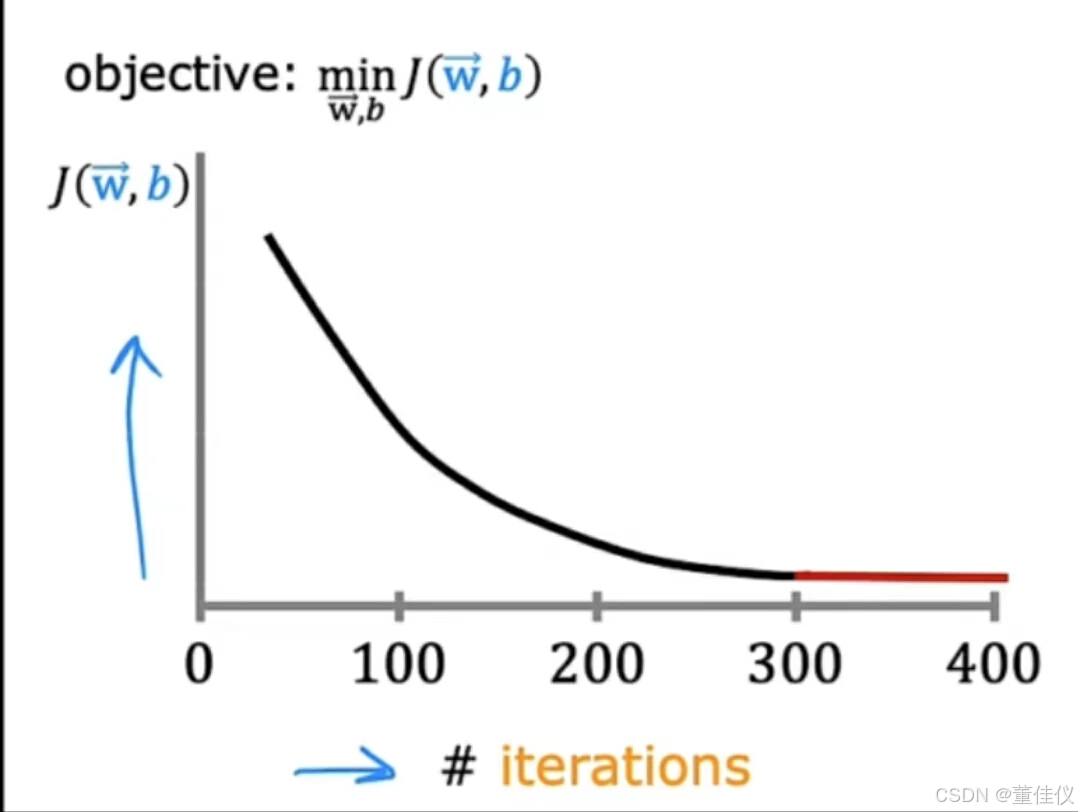
这与你之前看到的纵轴为成本的图表不同J和水平轴是单个参数,如w或b。这条曲线要被称为学习曲线。请注意,有几种不同类型的学习机器学习中使用的曲线,如果你看曲线上的这个点,这意味着之后你跑完100次迭代的梯度下降, 意味着100次同时更新参数,你有一些关于w和b的学习值。如果您计算w和b的值的成本J,w,b.在100次迭代后得到的那些,你得到成本J的这个值。也就是纵轴上的这个点。这里的一点对应于你之后得到的参数的J值200次梯度下降迭代。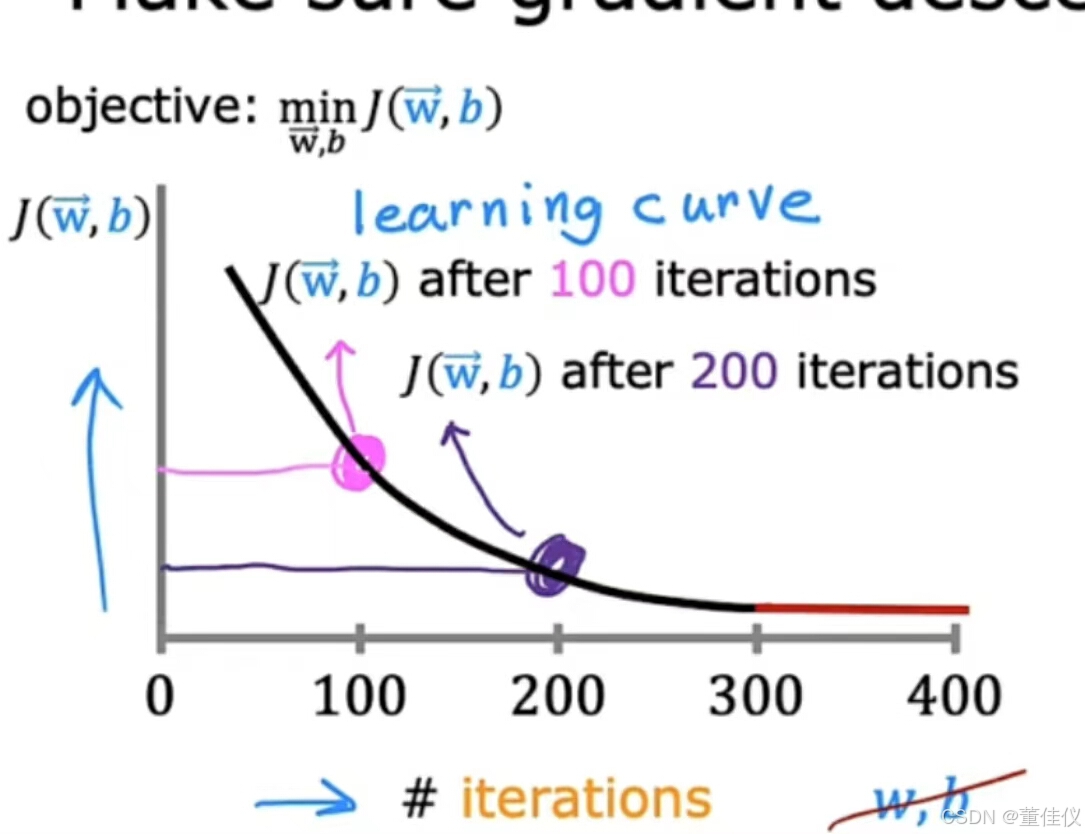 查看此图可帮助你了解成本J如何变化在每次梯度下降迭代之后。
查看此图可帮助你了解成本J如何变化在每次梯度下降迭代之后。
如果梯度下降工作正常,那么成本J应该每次迭代后减少。如果J在迭代后增加,这意味着alpha选择不当这通常意味着alpha太大,或者代码中可能存在错误这一部分可以告诉你的另一件有用的事情是,如果你看一下这曲线当你也达到300次迭送时,成本J正在平衡关闭并且不再减少太多。通过400次迭代,曲线看起来已经变平了。这意味着梯度下降或多或少地收敛了,因为曲线不再减少。梯度下降的迭代次数在不同的应用程序之间进行转换可能会有很大差距。在一个应用程序中,他可能会在30次迭代后收敛对于不同的应用程序,可能需要10000或10100100次迭代。
确定模型何事完成训练的另一种方法是使用自动收敛测试。这是希腊字母epsilon。让我们让epsilon是一个代表一个小数字的变量,例如0.001或10^-3。如果再一次迭代中成本J减少的幅度小于这个数字epsilon,那么你很可能在你看到的曲线的这个平坦部分左边,你可以声明收敛。记住,收敛,希望在你找到参数的情况下w和b接近于J。我通常发现选择正确的值epsilon是相当困难的,我实际上倾向于看左边这样的图表,而不是依靠自动收敛测试。 看立体图就可以告诉你,如果梯度下降也不能正常工作,我会提前给您一些警告
看立体图就可以告诉你,如果梯度下降也不能正常工作,我会提前给您一些警告
如何设置学习率
如果你绘制多次迭代的成本并注意到成本有时上升有时会下降,你应该将其视为梯度下降无法正常工作的明显迹象。这可能意味着代码中存在错误。或者有时这可能意味着你的学习率太大所以说这里有一个说明可能发生的事情。这里纵轴是一个代价函数J,横轴代表一个参数,也许w_1,如果学习率太大,那么如果你从这儿里开始,你的更新步骤可能会超出最小值并最终出现在此处,在这里的下一个更新步骤中,你的增益超调所以你最终在这里等等这就是为什么成本有时会上升而不是1下降的原因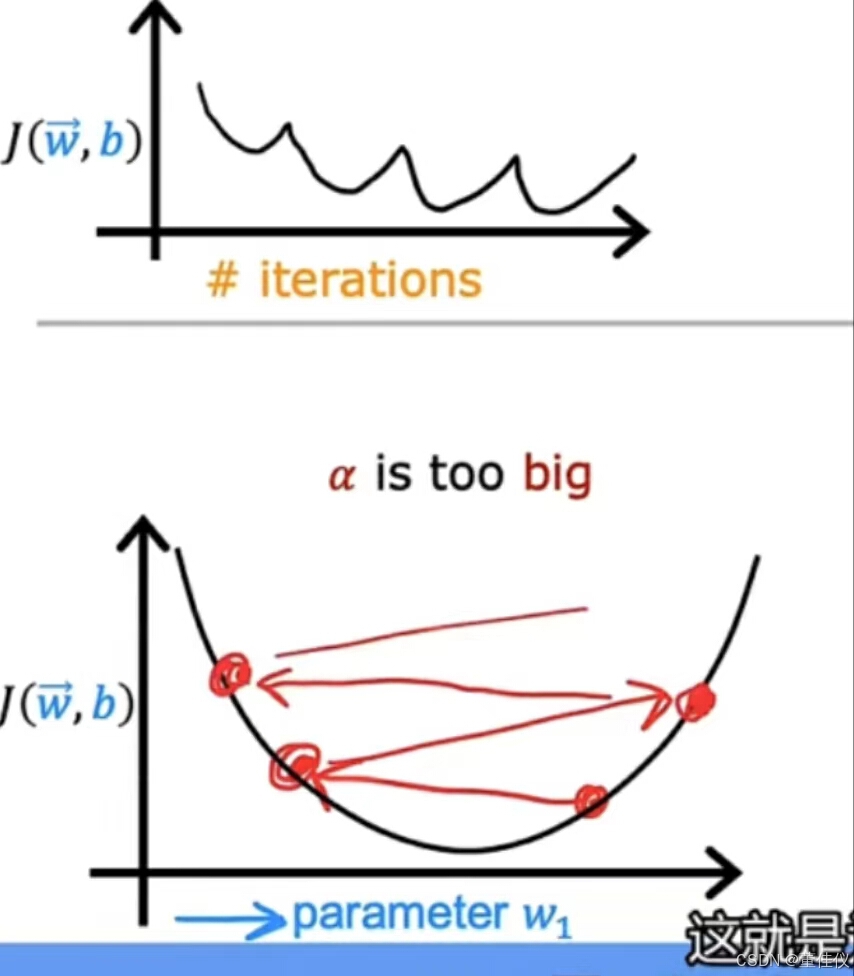
要解决此问题,你可以使用较小的学习率。然后你的更新可能从这里,然后一点点下降我们希望他会持续减少,直到达到全国最小值,有时你会看到迭代成本不断增加,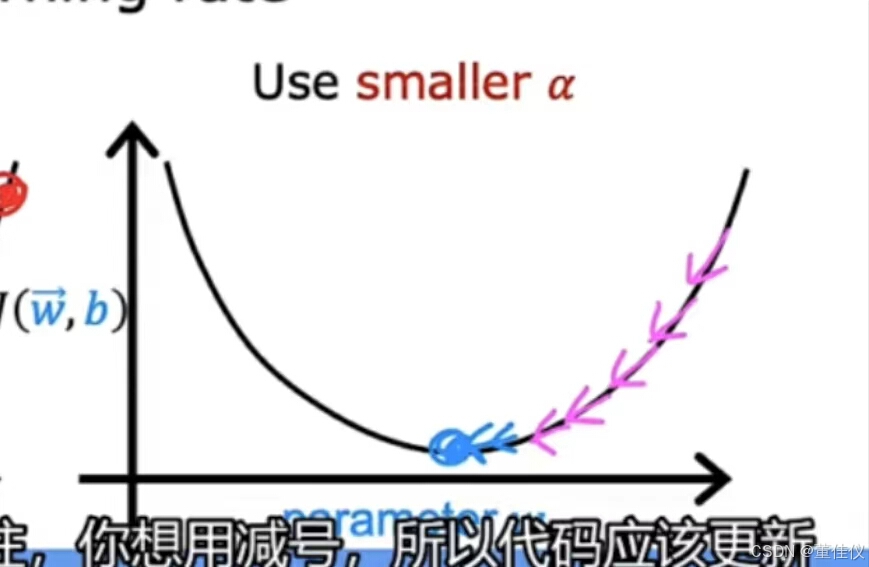 就像这里的曲线。这也可能是由于学习率太大,并且可以通过选择较小的学习率来解决。但是像这样的学习率也可能是代码被破坏的迹象。例如,如果我编写了代码以使w_1更新为w_1加上alpha乘以这个导数,这可能导致每次迭代的成本持续增加。
就像这里的曲线。这也可能是由于学习率太大,并且可以通过选择较小的学习率来解决。但是像这样的学习率也可能是代码被破坏的迹象。例如,如果我编写了代码以使w_1更新为w_1加上alpha乘以这个导数,这可能导致每次迭代的成本持续增加。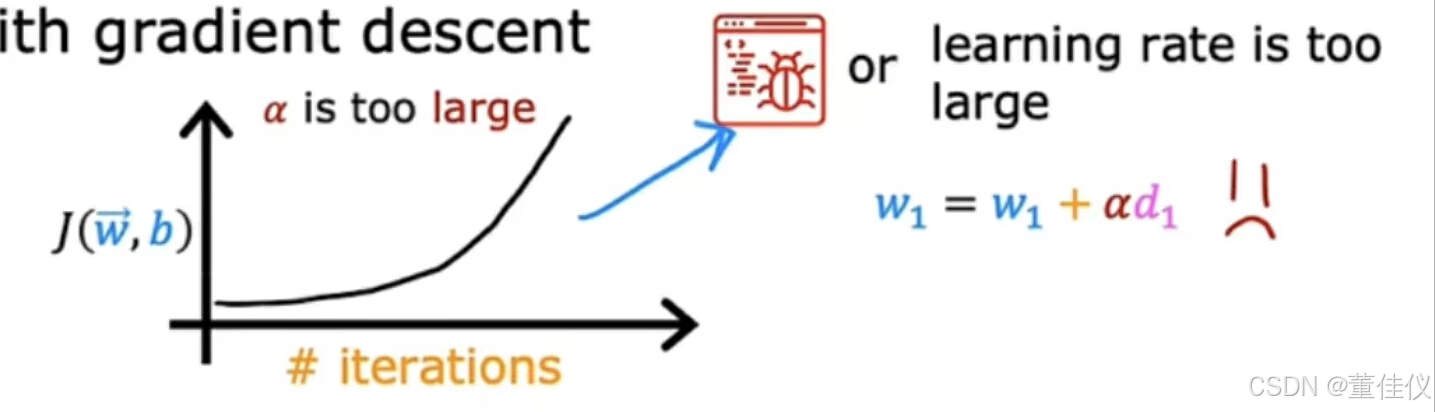 这是因为具有导数项会使你的成本J进一步远离全局最小值而不是更接近。所以记住,你想用减号,所以代码应该更新w_1更新w_1减去alpha乘以导数项
这是因为具有导数项会使你的成本J进一步远离全局最小值而不是更接近。所以记住,你想用减号,所以代码应该更新w_1更新w_1减去alpha乘以导数项 。正确实现梯度下降的一个调试技巧是在最够小的学习率下,成本函数应该每次迭代都会减少。所以如果梯度下降不起作用,我经常做的一件事就是将alpha设置为一个非常小的数字,看看这是否会导致每次迭代的成本降低。如果将alpha设置为非常小的数字,J不会在每次迭代中减少,而是有时会增加,那么这通常意味着代码中某个地方存在错误。请注意,将alpha设置为非常非常小意味着此处为调试步骤和非常小的alpha值不会是最有效的选择用于实际训练你的学习算法。一个重要的权衡是如果你的学习率太小,那么梯度下降可能需要很多迭代才能收敛。所以当我运行梯度下降时,我通常会试alpha的一系列值。我可以从尝试学习率开始0.001,我也可以,尝试将学习率提高10倍0.01,0.1或1等等,对于alpha的每一种选择,你可能会运行梯度下降少数迭代并绘制成本函数 J作为迭代次数的函数,在尝试了几个不同的值之后,然后,你可能会选择似乎会降低学习率的alpha
。正确实现梯度下降的一个调试技巧是在最够小的学习率下,成本函数应该每次迭代都会减少。所以如果梯度下降不起作用,我经常做的一件事就是将alpha设置为一个非常小的数字,看看这是否会导致每次迭代的成本降低。如果将alpha设置为非常小的数字,J不会在每次迭代中减少,而是有时会增加,那么这通常意味着代码中某个地方存在错误。请注意,将alpha设置为非常非常小意味着此处为调试步骤和非常小的alpha值不会是最有效的选择用于实际训练你的学习算法。一个重要的权衡是如果你的学习率太小,那么梯度下降可能需要很多迭代才能收敛。所以当我运行梯度下降时,我通常会试alpha的一系列值。我可以从尝试学习率开始0.001,我也可以,尝试将学习率提高10倍0.01,0.1或1等等,对于alpha的每一种选择,你可能会运行梯度下降少数迭代并绘制成本函数 J作为迭代次数的函数,在尝试了几个不同的值之后,然后,你可能会选择似乎会降低学习率的alpha
值,迅速,但也始终如一。事实上,我实际上所做的就是尝试这样的一系列值。尝试0.001后我将学习率提高三倍至0.003.之后我有尝试0.01,他又是0.003的三倍左右。所以这里粗略的尝试了梯度下降,每个值为alpha大约是之前值的三倍我要做的是尝试一系列值,直到我发现他的值太小,然后还要确保我找到了一个太大的值。我会慢慢尝试选择尽可能大的学习率,或者只是比我发现的最大合理值略小的东西。当我这样做时,它通常会为我的模型提供良好的学习率。我希望这项技术对你选择也有用实现梯度下降的良好学习率。
特征工程
事实上,对于许多实际应用,选择或输入正确的特征是使算法运行良好的关键步骤。让我们重新审视预测房子价格的示例来学习特征工程。假设每个房子都有两个特征。x_1是房屋所建地块的地块宽度。这种现实状态也被称为地段的正面第二个特征,x_2,是手数的深度,让我们假设房子建在一块长方形的土地上。鉴于这两个特征x_1和x_2,你可能会构建一个像这样的模型,其中f of x是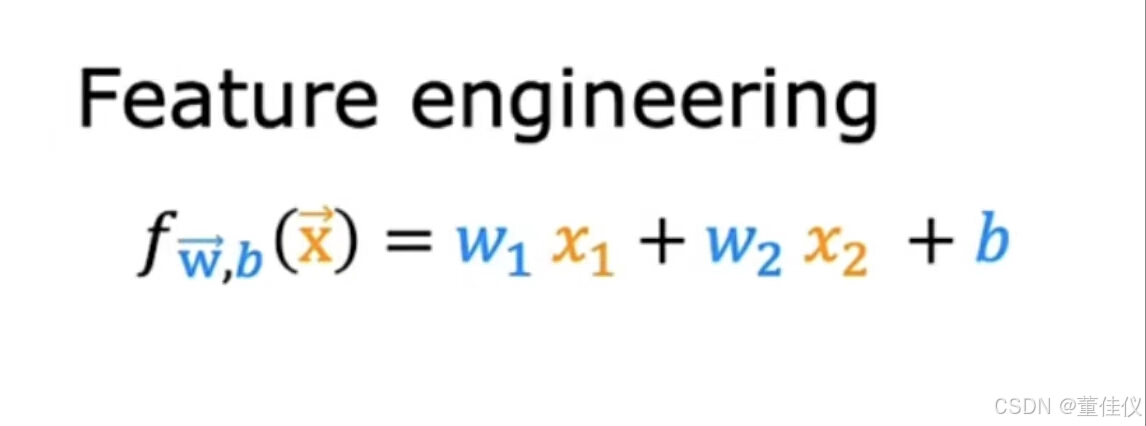
x_1是临街面或宽度,x_2是深度。这个模型可能工作正常但这里有另一种选择,您可以选择不同的方式在模型中使用这些功能可能会更有效。你可能会注意到土地的面积可以计算出来作为正面或宽度乘以深度,你可能有一种直觉,土地面积更能预测价格比正面和深度作为单独的特征。你可以将新特征x_3定义为x_1乘以x_2。这个新特征x_3等于地块的面积。使用此功能,你可以拥有一个模型 
以便模型现在可以选择参数w_1,w_2和w_3,取决于数据是否显示该地段的正面或深度或面积x_3原来是最重要的是预测房子的价格。我们刚刚所创建的一个新特性就是所谓的特性工程的一个例子,你可以在其中使用你对问题的知识或直觉来设计新功能,通常通过变换或组合原始特征问题以使学习算法更容易做出准确的预测。根据你可能对应用程序有哪些见解,而不是仅仅采用你碰巧拥有的功能,有些通过定义新功能开始,你可能可以获得更好的模型。
多项式回归
以多元线性回归和特征工程的思想来想出一种称为多项式回归的新算法,它可以让您拟合曲线,非线性函数,您的数据。假设你有一个住房看起来像这样的数据集,其中特征x是以平方英尺为单位的大小。它看起来不像一条直线非常适合这个数据集。也许你想拟合一条曲线,也许是数据的二次函数,比如这包括大小x和y平方,这是大小提高到2的幂。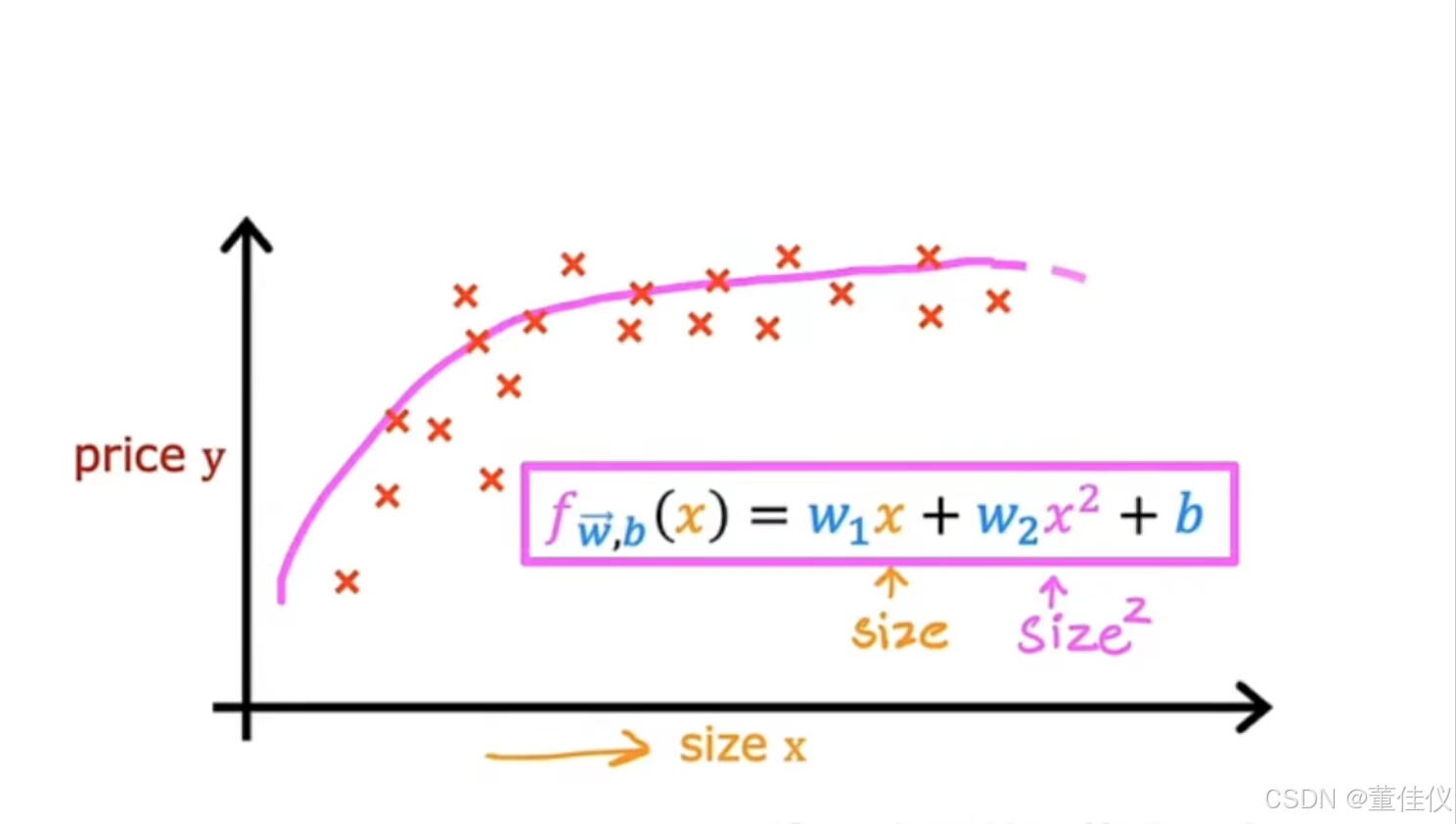 也许这会让你更好的适应数据。但是你可能会认为你的二次模型没有真正意义因为二次函数最终会回归
也许这会让你更好的适应数据。但是你可能会认为你的二次模型没有真正意义因为二次函数最终会回归
。当规模增加时,我们真的不会期望房价下跌。大房子似乎通常应该花费更多。然后你可以选择一个三次函数,我们现在不仅有x的平方还有x的立方。也许这个模型在这里产生了这条曲线,它更合适数据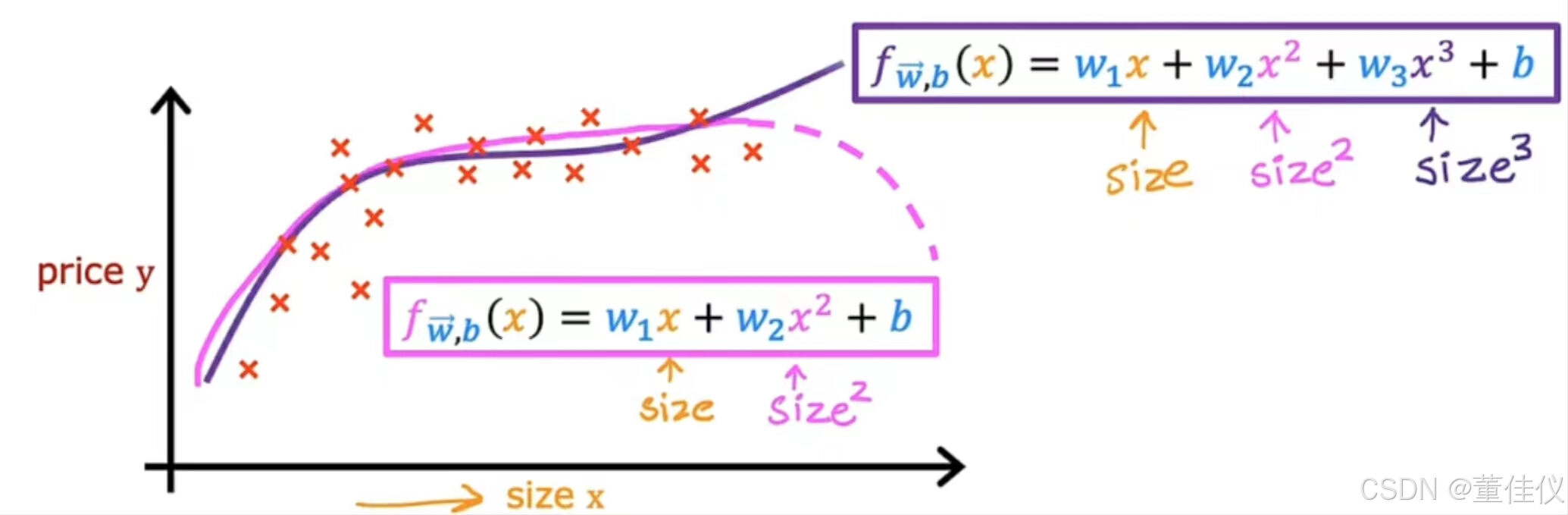
因为大小最终会随着 大小的增加而恢复。这些都是多项式回归的例子,因为你选择了您的可选特征x,并将其提高到二或三或任何其他幂的幂。在三次函数的情况下,第一个特征是大小,第二个特征是大小的平方,第三个特征是大小的立方。如果你创建的功能是这些力量就像原来这样的平方的特征,那么特征缩放变得越来越重要。如果房子的大小不等,1-1000平方英尺,然后第二个特征,即大小的平方,范围从一到一百万,第三个特征,他的大小是立方的,范围从1到10亿这两个特征,x平方和x立方,具有非常不同的范围于原始特征x相比的值。如果你使用梯度下降,则应用特征缩放以获得,将您的特征转换为可比较的值范围。最后,只是最后一个示例,说明你如何真正拥有多种功能可供选择,另一种合理的替代方法是取大小的平方和size cubed就是说使用x的平方根。您的模型可能看起来像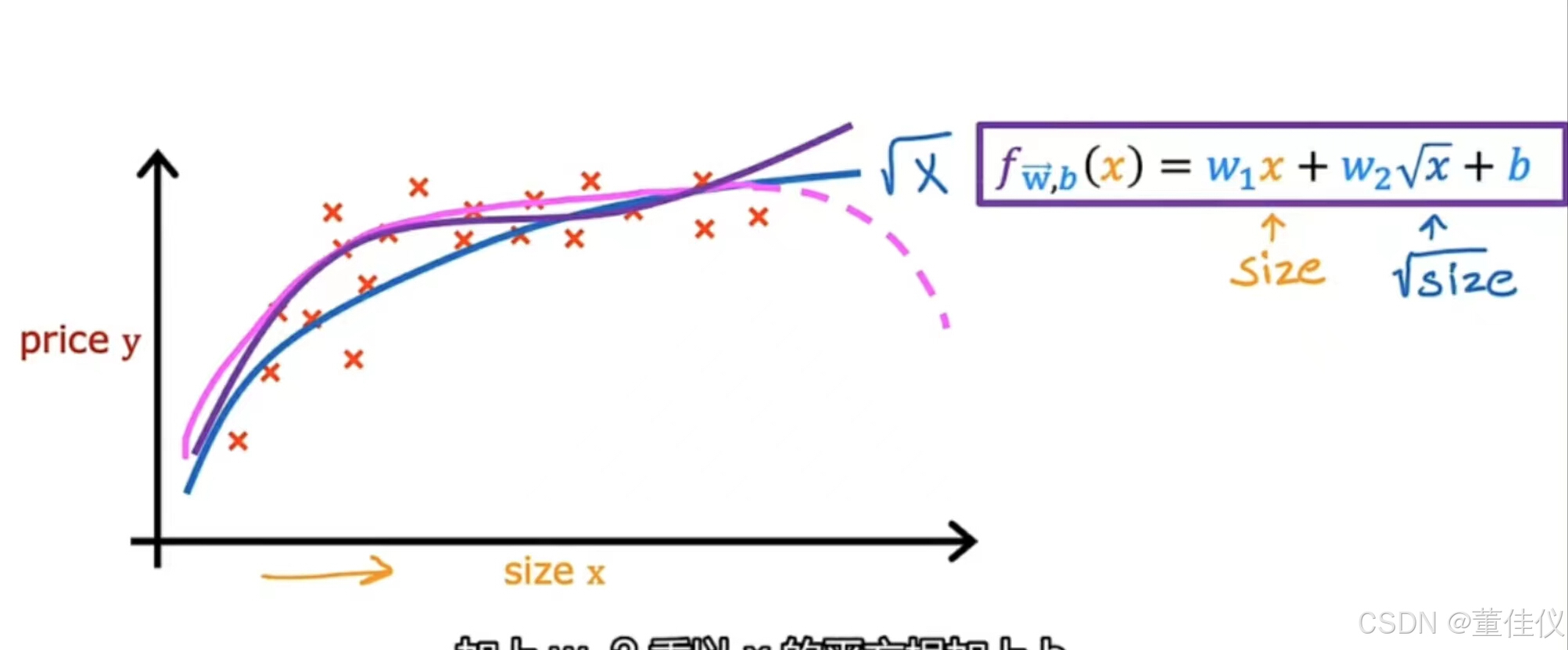
这样,随后x的增加,她变得不那么陡峭,但他永远都不会变平而且他肯定永远不会回来。这将是另一种功能选择可能也适用于这个数据集。通过使用特征工程和多项式函数,你可以获得为了您的数据提供更好的模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









