







 Seaborn的pairplot函数用于展示数据集中各变量之间的关系。通过全量放入变量,可以观察到对角线上的特征分布及非对角线上的相关性。使用kind和diag_kind参数调整显示类型,hue参数可用于分类显示,揭示不同类别间的差异。通过vars参数可以选择特定变量进行分析,如观察到萼片、花瓣长度和宽度对区分花种的重要性。
Seaborn的pairplot函数用于展示数据集中各变量之间的关系。通过全量放入变量,可以观察到对角线上的特征分布及非对角线上的相关性。使用kind和diag_kind参数调整显示类型,hue参数可用于分类显示,揭示不同类别间的差异。通过vars参数可以选择特定变量进行分析,如观察到萼片、花瓣长度和宽度对区分花种的重要性。
sns.pairplot()
- 用来展示两两特征之间的关系
import pandas as pd
from sklearn import datasets
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.set_style('white',{'font.sans-serif':['simhei','Arial']}) #解决中文不能显示问题
iris=datasets.load_iris()
iris_data= pd.DataFrame(iris.data,columns=iris.feature_names)
iris_data['species']=iris.target_names[iris.target]
iris_data.head(3).append(iris_data.tail(3))
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
iris_data.rename(columns={
"sepal length (cm)":"萼片长",
"sepal width (cm)":"萼片宽",
"petal length (cm)":"花瓣长",
"petal width (cm)":"花瓣宽",
"species":"种类"},
inplace=True
)
iris_data.head(3).append(iris_data.tail(3))
| 萼片长 | 萼片宽 | 花瓣长 | 花瓣宽 | 种类 | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
kind_dict = {
"setosa":"山鸢尾",
"versicolor":"杂色鸢尾",
"virginica":"维吉尼亚鸢尾"
}
iris_data["种类"] = iris_data["种类"].map(kind_dict)
画变量之间关系的图
1.全部变量都放进去
# 全部变量都放进去
sns.pairplot(iris_data)
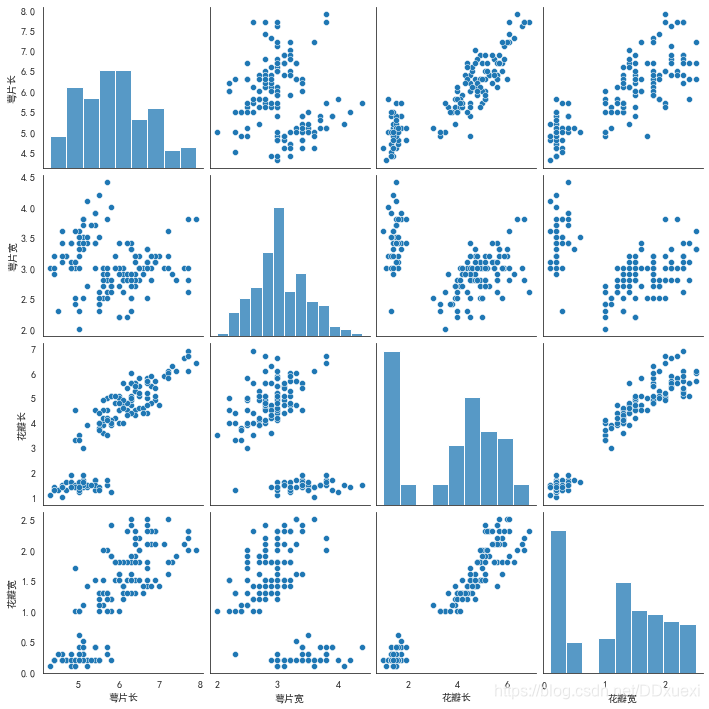
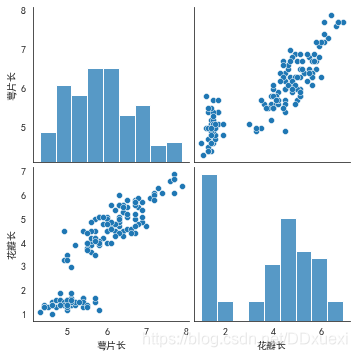
- 可以看到对角线上是各个属性的直方图(分布图),而非对角线上是两个不同属性之间的相关图,
- 从图中我们发现,花瓣的长度和宽度之间以及萼片的长短和花瓣的长、宽之间具有比较明显的相关关系
2.方法中的kind参数和diag_kind参数
#kind:用于控制非对角线上图的类型,可选'scatter'与'reg'
#diag_kind:用于控制对角线上的图分类型,可选'hist'与'kde'
# kind='scatter'时就相当于原图
sns.pairplot(iris_data,kind='reg',diag_kind='ked')
sns.pairplot(iris_data,kind='reg',diag_kind='hist')
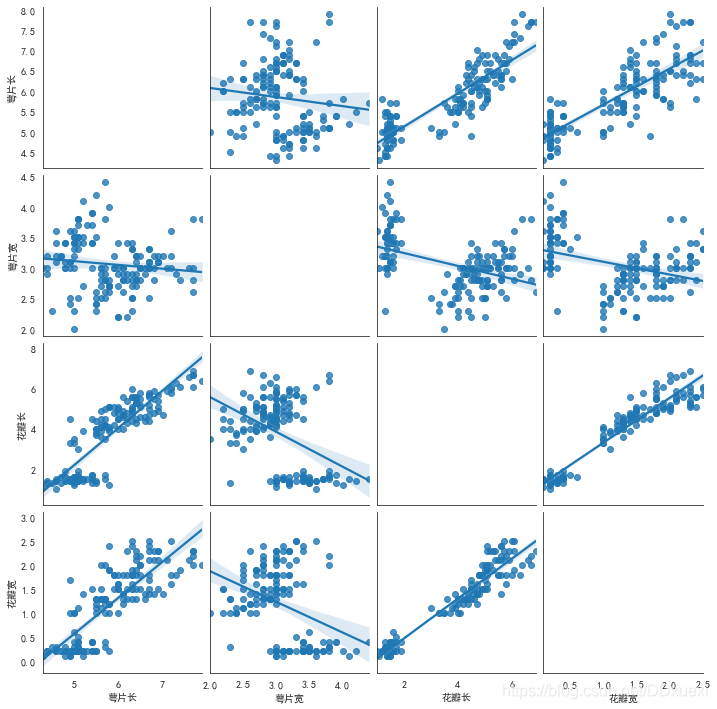
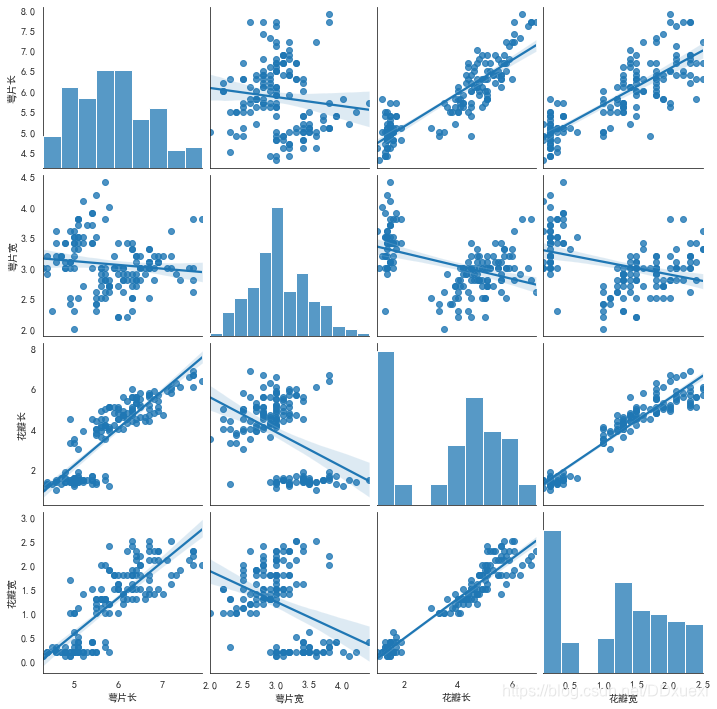
# sns.pairplot(iris_data,kind='scatter',diag_kind='hist')
# sns.pairplot(iris_data,kind='reg',diag_kind='hist')
3.方法中的hue参数
#hue:针对某一字段进行分类
sns.pairplot(iris_data,hue='种类')
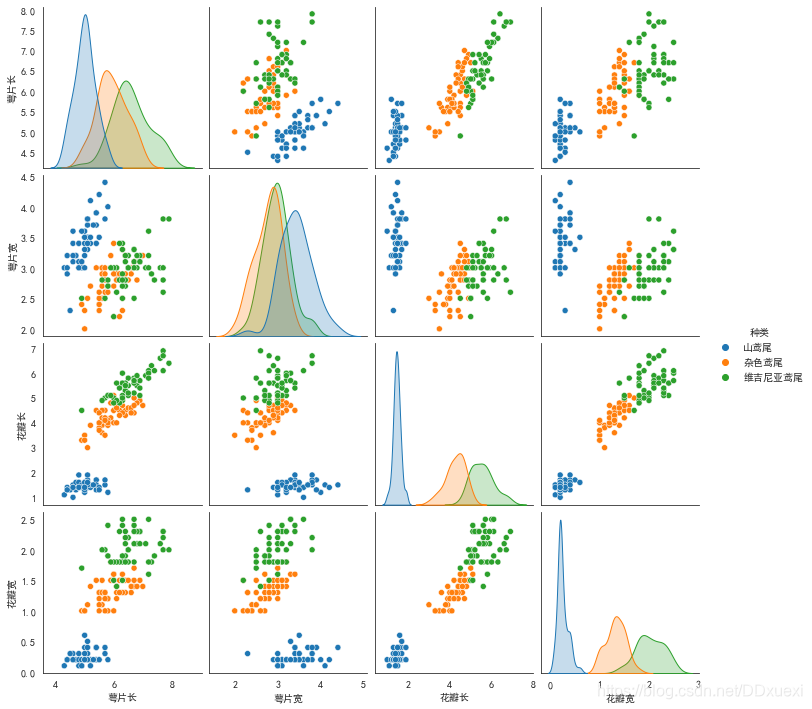
- 经过hue分类后的pairplot中发现,不论是从对角线上的分布图还是从分类后的散点图,
都可以看出对于不同种类的花,其萼片长、花瓣长、花瓣宽的分布差异较大,
-换句话说,
这些属性是可以帮助我们去识别不同种类的花的。
比如,对于萼片、花瓣长度较短,花瓣宽度较窄的花,那么它大概率是山鸢尾
4.vars参数选择特定的变量
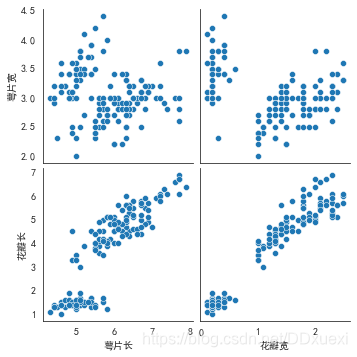
#vars:研究某2个或者多个变量之间的关系vars,
#x_vars,y_vars:选择数据中的特定字段,以list形式传入需要注意的是,x_vars和y_vars要同时指定
sns.pairplot(iris_data,vars=["萼片长","花瓣长"])
sns.pairplot(iris_data,x_vars=["萼片长","花瓣宽"],y_vars=["萼片宽","花瓣长"])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









