






Today the Phoenix blog is brought to you by my esteemed colleague and man of many hats, Mujtaba Chohan, who today is wearing his performance engineer hat.
The Skip Scan leverages SEEK_NEXT_USING_HINT of HBase Filter. It stores information about what set of keys/ranges of keys are being searched for in each column. It then takes a key (passed to it during filter evaluation), and figures out if it's in one of the combinations or range or not. If not, it figures out what the next highest key is that should be jumped to.
Input to the SkipScanFilter is a List<List<KeyRange>> where the top level list represents each column in the row key (i.e. each primary key part), and the inner list represents ORed together byte array boundaries.
Consider the following query:
List<List<KeyRange>> for SkipScanFilter for the above query would be:
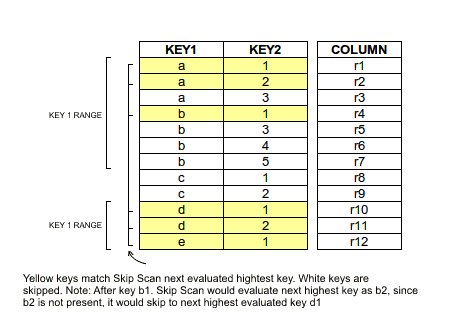
where [[a - b], [d - e]] is the range for KEY1 and [1, 2] keys for KEY2. Consider this running on the following data.
- Number of rows: 1 billion rows.
SKIP SCAN
Phoenix 1.2 uses a Skip Scan for intra-row scanning which allows for significant performance improvement over Multi Gets and Range Scan when rows are retrieved based on a given set of keys.The Skip Scan leverages SEEK_NEXT_USING_HINT of HBase Filter. It stores information about what set of keys/ranges of keys are being searched for in each column. It then takes a key (passed to it during filter evaluation), and figures out if it's in one of the combinations or range or not. If not, it figures out what the next highest key is that should be jumped to.
Input to the SkipScanFilter is a List<List<KeyRange>> where the top level list represents each column in the row key (i.e. each primary key part), and the inner list represents ORed together byte array boundaries.
Consider the following query:
SELECT * from T
WHERE ((KEY1 >='a' AND KEY1 <= 'b') OR (KEY1 > 'c' AND KEY1 <= 'e')) AND
KEY2 IN (1, 2)List<List<KeyRange>> for SkipScanFilter for the above query would be:
- [[[a - b], [d - e]], [1, 2]]
where [[a - b], [d - e]] is the range for KEY1 and [1, 2] keys for KEY2. Consider this running on the following data.
PERFORMANCE
For this performance comparison, we are using simulated data for a real use case outlined on the HBase user mailing list here.- Number of rows: 1 billion rows.
- Key consists of 50 million
OBJECTID
and 20
FIELDTYPE
. Each key has 10
ATTRIBID
and
VALUE
is random integer.
Phoenix Create Table DML
Query
IN-MEMORY TEST
Time taken to run the query when row are fetched from HBase Block Cache.

DISK READ TEST
Time taken to run the query when data is fetched from disk.

SERIAL TEST
To further illustrate the performance gain by using Skip Scan, we will compare Phoenix Serial Skip Scan performance ( phoenix.query.threadPoolSize= 1 ) against Serial Batched Get and Scan. Total number of rows are 8M (all rows fit in HBase block cache). The percentage of random keys passed in IN clause is varied on X axis.
Phoenix Create Table DML

CONCLUSION
Due to Skip Scan use of reseek, it is about 3 times faster than Batched Gets. Skip Scan can be 20x faster that scans over large data sets that cannot all fit into memory, it's 8x faster even if the data is in memory (when 1% of the rows are selected). This in addition to Phoenix fast performance due to use of server side coprocessor for aggregation, query parallelization which is yet another reason to use the latest Phoenix release!
CONFIGURATION
HBase 0.94.7
Hadoop 1.04
Region Servers (RS): 4 (6 Core 3GHz, 12GB with 8GB HBase set as HBase heap on each RS)
Total number of regions: 20
Note: All the keys passed in IN clause are present therefore Bloom Filters were not used.
CREATE TABLE T(
OBJECTID INTEGER NOT NULL, FIELDTYPE CHAR(2) NOT NULL,
CF.ATTRIBID INTEGER,CF.VAL INTEGER
CONSTRAINT PK PRIMARY KEY (OBJECTID,FIELDTYPE))
COMPRESSION='GZ', BLOCKSIZE='4096'Query
SELECT AVG(VAL) FROM T
WHERE OBJECTID IN (250K RANDOM OBJECTIDs) AND
FIELDTYPE = 'F1' AND
ATTRIBID='A1'
IN-MEMORY TEST
Time taken to run the query when row are fetched from HBase Block Cache.
| Test | Time |
| Phoenix | 1.7 sec |
| Batched Gets | 4.0 sec |
DISK READ TEST
Time taken to run the query when data is fetched from disk.
| Test | Time |
| Phoenix | 37 sec |
| Batched Gets | 82 sec |
| Range Scan | 12 mins |
| Hive over HBase | 20+ mins |
SERIAL TEST
To further illustrate the performance gain by using Skip Scan, we will compare Phoenix Serial Skip Scan performance ( phoenix.query.threadPoolSize= 1 ) against Serial Batched Get and Scan. Total number of rows are 8M (all rows fit in HBase block cache). The percentage of random keys passed in IN clause is varied on X axis.
Phoenix Create Table DML
CREATE TABLE T(
KEY VARCHAR NOT NULL AS KEY,
CF.A BIGINT,CF.B BIGINT, CF2.C BIGINT
Query
SELECT A FROM T
WHERE KEY IN (?,?,?...)
Comparison of Serial Skip Scan vs Serial Batched Gets, Scan by varying percentage of keys passed in IN clause
Due to Skip Scan use of reseek, it is about 3 times faster than Batched Gets. Skip Scan can be 20x faster that scans over large data sets that cannot all fit into memory, it's 8x faster even if the data is in memory (when 1% of the rows are selected). This in addition to Phoenix fast performance due to use of server side coprocessor for aggregation, query parallelization which is yet another reason to use the latest Phoenix release!
CONFIGURATION
HBase 0.94.7
Hadoop 1.04
Region Servers (RS): 4 (6 Core 3GHz, 12GB with 8GB HBase set as HBase heap on each RS)
Total number of regions: 20
Note: All the keys passed in IN clause are present therefore Bloom Filters were not used.
http://phoenix-hbase.blogspot.com/2013/05/demystifying-skip-scan-in-phoenix.html















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









