







蓝鲸智云体系介绍2(20210805)
蓝鲸智云体系介绍2(20210805)
CMDB
概念
配置管理数据库( Configuration Management Database,CMDB)是一个逻辑数据库,包含了配置项全生命周期的信息以及配置项之间的关系(包括物理关系、实时通信关系、非实时通信关系和依赖关系)。
蓝鲸配置平台是一款 面向应用的 CMDB,在 ITIL 体系里,CMDB 是构建其它流程的基石,而在蓝鲸智云体系里,配置平台就扮演着基石的角色,为应用提供了各种运维场景的配置数据服务。它是企业 IT 管理体系的核心,通过提供配置管理服务,以数据和模型相结合映射应用间的关系,保证数据的准确和一致性;并以整合的思路推进,最终面向应用消费,发挥配置服务的价值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dm2U4Fnc-1628164229749)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20210805094741145.png)]](https://img-blog.csdnimg.cn/5e4cbed0f9e54fb38ec5e802dff6a6c0.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RIWF8yMDE5,size_16,color_FFFFFF,t_70)
蓝鲸智云配置平台(CMDB功能)
业务
业务拓扑
业务/集群/模块/主机

(暂时)没用的机暂时不下架,先放到空闲机池(可用看到还有多少可用)
实现资源转移分配

服务/集群模板
服务模板-集群模板
通过模板新建集群,同步
浅色是手动创建的,深色是模板创建的
模板创建的业务无法删除下面的节点,只能整体删除
其他功能
服务分类
主机自动应用(自动更新机配置)
动态分组
自定义字段(个性化,只在对应业务内生效)
模型
模型管理
新建模型(表)能在“资源”看到
唯一校验(冲突):实例名冲突,加个不同ip
模型关联:为两个模型(源模型,目标模型)建立关系

各组件依赖及用途

CMDB的周边组件
MongoDB
MongoDB介绍
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组(如下图)。


MongoDB的复制集(高可用)
Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。

选举
复制集通过replSetInitiate命令(或mongo shell的rs.initiate())进行初始化,初始化后各个成员间开始发送心跳消息,并发起Priamry选举操作,获得『大多数』成员投票支持的节点,会成为Primary,其余节点成为Secondary。【大多数原则】
心跳
复制集成员间默认每2s会发送一次心跳信息,如果10s未收到某个节点的心跳,则认为该节点已宕机;如果宕机的节点为Primary,Secondary(前提是可被选为Primary)会发起新的Primary选举。
大多数:N/2+1(N为可投票的节点)——保证集群奇数,以选举出primary

复制
Primary与Secondary之间通过oplog来同步数据,Primary上的写操作完成后,会向特殊的 local.oplog.rs 特殊集合写入一条oplog,Secondary不断的从Primary取新的oplog并应用。【底层逻辑】
理解MySQL与MongoDB
| 数据库 | MongoDB | MySQL |
|---|---|---|
| 数据库模型 | 非关系型 | 关系型 |
| 存储方式 | 以类JSON的文档的格式存储 | 不同引擎有不同的存储方式 (表格式) |
| 查询语句 | MongoDB查询方式(类似JavaScript的函数) | SQL语句 |
| 数据处理方式 | 基于内存,将热数据存放在物理内存中,从而达到高速读写 (冷数据放硬盘) | 不同引擎有自己的特点 |
| 成熟度 | 新兴数据库,成熟度较低 | 成熟度高 |
| 广泛度 | NoSQL数据库中,比较完善且开源,使用人数在不断增长 | 开源数据库,市场份额不断增长 |
| 事务性 | 仅支持单文档事务操作,弱一致性 | 支持事务操作 |
| 占用空间 | 占用空间大 | 占用空间小 |
| join操作 | MongoDB没有join | MySQL支持join |
MongoDB更类似于Redis
需要定期清理MongoDB数据,但数据格式问题导致数据量并不大
Zookeeper
理解
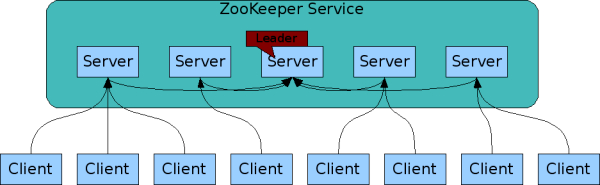
ZooKeeper 一个去中心化的服务, 用于维护配置信息, 命名服务(naming), 提供分布式同步和集群服务(group services)。ZK 被设计来存储协调数据: 状态信息、配置、位置信息等, 所以数据通常很小(byte 到 kilobyte 之间)。
命名空间
名字是一个用斜杆(/)分隔的路径元素序列, ZK 中每一个节点(znode)都用路径标识(类似Linux文件系统)

读写机制
Zookeeper是一个由多个server组成的集群
一个leader,多个follower
每个server保存一份数据副本
全局数据一致
分布式读写
更新请求转发,由leader实施
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M6w4HUXD-1628164229768)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20210805101914422.png)]](https://img-blog.csdnimg.cn/efe2fb42d0f64c279a3e6fada65bb89c.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RIWF8yMDE5,size_16,color_FFFFFF,t_70)


作业平台
概念
作业平台(Job)是一套基于蓝鲸智云管控平台 Agent 管道之上,提供基础操作的原子平台;
具备上万台并发处理能力,除了支持脚本执行、文件拉取 / 分发、定时任务等一系列基础运维场景以外,还支持通过流程调度能力将零碎的单个任务组装成一个自动化作业流程;
而每个任务都可做为一个原子节点,提供给上层或周边系统/平台使用,实现跨系统调度自动化。

各组件依赖及用途–JOB

| 术语 | 解释 |
|---|---|
| JOB | 蓝鲸作业平台简称 |
| job-config | 微服务: 配置中心 |
| job-gateway | 微服务: 业务网关 |
| job-manage | 微服务: 作业管理 |
| job-crontab | 微服务: 定时任务 |
| job-execute | 微服务: 作业执行 |
| job-logsvr | 微服务: 日志服务 |
| job-backup | 微服务: 作业迁移 |
| GSE Agent | 蓝鲸 GSE 团队研发的负责管理主机调度和与 TaskServer 进行交互的服务器主机代理程序 |
| GSE TaskServer | 蓝鲸 GSE 团队研发的用于负责管理分发调度作业和管理 GseAgent 通信的服务程序 |
| GSE APIServer | 蓝鲸 GSE 团队研发的 Gse Api 服务 |
| CMDB | 蓝鲸配置平台简称 |
| ESB | 蓝鲸 PAAS 企业总线,异构系统间的 API 调用需要通过 ESB |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5UEj9EMa-1628164229771)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20210805112545959.png)]
蓝鲸作业平台
快速执行
脚本执行
方式:手工录入/脚本引用
执行脚本(记得选服务器)

执行效果

grep process /proc/cpuinfo |wc -l 查看几核CPU
#分组方式查看CPU,job_start和job_success是上面定义好的函数
job_start
total=$(grep process /proc/cpuinfo |wc -l)
job_success $total

文件分发
限制条件:需要在目标IP地址服务器中安装Agent

业务管理
作业
新建作业模板
全局变量的变量类型选择“主机列表”

执行方案
模板不能直接执行,要在里面勾选创建执行方案
方案才是真正执行的

脚本
脚本放在同一地方去统一集中管理,按需执行
选择脚本上线后才能引用(脚本执行-脚本引用)

定时
类似于Linux的crontab


执行历史

账号
账号管理

底层原理:模拟root用户查看用户权限

消息通知
通知到什么执行人,通知方式

平台管理
公共脚本
大家都有的脚本
运营视图
数据统计图
IP白名单
已弃用功能,被全局业务(所有主机都放到一块(业务集),只有管理员才能看到)代替
机器加入白名单才能进行跨业务执行
全局设置
通知设置
设置高危语句规则:检测脚本中的高危语句
账号命名规则
平台信息
文件上传设置
服务状态
运维关注:版本号、状态
自检服务















 9387
9387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









