









1. 中文文本纠错任务,常见错误类型包括:
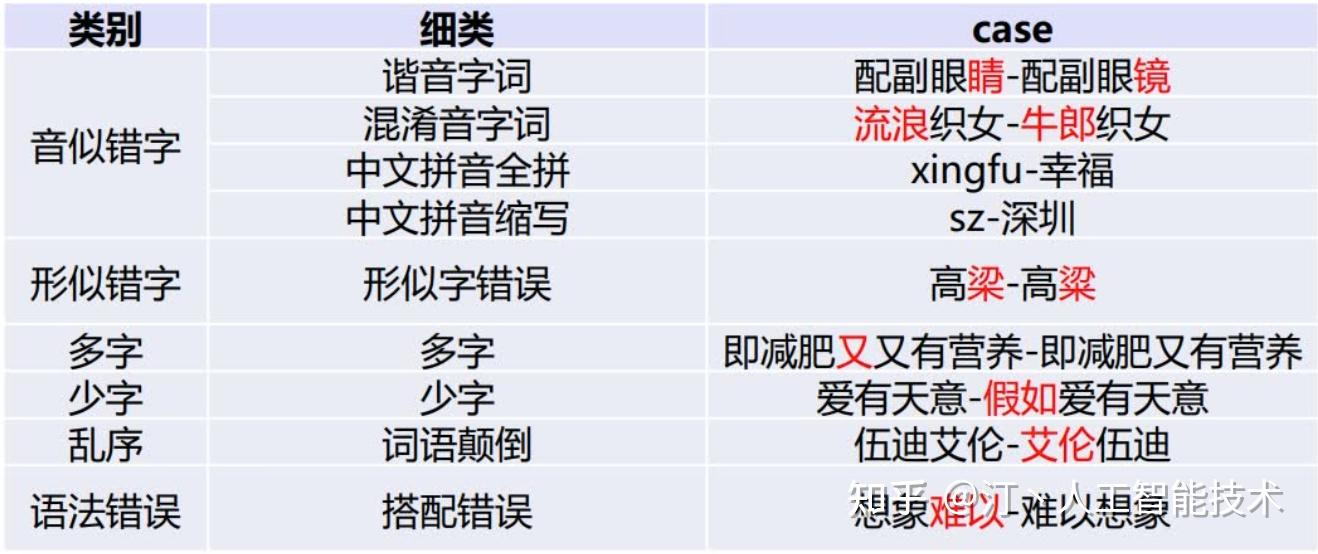
当然,针对不同业务场景,这些问题并不一定全部存在,比如拼音输入法、语音识别校对关注音似错误;五笔输入法、OCR校对关注形似错误, 搜索引擎/问答query纠错关注所有错误类型。
2. 解决方案
2.1. 规则的解决思路
依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
- 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
2.2. 深度模型的解决思路
- 端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,RNN Attn在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
- CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
- Seq2Seq模型是使用Encoder-Decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一;
- BERT/ELECTRA/ERNIE/MacBERT等预训练模型强大的语言表征能力,对NLP届带来翻天覆地的改变,海量的训练数据拟合的语言模型效果无与伦比,基于其MASK掩码的特征,可以简单改造预训练模型用于纠错,加上fine-tune,效果轻松达到最优。
3. 模型推荐
- Kenlm模型:本项目基于Kenlm统计语言模型工具训练了中文NGram语言模型,结合规则方法、混淆集可以纠正中文拼写错误,方法速度快,扩展性强,效果一般
- MacBERT模型【推荐】:本项目基于PyTorch实现了用于中文文本纠错的MacBERT4CSC模型,模型加入了错误检测和纠正网络,适配中文拼写纠错任务,效果好
- Seq2Seq模型:本项目基于PyTorch实现了用于中文文本纠错的Seq2Seq模型、ConvSeq2Seq模型,其中ConvSeq2Seq在NLPCC-2018的中文语法纠错比赛中,使用单模型并取得第三名,可以并行训练,模型收敛快,效果一般
- T5模型:本项目基于PyTorch实现了用于中文文本纠错的T5模型,使用Langboat/mengzi-t5-base的预训练模型fine-tune中文纠错数据集,模型改造的潜力较大,效果好
- BERT模型:本项目基于PyTorch实现了基于原生BERT的fill-mask能力进行纠正错字的方法,效果差
- ELECTRA模型:本项目基于PyTorch实现了基于原生ELECTRA的fill-mask能力进行纠正错字的方法,效果差
- ERNIE_CSC模型:本项目基于PaddlePaddle实现了用于中文文本纠错的ERNIE_CSC模型,模型在ERNIE-1.0上fine-tune,模型结构适配了中文拼写纠错任务,效果好
- DeepContext模型:本项目基于PyTorch实现了用于文本纠错的DeepContext模型,该模型结构参考Stanford University的NLC模型,2014英文纠错比赛得第一名,效果一般
- Transformer模型:本项目基于PyTorch的fairseq库调研了Transformer模型用于中文文本纠错,效果一般
- 思考
- 规则的方法,在词粒度的错误召回还不错,但错误纠正的准确率还有待提高,更多优质的纠错集及纠错词库会有提升,我更希望算法模型上有更大的突破。
- 现在的文本错误不再局限于字词粒度上的拼写错误,需要提高中文语法错误检测(CGED, Chinese Grammar Error Diagnosis)及纠正能力,列在TODO中,后续调研。
4. 模型评估
提供评估脚本https://github.com/shibing624/pycorrector/blob/master/examples/evaluate_models/evaluate_models.py:
- 使用sighan15评估集:SIGHAN2015的测试集https://github.com/shibing624/pycorrector/blob/master/examples/data/sighan_2015/test.tsv,已经转为简体中文。
- 评估标准:纠错准召率,采用严格句子粒度(Sentence Level)计算方式,把模型纠正之后的与正确句子完成相同的视为正确,否则为错。
- 评估结果 评估数据集:SIGHAN2015测试集
- GPU:Tesla V100,显存 32 GB
| Model Name | Model Hub Link | Backbone | GPU | Precision | Recall | F1 | QPS |
| Rule | - | kenlm | CPU | 0.6860 | 0.1529 | 0.2500 | 9 |
| BERT-CSC | - | bert-base-chinese | GPU | 0.8029 | 0.4052 | 0.5386 | 2 |
| BART-CSC | shibing624/bart4csc-base-chinese | fnlp/bart-base-chinese | GPU | 0.6984 | 0.6354 | 0.6654 | 58 |
| T5-CSC | - | byt5-small | GPU | 0.5220 | 0.3941 | 0.4491 | 111 |
| Mengzi-T5-CSC | shibing624/mengzi-t5-base-chinese-correction | mengzi-t5-base | GPU | 0.8321 | 0.6390 | 0.7229 | 214 |
| ConvSeq2Seq-CSC | - | ConvSeq2Seq | GPU | 0.2415 | 0.1436 | 0.1801 | 6 |
| ChatGLM-6B-CSC | shibing624/chatglm-6b-csc-zh-lora | ChatGLM | GPU | 0.5263 | 0.4052 | 0.4579 | 4 |
| MacBERT-CSC | shibing624/macbert4csc-base-chinese | hfl/chinese-macbert-base | GPU | 0.8254 | 0.7311 | 0.7754 | 224 |
- 结论
- 中文拼写纠错模型效果最好的是MacBert-CSC,模型名称是shibing624/macbert4csc-base-chinese,huggingface model:shibing624/macbert4csc-base-chinese
- 中文语法纠错模型效果最好的是BART-CSC,模型名称是shibing624/bart4csc-base-chinese,huggingface model:shibing624/bart4csc-base-chinese
- 最具潜力的模型是Mengzi-T5-CSC,模型名称是shibing624/mengzi-t5-base-chinese-correction,huggingface model:shibing624/mengzi-t5-base-chinese-correction,未改变模型结构,仅fine-tune中文纠错数据集,已经在
SIGHAN 2015取得接近SOTA的效果 - 基于ChatGLM-6B的纠错微调模型效果也不错,模型名称是shibing624/chatglm-6b-csc-zh-lora,huggingface model:shibing624/chatglm-6b-csc-zh-lora,大模型不仅能改错还能润色句子,但是模型太大,推理速度慢
5. 下载模型
5.1. 使用 transformers 库自动下载
如果你使用 transformers,模型会自动从 Hugging Face 下载到本地缓存目录(默认 ~/.cache/huggingface/transformers/)。
from transformers import AutoModelForMaskedLM, AutoTokenizer
# 模型名称
model_name = "shibing624/macbert4csc-base-chinese"
# 自动下载 tokenizer 和 model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForMaskedLM.from_pretrained(model_name)
print("模型下载完成,已加载!")
5.2. 手动下载Hugging Face上的模型
5.2.1. 下载模型文件(model.safetensors可以不用下载):
https://huggingface.co/shibing624/macbert4csc-base-chinese
5.2.2. 解压到本地目录:
mkdir -p /opt/zhanghao/shibing624/macbert4csc-base-chinese
mv ~/Downloads/* /opt/zhanghao/shibing624/macbert4csc-base-chinese6. 使用模型
使用的天津A100环境,GPU显存80G
模型大小400M
6.1. 主动加载模型
load_macbert4csc.py
# -*- coding: utf-8 -*-
from transformers import AutoModelForMaskedLM, AutoTokenizer
# 指定本地路径
local_model_path = "/opt/zhanghao/shibing624/macbert4csc-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForMaskedLM.from_pretrained(local_model_path)
print("已从本地路径加载模型!")
只需运行一次,后续会从本地缓存读取,不用重复下载。
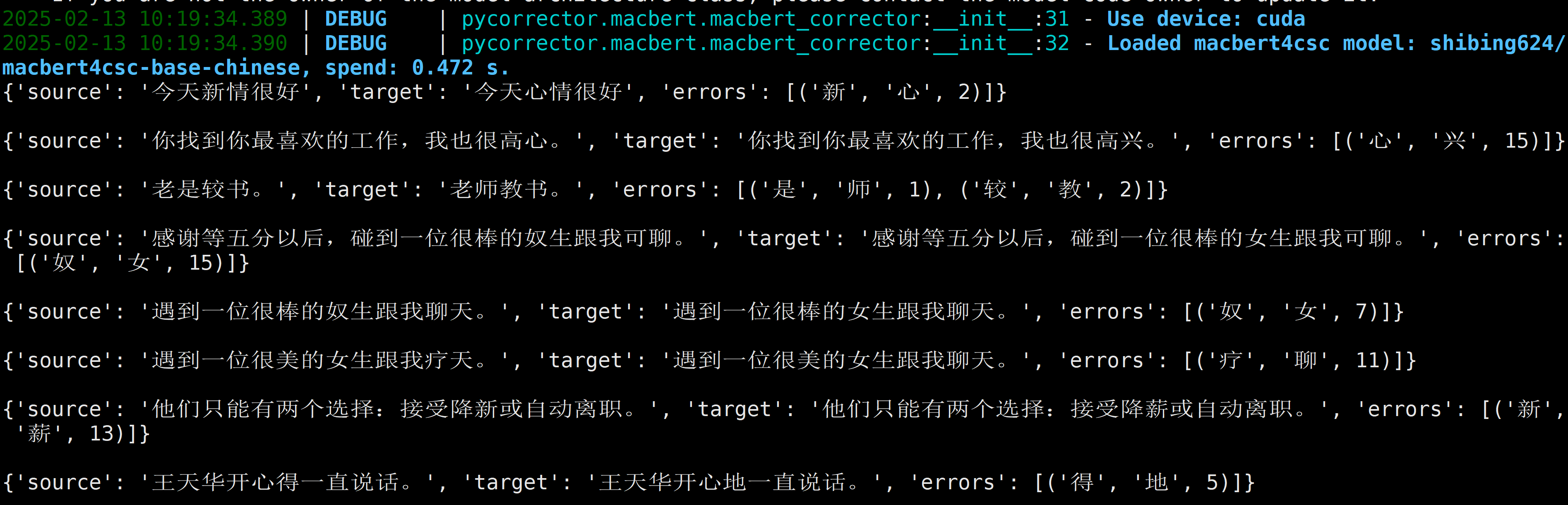
6.2. 批量纠错
# -*- coding: utf-8 -*-
from pycorrector import MacBertCorrector
def main():
m = MacBertCorrector()
error_sentences = [
'今天新情很好',
'你找到你最喜欢的工作,我也很高心。',
'老是较书。',
'感谢等五分以后,碰到一位很棒的奴生跟我可聊。',
'遇到一位很棒的奴生跟我聊天。',
'遇到一位很美的女生跟我疗天。',
'他们只能有两个选择:接受降新或自动离职。',
'王天华开心得一直说话。'
]
batch_res = m.correct_batch(error_sentences)
for i in batch_res:
print(i)
print()
执行结果如下
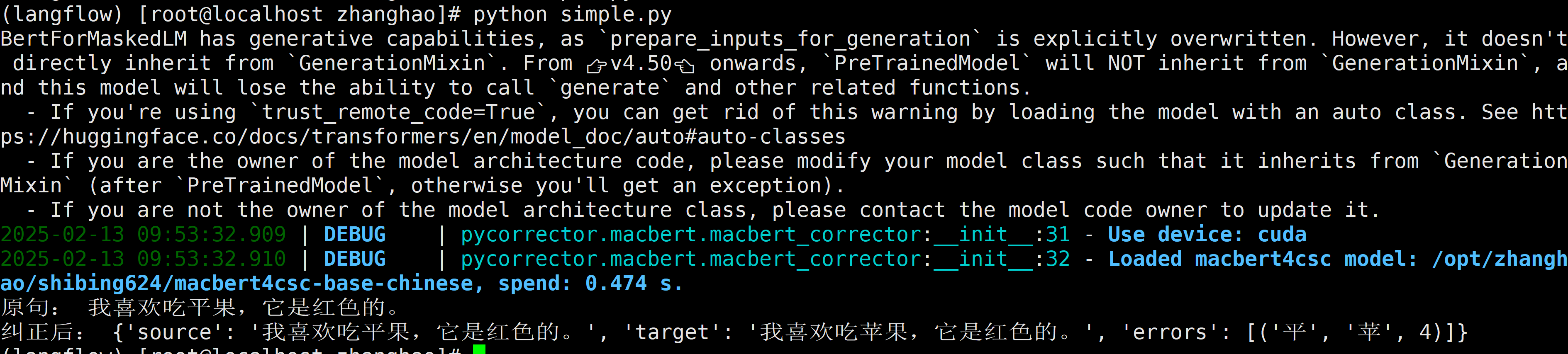
6.3. 单文本纠错
# -*- coding: utf-8 -*-
from pycorrector.macbert.macbert_corrector import MacBertCorrector
# 使用 MacBERT 纠错
model_path = "/opt/zhanghao/shibing624/macbert4csc-base-chinese"
corrector = MacBertCorrector(model_path)
# 测试句子
error_sentence = "我喜欢吃平果,它是红色的。"
corrected_sentence = corrector.correct(error_sentence)
print("原句:", error_sentence)
print("纠正后:", corrected_sentence)
执行结果如下:
6.4. 未发现需要纠正的错误,输出如下

7. 运行时资源
7.1. MacBERT 模型大小
MacBertCorrector 使用的 shibing624/macbert4csc-base-chinese 大致占用:
- 模型大小:约 400MB(
pytorch_model.bin) - Tokenizer 额外占用:约 30MB
- 总文件大小:~ 430MB
7.2. 运行时占用(显存 & 内存)
不同环境下的 运行时内存占用 估算如下:
| 运行环境 | 显存占用 | RAM(内存)占用 |
| CPU(无 GPU) | ❌(无显存) | 约 1GB - 2GB(下周测试,联系汪洋开一个纯CPU,16C32G) |
| GPU(8GB 以上显存) | 约 1GB - 2GB | 约 500MB - 1GB |
| GPU(16GB 以上显存) | 约 1GB | 约 300MB - 500MB |
7.2.1. 实测显存
nvidia-smi

7.2.2. 实测内存
在加载模型的一瞬间会

后续变为单核处理

0.4*125G=500MB
最高可以为0.8*125G=1G
7.3. 影响缓存大小的因素
batch_size:如果一次处理多个句子,显存/内存占用会增加。- 是否使用 GPU:
-
- GPU 运行(推荐):占用 1GB 显存 + 500MB RAM 左右。
- CPU 运行:占用 1GB - 2GB RAM,速度较慢。
- 文本长度:
-
- 句子越长,占用的缓存(显存/内存)越多。
- 默认最大长度
512,但普通中文句子一般 小于 50。(指的是汉字个数,不是token)
- 服务对外提供的并发能力:
-
- 单个并发处理多个文本,对内存和显存的消耗不是很大
- 多并发的情况下,需要适当的增加资源,至少8倍以上,可以应对15-20左右个并发
8. 存在的问题:
8.1. 对中英文混合,和纯英文的场景很不友好

9. 和大语言模型对比:
1.性能(下周)
2.效果(下周)
4.资源(下周)用在线不考虑资源
3.可以考虑在query改写的时候把纠错给做了。glm4 ds-r1(Q2)


















 829
829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









