







1. 闻达语言模型平台介绍
闻达模型具体介绍参阅官方github地址:
闻达github地址:https://github.com/wenda-LLM/wenda
2. 环境准备
基于chatGLM-6B、text2vec-large-chinese两种模型部署闻达平台,并实现本地知识库搭建。
2.1. 依赖环境准备
硬件:显存大于6g以上的显卡,chatGLM-6B在量化等级为INT4,最小可以在6g显存上运行
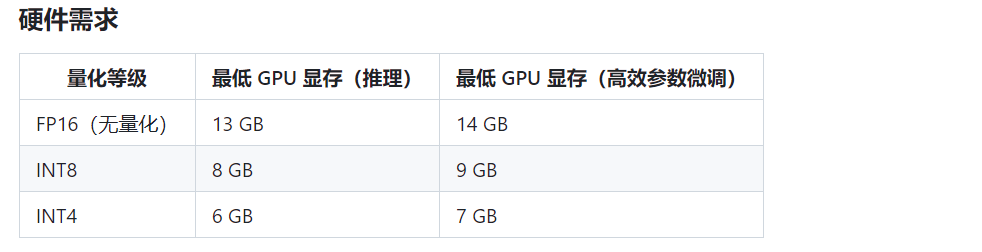
软件:
- 操作系统centos7.9
- python 3.9.16版本(安装文档,运维提供)
- pip包管理工具(安装文档,运维提供)
- git(安装文档,运维提供)
- 显卡驱动,cuda安装包会包含显卡驱动,也可以手动安装,版本需要到官网上查(下载 NVIDIA 官方驱动 | NVIDIA)
- cuda,11.8版本(CUDA Toolkit Archive | NVIDIA Developer)(安装文档,运维提供)
- 需要安装anaconda3
http://www.taodudu.cc/news/show-3892930.html?action=onClick
- pytorch,版本需要cuda配套(Previous PyTorch Versions,该页面是官方pythorch和cuda版本对应的下载地址,根据该页面安装)(安装文档,运维提供)
- 一定要下载这个版本不然不能用CUDA进行加速计算 (深坑)
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
2.2. 环境验证
以上环境安装好之后,需要检查显卡驱动是否正常以及cuda版本pytorch版本是否适配
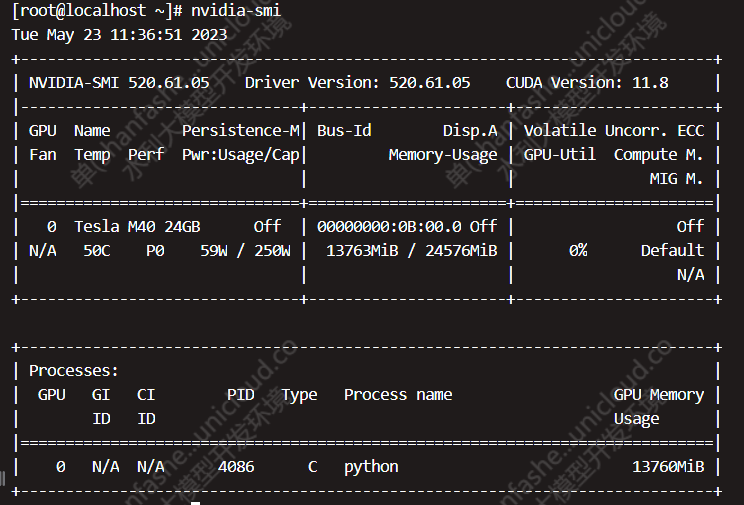
- 输入以下命令,验证显卡驱动:
nvidia-smi显示如下结果,显示CUDA版本为11.8,显卡驱动版本520.61.05
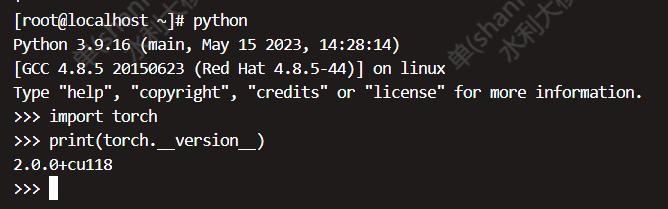
- 执行以下命令,查看Pytorch和cuda版本是否对应
python
import torch
print(torch.__version__)显示如下结果,显示torch版本为2.0.0,适配的cuda版本为11.8
3. chatGLM-6模型安装
闻达github上提供chatGLM-6模型的懒人包,经过验证未能成功运行,这边采用源码部署运行。
3.1. 源码下载
进入指定要安装的目录,运行如下命令
git clone https://github.com/THUDM/ChatGLM-6B.git3.2. 依赖安装
cd ChatGLM-6B
pip install -r requirements.txt这一步大概率会报错,ModuleNotFoundError,需要根据具体提示安装,提示缺少哪个module就用这个命令安装“pip install xxx”,后面module名字需要确认下,不一定是报错提示的那个。还有一些module,不是python自带的,就需要通过yum先安装,然后重新编译安装python,这块安装的时候就是遇到什么问题,解决什么问题,也没记录,所以没有详细的记录需要安装哪些module,可以找个新环境重新装下,把这个过程记录下。
3.3. 模型下载
去https://huggingface.co/THUDM/chatglm-6b/tree/main地址上下载模型,文件比较大,总共加起来大概有12个G,可以直接下载,网上也有一些其他的方法下载,需要将以下内容全部下载下来。
在ChatGLM-6B/web_demo.py文件里指定了模型存放路径
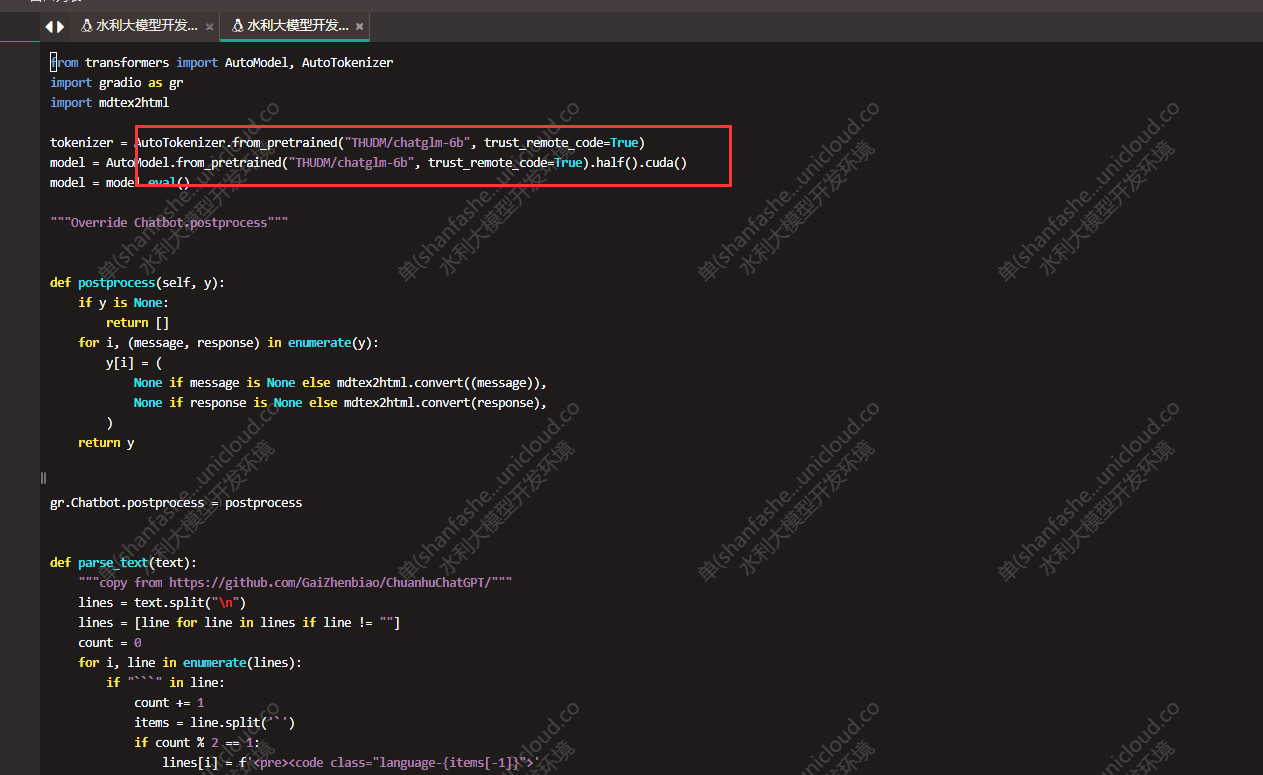
按相对路径,在ChatGLM-6B下新建THUDM/chatglm-6b路径,并将上面下载的文件全部拷贝进去。如果需要指定其他路径,可以修改web_demo.py中的路径代码。
3.4. 启动验证
修改web_demo.py文件,将最后一行share参数改为true.

执行以下命令启动,启动会比较慢。
python web_demo.py

访问日志中的public url就可以直接对话问答了。如果share参数为false,这里不会有public url,只能在127.0.0.1上访问。到这里如果public url能正常访问,并且进行对话,说明ChatGLM-6B部署完成,可以ctrl+c把模型停掉了。
4. wenda安装
4.1. 源码下载
进入指定要安装的目录,运行如下命令
git clone https://github.com/wenda-LLM/wenda.git4.2. 依赖安装
cd wenda
pip install -r requirements.txt这里同ChatGLM-6B一样,按需安装依赖。
4.3. 配置文件修改
cp example.config.yml config.yml
vim config.yml修改以下几个点:
device: cuda
librarys:
bing:
count: 5
#最大抽取数量
bingsite:
count: 5
#最大抽取数量
site: "www.12371.cn"
#搜索网站
fess:
count: 1
#最大抽取数量
fess_host: "127.0.0.1:8080"
#fess搜索引擎的部署地址
remote:
host: "http://127.0.0.1:17860/api/find"
#远程知识库地址地址
rtst:
count: 3
#最大抽取数量
size: 20
#分块大小"
overlap: 0
#分块重叠长度
model_path: "model/text2vec-large-chinese"
#向量模型存储路径
device: cuda
#embedding运行设备path: "/opt/wenda-source/ChatGLM-6B/THUDM/chatglm-6b"上面部署的chatglm-6b存放路径
llm_type: glm6b
#llm模型类型:glm6b、rwkv、llama、replitcode等,详见相关文件
llm_models:
rwkv:
path: "model/rwkv-4-raven-7b-v11.pth" #rwkv模型位置"
strategy: "cuda fp16i8"
# path: "model/rwkv_ggml_q8.bin" #rwkv模型位置"
# strategy: "Q8_0" #rwkvcpp:运行方式,设置strategy诸如"Q8_0->16"即可开启,代表运行Q8_0模型在16个cpu核心上
#rwkv模型参数"
historymode: state
#rwkv历史记录实现方式:state、string
glm6b:
#path: "model/chatglm-6b-int4"
path: "/opt/wenda-source/ChatGLM-6B/THUDM/chatglm-6b"
#glm模型位置"
strategy: "cuda fp16"
#cuda fp16 所有glm模型 要直接跑在gpu上都可以使用这个参数
#cuda fp16i8 fp16原生模型 要自行量化为int8跑在gpu上可以使用这个参数
#cuda fp16i4 fp16原生模型 要自行量化为int4跑在gpu上可以使用这个参数
#cpu fp32 所有glm模型 要直接跑在cpu上都可以使用这个参数
#cpu fp16i8 fp16原生模型 要自行量化为int8跑在cpu上可以使用这个参数
#cpu fp16i4 fp16原生模型要 自行量化为int4跑在cpu上可以使用这个参数"
#cuda:0 fp16 *14 -> cuda:1 fp16 多卡流水线并行,使用方法参考RWKV的strategy介绍。总层数28
lora: ""
#glm-lora模型位置4.4. text2vec-large-chinese模型下载
去下面地址下载该模型
https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main
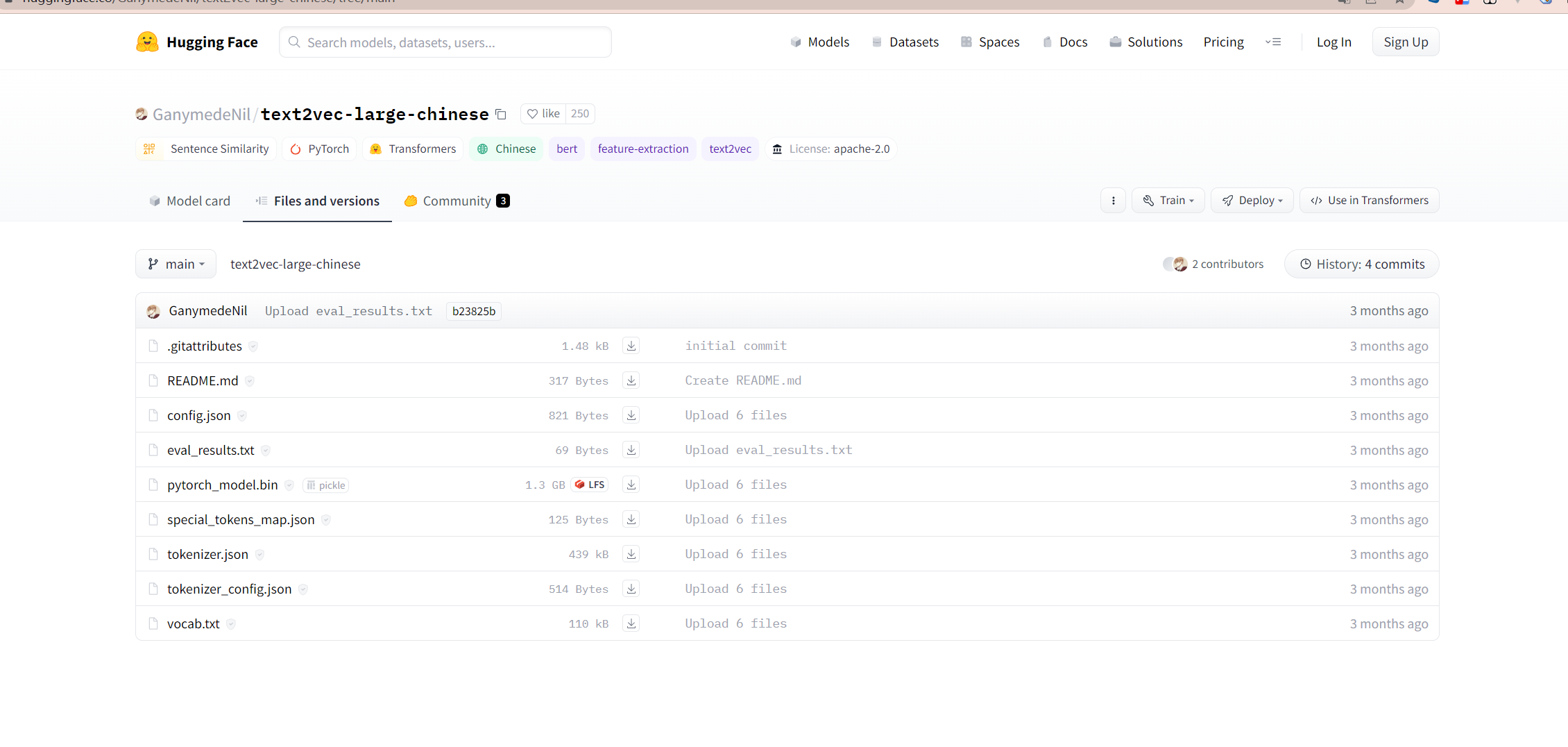
将上面文件全部下载下来,拷贝到wenda/model/text2vec-large-chinese文件下。
4.5. wenda启动
python wenda.py
# 后台启动 nohup python -u wenda.py > log.log 2>&1 &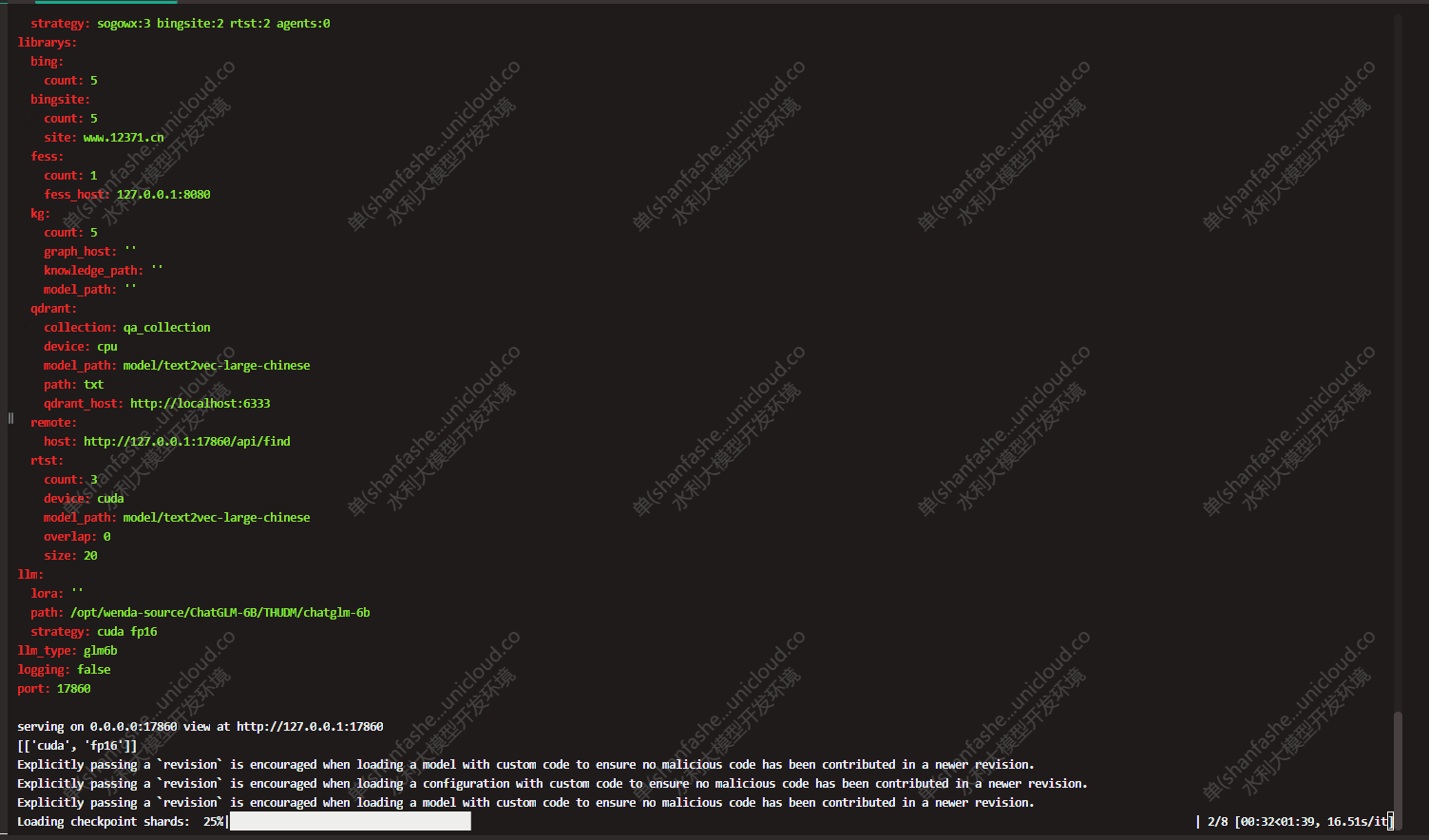
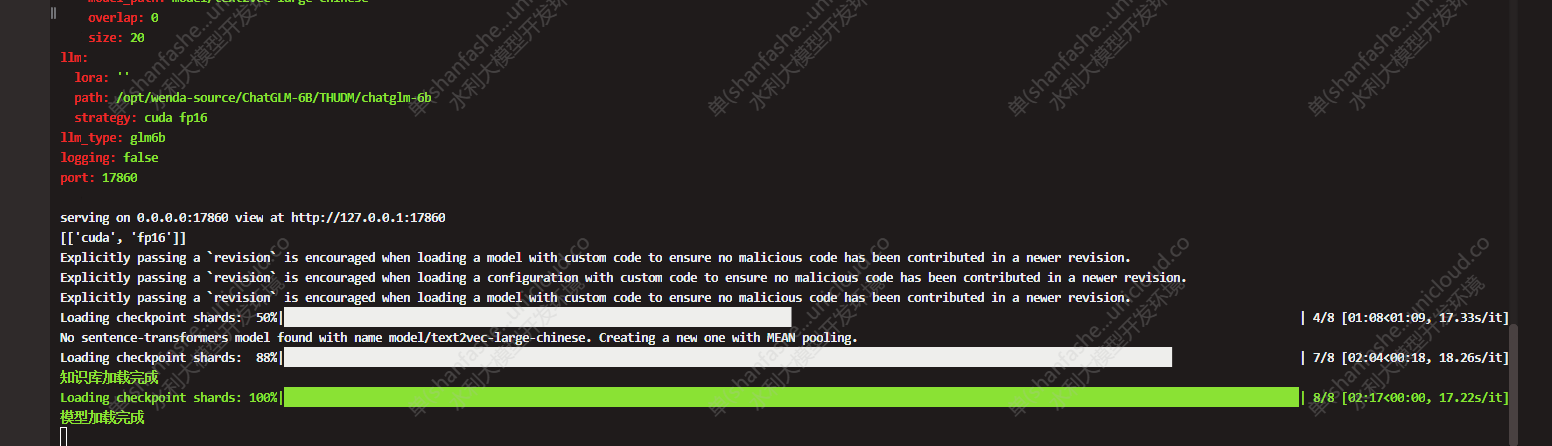
访问http://ip:17860/,打开web页面,进行对话问答。端口可以修改,在config.yml中
5. 本地知识库构建
- 新建文件夹wenda/txt,将需要被构建成知识库的txt文件和pdf文件拷贝放进去
- 执行命令:python plugins/gen_data_st.py
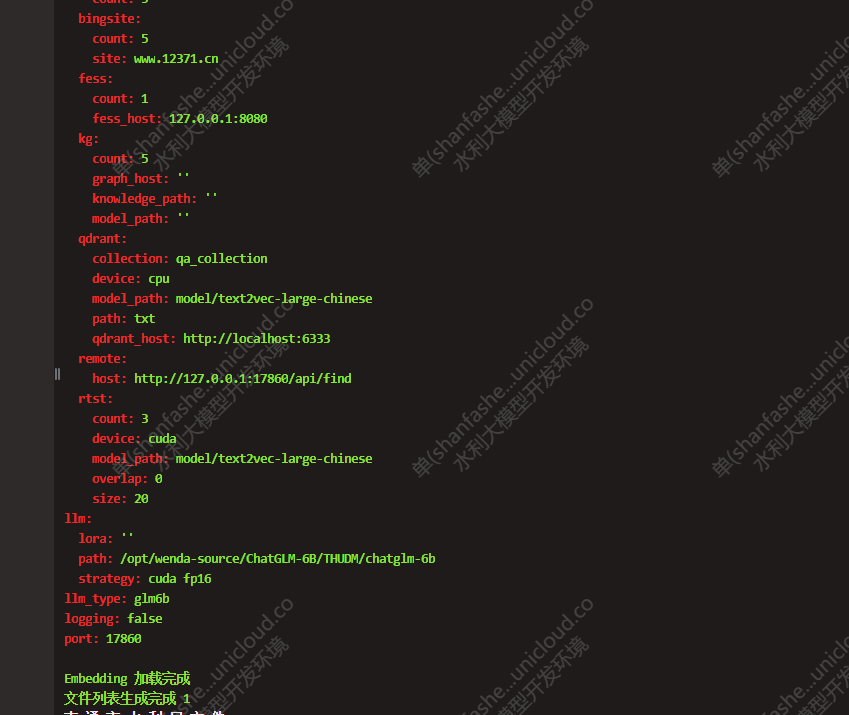

- 访问闻达控制台,开启本地知识库模式
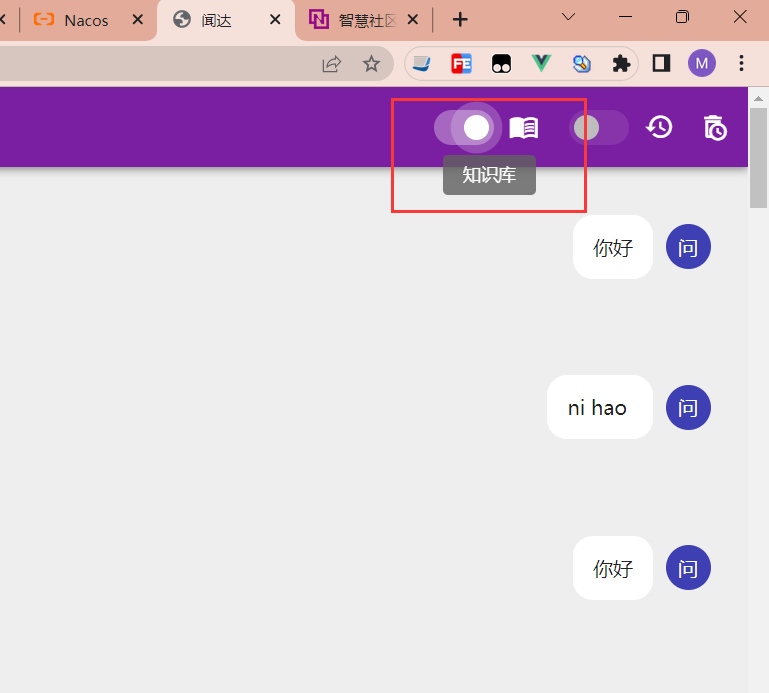
- 重新启动闻达,即可通过本地知识库中的知识做问答


















 1965
1965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









