







召回率
在医疗模型测评中,召回率(Recall)是一个关键指标,用于衡量模型对真实正例(实际患病的患者)的识别能力。它的核心目的是回答:“在所有实际患病的人中,模型正确检测出了多少?”
召回率的定义与计算
公式:
- 召回率=真正例(TP)/ [真正例(TP)+假反例(FN)]
-
- 真正例(TP):模型正确预测为患病的病例。
- 假反例(FN):模型错误预测为健康(漏诊)的病例。
- 举例:
假设测试数据集中有100名实际患病的患者:
-
- 模型检测出80名为阳性(TP),漏诊20名(FN)。
- 召回率 = 80 / (80 + 20) = 80%(即模型找出了80%的真实患者)。
为什么召回率在医疗中至关重要?
- 避免漏诊:
高召回率意味着更少的假阴性(FN),尤其在重症(如癌症、肺炎)场景中,漏诊的代价远高于误诊(假阳性)。
-
- 例如:新冠检测中,漏诊患者可能导致疫情扩散。
- 临床权衡:
召回率常与精确率(Precision)冲突(提高召回率可能增加误诊)。医疗场景通常优先保证召回率,再通过其他手段(如二次筛查)降低误诊。 - 法规要求:
部分医疗AI认证(如FDA)会设定召回率的最低阈值(如≥90%)。
召回率与其他指标的关系
| 指标 | 关注点 | 医疗意义 |
| 召回率(Recall) | 减少漏诊(FN) | “宁可错查,不可漏查” |
| 精确率(Precision) | 减少误诊(FP) | 避免过度医疗(如不必要的活检) |
| F1-score | 召回率与精确率的调和平均 | 综合平衡(适用于类别不平衡数据) |
如何优化召回率?
- 数据层面:
-
- 增加罕见病例样本(避免模型忽略少数类)。
- 使用过采样(如SMOTE)或损失函数加权(如Focal Loss)。
- 模型层面:
-
- 调整分类阈值(降低阈值可提高召回率,但会降低精确率)。
- 采用敏感度更高的结构(如注意力机制)。
- 后处理:
-
- 对低置信度病例触发人工复核(如放射科医生二次审阅)。
医疗场景中的典型召回率要求
- 筛查类任务(如肺癌CT):通常要求召回率 >85%
- 急诊分诊(如脑卒中识别):召回率需接近95%
- 慢性病预测(如糖尿病):可接受稍低召回率(如70%),但需结合其他指标。
若您的模型在特定疾病(如乳腺癌)上的召回率显著低于临床需求,需优先优化数据或模型结构。
精确率和准确率
在医疗模型的疾病分类任务中,准确率(Accuracy)和精确率(Precision)是两种不同的性能指标,它们从不同角度评估模型的预测能力,尤其在医疗场景中需要明确区分。以下是它们的核心区别和实际意义:
1. 定义与公式
| 指标 | 公式 | 解释 |
| 准确率(Accuracy) | (TP+TN)/(TP+TN+FP+FN) | 所有预测正确的样本(正+负)占总样本的比例。 |
| 精确率(Precision) | TP/(TP+FP) | 模型预测为正的样本中,真实为正的比例(避免误诊的关键)。 |
- TP(真正例):实际患病且被模型正确预测为患病。
- TN(真反例):实际健康且被模型正确预测为健康。
- FP(假正例):实际健康但被模型误预测为患病(误诊)。
- FN(假反例):实际患病但被模型误预测为健康(漏诊)。
2. 核心区别
(1)关注点不同
- 准确率:
-
- 衡量模型整体预测的正确性(无论正负类)。
- 短板:在数据不平衡时(如健康样本远多于患病样本),高准确率可能掩盖模型对少数类(患病)的识别能力差的问题。
例如:
若数据中健康人占95%,模型即使将所有样本预测为健康,准确率仍可达95%,但完全漏诊患者。
- 精确率:
-
- 衡量模型预测为正类的可靠性,即“模型说你有病时,真的患病的概率”。
- 医疗意义:减少误诊(FP),避免不必要的医疗干预(如过度活检)。
(2)医疗场景中的优先级
| 场景 | 更重要的指标 | 原因 |
| 疾病筛查(如癌症) | 召回率(Recall) | 优先减少漏诊(FN),即使代价是误诊(FP)需二次确认。 |
| 确诊辅助 | 精确率(Precision) | 避免误诊导致患者心理负担或过度治疗(如手术)。 |
| 健康体检 | 准确率(Accuracy) | 整体结果可靠性更重要(但需结合其他指标,防止不平衡数据误导)。 |
3. 实例对比
假设对1000人进行糖尿病预测,其中实际患者100人(10%患病):
- 模型预测结果:
-
- TP=80,FP=20,TN=850,FN=50
| 指标 | 计算 | 结果 | 解释 |
| 准确率 | (80+850)/1000 | 93% | 模型整体正确率高,但可能掩盖漏诊50人。 |
| 精确率 | 80/(80+20) | 80% | 模型预测的100名“患者”中,80人真实患病,20人误诊。 |
4. 如何选择?
- 需结合使用:
-
- 单独看准确率会忽略类别不平衡问题,需结合精确率、召回率、F1-score综合评估。
- 医疗决策建议:
-
- 高精确率:用于确诊阶段,确保“阳性预测”可靠。
- 高召回率:用于初筛阶段,避免漏诊。
- 准确率:需确认数据平衡性后再参考。
5. 可视化对比
Copy
[所有样本]
/ \
实际患病(TP+FN) 实际健康(TN+FP)
/ \ / \
TP(正确) FN(漏诊) TN(正确) FP(误诊)- 准确率 = (TP + TN) / 全体
- 精确率 = TP / (TP + FP)
总结
- 准确率是“整体正确率”,但可能被多数类主导;
- 精确率是“预测阳性的可信度”,直接关联误诊风险;
- 在医疗模型中,需根据临床需求权衡精确率与召回率(如通过调整分类阈值),并优先关注少数类(患病)的表现。
F1-score和AUC-ROC
在医疗模型的疾病分类任务中,F1-score和AUC-ROC是两种重要的综合性指标,用于解决类别不平衡问题和评估模型整体判别能力。以下是它们的详细解释和医疗场景中的应用:
1. F1-score:精确率与召回率的调和平衡
定义与公式
- 作用:综合衡量模型在精确率(Precision)和召回率(Recall)之间的平衡性,尤其适用于类别分布不平衡的数据(如罕见病检测)。
公式:
- F1-score=2×Precision×Recall/(Precision+Recall)
-
- 其中:
-
-
- Precision = TP/(TP+FP)(减少误诊)
- Recall = TP/(TP+FN)(减少漏诊)
-
医疗意义
- 平衡误诊与漏诊:
-
- 高F1-score意味着模型在减少误诊(FP)和漏诊(FN)之间取得了较好的权衡。
- 例如:在癌症筛查中,既不能漏掉真实患者(高Recall),也不能让健康人过度恐慌(高Precision)。
- 适用场景:
-
- 当精确率和召回率同等重要时使用(如传染病初筛、慢性病风险评估)。
- 不适用于极端需求场景(如新冠检测需优先Recall)。
示例
假设模型预测结果:
- Precision=80%,Recall=90%
- F1-score=2×0.8×0.9/(0.8+0.9)=84.7%
2. AUC-ROC:模型整体判别能力的评估
定义与原理
- 作用:评估模型区分正负类的能力(如患病vs健康),不受分类阈值影响。
- ROC曲线:横轴是假正率(FPR=FP/(FP+TN)),纵轴是真正率(TPR=Recall)。
- AUC值:ROC曲线下的面积,范围0.5(随机猜测)~1(完美分类)。
医疗意义
- 全面性评估:
-
- AUC-ROC反映模型在所有可能分类阈值下的表现,适用于不确定最优阈值的场景(如不同医院对风险容忍度不同)。
- 抗不平衡性:
-
- 对类别分布不敏感,即使健康样本远多于患者,AUC仍能可靠评估模型能力。
- 临床决策支持:
-
- AUC>0.9:优秀(如影像诊断模型);
- AUC 0.7~0.9:可接受(如风险预测模型)。
示例
- 模型A的AUC=0.92,模型B的AUC=0.85 → 模型A的区分能力更强。
- ROC曲线解读:
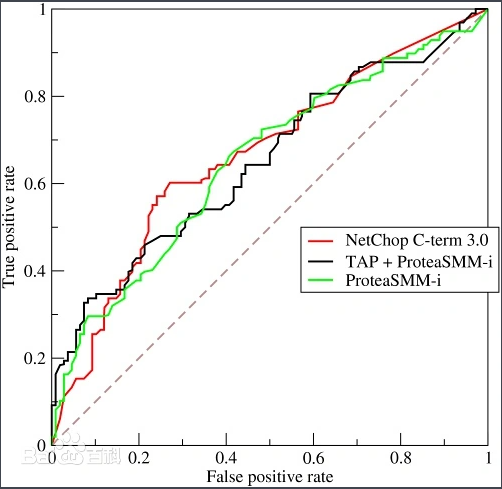
曲线越靠近左上角,模型性能越好。
3. F1-score与AUC-ROC的关键区别
| 特性 | F1-score | AUC-ROC |
| 关注点 | 单一阈值下的精确率-召回率平衡 | 所有阈值下的整体区分能力 |
| 数据不平衡影响 | 受较大影响(需调整阈值) | 相对鲁棒 |
| 适用阶段 | 模型调优(固定阈值后) | 模型选择(比较不同模型) |
| 医疗典型用途 | 初筛模型验收 | 科研论文或横向对比 |
4. 医疗场景中的选择建议
- 优先使用F1-score:
-
- 当临床已确定分类阈值(如“概率>0.5判为患病”),且需平衡误诊和漏诊时。
- 案例:糖尿病视网膜病变分级模型。
- 优先使用AUC-ROC:
-
- 当需要全局评估模型,或阈值未定时(如不同科室对误诊容忍度不同)。
- 案例:癌症风险预测模型的学术研究。
- 联合使用:
在模型报告中同时给出F1和AUC,例如:
-
- markd
- AUC-ROC = 0.91(区分能力优秀)
- F1-score = 0.83(在阈值0.4下平衡性良好)5. 如何优化这两个指标?
- 提升F1-score:
-
- 调整分类阈值(通过ROC曲线找到Precision和Recall的平衡点)。
- 使用代价敏感学习(对FN/FP赋予不同惩罚权重)。
- 提升AUC-ROC:
-
- 改进特征工程(如加入更多医学先验知识)。
- 尝试集成模型(如XGBoost+神经网络)。
总结
- F1-score是“临床实用性”指标,直接关联误诊和漏诊的权衡;
- AUC-ROC是“学术性”指标,反映模型本质区分能力;
- 在医疗AI测评中,二者需结合使用,并明确说明测试数据的分布(如患病率)。


















 2177
2177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









