







1. 概述与核心价值
在现代高并发、大流量的分布式系统架构中,数据库往往成为性能的主要瓶颈。分布式缓存通过将高频访问的数据存储在内存中,为应用程序提供高速数据读写能力,是提升系统性能、扩展性和可用性的关键技术。
核心价值:
- 性能提升:内存读写速度远高于磁盘(如数据库),可显著降低数据访问延迟。
- 降低后端负载:缓存能够拦截大量对数据库的重复查询,有效防止数据库被击垮。
- 系统扩展性:通过横向扩展缓存集群,可以轻松应对不断增长的数据量和访问压力。
- 高可用性:优秀的分布式缓存方案提供故障转移(Failover)和数据冗余机制,保证服务连续性。
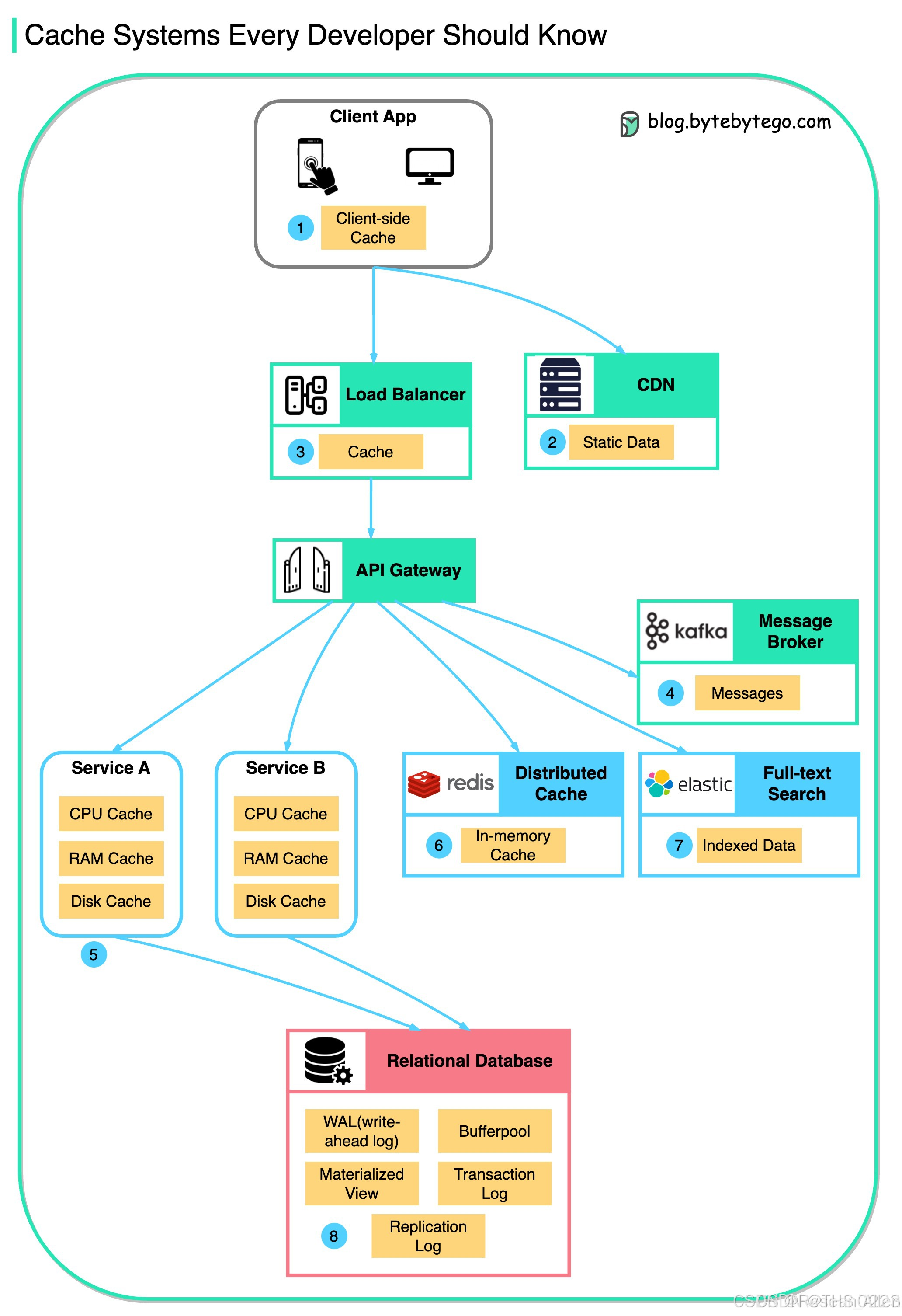
2. 主流技术选型 (Java生态)
Java开发者有多种成熟的分布式缓存解决方案可供选择:
-
Redis
- 描述:最流行的内存键值存储数据库,支持丰富的数据结构(String, Hash, List, Set, SortedSet等),功能极其丰富。
- 特点:单线程模型避免并发冲突、高性能、支持持久化、提供主从复制和哨兵(Sentinel)/集群(Cluster)模式实现高可用。
- Java客户端:Jedis, Lettuce (Spring Boot默认), Redisson (提供分布式对象和服务)。
-
Memcached
- 描述:一个高性能、分布式的纯内存缓存系统,设计简单,专注于简单的键值缓存。
- 特点:多线程、性能极高、不支持持久化和复杂数据结构。
- 适用场景:适合需要缓存简单键值对、追求极致性能的场景。
-
Hazelcast / Ignite
- 描述:内存数据网格(In-Memory Data Grid),而不仅仅是缓存。它们以JAR包形式嵌入应用,节点自动发现组成集群。
- 特点:数据分片存储在集群所有节点中,提供分布式数据结构(Map, Queue, Lock等)、计算和事务支持。与Java应用集成度极高。
-
Ehcache (with Terracotta)
- 描述:成熟的Java进程内缓存库,通过Terracotta技术可以组成分布式集群。
- 特点:从进程内缓存扩展到分布式缓存的优雅方案,对于已有Ehcache的项目过渡平滑。

选型建议:
- 绝大多数场景下,Redis是功能、性能和社区支持最均衡的选择,是事实上的标准。
- 如果需要与Java应用深度集成,使用分布式集合和计算,可考虑Hazelcast/Ignite。
- 如果仅需缓存简单的键值对且追求极致简单和性能,Memcached仍是一个选项。
3. 核心分布式缓存策略
3.1 数据分片 (Sharding/Partitioning)
为了突破单机内存限制,必须将数据分散到集群的多个节点上。
- 策略:
- 客户端分片:客户端使用一致性哈希等算法,直接计算key对应的节点并进行通信。Jedis等客户端支持。
- 代理分片:使用Twemproxy, Codis等代理中间件,应用连接代理,由代理负责将请求路由到正确的节点。
- 集群模式分片:如Redis Cluster,内置分片功能,客户端可查询集群获取路由信息(Smart Client),直接与目标节点通信,效率更高。
3.2 数据一致性策略
缓存与底层数据库(如MySQL)的数据同步是关键挑战。
- 缓存读写模式:
- Cache-Aside (Lazy Loading):最常用策略。
- 读:先读缓存,命中则返回;未命中则读数据库,写入缓存后返回。
- 写:直接更新数据库,然后使缓存中对应数据失效(非删除,是标记为不可用,下次读时触发加载)。
- 优点:实现简单,容错性好。
- 缺点:可能存在短暂的数据不一致(在“更新DB”后、“失效缓存”前有读请求,会加载到旧数据)。
- Write-Through:
- 写:应用同时更新缓存和数据库(通常是一个原子性操作或通过事务保证)。
- 读:直接读缓存。
- 优点:保证强一致性。
- 缺点:写延迟较高,对缓存和数据库的写操作是同步的。
- Write-Behind (Write-Back):
- 写:应用只更新缓存,然后异步、批量地更新数据库。
- 优点:写性能极高。
- 缺点:有数据丢失风险(缓存节点宕机导致数据未落库),实现复杂。
- Cache-Aside (Lazy Loading):最常用策略。
3.3 高可用与故障转移策略
- 主从复制 (Replication):每个主节点(Master)配备一个或多个从节点(Slave)。主节点处理写操作,并异步将数据同步到从节点。从节点处理读操作,分担负载。
- 哨兵模式 (Sentinel):一套独立的监控系统,用于管理Redis主从集群。它监控节点健康状态,并在主节点宕机时,自动将一个从节点提升为新的主节点,并通知客户端新的地址。
- 集群模式 (Cluster):Redis官方解决方案,内置了数据分片、主从复制和故障转移能力,无需额外哨兵系统。当某个主节点故障时,其从节点会自动晋升为主节点。
3.4 缓存失效与更新策略
- TTL (Time-To-Live):为每个缓存键设置过期时间,是避免数据陈旧的最简单有效的方法。
- 定期刷新:对于不过期或长TTL的缓存,通过后台任务定期重新加载数据。
- 消息通知:利用数据库的Binlog或变更数据捕获(CDC)工具(如Canal, Debezium),在数据库变更时发布消息,缓存服务消费消息后主动更新或失效缓存。这是保证最终一致性的高级方案。
4. Java实现最佳实践与代码片段 (以Spring Boot + Redis为例)
-
依赖注入 (使用Spring Boot Starter Data Redis)
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> -
配置连接 (
application.yml)spring: redis: host: your-redis-cluster-endpoint port: 6379 password: your-password lettuce: pool: max-active: 8 max-idle: 8 min-idle: 0 -
使用
@Cacheable注解实现Cache-Aside模式@Service public class UserService { @Autowired private UserRepository userRepository; // JPA or MyBatis Mapper @Cacheable(value = "user", key = "#id") // 缓存名为user,key为id public User getUserById(Long id) { // 这个方法只有在缓存未命中时才会被执行 // 执行数据库查询 return userRepository.findById(id).orElseThrow(...); } @CacheEvict(value = "user", key = "#user.id") // 更新或删除数据库后,使缓存失效 public User updateUser(User user) { User updatedUser = userRepository.save(user); return updatedUser; } // 也可以使用 @CachePut 强制更新缓存,但通常CacheEvict更安全 } -
自定义缓存配置(如使用Jackson序列化)
@Configuration @EnableCaching public class RedisConfig { @Bean public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) { // 使用Jackson2JsonRedisSerializer来序列化值 Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<>(Object.class); ObjectMapper mapper = new ObjectMapper(); mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); mapper.activateDefaultTyping(mapper.getPolymorphicTypeValidator(), ObjectMapper.DefaultTyping.NON_FINAL); serializer.setObjectMapper(mapper); RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig() .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(serializer)) .entryTtl(Duration.ofMinutes(30)); // 设置默认TTL return RedisCacheManager.builder(connectionFactory) .cacheDefaults(config) .build(); } }
5. 常见问题与应对策略
-
缓存穿透:大量请求查询一个根本不存在的数据(如不存在的userid),请求直达数据库。
- 对策:
- 缓存空值:对查询结果为null的key也进行缓存,并设置一个较短的TTL。
- 布隆过滤器 (Bloom Filter):在缓存之前加一层布隆过滤器,快速判断key是否存在,如果不存在直接返回,避免对缓存和数据库的查询。
- 对策:
-
缓存击穿:某个热点key过期的瞬间,大量并发请求这个key,全部直达数据库。
- 对策:
- 永不过期:对极热点数据设置逻辑过期时间,而非物理过期。后台任务异步更新。
- 互斥锁 (Mutex Lock):第一个请求发现缓存失效时,获取一个分布式锁,然后查询数据库并重建缓存,期间其他请求等待或返回默认值。
- 对策:
-
缓存雪崩:大量key在同一时间点(或时间段)过期,导致所有请求都直达数据库。
- 对策:
- 随机化TTL:为缓存key的TTL设置一个随机值(如基础时间 + 随机偏移),避免集体失效。
- 构建高可用缓存集群:如使用Redis Cluster,防止单个节点宕机导致所有缓存丢失。
- 服务降级与熔断:使用Hystrix、Sentinel等组件,当数据库压力过大时,对请求进行降级或直接返回默认值,保护后端系统。
- 对策:
6. 总结与展望
分布式缓存是构建高性能Java应用的基石。选择Redis等成熟方案,并结合Cache-Aside、合理分片、高可用架构以及针对穿透/击穿/雪崩的防御性编码,可以构建出健壮、高效的缓存层。
未来趋势:
- Serverless缓存:云服务商提供完全托管的缓存服务(如AWS ElastiCache,Azure Cache for Redis),无需管理基础设施,开箱即用。
- 持久化内存(PMEM):英特尔傲腾等非易失性内存技术可能改变缓存和数据库的界限,提供更高性能和数据持久性。
- 多级缓存架构:结合本地缓存(Caffeine, Guava Cache)与分布式缓存,形成多级缓存,进一步降低延迟和网络开销。
通过深入理解并正确应用这些策略和技术,开发者和架构师能够显著提升其分布式系统的整体性能和韧性。


















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









