







Lucene简介
Lucene是什么
- Lucene是一个开源的全文检索引擎工具包,提供了完整的查询引擎合索引引擎,部分语种文本分析引擎
- Lucene并不是一个完整的全文检索引擎,仅提供了全文检索引擎架构,但仍可以作为一个工具包结合各类插件为项目提供部分高性能的全文检索功能
- ES、Solr的底层
Lucene使用场景
适用于需要数据索引量不大的场景,档索引量过大,需要ES或Solr
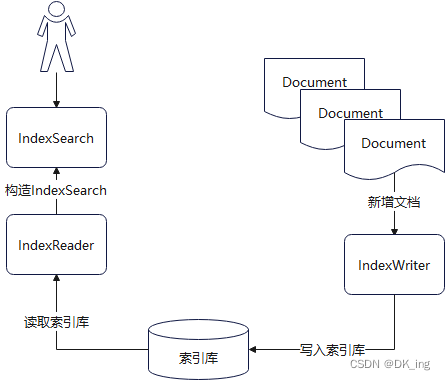
Lucene基础工作流程
索引的生成分为两个部分:
- 创建阶段:
- 添加文档阶段,通过IndexWriter调用addDocument方法生成正向索引文件;
- 文档添加后,通过flush或者merge操作生成倒排索引文件。
- 搜索阶段:
- 客户端通过查询语句向Lucene发送查询请求;
- 通过IndexSearch下的IndexReader读取索引库内容,获取文档索引;
- 得到搜索结果后,基于搜索算法堆结果进行排序后返回。
Lucene索引构成
正向索引
Lucene的基础层次结构由索引、段、文档、域、词五个部分组成。正向索引的生成即为基于Lucene的基础层次结构一级一级处理文档并分解成域存储次的过程。
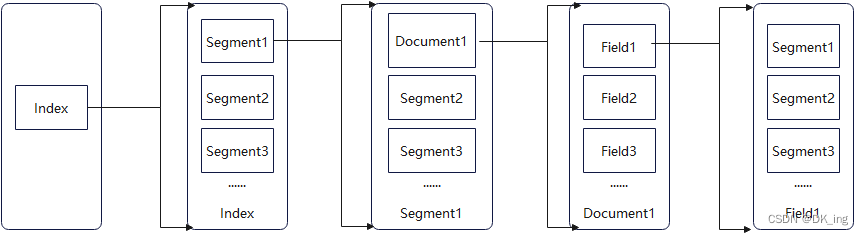
- 索引: Lucene索引库包含了搜索文本的所有内容,可以通过文件或文件流的方式存储在不同的数据库或文件目录下。
- 段: 一个索引中包含多个段,段与段之间较多会增加较大的I/O开销,减慢检索速度,因此写入是会通过段合并策略对不同的段进行合并。
- 文档: Lucene会将文档写入段中,一个段中包含多个文档。
- 域: 一篇文档会包含多种不同的字段,不同的字段保存在不同的域中。
- 词: Lucene会通过分词器将域中的字符串通过词法分析合语言处理后拆分成词,Lucene通过这些关键词进行全文检索。
倒排索引
Lucene全文索引的核心是基于倒排索引实现的快速索引机制。
倒排索引原理如下图。基于分词器将文本内容进行分词后,记录每个词出现在哪篇文章中,从而通过用户输入的索引词查询出包含该词的文章。
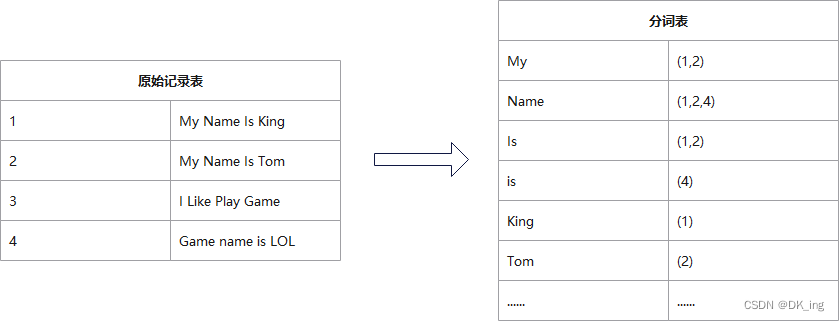
可以看到,随着文档数量增多,篇幅较长时,索引词可能会占用大量的存储空间,加载到内存后内存损耗过大。
从Lucene4开始,Lucene采用了FST来减少索引词带来的空间消耗。
字典数据结构-FST(Finite State Transducers)
有限状态转换器。主要特点如下:
- 查找词的时间复杂度为O(len(str));
- 通过将前缀和后缀分开存储的方式,减少了存放词所需的空间;
- 加载时仅将前缀放入内存索引,后缀词咋i磁盘中进行存放,减少了内存索引使用空间的消耗;
- FST结构在对PrefixQuery、FuzzyQuery、RegexpQuery等查询条件查询时,查询效率高。
FST原理
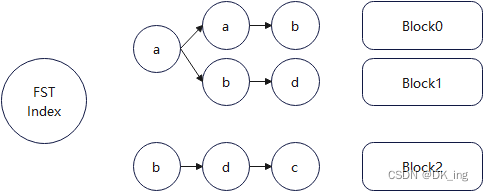
性能:
FST压缩率一般在3倍~20倍之间,相对于TreeMap/HashMap的膨胀3倍,内存节省就有9倍到60倍!
倒排索引相关文件
包含.tip、.tim和.doc这三个文件,其中:
- tip: 用于保存倒排索引Term的前缀,来快速定位.tim文件中属于这个Field的Term的位置,即上图中的aab、abd、bdc。
- tim: 保存了不同前缀对应的相应的Term及相应的倒排表信息,倒排表通过跳表实现快速查找,通过跳表能够跳过一些元素的方式对多条件查询交集、并集、差集之类的集合运算也提高了性能。
- doc: 包含了文档号及词频信息,根据倒排表中的内容返回该文件中保存的文本信息。
索引查询及文档搜索过程
Lucene利用倒排索引定位需要查询的文档ID,通过文档ID搜索出文件后,再利用词权重等信息对文档排序而后返回。
- 内存加载.tip文件,根据FST匹配到后缀词块在.tim文件中的位置;
- 根据查询到的后缀词块位置查询到后缀及倒排表的相关信息;
- 根据.tim中查询到的倒排表信息从.doc文件中定位出文档ID以及词频信息,完成搜索;
- 文档定位完成后Lucene将去.fdx文件目录索引及.fdt中根据正向索引查找出目标文件。
Lucene存储的文件类型及含义
| 文件名 | 扩展名 | 描述 |
|---|---|---|
| Segments File | segments.gen,segments_N | segment文件,存储commit点的信息 |
| Lock File | write.lock | 写锁文件,防止多个IndexWriter写入同一个文件 |
| Segment Info | .si | segment信息文件,存储segment的元数据,指明段包含哪些文件 |
| Compound File | .cfs,.cfe | 如果启用Compound功能,会压缩索引到2个文件内 |
| Fields | .fnm | 域文件,存储field信息 |
| Field Index | .fdt | 域指针文件,包含到域文件的指针 |
| Term Dictionary | .tim | Term词典,存储项信息 |
| Term Index | .tip | Term索引,存储到Term词典的索引 |
| Frequencies | .doc | 频率,包含每个Term以及频率信息 |
| Positions | .pos | 位置,存储一个Term在索引中的位置信息 |
| Payloads | .pay | 载荷,存储额外的预先设置好的元信息如字符偏移或者用户载荷 |
| Norms | .nvd,.nvm | 调整因子,.nvm保存加权因子元数据;.nvd存储加权数据 |
| Per-Document Values | .dvd,.dvm | .dvm存文档正排元数据;.dvd存文档正排数据 |
| Term Vector Index | .tvx | 文档向量索引,存储在文档数据文件的偏移量,指向.tvd的offset |
| Term Vector Documents | .tvd | 包含每个文档的term vector信息 |
| Term Vector Fields | .tvf | 包含域级别的项向量信息 |
| Deleted Documents | .del | 关于文档被删除的信息 |















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









