






DStream的转换
与RDD类似,转换允许修改来自输入DStream的数据。DStream支持普通Spark RDD上可用的许多转换。一些常见的如下。
| 转换 | 含义 |
| map(func) | 通过将源DStream的每个元素传递给函数func来返回一个新的DStream |
| flatMap(func) | 与map类似,但每个输入项可以映射到0个或更多输出项。 |
| filter(func) | 通过仅选择func返回true的源DStream的记录来返回新的DStream。 |
| repartition(numPartitions) | 通过创建更多或更少的分区来更改此DStream中的并行度级别。 |
| union(otherStream) | 返回一个新的DStream,它包含源DStream和otherDStream中元素的并集。 |
| count() | 通过计算源DStream的每个RDD中的元素数量,返回单元素RDD的新DStream。 |
| reduce(func) | 通过使用函数func(它接受两个参数并返回一个)聚合源DStream的每个RDD中的元素,返回单元素RDD的新DStream。该函数应该是关联和可交换的,以便可以并行计算。 |
| countByValue() | 当在类型为K的元素的DStream上调用时,返回(K,Long)对的新DStream,其中每个键的值是其在源DStream的每个RDD中的频率。 |
| redduceByKey(func,[numTasks]) | 当在(K,V)对的DStream上调用时,返回(K,V)对的新DStream,其中使用给定的reduce函数聚合每个键的值。注意:默认情况下,这使用Spark的默认并行任务数(本地模式为2,在集群模式下,数量由config属性spark.default.parallelism确定)进行分组。我们可以传递可选numTasks参数来设置不同数量的任务。 |
| join(otherStream,[numTasks]) | 当在(K,V)和(K,W)对的两个DStream上调用时,返回(K,(V,W))对的新DStream与每个键的所有元素对。 |
| cogroup(otherStream,[numTasks]) | 当在(K,V)和(K,W)对的DStream上调用时,返回(K,Seq[V],Seq[W])元组的新DStream。 |
| transform(func) | 通过将RDD-to-RDD函数应用于源DStream的每个RDD来返回新的DStream。这可以用于在DStream上执行任意RDD操作。 |
| updateStateByKey(func) | 返回一个新的“状态”DStream,其中通过在键的先前状态和键的新值上应用给定函数来更新每个键的状态。这可用于维护每个密钥的任意状态数据。 |
UpdateStateByKey操作
该updateStateByKey操作允许我们在使用新信息不断更新时保持任意状态。要使用它,我们必须执行两个步骤:
- 定义状态:状态可以时任意数据类型。
- 定义状态更新功能:使用函数指定如何使用先前状态和输入流中的新值更新状态。
在每个批处理中,Spark都会对所有现有密钥应用状态更新功能,无论它们是否在批处理中都有新数据。如果更新函数返回,None则将删除键值对。
举个栗子。假设我们要维护文本数据流中看到的每个单词的运行计数。这里,运行计数是状态,它是一个整数。我们将更新功能定义为:
Function2<List<Integer>, Optional<Integer>, Optional<Integer>> updateFunction =
(values, state) -> {
Integer newSum = ... // add the new values with the previous running count to get the new count
return Optional.of(newSum);
};这是施加在含DStream
JavaPairDStream<String, Integer> runningCounts = pairs.updateStateByKey(updateFunction);将为每个单词调用更新函数,newValues其序列为1(来自(word,1)成对)并runningCount具有前一个计数。
请注意,使用updateStateByKey需要配置检查点目录。
Transform操作
该transform操作允许在DStream上应用任意RDD到RDD功能。它可用于应用未在DStream API中公开的任何RDD操作。例如,将数据流中的每个批次与另一个数据集连接的功能不会直接在DStream API中公开。但是,我们可以轻松地使用transform来执行此操作。例如,可以通过将输入数据流与预先计算的垃圾邮件信息(也可以使用Spark生成)连接,然后根据它进行过滤,来进行实时数据清理。
import org.apache.spark.streaming.api.java.*;
// RDD containing spam information
JavaPairRDD<String, Double> spamInfoRDD = jssc.sparkContext().newAPIHadoopRDD(...);
JavaPairDStream<String, Integer> cleanedDStream = wordCounts.transform(rdd -> {
rdd.join(spamInfoRDD).filter(...); // join data stream with spam information to do data cleaning
...
});请注意,在每个批处理间隔中都会调用提供的函数。这允许您进行时变RDD操作,即RDD操作,分区数,广播变量等可以在批次之前进行更改。
Window操作
Spark Streaming还提供窗口计算,允许我们在滑动数据窗口上应用转换。下图说明了此滑动窗口。
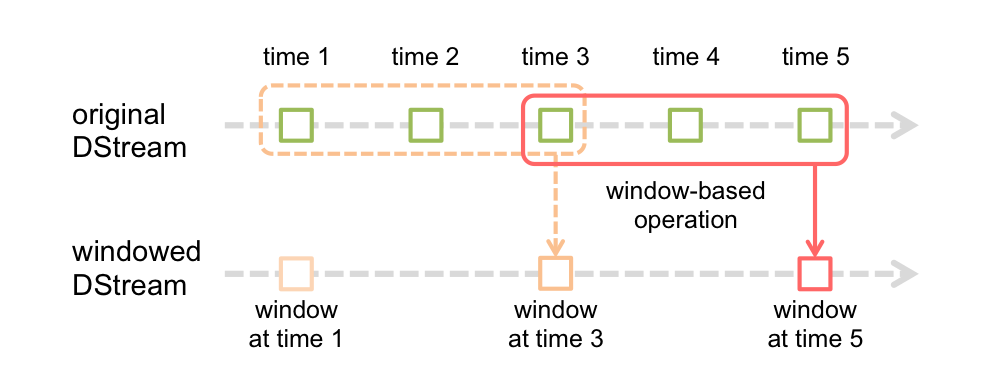
如该图所示,每一个窗口时间的幻灯片在源DStream,落入窗口内的源RDDs被组合及操作,以产生加窗DStream的RDDs。在这种特定情况下,操作应用于最后3个时间单位的数据,并按2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
- 窗口长度:窗口的持续时间(图中的3)。
- 滑动间隔:执行窗口操作的间隔(图中的2)。
这两个参数必须是源DStream的批处理间隔的倍数(图中的1)。
让我们用一个例子来说明窗口操作。比如说,我们希望通过每隔10秒生成最后30秒数据的字数来扩展前面的示例。为此我们必须在最后30秒的数据reduceByKey上对pairsDstream(word , 1)对应操作。这是使用该操作完成的reduceByKeyAndWindow。
// Reduce last 30 seconds of data, every 10 seconds
JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2, Durations.seconds(30), Durations.seconds(10));一些常见的窗口操作如下。所有这些操作都采用上述两个参数:windowLength 和 slideInterval。
| 转换 | 含义 |
| window(windowLength,slideInterval) | 返回一个新的DStream,它是根据源DStream的窗口批次计算的。 |
| countByWindow(windowLength,slideInterval) | 返回流中元素的滑动窗口数。 |
| reduceByWindow(func,windowLength,slideInterval) | 返回一个新的单元素流,通过使用func在滑动间隔内聚合流中的元素而创建。该函数应该是关联的和可交换的,以便可以并行正确计算。 |
| reduceByKeyAndWindow(func,windowLength,slideInterval,[ numTasks ]) | 当在(K,V)对的DStream上调用时,返回(K,V)对的新DStream,其中使用给定的reduce函数func在滑动窗口中的批次聚合每个键的值。注意:默认情况下,这使用Spark的默认并行任务数(本地模式为2,在集群模式下,数量由config属性spark.default.parallelism确定)进行分组。我们可以传递可选参数numTask来设置不同数量的任务。 |
| reduceByKeyAndWindow(func,invFunc,windowLength,slideInterval,[ numTasks ]) | 上述更有效的版本,reduceByKeyAndWindow()其中使用前一窗口的reduce值逐步计算每个窗口的reduce值。这是通过减少进入滑动窗口的新数据和“反向减少”离开窗口的旧数据来完成的。一个例子是当窗口滑动时“添加”和“减少”键的计数。但是,它仅适用于“可逆减少函数”,即哪些具有想用“反向减少”函数的减函数(作为参数invFunc)。 |
| countByValueAndWindow(windowLength, slideInterval,[numTasks ]) | 当在(K,V)对的DStream上调用时,返回(K,Long)对的新DStream,其中每个键的值是其在滑动窗口内的频率。同样reduceByKeyAndWindow,reduce任务的数量可通过可选参数进行配置 |
Join操作
最后,值得强调的是,我们可以轻松地在Spark Streaming中执行不同类型地连接。
流连接
Streams可以很容易地与其他流连接。
JavaPairDStream<String, String> stream1 = ...
JavaPairDStream<String, String> stream2 = ...
JavaPairDStream<String, Tuple2<String, String>> joinedStream = stream1.join(stream2);这里,在每个批处理间隔中,生成地RDD stream1将与生成的RDD连接stream2.你也可以做leftOuterJoin,rightOuterJoin,fullOuterJoin。此外,在流的窗口上进行连接通常非常有用,同时也很容易。
JavaPairDStream<String, String> windowedStream1 = stream1.window(Durations.seconds(20));
JavaPairDStream<String, String> windowedStream2 = stream2.window(Durations.minutes(1));
JavaPairDStream<String, Tuple2<String, String>> joinedStream = windowedStream1.join(windowedStream2);流数据集连接
在解释DStream.transform操作时已经显示了这一点。这是将窗口流与数据集连接的另一个示例。
JavaPairRDD<String, String> dataset = ...
JavaPairDStream<String, String> windowedStream = stream.window(Durations.seconds(20));
JavaPairDStream<String, String> joinedStream = windowedStream.transform(rdd -> rdd.join(dataset));实际上,我们还可以动态更改要加入的数据集。提供给的函数在transform每个批处理间隔进行评估,因此将使用dataset引用指向的当前数据集。
API文档中提供了完整的DStream转换列表。我们在使用Spark时,可以参考Spark官方API文档进行查询参阅。
DStreams的输出操作
输出操作允许将DStream的数据推送到外部系统,如数据库或文件系统。由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有DStream转换的实际执行(类似于RDD的操作)。目前,定义了以下输出操作:
| 输出操作 | 含义 |
| print() | 在运行流应用程序的驱动程序节点上打印DStream中每批数据的前是个元素。这对开发和调试很有用。 |
| saveAsTextFiles(prefix,[suffix]) | 将此DStream的内容保存为文本文件。每个批处理间隔的文件名基于前缀和后缀生成:"prefix-TIME_IN_MS[.suffix]"。 |
| saveAsObjectFiles(prefix,[suffix]) | 将此DStream的内容保存为SequenceFiles序列化Java对象。每个批处理间隔的文件名基于前缀和后缀生成:"prefix-TIME_IN_MS[.suffix]"。 |
| saveAsHadoopFiles(prefix,[suffix]) | 将此DStream的内容保存为Hadoop文件。每个批处理间隔的文件名基于前缀和后缀生成:"prefix-TIME_IN_MS[.suffix]"。 |
| foreachRDD(func) | 最通用的输出运算符,它将函数func应用于从流生成的每个RDD。此函数应将每个RDD中的数据推送到外部系统,例如将RDD保存到文件,或通过网络将其写入数据库。请注意,函数func在运行流应用数据的驱动程序进程中执行,并且通常会在其中执行RDD操作,这将强制计算流式RDD。 |
使用foreachRDD的设计模式
dstream.foreachRDD是一个功能强大的原语,允许将数据发送到外部系统。但是,了解如何正确有效地使用此原语非常重要。一些常见地错误要避免如下操作。
通常将数据写入外部系统需要创建连接对象(例如,与远程服务器地TCP连接)并使用它将数据发送到远程系统。为此,开发人员可能无意中尝试在Spark驱动程序中创建连接对象,然后尝试在Spark工作程序中使用它来保存RDD中地记录。
dstream.foreachRDD(rdd -> {
Connection connection = createNewConnection(); // executed at the driver
rdd.foreach(record -> {
connection.send(record); // executed at the worker
});
});这是不正确地,因为这需要连接对象被序列化并从驱动程序发送到worker。这种连接对象很少跨机器传输。此错误可能表现为序列化错误(连接对象不可序列化),初始化错误(需要在worker处初始化连接对象)等。正确地解决方案是在worker出创建连接对象。
但是,这可能会导致另一个常见错误:为每条记录创建一个新连接。例如:
dstream.foreachRDD(rdd -> {
rdd.foreach(record -> {
Connection connection = createNewConnection();
connection.send(record);
connection.close();
});
});通常,创建连接对象会产生时间和资源开销。因此,为每个记录创建和销毁连接对象可能会产生不必要地高开销,并且可能会显著降低系统地吞吐量。更好地解决方案是使用rdd.foreachPartition:创建单个连接对象并使用该连接发送RDD分区中地所有记录。
dstream.foreachRDD(rdd -> {
rdd.foreachPartition(partitionOfRecords -> {
Connection connection = createNewConnection();
while (partitionOfRecords.hasNext()) {
connection.send(partitionOfRecords.next());
}
connection.close();
});
});这会分摊许多记录地连接创建开销。
最后,通过多个RDDs/batches中重用连接对象,可以进一步优化这一点。由于多个批次的RDD被推送到外部系统,因此可以维护连接对象的静态池,而不是可以重用的连接对象,从而进一步减少了开销。
dstream.foreachRDD(rdd -> {
rdd.foreachPartition(partitionOfRecords -> {
// ConnectionPool is a static, lazily initialized pool of connections
Connection connection = ConnectionPool.getConnection();
while (partitionOfRecords.hasNext()) {
connection.send(partitionOfRecords.next());
}
ConnectionPool.returnConnection(connection); // return to the pool for future reuse
});
});请注意,池中的连接应根据需要延迟创建,如果暂时不使用,则会超时。这实现了最有效的数据发送到外部系统。
要记住的其他要点:
- DStream由输出操作延迟执行,就像RDD由RDD操作延迟执行一样。具体而言,DStream输出操作中的RDD操作会强制处理接收到的数据。因此,如果您的应用程序没有任何输出操作,或者输出操作dstream.foreachRDD()没有任何RDD操作,那么就不会执行任何操作。系统将简单地接收数据并将其丢弃。
- 默认情况下,输出操作一次执行一次。它们按照应用程序中定义的顺序执行。















 3394
3394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









