






目录
前言
操作同一类型数据或对象,在java中可使用一组数组来存放。但是,数组是固定长度的,使用数组进行开发会造成很多不便,比如资源的浪费,开发人员操作繁琐。
为了解决这个问题,一种更优的解决方案“集合”出现了。Java 所有的集合类都位于 java.util 包下,提供了一个表示和操作对象集合的统一构架,包含大量集合接口,以及这些接口的实现类和操作它们的算法。
集合与数组的对比:
1、数组声明了它容纳的元素的类型,而集合不声明。这是由于集合以object形式来存储它们的元素。
2、一个数组实例具有固定的大小,不能伸缩。集合则使用初始容量和加载因子根据需要动态改变自己的大小。
3、集合中不能放基本数据类型,但可以放基本数据类型的包装类。
集合框架图:
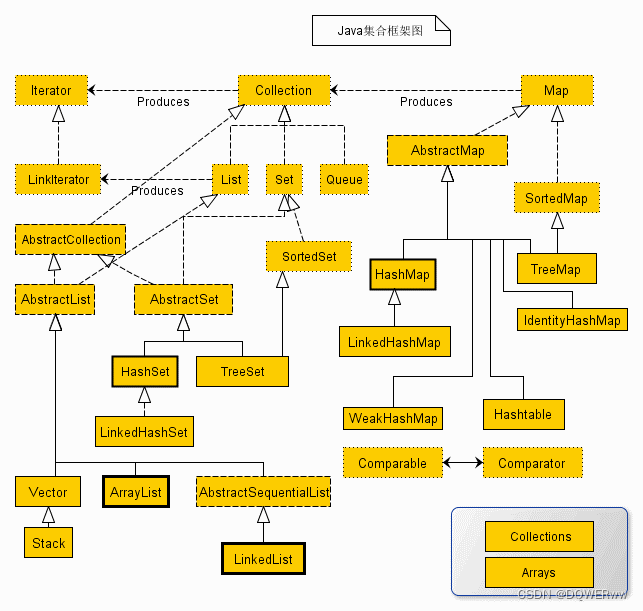
上述类图中,实线边框的是实现类,比如ArrayList,LinkedList,HashMap等,折线边框的是抽象类,比如AbstractCollection,AbstractList,AbstractMap等,而点线边框的是接口,比如Collection,Iterator,List等。
Collection和Map
java中的集合主要分为Collection和Map两种:
Collection:单列
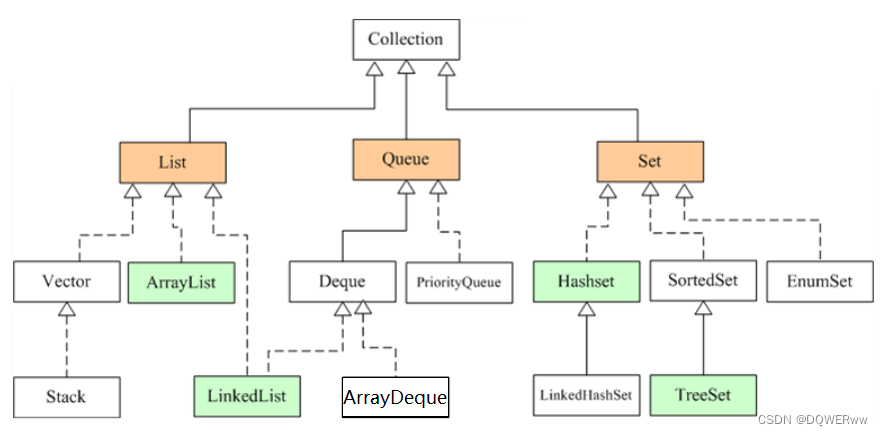
Collection 接口是 List、Set 和 Queue 接口的父接口,通常情况下不被直接使用。Collection 接口定义了一些通用的方法,通过这些方法可以实现对集合的基本操作。定义的方法既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
Collection的常用方法:
| boolean add(Object o) | 添加指定元素 |
| boolean addAll(Collection c) | 添加指定集合 |
| boolean remove(Object o) | 删除指定元素 |
| boolean removeAll(Collection c) | 输出两个集合的交集 |
| boolean retainAll(Collection c) | 保留两个集合的交集 |
| void clear() | 清空集合 |
| int size(); | 集合中的有效元素个数 |
| Object[] toArray() | 将集合中的元素转换成Object类型数组 |
| boolean isEmpty(); | 判断是否为空 |
| boolean containsAll(Collection c) | 判断是否包含指定集合 |
| boolean contains(Object o); | 判断是否包含指定元素 |
List:有序列表集合
特点:有索引值,有序,可重复;
常用实现类:
| ArrayList | 底层数据结构是数组,查询快,增删慢。 线程不安全,效率高。 |
| Vector | 底层数据结构是数组,查询快,增删慢。 线程安全,效率低。 |
| LinkedList | 集合数据存储的结构是链表结构。方便元素添加、删除的集合。查询慢,增删快。 线程不安全,效率高。 |
Queue:队列集合
特点:队列的入口、出口各占一侧。
常用实现类以及接口:
| PriorityQueue | PriorityQueue是一种比较标准的队列实现类,而不是绝对标准的。这是因为PriorityQueue保存队列元素的顺序不是按照元素添加的顺序来保存的,而是在添加元素的时候对元素的大小排序后再保存的。因此在PriorityQueue中使用peek()或pool()取出队列中头部的元素,取出的不是最先添加的元素,而是最小的元素。 |
| Dueue接口与ArrayDeque实现类 | Deque接口是Queue接口的子接口,它代表一个双端队列;(有大量的首位操作方法) |
| LinkedList | LinkedList是List接口的实现类,因此它可以是一个集合,可以根据索引来随机访问集合中的元素。此外,它还是Duque接口的实现类,因此也可以作为一个双端队列,或者栈来使用。LinkedList与ArrayList,ArrayDeque的实现机制完全不同,ArrayList和ArrayDeque内部以数组的形式来保存集合中的元素,因此随机访问集合元素时有较好的性能;而LinkedList以链表的形式来保存集合中的元素,因此随机访问集合元素时性能较差,但是插入和删除元素时性能比较出色(只需改变指针所指的地址即可),需要指出的是,虽然Vector也是以数组的形式来存储集合但因为它实现了线程同步(而且实现的机制不好),故各方面的性能都比较差。 |
Queue接口常用方法:
| void add(Object e) | 将指定元素插入到队列的尾部 |
| object element() | 获取队列头部的元素,但是不删除该元素。 |
| boolean offer(Object e) | 将指定的元素插入此队列的尾部。当使用容量有限的队列时,此方法通常比add(Object e)有效。 |
| Object peek() | 返回队列头部的元素,但是不删除该元素。如果队列为空,则返回null。 |
| Object poll() | 返回队列头部的元素,并删除该元素。如果队列为空,则返回null。 |
| Object remove() | 获取队列头部的元素,并删除该元素。 |
Dueue接口的常用方法:
| void add(Object e) | 将指定元素插入到队列的尾部。 |
| object element() | 获取队列头部的元素,但是不删除该元素。 |
| boolean offer(Object e) | 将指定的元素插入此队列的尾部。当使用容量有限的队列时,此方法通常比add(Object e)有效。 |
| Object peek() | 返回队列头部的元素,但是不删除该元素。如果队列为空,则返回null。 |
| Object poll() | 返回队列头部的元素,并删除该元素。如果队列为空,则返回null。 |
| Object remove() | 获取队列头部的元素,并删除该元素。 |
Set:无序散列集合
特点:没有索引值,不可重复;
常用实现类:
| HashSet | 无序,底层是哈希表,线程不安全,效率高 |
| LinkedHashSet | 有序,底层是链表+哈希表 |
| TreeSet | 可以排序,底层是红黑树 |
| Hashtable | 和HashSet相似,线程安全,效率低 |
set集合的新增过程:
1、创建set集合,底层会创建一个数组;
2、添加元素时,新增元素的索引=该元素.hashCode()%数组长度,若该位置存在重复元素,则不添加;若不存在重复元素,则以链表形式挂在该索引位置下;
3、若同一索引位置添加的元素大于8个,则该链表链接会转换成为红黑树;
判断重复元素的依据:
哈希值相同&&( 地址值相同 || equal() 相同);
通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
Map:双列
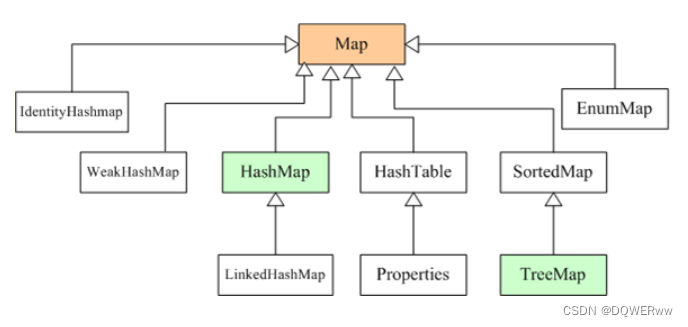
特点:
1.一个元素是有一个K,一个V两部分组成
2.K V可以是任意的引用数据类型
3.一个K对应唯一的一个V。K不能重复,V可以重复
常用实现类:
| HashMap | 底层是哈希表。无序,线程不安全,效率高 |
| LinkedHashMap | 底层是链表+哈希表。有序 |
| TreeMap | 底层是红黑树。可排序 |
| Hashtable | 线程安全,效率低和HashMap类似 |
Map集合的常用方法
| public V put(K key, V value) | 把指定的键与指定的值添加到Map集合中。 |
| public V remove(Object key) | 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。 |
| public V get(Object key) | 根据指定的键,在Map集合中获取对应的值。 |
| boolean containsKey(Object key) | 判断集合中是否包含指定的键。 |
| public Set<K> keySet(): | 获取Map集合中所有的键,存储到Set集合中。 |
| public Set<Map.Entry<K,V>> entrySet(): | 获取到Map集合中所有的键值对对象的集合(Set集合)。 |
集合的应用
采用leetCode题库讲解:
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/two-sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
暴力循环解:
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] res = new int[2];
for(int i=0;i<nums.length;i++){
for(int j=i+1;j<nums.length;j++){
if(nums[i]+nums[j]==target){ //获取索引值强行遍历
res[0]=i;
res[1]=j;
break;
}
}
}
return res;
}
}使用单列集合:
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] res = new int[2];
ArrayList<Integer> list = new ArrayList<Integer>();
for(int i=0;i<nums.length;i++){
if(list.contains(nums[i])){ //如果等于补数
res[0]=list.indexOf(nums[i]); //获取补数的索引
res[1]=i; //获取索引
}
list.add(target-nums[i]); //不存在添加补数
}
return res;
}
}使用双列集合:
class Solution {
public static int[] twoSum(int[] nums, int target) {
int[] arr = new int[2];
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
// 如果包含,,获取map的下标和i,即是索引值
if (map.containsKey(nums[i])) {
arr[0] = map.get(nums[i]); // 补数的下标
arr[1] = i;
return arr;
}
// 如果不包含,补数作为key,索引值作为value
map.put(target - nums[i], i);
}
return null;
}
}表面上看,第一种解法执行效率 < 第二种解法执行效率 < 第三种解法执行效率;实际上却不是如此;
暴力循环解:至少2个for循环,效率最低;若数组长度为x,则循环需要执行x²次;
使用单列集合:表面上时执行了1次for循环,然而list.contains() 方法底层其实执行的也是for循环,参考下图:
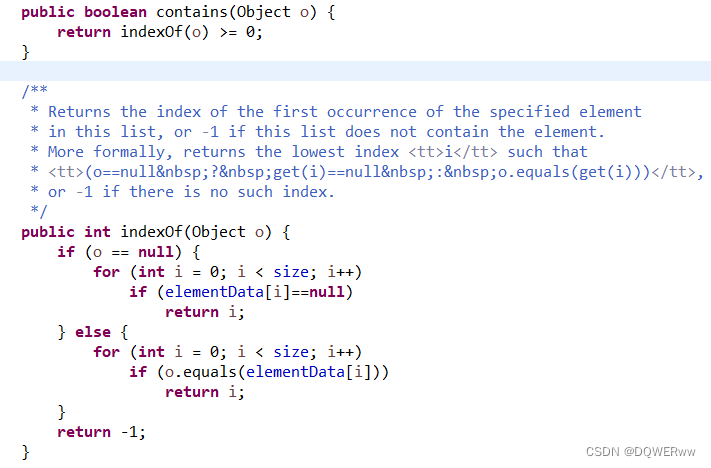
实际效率与第一种差不多;
使用双列集合:补数作为map的key,索引值作为value,只需要遍历一次,效率大大提升;















 5311
5311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









