







11.7银行大作业实验报告
1 分析与实现
1.1 普通版(program1)
1.1.1 目标
在原来的程序上加入 VIP 功能,满足:
- 任意 VIP 客户优先于任意普通客户办理业务;
- VIP 客户之间保持先来后到的顺序服务;
- 普通客户排队顺序原则不变。
1.1.2 任务分析
如果直接暴力实现 VIP 的插队行为,那么某个窗口被它插队的所有普通客户的 departure 事件都需要更改(time 和 waittime 改变了),复杂度高且实现比较繁琐。更重要的是,这样做打破了“普通客户排队顺序不变”的原则(比如先来的3号普通客户被插队,别的窗口没被插队的4号普通客户就可能比3号更早被服务到)。
如何优化?我们想要的是:一个 departure 事件一旦生成,后面就不会更改。这意味着我们不能像原程序一样在处理 arrival 事件的时候生成 departure 事件(如果这样做,后面他在排队的时候可能会被插队),只能在一个 customer 被 teller 服务的时候才能确定 departure 事件(已经在被服务了,后面不可能被插队了)。
1.1.3 实现方法
一种做法是开一个缓冲优先队列 buf,从 pq 处理完 arrival 事件后不直接分给某个 teller(但要生成下一个 arrival),而是进入 buf 排队;当某个 teller 空闲时,再从 buf 的队头取客户,同时生成其离开事件。也就是说,所有的“插队”过程放在 buf 中进行,并且 buf 中普通客户和 VIP 客户分别保持着先来后到的顺序。显然,这样做能够满足三个目标。
进一步发现,buf 中的 VIP 客户和普通客户都是到来时间有序的,因此可以开两个普通队列 bufV 和 bufN,VIP 客户进入 bufV,普通客户进入 bufN;取元素的时候如果 bufV 非空就取 bufV 队头,否则取 bufN 队头,从而避免了优先队列的使用(但为了方便,程序中还是直接借用了 PQueue 类)。
1.2 附加版(program2)
1.2.1 目标
设计一套自动引导顾客进行排队的机制,让无论是否是 VIP 的顾客体验都能最好。此题为开放题,言之成理,实验结果能够支撑论点即可。
1.2.2 任务分析
首先,附加题的目标和普通版的目标不能保证在特殊数据下被同时满足(如果按照普通版要求,一个窗口,两个普通客户,后面密集的来 VIP 客户,那么第二个普通客户需要等待很久很久)。因此我们必须要牺牲 VIP 的部分权益(不能无限插队)来提升普通用户体验,
通过计算,每个顾客的期望等待时间可能是递增的,即越后面来的客户会等越久(比如如果期望服务时间大于顾客到来的期望间隔时间,那么可以证明顾客的期望等待时间不小于某个等差数列,证明略)。因此直接计算等待时间的方差或者平均值是不合理且没有意义的,不能作为评判程序好坏的依据。
那我们就要先制定一个合理的评价指标。站在客户的角度尝试思考问题,某个普通客户什么时候会不满意?如果 A 来的时候估算出自己需要等待 20 分钟,结果被若干 VIP 客户插队后实际等待时间变成了 60 分钟,那他肯定会不满意;但对于 B 来说,他本来就需要等待 50 分钟,而实际等待时间同样为 60 分钟也是可以被接受的。也就是说,我们更关注实际等待时间和预估等待时间的比值。
形式化来讲,如果某位普通客户本来需要等待 s s s 分钟,由于插队多等了 t t t 分钟,我们用 α = t / s \alpha = t / s α=t/s 表示他的“不满意指数”。直观上来说,对这个比值求平均数或方差是较为合理的。接着我们假定,如果 t > c s t > cs t>cs 时顾客体验会极差,其中 c c c 是由数据特性确定的常数,后面根据实验结果调整。因此,我们让 VIP 插队的时候要尽量保证每位普通客户的 t ≤ c s t \leq cs t≤cs。也就是说,我是通过抑制普通客户的不满意指数来控制其均值及方差。同理,对 VIP 客户我们采取相同的定义,显然,VIP 用户的不满意指数恒不超过 1。
需要注意的是,选择 c c c 的时候既要照顾普通用户( c c c 不能太大),又要考虑 VIP 权益( c c c 不能太小)。
1.2.3 实现方法
大部分和普通版一样,开 bufV 和 bufN 两个缓冲队列,但不是在 bufV 空的时候才取 bufN,而是在 bufV 头不能排在 bufN 头前,即 bufN 头的 t > c s t > cs t>cs 的时候取 bufN,否则 bufN 头就因为被插太多次队而不满意了。
经过数学推导,初步确定参数
c
c
c 的取值为 1.0 * (serviceHigh + serviceLow) / (arrivalHigh + arrivalLow) * 0.3 / numTellers; (见程序),大致含义为普通客户原本等待时间内来的 VIP 客户都可以插到他前面。其合理性在后面还会探讨。
2 完成效果
2.1 数据获取
首先,程序可以正确运行。
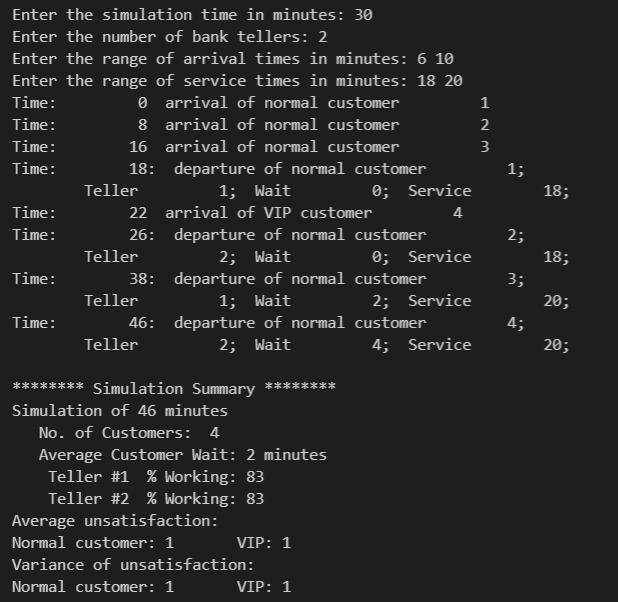
如前面分析,记不满意指数 α \alpha α 为某位顾客的 实际等待时间 / 预估等待时间,并计算 α \alpha α 的最大值 M a x ( α ) Max(\alpha) Max(α) 、平均值 E ( α ) E(\alpha) E(α) 和方差 S 2 ( α ) S^2(\alpha) S2(α) (反映不满意指数的分布情况,所谓不患寡而患不均,数据越稳定当然越好)来展示程序的实际效果。
由于在构造数据下可能会出现非常奇怪的情景(例如某段时间集中来了很多 VIP)且不符合实际情况,我们只关注程序在随机数据下的表现, 即 VIP 占比 30%,所有时间在给定范围内随机生成。
可以通过理论分析和实验结果证明,输入数据的主要特征是 “期望服务时间/窗口数量” 与 “顾客到来的期望间隔时间” 的比值。因此这里只选取控制服务时间生成范围([2, 5])、窗口数量(4)和模拟时间(5000)不变,仅改变间隔时间的生成范围的 8 组输入数据来做分析,每组数据运行 20 次取平均值,用 MATLAB 作图如下:

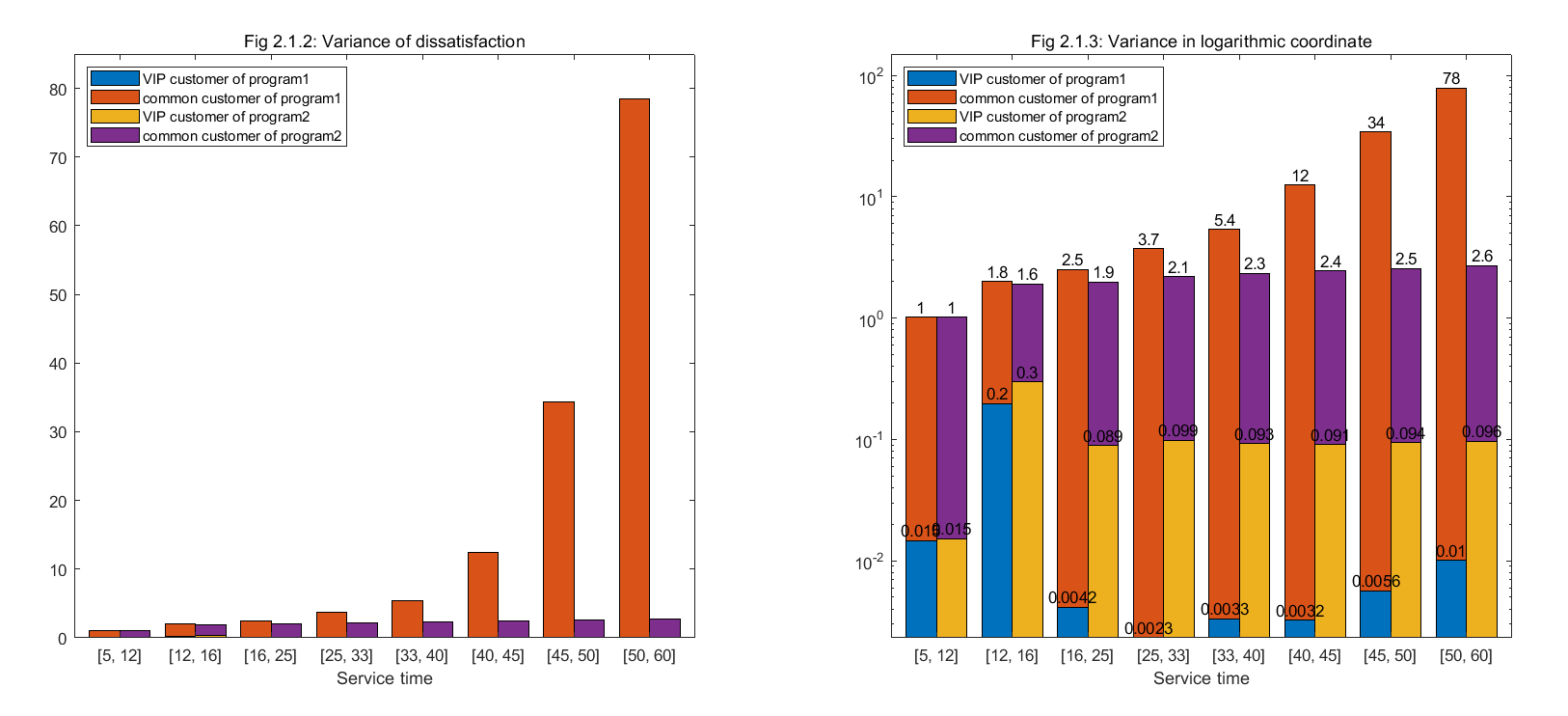
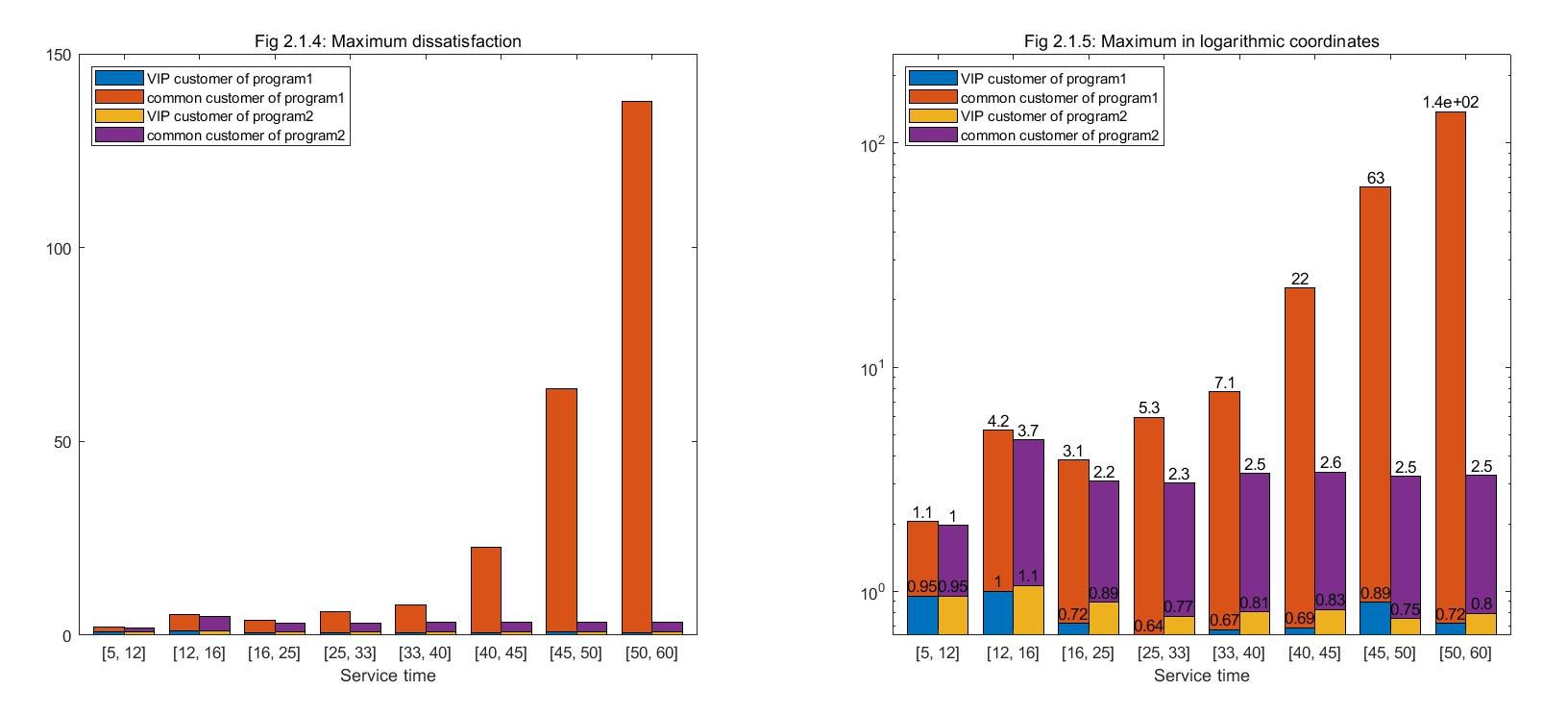
(注:图 2.1.3 以及图 2.1.5 纵坐标为对数坐标。某些看似没出现在图中的颜色是因为数值太小,不明显。原始数据见 data/out1 和 data/out2。)
2.2 讨论分析
首先,纵向对比,无论程序1还是程序2,在模拟中普通客户的不满意指数平均值、最大值和方差都明显高于 VIP 客户,因此 VIP 用户整体对服务更为满意。
横向比较,随着每位顾客期望服务时间的增长,程序2在保证普通用户的权益方面优势显著,不满意指数平均值、方差、最大值都显著小于程序1,甚至平均值和方差仅为程序1的几十分之一,图中对比十分明显。而 VIP 客户平均不满意指数稳定在 0.3 上下,可以接受。
模拟实验进一步验证了 1.2.3 中 c c c 选择的合理性。这样选择使得客户不满意指数的统计数据不会随着每位顾客期望服务时间的增长而无限增大,而是趋于稳定。值得注意到是,由于方差较小,这个稳定后的平均值还可以较为准确的预测顾客的实际等待时间,进一步提升用户体验。
3 感受与感悟
我觉得这个大作业最重要的是建模以及评估两项,这也是花费我最多时间的部分。
如果不拿出数据作为支持,那么很多做法看上去其实都很靠谱。实际上,几个我本来以为很有效的做法,都在我构造的数据下被证明没有那么有效甚至是被证伪。
所以我的感受是,一个好的解决方法绝不是一拍脑袋想出来的,一定是要有数学理论以及实验结果支持。















 3588
3588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









