







文章目录
全文搜索引擎
百度百科中的定义:
全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
为什么要用全文搜索搜索引擎
为什么要用搜索引擎?我们的所有数据在数据库里面都有,而且 Oracle、SQL Server 等数据库里也能提供查询检索或者聚类分析功能,直接通过数据库查询不就可以了吗?确实,我们大部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过建数据库索引,优化SQL等方式进行提升效率,甚至通过引入缓存来加快数据的返回速度。如果数据量更大,就可以分库分表来分担查询压力。
主要从以下几个原因分析:
数据类型
全文索引搜索支持非结构化数据的搜索,可以更好地快速搜索大量存在的任何单词或单词组的非结构化文本。
例如 Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
索引的维护
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对SQL的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
什么时候使用全文搜索引擎
搜索的数据对象是大量的非结构化的文本数据。
文件记录量达到数十万或数百万个甚至更多。
支持大量基于交互式文本的查询。
需求非常灵活的全文搜索查询。
对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
ElasticSearch简介
Elasticsearch是一个基于Apache Lucene™的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
Lucene是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎
特点:
a.分布式的实时文件存储,每个字段都被索引并可被搜索
b.分布式的实时分析搜索引擎–做不规则查询
c.可以扩展到上百台服务器,处理PB级结构化或非结构化数据
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch能做什么
全文检索(全部字段)、模糊查询(搜索)、数据分析(提供分析语法,例如聚合)
Elasticsearch使用案例
(1)2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索.GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码
(2)维基百科:启动以elasticsearch为基础的核心搜索架构SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
(3)百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
(4)新浪使用ES 分析处理32亿条实时日志
(5)阿里使用ES 构建挖财自己的日志采集和分析体系
同类产品
Solr、ElasticSearch、Hermes(腾讯)(实时检索分析)
Solr、ES
-
源自搜索引擎,侧重搜索与全文检索
-
数据规模从几百万到千万不等,数据量过亿的集群特别少。
有可能存在个别系统数据量过亿,但这并不是普遍现象(就像Oracle的表里的数据规模有可能超过Hive里一样,但需要小型机)。
Hermes
-
一个基于大索引技术的海量数据实时检索分析平台。侧重数据分析。
-
数据规模从几亿到万亿不等。最小的表也是千万级别。
在 腾讯17 台TS5机器,就可以处理每天450亿的数据(每条数据1kb左右),数据可以保存一个月之久。
Solr、ES区别
全文检索、搜索、分析。基于lucene
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于Elasticsearch-----附近的人

ElasticSearch安装
准备工作
安装Centos7、建议内存2G以上、安装java1.8环境
基本配置
设置IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iOIBy21e-1588424199524)(file:///C:/Users/daiha/AppData/Local/Temp/msohtmlclip1/01/clip_image002.jpg)]](https://img-blog.csdnimg.cn/20200502211445919.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RfQV9JX0hfQV9P,size_16,color_FFFFFF,t_70) ### 网络重置
### 网络重置
service network restart
添加用户
[root@localhost ~]# adduser elk
[root@localhost ~]# passwd elk
-以下授权步骤可省略
[root@localhost ~]# whereis sudoers
[root@localhost ~]# ls -l /etc/sudoers
[root@localhost ~]# vi /etc/sudoers
-Allow root to run any commands anywher
root ALL=(ALL) ALL
linuxidc ALL=(ALL) ALL #这个是新增的用户
[root@localhost ~]# chmod -v u-w /etc/sudoers
[root@localhost ~]# su elk
Java环境安装
解压安装包
[root@localhost jdk1.8]# tar -zxvf jdk-8u171-linux-x64.tar.gz
设置Java环境变量
[root@localhost jdk1.8.0_171]# vi /etc/profile
在文件最后添加
export JAVA_HOME=/home/elk1/jdk1.8/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/LIB:$JRE_HOME/LIB:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
[root@localhost jdk1.8.0_171]# source /etc/profile
[root@localhost jdk1.8.0_171]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
ElasticSerach单机安装
解压安装包
[root@localhost elasticserach]# tar -zxvf elasticsearch-6.3.1.tar.gz
[root@localhost elasticserach]# cd elasticsearch-6.3.1/bin
[root@localhost bin]# ./elasticsearch
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HH8nzrge-1588424199526)(C:\Users\daiha\AppData\Roaming\Typora\typora-user-images\image-20200502205343866.png)]](https://img-blog.csdnimg.cn/20200502211510660.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RfQV9JX0hfQV9P,size_16,color_FFFFFF,t_70)
[root@localhost bin]# su elk1
[elk1@localhost bin]$ ./elasticsearch
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zlfTNcuz-1588424199527)(file:///C:/Users/daiha/AppData/Local/Temp/msohtmlclip1/01/clip_image004.jpg)]](https://img-blog.csdnimg.cn/20200502211525507.png)
权限
chown -R 用户名:用户名 文件(目录)名
chmond 777 *
[root@localhost bin]# chown -R DAIHAO: DAIHAO /home/ DAIHAO /elasticsearch
[elk1@localhost bin]$ ./elasticsearch
[elk1@localhost config]$ vi jvm.options
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XWTcShB7-1588424199529)(file:///C:/Users/daiha/AppData/Local/Temp/msohtmlclip1/01/clip_image005.png)]](https://img-blog.csdnimg.cn/2020050221162475.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RfQV9JX0hfQV9P,size_16,color_FFFFFF,t_70)
[elk1@localhost bin]$ ./elasticsearch

[root@localhost jdk1.8.0_171]# curl 127.0.0.1:9200

后台启动
[elk1@localhost bin]$
关闭程序
[elk1@localhost bin]$ ps -ef|grep elastic

[elk1@localhost bin]$ kill 10097
设置浏览器访问
[root@localhost bin]systemctl stop firewalld
[root@localhost bin]vi config/elasticsearch.yml

安装问题

解决方案
[root@localhost bin]# vi /etc/security/limits.conf
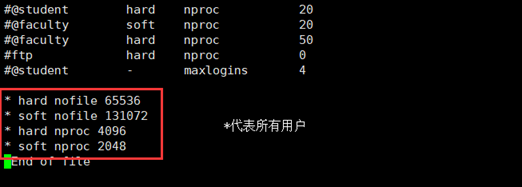
nofile - 打开文件的最大数目
noproc - 进程的最大数目
soft 指的是当前系统生效的设置值
hard 表明系统中所能设定的最大值
* hard nofile 655360
\* soft nofile 131072
\* hard nproc 4096
\* soft nproc 2048
解决方案
[root@localhost bin]# vi /etc/sysctl.conf
[root@localhost bin]# sysctl -p
vm.max_map_count=655360
fs.file-max=655360
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-orb0WUGi-1588424199537)(file:///C:/Users/daiha/AppData/Local/Temp/msohtmlclip1/01/clip_image019.jpg)]](https://img-blog.csdnimg.cn/20200502212234840.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RfQV9JX0hfQV9P,size_16,color_FFFFFF,t_70)
vm.max_map_count=655360,因此缺省配置下,单个jvm能开启的最大线程数为其一半
file-max是设置 系统所有进程一共可以打开的文件数量
# 测试0.0.0.0 account.jetbrains.com
0.0.0.0 www.jetbrains.com
Liunx执行: curl ‘http://localhost:9200/?pretty’
浏览器访问:http://localhost:9200/?pretty
状态查看命令
语法:
ip:post/_cat/[args](?v|?format=json&pretty)
(?v表示显示字段说明,?format=json&pretty表示显示成json格式)
1、查看所有索引
GET _cat/indices?v
2、查看es集群状态
GET _cat/health?v















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









