







Hadoop概述、搭建完全分布式(非高可用)
HDFS概述、Shell与API操作
务必配合Hadoop概述、搭建完全分布式(非高可用)一起使用,因为在搭建过程中封装了较多脚本
一、HDFS读写数据流程
- 网络拓扑——节点间距离计算
(1) 节点距离:两个节点到达最近的共同祖先的距离总和
(2) 计算方法
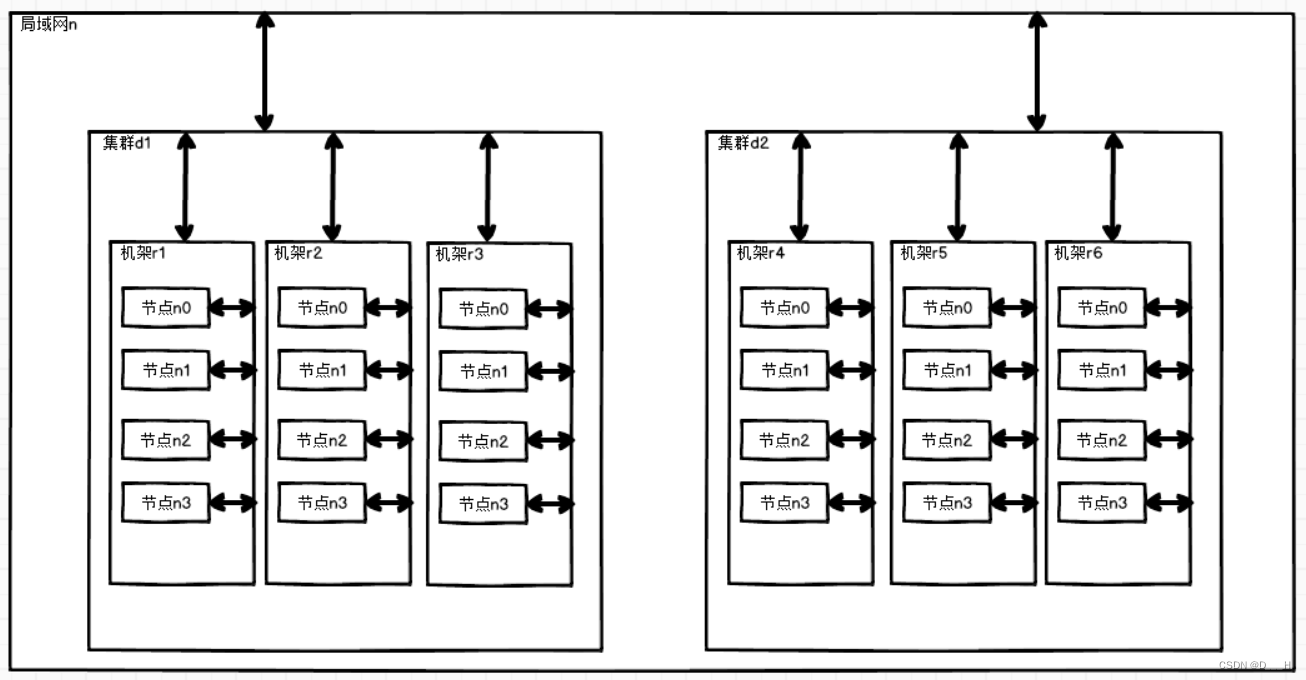
r1中n0到r4中n3的距离:r1中n0->r1->d1->n->d2->r4->r4中n3,最近的共同祖先为n,r1中n0到达n的距离为3,r4中n3到达n的距离为3,r1中n0到r4中n3的距离为6(3+3)。 - 机架感知(副本存储节点选择)——副本数为3
(1) 如果客户端在集群中,选择客户端所在节点为第一个副本;如果客户端在集群外,随机选一个节点作为第一个副本;
(2) 选择另一个机架上的随机一个节点作为第二个副本;
(3) 选择第二个副本所在机架上的另一个随机节点作为第三个副本; - 写数据流程
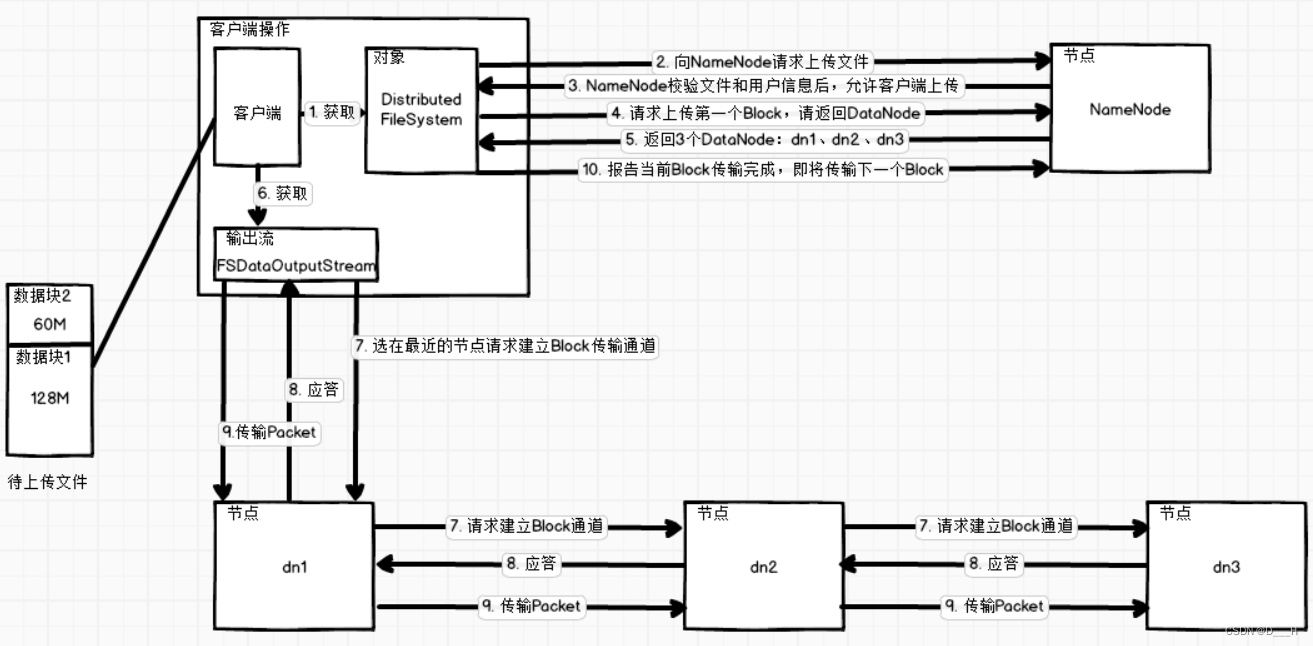
(1) 客户端获取Distributed FileSystem对象,通过该对象与NameNode进行交互;
(2) 向NameNode请求上传文件,NameNode在校验用户以及要上传文件信息均合法后,会应答允许上传文件;
(3) 客户端准备上传数据块,请求NameNode返回一定数量的节点列表;
(4)NameNode应答客户端请求,返回DataNode列表;
(5) 客户端获得DataNode列表后,就会获取输出流对象,通过该对象传输数据块;
(5) 挑选最近的节点建立数据块传输通道。最近的节点将会并行与另一个节点建立传输通道,其他节点间的传输由其他机器负责;
(6) 收到传输通道建立成功的应答。最近的节点也会收到其他节点的通道建立成功的应答,应答过程之间是并行的;
(7) 将数据块划分为更小的单元Packet(大小64KB),传输给数据单元,其他节点之间的传输是并行的,其他节点间的传输由其他机器负责;
(8) 传输完成后,报告NameNode当前数据块传输完毕,然后开始下一个数据块的传输。 - 读数据流程
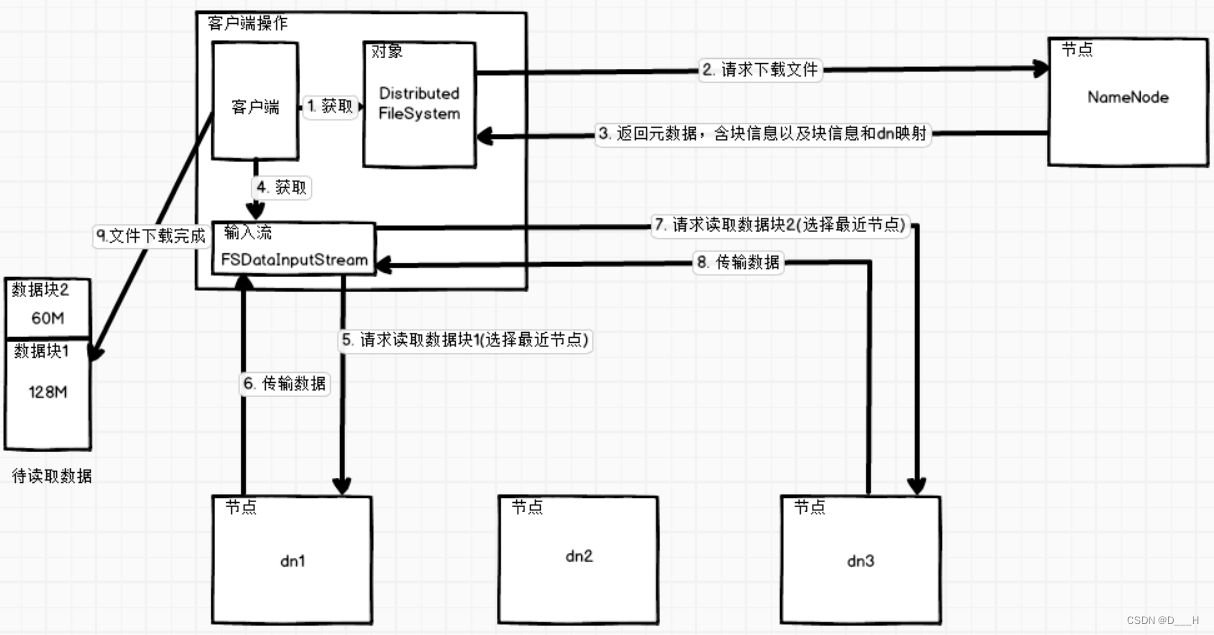
(1) 客户端获取Distributed FileSystem对象,通过该对象与NameNode进行交互;
(2) 向NameNode请求下载文件,NameNode返回元数据信息,其中包括要下载的文件的块列表信息;
(3) 客户端获取输入流,从块列表信息里面选择每一个块所在节点距离最近的节点进行块数据的读取。
二、NameNode与Secondary NameNode工作流程
NameNode元数据文件列表
(1)cd $HADOOP_HOME/data/dfs/name/current ll -rw-rw-r--. 1 soro soro 1048576 7月 1 21:55 edits_0000000000000000001-0000000000000000001 -rw-rw-r--. 1 soro soro 1048576 7月 1 22:00 edits_0000000000000000002-0000000000000000004 -rw-rw-r--. 1 soro soro 1048576 7月 1 22:12 edits_0000000000000000005-0000000000000000131 -rw-rw-r--. 1 soro soro 1048576 7月 2 16:21 edits_0000000000000000132-0000000000000000133 -rw-rw-r--. 1 soro soro 1048576 7月 3 18:32 edits_0000000000000000134-0000000000000000134 -rw-rw-r--. 1 soro soro 1048576 7月 3 18:39 edits_inprogress_0000000000000000135 -rw-rw-r--. 1 soro soro 2311 7月 2 16:19 fsimage_0000000000000000131 -rw-rw-r--. 1 soro soro 62 7月 2 16:19 fsimage_0000000000000000131.md5 -rw-rw-r--. 1 soro soro 2281 7月 3 18:32 fsimage_0000000000000000133 -rw-rw-r--. 1 soro soro 62 7月 3 18:32 fsimage_0000000000000000133.md5 -rw-rw-r--. 1 soro soro 4 7月 3 18:34 seen_txid -rw-rw-r--. 1 soro soro 218 7月 3 18:32 VERSIONedits文件:存储的内容是对hdfs的操作记录,edits_inprogress文件是集群正在往里面记录操作的文件,其他的edits文件是之前集群使用的记录文件;
(2)fsimage文件:存储的内容是元数据,创建时间最新的fsimage文件内存储的是次新的元数据和次新的edits文件合并后的元数据;其余的fsimage文件内存储的内容是其他更旧的fsimage文件和edits文件合并后的结果;
(3)ecits_inprogress+ 最新的fsimage= 最新数据- 工作流程
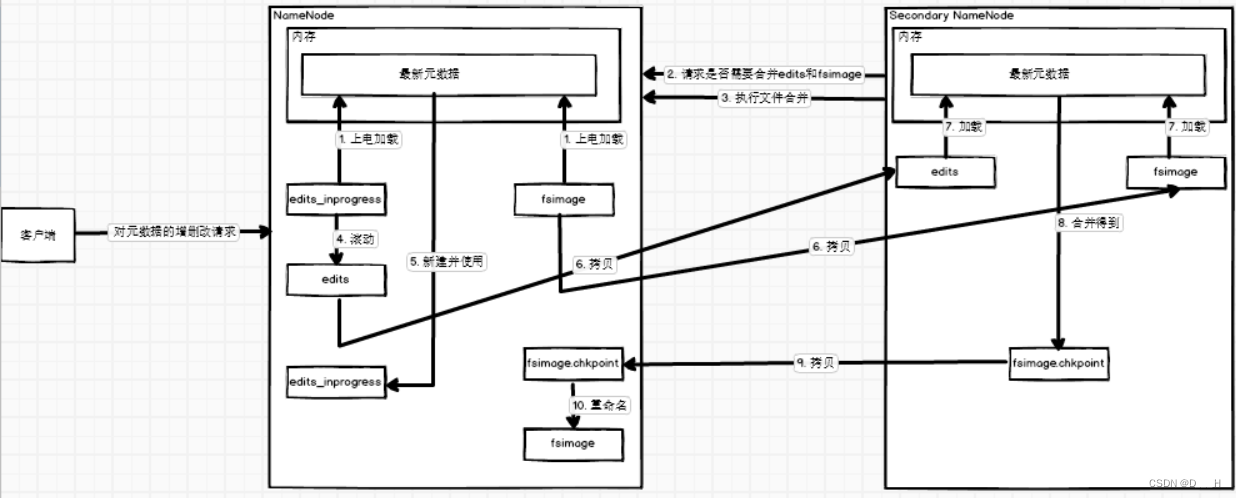
(1) 集群上电后,首先NameNode会将edits_inprogress和最新的fsimage加载到内存进行合并,得到最新的元数据;
(2) 用户不断请求对元数据的增删改,NameNode不断在内存中执行操作,同时将操作不断记录在edits_inprogress文件中;
(3)Secondary NameNode每隔一定时间(edits_inprogress文件中的记录条数达到一定数量)会对NameNode中的edits_inprogress和fsimage文件进行合并;
(4)NameNode会将当前正在使用的edits_inprogress文件滚动为普通的edits文件,然后创建一个空的edits_inprogress文件,向其中写入操作记录;
(5)Secondary NameNode将NameNode中最新的edits和fsimage文件拷贝到本地,在内存中进行合并,并生成fsimage.chkpoint文件;
(6)Secondary NameNode生成的fsimage.chkpoint文件将会被拷贝到NameNode中,然后被重命名为fsimage;
(7)Secondary NameNode中会保存除了NameNode中的edits_inprogress文件以外的所有文件。 - 存在问题
由于Secondary NameNode中没有edits_inprogress文件,导致操作记录缺失,当利用Secondary NameNode进行数据恢复时,有可能造成数据丢失。 - 配置文件合并的时间间隔和
edits_inprogress文件中出发合并的最大记录条数
默认配置文件为:hdfs-default.xml配置项名 说明 dfs.namenode.checkpoint.period 合并时间间隔 dfs.namenode.checkpoint.txns 最大操作记录条数 dfs.namenode.checkpoint.check.period 检查edits_inprogress文件中记录条数的时间间隔<!-- 应于hdfs-site.xml中进行配置 --> <!-- 配置合并文件的时间间隔,默认1小时 --> <property> <name>dfs.namenode.checkpoint.period</name> <value>3600s</value> </property> <!-- 配置edits_inprogress文件中触发合并的最大记录条数 --> <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>操作动作次数</description> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60s</value> <description> 1分钟检查一次操作次数</description> </property >
三、DataNode工作原理
- 工作流程
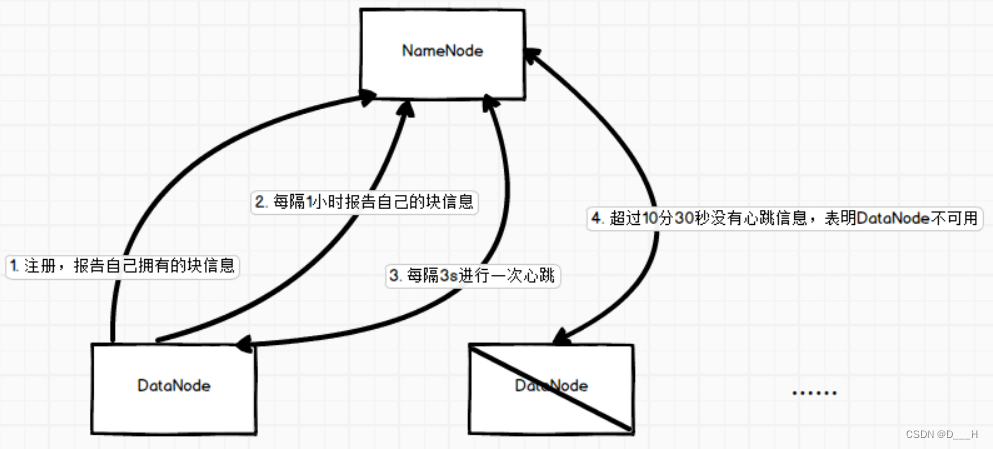
(1)DataNode启动后,会向NameNode注册,并提供自己拥有的块信息,NameNode会将文件块和其所处DataNode的映射维护在内存中;
(2) 之后,每隔1小时DataNode会自己主动向NameNode汇报自己的块信息,同时NameNode和DataNode之间每隔3秒会进行一次心跳;
(3) 如果NameNode和DataNode超过10分30秒没有进行心跳,表明DataNode不可用; DataNode中数据的完整性
DataNode中将数据存储以后,会通过校验算法计算,生成一个校验和文件。当客户端要从DataNode中下载数据块时,会重新使用该数据块通过一定的校验算法计算出校验和,使用新计算出的校验和与之前的校验和文件比较,相同表明数据块正常,可以下载;不同表明数据块损坏,去其他的DataNode中下载数据块。- 掉线时限参数设置(
NameNode判断DataNode不可用所经过的时间)<!-- 应于hdfs-site.xml中进行配置 --> <!-- 掉线时间 = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval --> <!-- 单位为毫秒 --> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <!-- 单位为秒 --> <property> <name>dfs.heartbeat.interval</name> <value>3</value> </property> - 数据节点的服役与退役
(1) 在hdfs-site.xml文件中配置白名单与黑名单文件名
(2) 在<!-- 白名单 --> <property> <name>dfs.hosts</name> <value>/opt/moudle/hadoop-3.1.3/etc/hadoop/whitelist</value> </property> <!-- 黑名单 --> <property> <name>dfs.hosts.exclude</name> <value>/opt/moudle/hadoop-3.1.3/etc/hadoop/blacklist</value> </property>/opt/moudle/hadoop-3.1.3/etc/hadoop下新建白名单whitelist和黑名单blacklist
(3) 服役新节点,只需在whitelist中写入主机名即可
(4) 退役旧节点,只需在blacklist中写入whitelist中的主机名后,就会把对应的主机退役掉
(5) 文件分发同步# 文件同步 xrsync.sh /opt/moudle/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/moudle/hadoop-3.1.3/etc/hadoop/whitelist /opt/moudle/hadoop-3.1.3/etc/hadoop/blacklist # 退役后,需要进行刷新操作 hdfs dfsadmin -refreshNodes yarn rmadmin -refreshNodes - 多目录配置
(1) 在hdfs-site.xml文件中添加如下内容
(2) 格式化、启动集群<property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value> </property># 如果集群开启,首先关闭 hadoop.sh stop hadoop.sh format # 开启集群,应用新配置 hadoop.sh start
四、安全模式
-
集群启动过程
(1)NameNode启动,将edits和fsimage文件加载到内存合并,新建edits_inprogress文件用来记录操作,开始监听DataNode,此时会一直 处于安全模式,只能看不能改
(2)DataNode启动,向NameNode注册并汇报块信息;当NameNode从DataNode了解到了足够多的块信息(即知道哪些块存储在哪个DataNode上),满足最小副本条件后,就会在30s后退出安全模式
(2) 最小副本条件
默认配置为dfs.replication.min=1(hdfs-default.xml)。条件可描述为: 当NameNode知道每一个块的至少一个副本所处DataNode的位置后,就满足了最小副本条件 -
安全模式常用命令
语法 说明 hdfs dfsadmin -safemode get 查看安全模式装态是开启还是关闭 hdfs dfsadmin -safemode enter 进入安全模式 hdfs dfsadmin -safemode leave 离开安全模式 hdfs dfsadmin -safemode wait 当集群处于安全模式时,程序会挂起;集群一退出安全模式,程序接着该条命令继续往下运行















 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









