







一、kafka中消息数据存储方式
1. 逻辑上的存储方式
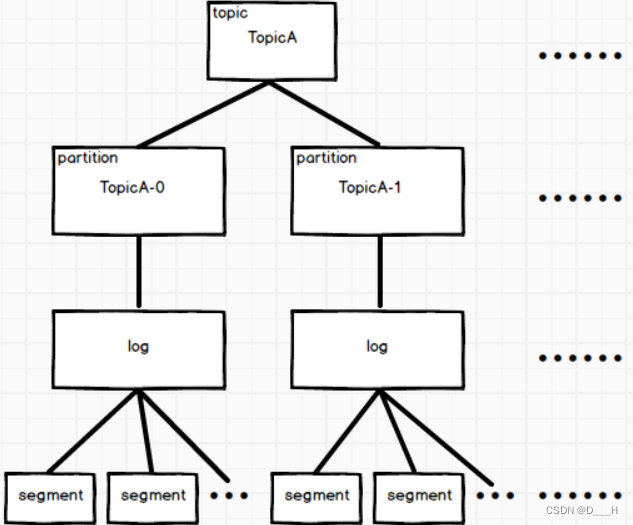
逻辑上,kafka将每个分区的所有消息存储在一个log文件中,log文件中又有多个片段(segment)
2. 物理上的存储方式
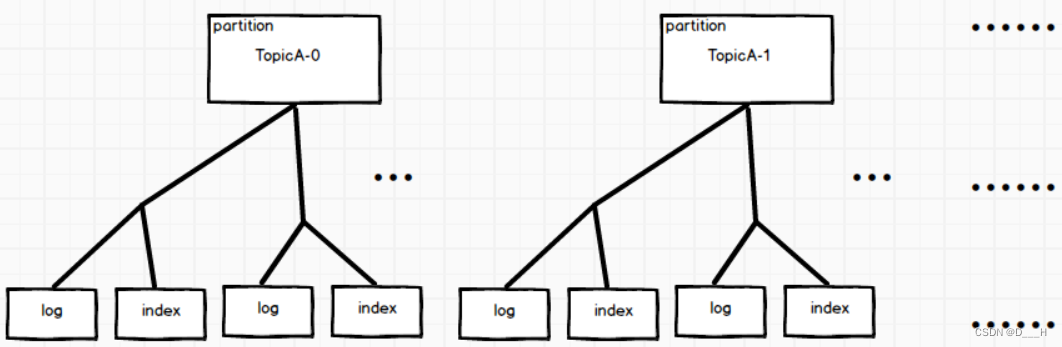
物理上,kafka会为每个分区创建一个目录,命名为:主题名-分区号;在分区目录中,存在多对log、index文件,log文件负责存储真实的数据,index文件是一个索引,可以加快在log文件中查找消息的速度。
默认情况下每个log文件最大为1G,超出1G之后,就会滚动出下一个log文件。可在server.properties中进行配置;
3. 逻辑&物理
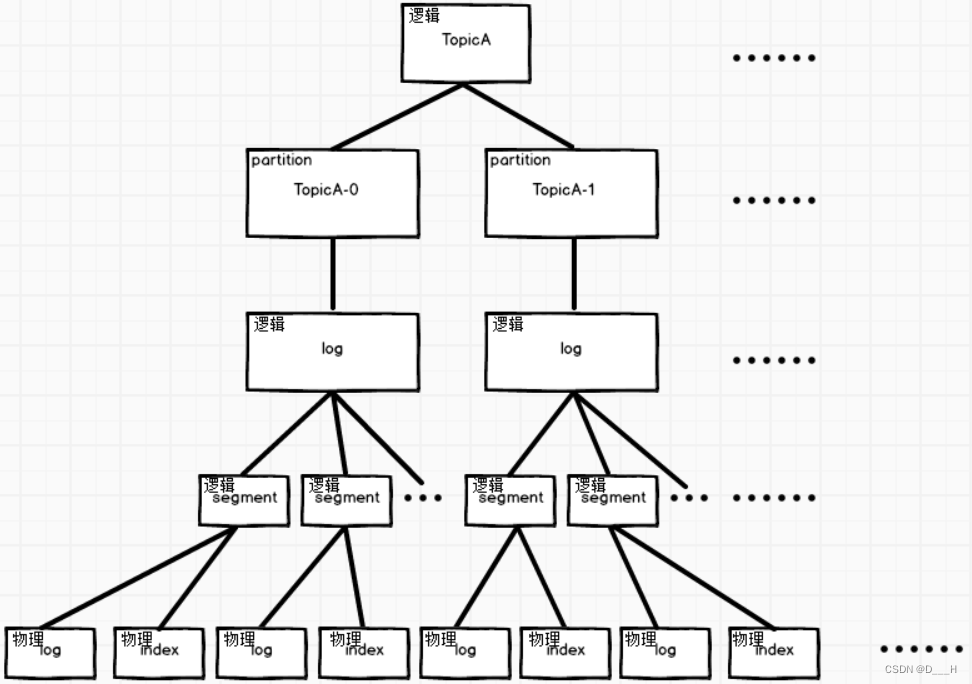
二、生产者生产出的消息的分区存放策略
1. 指定分区号
当生产数据时指定了分区号后,会直接将该条消息放入分区号所指定的分区。
2. 指定key
当生产数据时指定了了key时,会取key的哈希值,然后取余分区个数,计算出消息的所属分区号。
3. 什么也没指定
当生产数据时既没有指定分区号,也没有指定key时,采用粘性分区策略。粘性分区策略会尽可能地向一个分区中放入消息,只有当满足一定批次(batch size)或者经过一定时间后,选择另一个不相同的分区继续存放消息。
以上三种策略的优先级大小为:指定分区号 > 指定key > 什么也没指定(粘性分区)
三、数据可靠性保证
1. 如何同步数据
(1) 发送ack的策略
当生产者向分区的Leader传输数据时,Leader会在某一时刻向生产者返回ack,表明数据同步完成,返回ack的时机有以下三种:
a. 0 -> Leader接收到数据后,自己还没落盘,就直接向生产者发送ack;Leader发送完ack后如果挂掉就会导致数据丢失;
b. 1 -> Leader接受到数据并且成功落盘后,就直接向生产者发送ack;Leader发送完ack就挂掉会导致数据丢失;
c. -1/all -> Leader接受到数据落盘之后,将该数据同步,当所有Follower数据同步完成(落盘)后,Leader才会向生产者发送ack;当Leader正在发送ack的时候挂掉,会导致数据重复;
(2) kafka数据同步细节
kafka采用的ack发送策略为: c
kafka会维护一个集合ISR,在这个集合中的partition Follower都可以在指定时间内成功同步数据,如果集合内的某一个Follower无法在指定时间内成功同步数据,就会被踢出这个集合;这样成功避免了当某一个Follower挂掉,无法向Leader发送同步成功的消息时,Leader永远无法向生产者发送ack的情况;
被踢出ISR集合的Follower也并不是永远被踢出,只要它之后能够在指定时间内同步数据,就又会被拉入ISR集合中;
2. 当某一分区的Leader挂掉之后,如何选举新的Leader

如上图所示,每一个分区都具有两个特殊的位置:HW、LEO
| 名称 | 描述 |
| HW(Hight Water) | 从分区开始到该位置的数据都已经同步成功,且这些数据已经被消费者消费了 |
| LEO(Log End Offset) | 当前分区内最后一个消息的位置,超过HW的消息可能其他的一些分区同步成功,也可能另外的一些分区同步失败,可以肯定的一点是,这个范围内的消息绝对被消费者消费 |
当Leader挂掉之后,会根据Replicas和ISR集合内分区所在broker的顺序挑选下一个Leader,新的Leader选举出来后,会让所有的分区(包括自己)将HW后的数据丢掉,由于HW后的数据没有同步成功,上一任Leader肯定没有向生产者发送ack,所以生产者会重新发送这部分数据。
四、Consumer Group消费数据策略(组中哪几个消费者负责消费哪几个分区)
当消费者组中的消费者数量增加时,会将每个消费者负责的分区收回,进行重新分配。
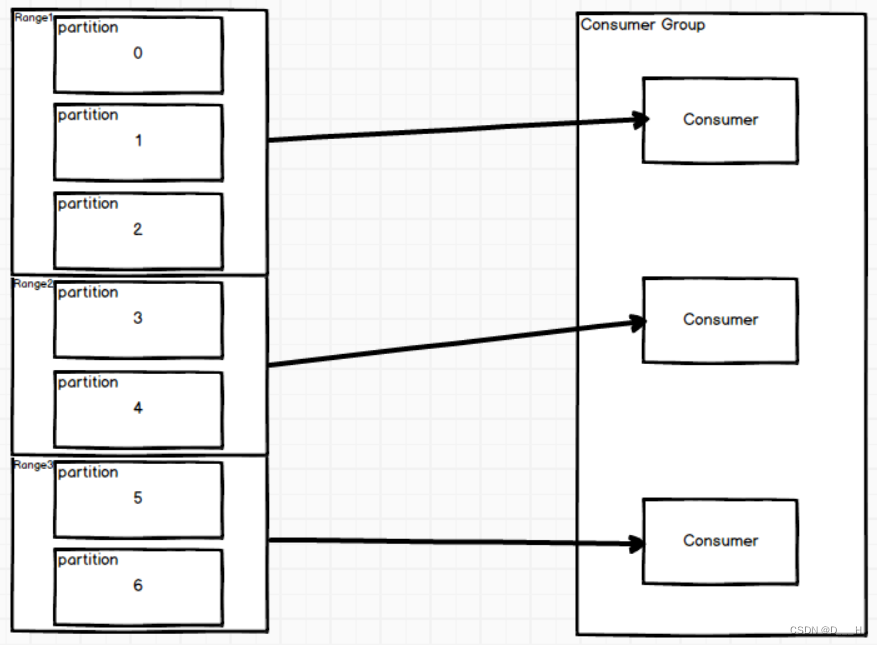
1. 范围消费策略(Range)
2. 轮询消费策略(RoundRobin)
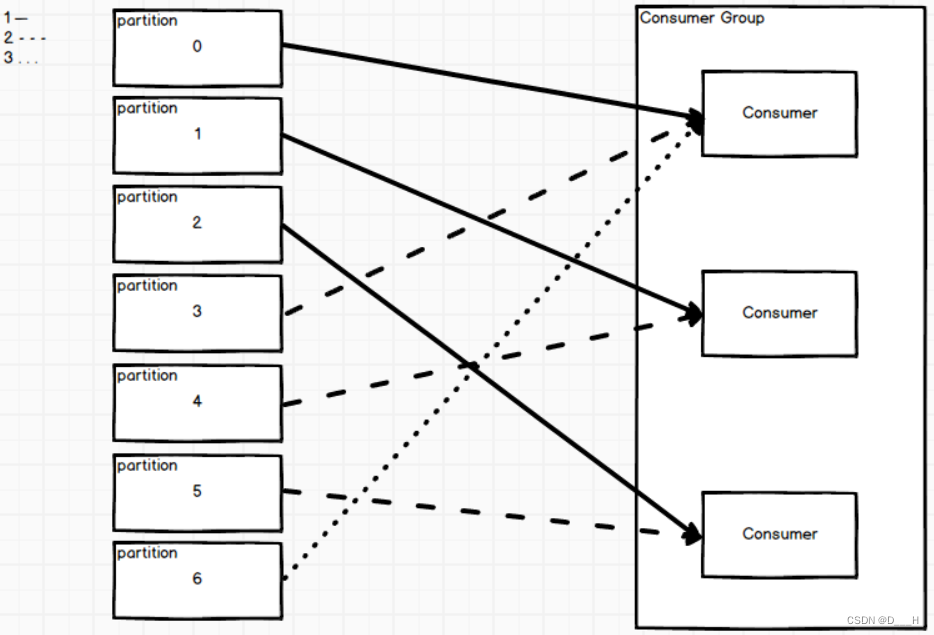
3. 粘性消费策略(Sticky)
粘性消费和轮询基本一行,唯一不同的是,当消费者组中减少了消费者以后,轮询会将每个消费者的所有分区回收,进行再分配;而粘性只会回收离开的消费者所负责的分区,并将这些分区按照轮询的规律重新分配给剩余分区。
五、Offset
Offset是关于消费者组消费主题中分区数据位置的记录,这些记录被存储在一个名为__consumer_offsets的内置主题中。
案例:查看当前消费者组的__consumer_offsets
1. 修改消费者配置文件,允许消费者消费内置主题
# 打开消费者的配置文件
vim $KAFKA_HOME/config/consumer.properties
# 在该配置文件末端添加配置项为:
# 不排除内部的topic
exclude.internal.topics=false
# 也可自定义一个组名
# 保存退出,并分发
xrsync.sh $KAFKA_HOME/config/consumer.properties2. 启动消费者消费__consumer_offsets
kafka-ops.sh consumer --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config $KAFKA_HOME/config/consumer.properties3. 启动另一个消费者消费其他队列
# 创建一个新主题
kafka-ops.sh topics --create --topic first --partitions 2 --replication-factor 3
# 启动生产者向其中生产数据
kafka-ops.sh producer --topic first
# 启动消费者消费其中的数据
kafka-ops.sh consumer --topic first --consumer.config $KAFKA_HOME/config/consumer.properties六、为什么Kafka能够高效读写数据
1. 真实数据文件会搭配一个索引文件,让读取更快速;
2. 只对文件追加写;
3. 充分利用了操作系统的优势:页缓存、零拷贝;
4. 分区中的Leader一般存在于不同的机器上,无论读写,相当于同时读/写多台服务器,假设从一台服务器读写的速度分别为vr和vw,从n台服务器中同时读写n个Leader时的速率分贝为n * vr、n * vw;
七、Zookeeper作用
帮助选举Controller,通知Controller集群中Broker的上下线(便于Controller重新选举Leader),存储一些Kafka集群的必要信息。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









